python实现线性回归
参考:《机器学习实战》- Machine Learning in Action
一、 必备的包
一般而言,这几个包是比较常见的:
• matplotlib,用于绘图
• numpy,数组处理库
• pandas,强大的数据分析库
• sklearn,用于线性回归的库
• scipy, 提供很多有用的科学函数
我一般是用pip安装,若不熟悉这些库,可以搜索一下它们的简单教程。
二、 线性回归
为了尽量简单,所以用以下一元方程式为例子:
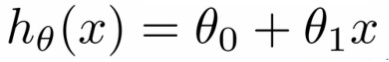
典型的例子是房价预测,假设我们有以下数据集:

我们需要通过训练这些数据得到一个线性模型,以便来预测大小为700平方英尺的房价是多少。
详细代码如下:
import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn import datasets, linear_model def get_data(file_name): data = pd.read_csv(file_name) X_parameter = [] Y_parameter = [] for single_square_feet ,single_price_value in zip(data['square_feet'],data['price']): X_parameter.append([float(single_square_feet)]) Y_parameter.append(float(single_price_value)) return X_parameter,Y_parameter def linear_model_main(X_parameters,Y_parameters,predict_value): regr = linear_model.LinearRegression() regr.fit(X_parameters, Y_parameters) predict_outcome = regr.predict(predict_value) predictions = {} predictions['intercept'] = regr.intercept_ predictions['coefficient'] = regr.coef_ predictions['predicted_value'] = predict_outcome return predictions def show_linear_line(X_parameters,Y_parameters): regr = linear_model.LinearRegression() regr.fit(X_parameters, Y_parameters) plt.scatter(X_parameters,Y_parameters,color='blue') plt.plot(X_parameters,regr.predict(X_parameters),color='red',linewidth=4) #plt.xticks(()) #plt.yticks(()) plt.show() if __name__ == "__main__": X,Y = get_data('E:/machine_learning/LR/input_data.csv') #show_linear_line(X,Y) predictvalue = 700 result = linear_model_main(X,Y,predictvalue) print "Intercept value " , result['intercept'] print "coefficient" , result['coefficient'] print "Predicted value: ",result['predicted_value']
结果如图:
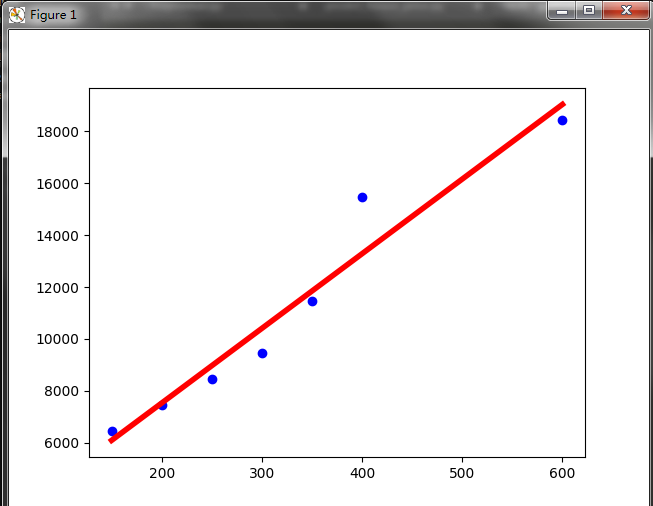
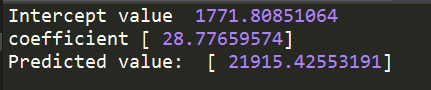
前两个为公式里的参数。
三、 多项式回归
简单的线性模型误差难免高,于是引入多项式回归模型,方程式如下:
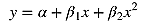
这次我们用scipy.stats中的norm来生成满足高斯分布的数据,直接贴代码:
# encoding:utf-8 import matplotlib.pyplot as plt import numpy as np from scipy.stats import norm from sklearn.pipeline import Pipeline from sklearn.linear_model import LinearRegression, SGDClassifier from sklearn.preprocessing import PolynomialFeatures, StandardScaler x = np.arange(0, 1, 0.002) y = norm.rvs(0, size=500, scale=0.1) #高斯分布数据 y = y + x**2 plt.scatter(x, y, s=5) y_test = [] y_test = np.array(y_test) #clf = LinearRegression(fit_intercept=False) clf = Pipeline([('poly', PolynomialFeatures(degree=100)), ('linear', LinearRegression(fit_intercept=False))]) clf.fit(x[:, np.newaxis], y) y_test = clf.predict(x[:, np.newaxis]) plt.plot(x, y_test, linewidth=2) plt.grid() #显示网格 plt.show()
结果如下:
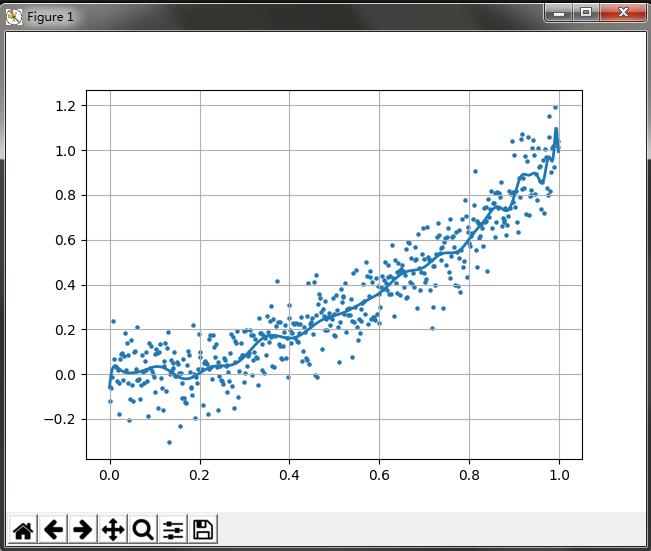
这里取的最高次为100
参考博客:http://python.jobbole.com/81215/
作者: vachester
出处:http://www.cnblogs.com/vachester/
邮箱:xcchester@gmail.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号