
自然语言开发AI应用,利用云雀大模型打造自己的专属AI机器人

如今,大模型层出不穷,这为自然语言处理、计算机视觉、语音识别和其他领域的人工智能任务带来了重大的突破和进展。大模型通常指那些参数量庞大、层数深、拥有巨大的计算能力和数据训练集的模型。
但不能不承认的是,普通人使用大模型还是有一定门槛的,首先大模型通常需要大量的计算资源才能进行训练和推理。这包括高性能的图形处理单元(GPU)或者专用的张量处理单元(TPU),以及大内存和高速存储器。说白了,本地没N卡,就断了玩大模型的念想吧。
其次,大模型的性能往往受到模型调优和微调的影响。这需要对模型的超参数进行调整和优化,以适应特定任务或数据集。对大模型的调优需要一定的经验和专业知识,包括对深度学习原理和技术的理解。
那么,如果不具备相关专业知识,也没有专业的设备,同时也想开发属于自己的基于AI大模型的应用怎么办?本次我们使用在线的云雀大模型来打造属于自己的AI应用。
构建线上AI应用
首先访问扣子应用的官网:
https://www.coze.cn/home
注册成功之后,我们需要一个创意,也就是说我们到底想要做一个什么应用,这个应用的功能是什么,当然,关于创意AI是帮不了你的,需要自己想,比如笔者的代码水平令人不敢恭维,平时在CodeReView时,经常被同事嘲笑,没办法,有的人就是没有代码洁癖,为了避免此种情况经常发生,想要打造一款AI机器人能够在代码提交之前帮忙审核代码,检查语法的错误并给出修改意见和性能层面优化的方案。
此时点击创建Bot:
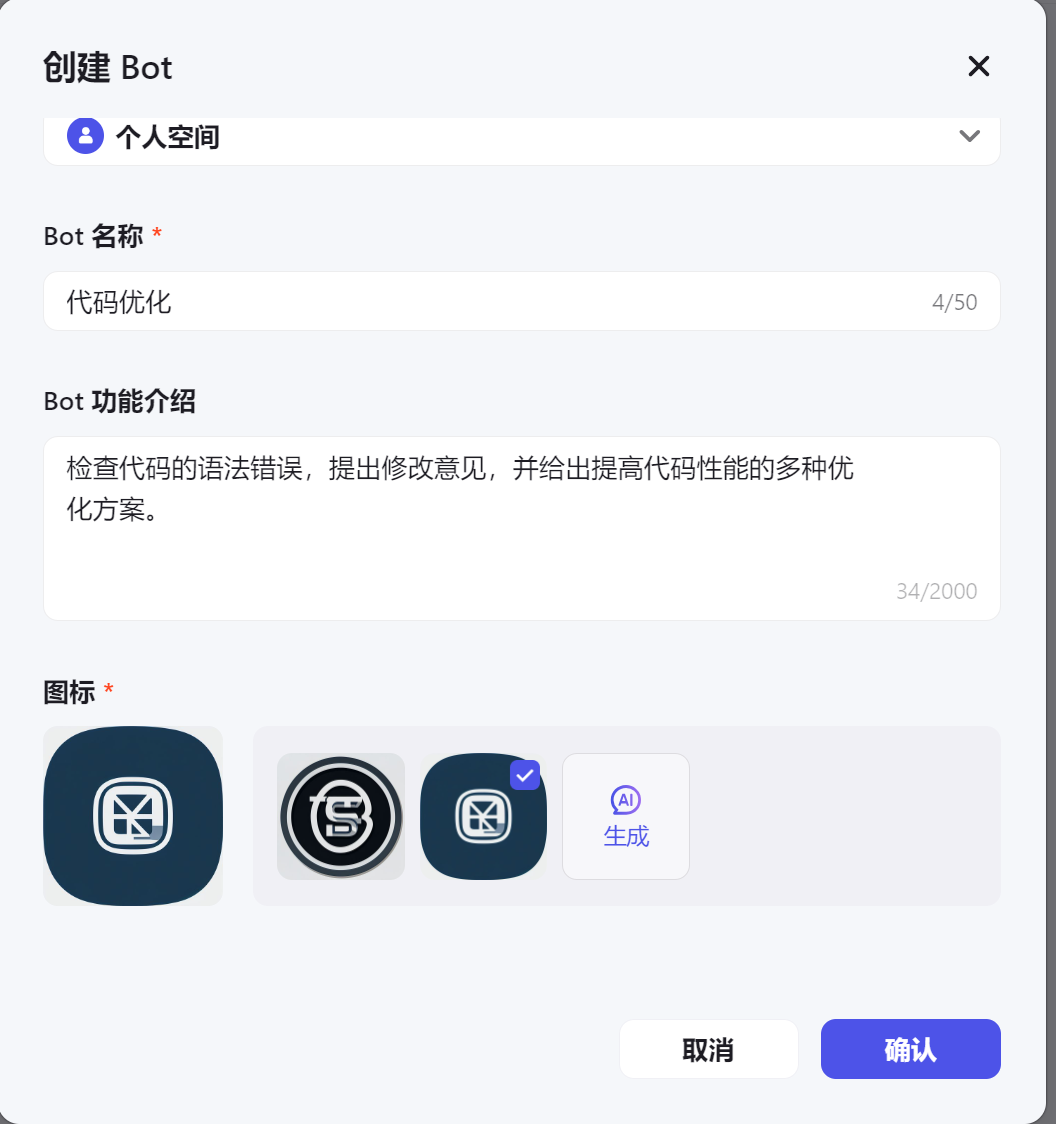
如上图所示,这里输入应用的名称和描述,至于应用图标,可以让AI生成一个。
工作流 WorkFlow
工作流指的是支持通过可视化的方式,对插件、大语言模型、代码块等功能进行组合,从而实现复杂、稳定的业务流程编排。
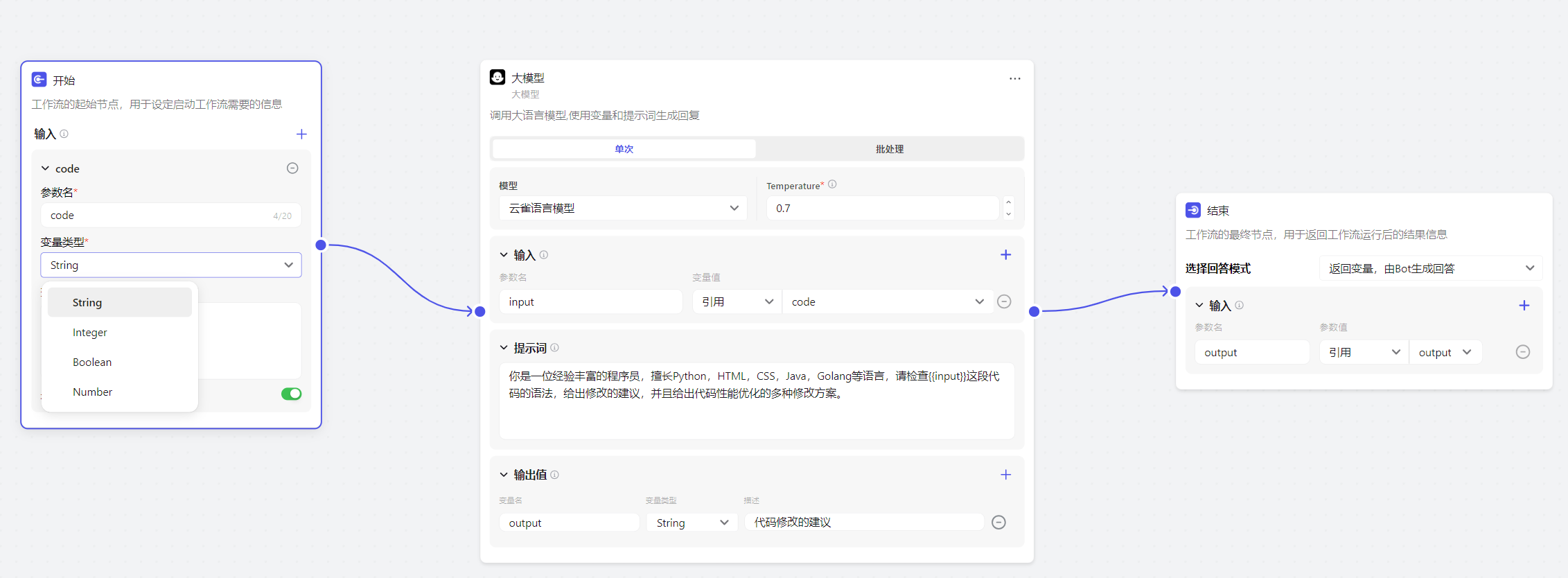
我们的工作流非常简单,第一步,用户输入代码,第二步,大模型检查代码,第三步,大模型返回修改意见。
点击创建工作流,输入的参数变量为code,数据类型可以选择四种,即字符串、整形、布尔和数字,这里代码显然选择字符串。
接着接入大模型,引导词这样填写:
你是一位经验丰富的程序员,擅长Python,HTML,CSS,Java,Golang等语言,请检查{{input}}这段代码的语法,给出修改的建议,并且给出代码性能优化的多种修改方案。
通过引导词来让大模型针对输入的代码进行检测。
最后返回大模型输入的修改意见。
如图所示:
随后可以运行整个工作流进行测试,大模型返回:
{
"output": "可优化项目与建议:\n- 建议使用 `try-except` 结构来捕获所有类型的异常,然后进行统一处理。\n- 建议添加代码注释,增强代码的可读性。\n\n优化后的代码如下所示:\n```python\ndef make_tran():\n \"\"\"\n 该函数用于将 video.srt 文件中的英文翻译成中文,并将翻译结果写入 two.srt 文件\n\n Returns:\n str: \"翻译完毕\",表示翻译过程已完成\n \"\"\"\n # 从预训练模型中加载 tokenizer 和 model\n tokenizer = AutoTokenizer.from_pretrained(\"Helsinki-NLP/opus-mt-en-zh\")\n model = AutoModelForSeq2SeqLM.from_pretrained(\"Helsinki-NLP/opus-mt-en-zh\")\n # 打开 video.srt 文件并读取其中的内容\n with open(\"./video.srt\", 'r', encoding=\"utf-8\") as file:\n gweight_data = file.read()\n # 将读取到的内容按换行符分割成多个段落,并存储在 result 列表中\n result = gweight_data.split(\"\\n\\n\")\n # 如果 two.srt 文件存在,则将其删除\n if os.path.exists(\"./two.srt\"):\n os.remove(\"./two.srt\")\n # 遍历 result 列表中的每个段落\n for res in result:\n # 将每个段落按换行符分割成多个句子,并存储在 line_srt 列表中\n line_srt = res.split(\"\\n\")\n # 尝试对每个句子进行翻译\n try:\n # 使用 tokenizer 对句子进行预处理,以便模型可以处理它们\n tokenized_text = tokenizer.prepare_seq2seq_batch([line_srt[2]], return_tensors='pt')\n # 使用模型进行翻译\n translation = model.generate(**tokenized_text)\n # 使用 tokenizer 将翻译结果解码为文本\n translated_text = tokenizer.batch_decode(translation, skip_special_tokens=False)[0]\n # 移除翻译结果中的填充字符和结束符号,并去除首尾的空格\n translated_text = translated_text.replace(\"<pad>\", \"\").replace(\"</s>\", \"\").strip()\n # 打印翻译结果\n print(translated_text)\n # 将翻译结果写入 two.srt 文件\n with open(\"./two.srt\", \"a\", encoding=\"utf-8\") as f:\n f.write(f\"{line_srt[0]}\\n{line_srt[1]}\\n{line_srt[2]}\\n{translated_text}\\n\\n\")\n # 如果在翻译过程中发生任何异常,则打印异常信息,并跳过当前句子\n except Exception as e:\n print(str(e))\n # 返回 \"翻译完毕\",表示翻译过程已完成\n return \"翻译完毕\"\n```"
}
如此,就完成了一个代码检查和优化的工作流,说白了,就是给用户一个没有token限制并且无限次使用的大模型,并且跳过prompt环节,直接简单粗暴返回垂直内容的解决方案。
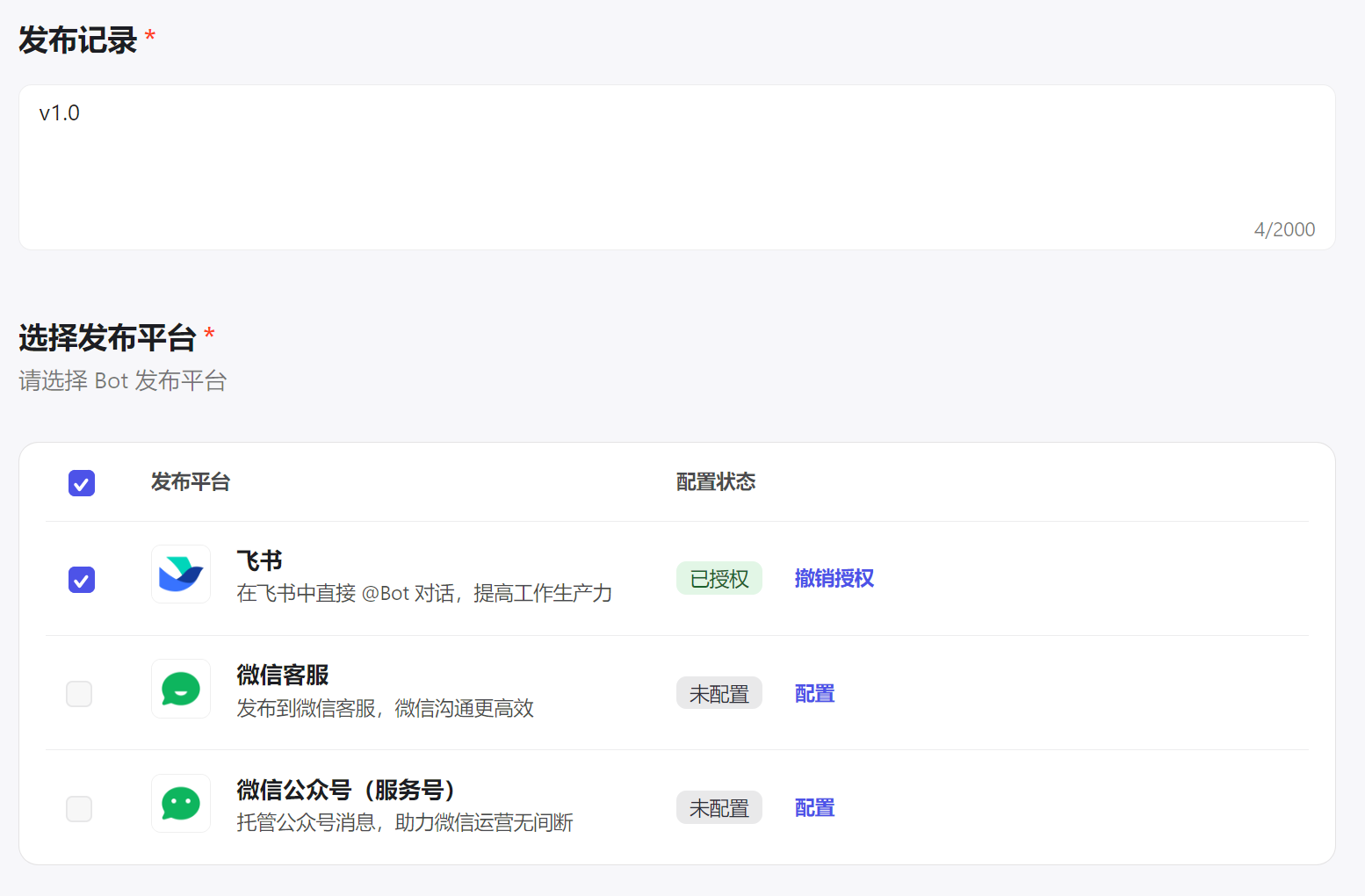
发布应用
构建好应用之后,我们可以在其他平台发布,让更多人使用该应用,这里以飞书为例子,飞书是一站式协同办公平台,为企业提供各种数字化办公解决方案,大部分公司都在使用。
随后在公司群里就可以直接调用自己的应用了:
结语
尽管使用大模型可能具有一些挑战,但随着技术的进步和资源的可用性,大模型的门槛正在逐渐降低。这为更多的普通人、无编程背景的爱好者提供了利用大模型来解决对于个人垂直领域相对复杂任务的机会。




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 如何使用 Uni-app 实现视频聊天(源码,支持安卓、iOS)
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)