Trie树
借鉴这篇博客,总结了Trie树的相关知识。
1. 概念
字典树(Trie)可以保存一些字符串->值的对应关系。基本上,它跟Java的HashMap功能相同,都是key-value映射,只不过Trie的key只能是字符串。Trie来自单词"retrieve,说明它的功能是用于快速地检索。
的确,Trie的强大之处就在于它的时间复杂度。它的插入和查询时间复杂度都为O(k),其中k为key的长度,与Trie中保存了多少个元素无关。Hash表号称是O(1)的,但在计算hash的时候就肯定会是O(k),而且还有碰撞之类的问题;Trie 的缺点是空间消耗很高。
其典型的应用是用于统计和排序大量的字符串。
2. 性质
Trie树的基本性质可以归纳为:
- 根节点不包含字符,除根节点意外每个节点只包含一个字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符串不相同
如给出字符串"abc","ab","bd","dda",根据该字符串序列构建一棵Trie树。则构建的树如下:
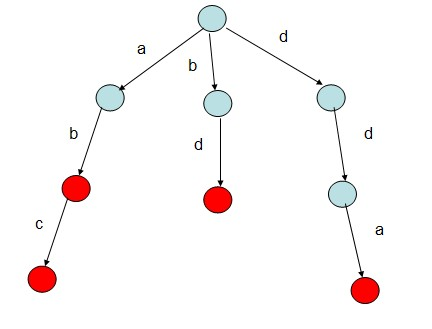
红色表示可以构成一个单词
3. 代码实现
- 构造
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;
- 插入操作
TrieNode* createTrieNode()
{
TrieNode* node = (TrieNode *)malloc(sizeof(TrieNode));
node->count = 0;
node->exist = false;
memset(node->next , 0 , sizeof(node->next)); //初始化为空指针
return node;
}
void Trie_insert(Trie root, char* word , char* trans)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
if(node->next[id] == NULL)
{
node->next[id] = createTrieNode();
}
node = node->next[id]; // 每插入一步,相当于有一个新串经过,指针向下移动
++p;
node->count += 1; // 这行代码用于统计每个单词前缀出现的次数(也包括统计每个单词出现的次数)
}
node->exist = true; // 单词结束的地方标记此处可以构成一个单词
strcpy(node->trans , trans);
}
- 查找操作
int Trie_search(Trie root, char* word)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
node = node->next[id];
++p;
if(node == NULL)
return 0;
}
return node->count;
}
作者: vachester
出处:http://www.cnblogs.com/vachester/
邮箱:xcchester@gmail.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号