又欲又撩人,基于新版Bert-vits2V2.0.2音色模型雷电将军八重神子一键推理整合包分享
Bert-vits2项目近期炸裂更新,放出了v2.0.2版本的代码,修正了存在于2.0先前版本的重大bug,并且重炼了底模,本次更新是即1.1.1版本后最重大的更新,支持了三语言训练及混合合成,并且做到向下兼容,可以推理老版本的模型,本次我们基于新版V2.0.2来本地推理原神小姐姐们的音色模型。
具体的更新日志请参见官网:
https://github.com/fishaudio/Bert-VITS2/releases
模型配置
首先克隆官方最近的v2.0.2代码:
git clone https://github.com/fishaudio/Bert-VITS2.git
随后在项目的根目录创建Data目录
cd Bert-VITS2
mkdir Data
该目录用来存放音色模型文件。
随后下载雷电将军和八重神子的音色模型:
链接:https://pan.baidu.com/s/1e9gKidfvYKLU2IzjoW3sVw?pwd=v3uc
这两个模型都是基于老版本进行训练的,囿于篇幅,训练流程先按下不表。
需要注意的是,模型文件所在的目录不支持中文,最好改成英文,目录结构如下所示:
E:\work\Bert-VITS2-v202_launch_yingAndBachong\Data>tree/F
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
├───bachong
│ │ config.json
│ │
│ └───models
│ G_47700.pth
│
└───ying
│ config.json
│ config.yml
│
├───custom_character_voice
├───filelists
└───models
G_4600.pth
这里.pth文件就是模型本体,config.json是模型配置文件。
当然,除了笔者分享的模型,也可以加载之前老版本自己训练的模型,但需要注意的是,必须指定模型训练的版本,也就是当时训练操作过程中Bert-VITS2的版本,比如笔者的模型训练时是基于v1.1.1,那么就必须在config中进行指定:
{
"train": {
"log_interval": 100,
"eval_interval": 100,
"seed": 52,
"epochs": 200,
"learning_rate": 0.0001,
"betas": [
0.8,
0.99
],
"eps": 1e-09,
"batch_size": 4,
"fp16_run": false,
"lr_decay": 0.999875,
"segment_size": 16384,
"init_lr_ratio": 1,
"warmup_epochs": 0,
"c_mel": 45,
"c_kl": 1.0,
"skip_optimizer": true
},
"data": {
"training_files": "filelists/train.list",
"validation_files": "filelists/val.list",
"max_wav_value": 32768.0,
"sampling_rate": 44100,
"filter_length": 2048,
"hop_length": 512,
"win_length": 2048,
"n_mel_channels": 128,
"mel_fmin": 0.0,
"mel_fmax": null,
"add_blank": true,
"n_speakers": 2,
"cleaned_text": true,
"spk2id": {
"bachong": 0
}
},
"model": {
"use_spk_conditioned_encoder": true,
"use_noise_scaled_mas": true,
"use_mel_posterior_encoder": false,
"use_duration_discriminator": true,
"inter_channels": 192,
"hidden_channels": 192,
"filter_channels": 768,
"n_heads": 2,
"n_layers": 6,
"kernel_size": 3,
"p_dropout": 0.1,
"resblock": "1",
"resblock_kernel_sizes": [
3,
7,
11
],
"resblock_dilation_sizes": [
[
1,
3,
5
],
[
1,
3,
5
],
[
1,
3,
5
]
],
"upsample_rates": [
8,
8,
2,
2,
2
],
"upsample_initial_channel": 512,
"upsample_kernel_sizes": [
16,
16,
8,
2,
2
],
"n_layers_q": 3,
"use_spectral_norm": false,
"gin_channels": 256
},
"version": "1.1.1"
}
最后的version参数用来指定模型,如果不指定模型,系统默认是v2.0版本,假设模型和版本不匹配,会造成本地推理的音色异常。
修改好版本之后,可以通过pip安装依赖:
pip install -r requirements.txt
至此,模型就配置好了。
本地推理
依赖安装好之后,在根目录执行命令:
python3 server_fastapi.py
程序返回:
E:\work\Bert-VITS2-v202_launch_yingAndBachong>python server_fastapi.py
E:\work\Bert-VITS2-v202_launch_yingAndBachong\venv\lib\site-packages\torch\nn\utils\weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
11-20 11:08:46 SUCCESS | server_fastapi.py:101 | 添加模型E:\work\Bert-VITS2-v202_launch_yingAndBachong\Data\ying\models\G_4600.pth,使用配置文件E:\work\Bert-VITS2-v202_launch_yingAndBachong\Data\ying\config.json
11-20 11:08:46 SUCCESS | server_fastapi.py:107 | 模型已存在,添加模型引用。
11-20 11:08:46 WARNING | server_fastapi.py:626 | 本地服务,请勿将服务端口暴露于外网
11-20 11:08:46 INFO | server_fastapi.py:627 | api文档地址 http://127.0.0.1:7860/docs
说明服务已经启动,没错,Bert-vits2的推理api是基于Fast-api的。关于Fast-api框架,请移步:
2020年是时候更新你的技术武器库了:Asgi vs Wsgi(FastAPI vs Flask)
随后访问http://127.0.0.1:7860/:
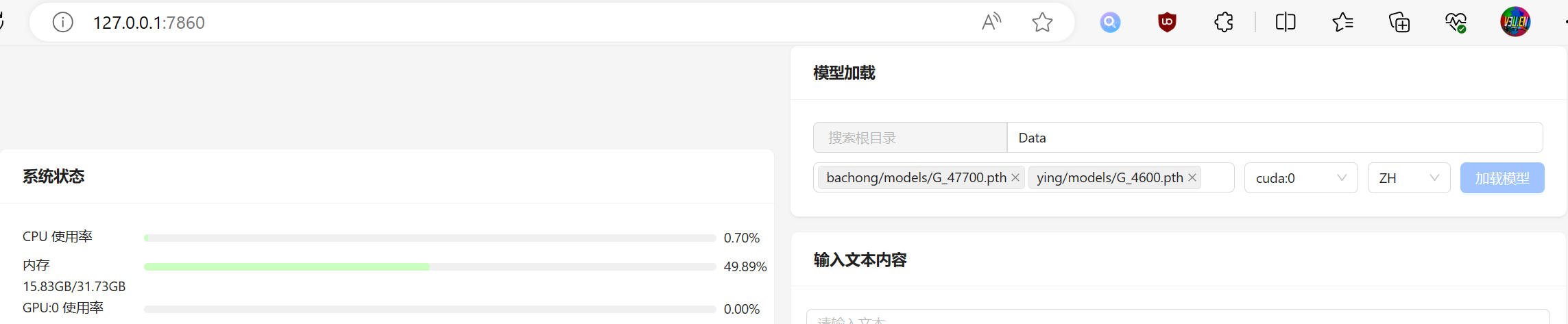
这里可以将两个模型一起加载进来。
右侧参数为推理设备和语言,默认是使用cuda和中文。
如果是没有N卡的同学,也可以选择用cpu进行本地推理。
随后将推理文本写入文本框:
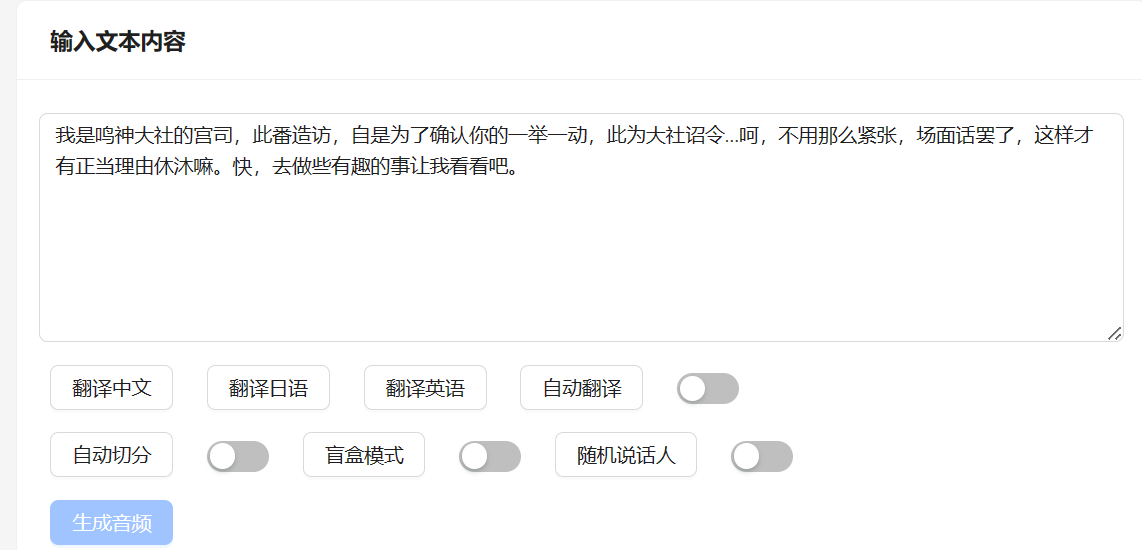
这里值得一提的是,Bert-vits2解决了长文本报错的问题,如果是长文本,只需要打开自动切分的选项即可,系统会根据文本中的标点进行切割,减少每次推理的token数量,从而避免报错。
最后新版本支持多模型同时推理:
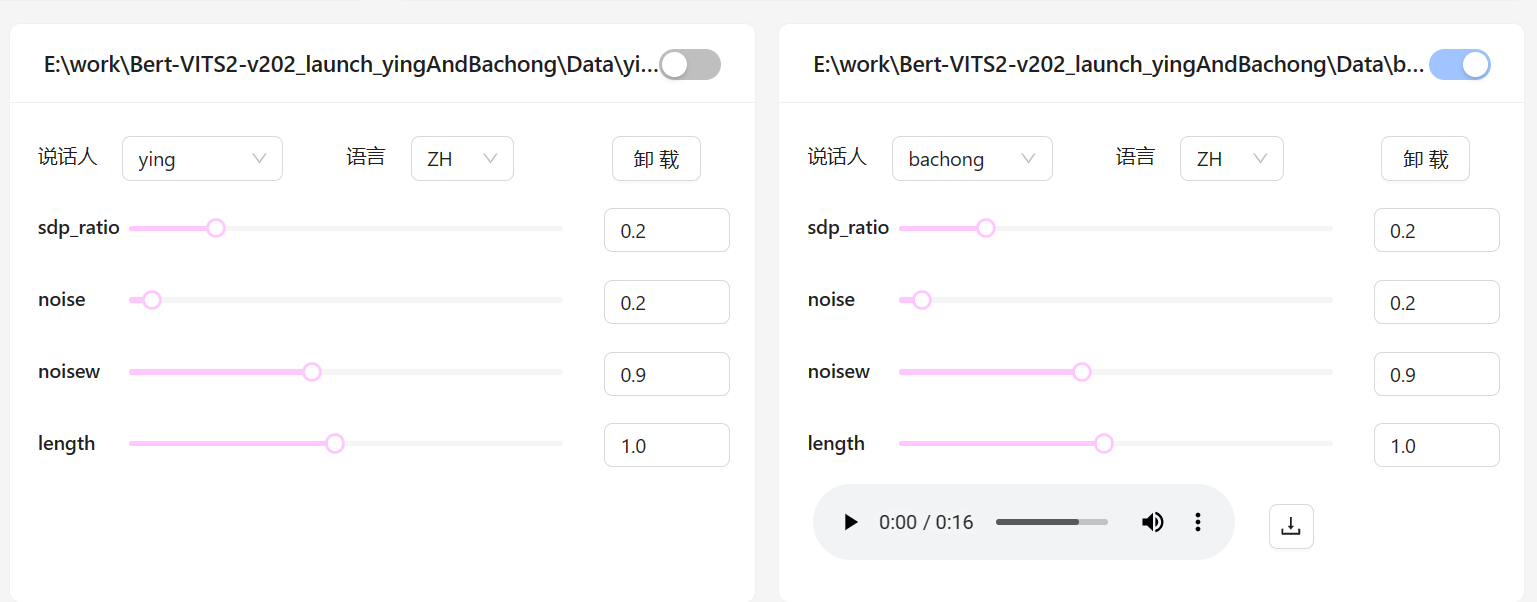
只需要选择对应的模型选项,然后下载音频即可。
结语
笔者已经采用:一键整合,万用万灵,Python3.10项目嵌入式一键整合包的制作(Embed)的方式将项目做成了一键整合包,解压后运行launch.bat文件,开箱可用,一键推理:
链接:https://pan.baidu.com/s/12pinwHb5mmYvskYTZtLKvg?pwd=v3uc
欢迎诸公下载品鉴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号