航空公司价值预测代码
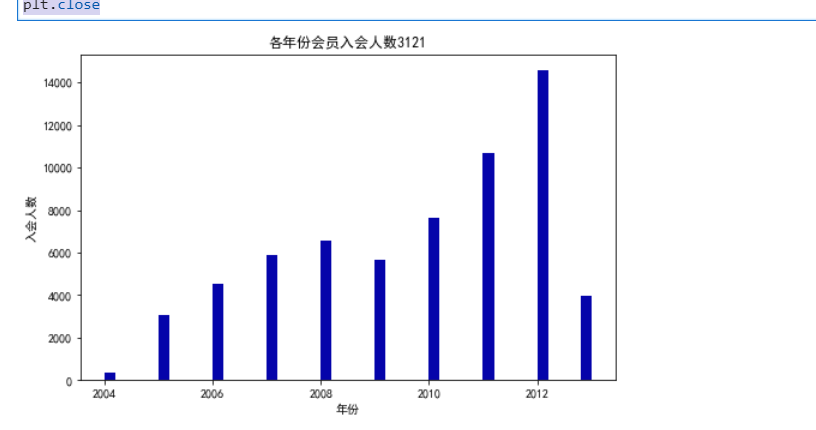
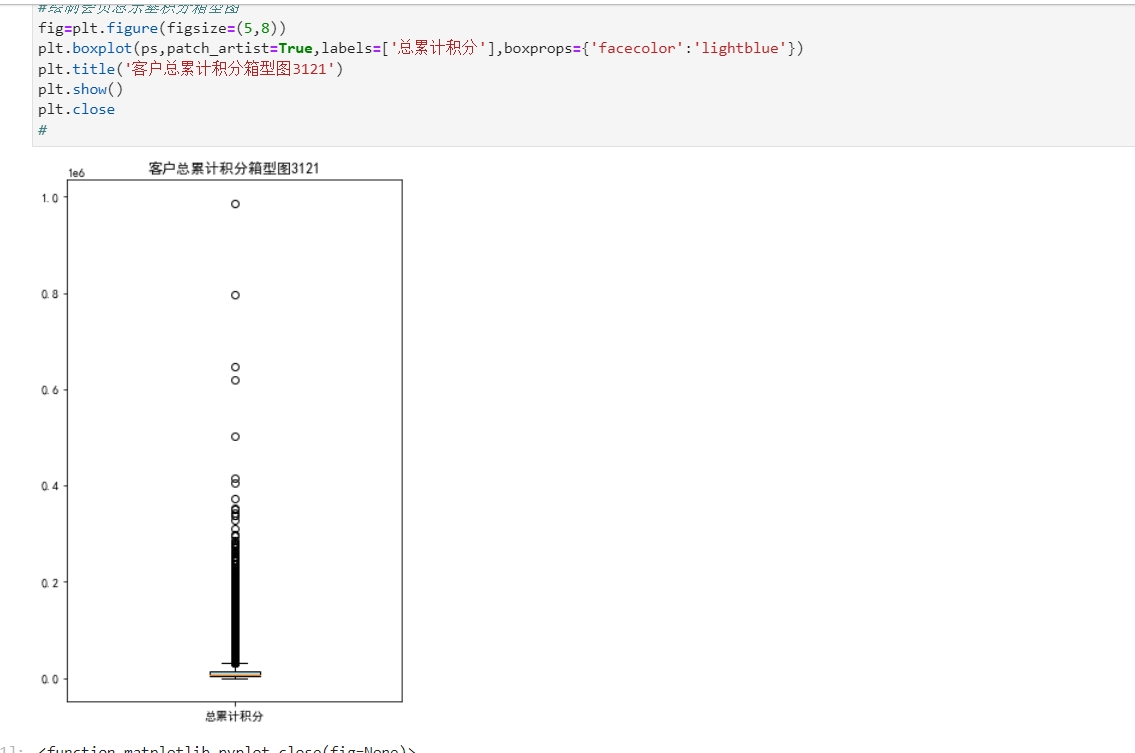
import pandas as pd datafile=r"C:\Users\Lenovo\Desktop\air_data.csv" resultfile=r"D:\explore.csv" data=pd.read_csv(datafile, encoding='utf-8') explore=data.describe(percentiles=[],include='all').T explore['null']=len(data)-explore['count'] explore=explore[['null','max','min']] explore.columns=[u'空值数',u'最大值',u'最小值'] explore.to_csv(resultfile) from datetime import datetime import numpy as np import pandas as pd import matplotlib.pyplot as plt; ffp=data['FFP_DATE'].apply(lambda x:datetime.strptime(x,'%Y/%m/%d')) ffp_year=ffp.map(lambda x : x.year) #绘制各年份会员入会人数直方图 fig=plt.figure(figsize=(8,5)) plt.rcParams['font.sans-serif']='SimHei' plt.rcParams['axes.unicode_minus']=False plt.hist(ffp_year,bins='auto',color='#0504aa') plt.xlabel('年份') plt.ylabel('入会人数') plt.title('各年份会员入会人数3121') plt.show() plt.close
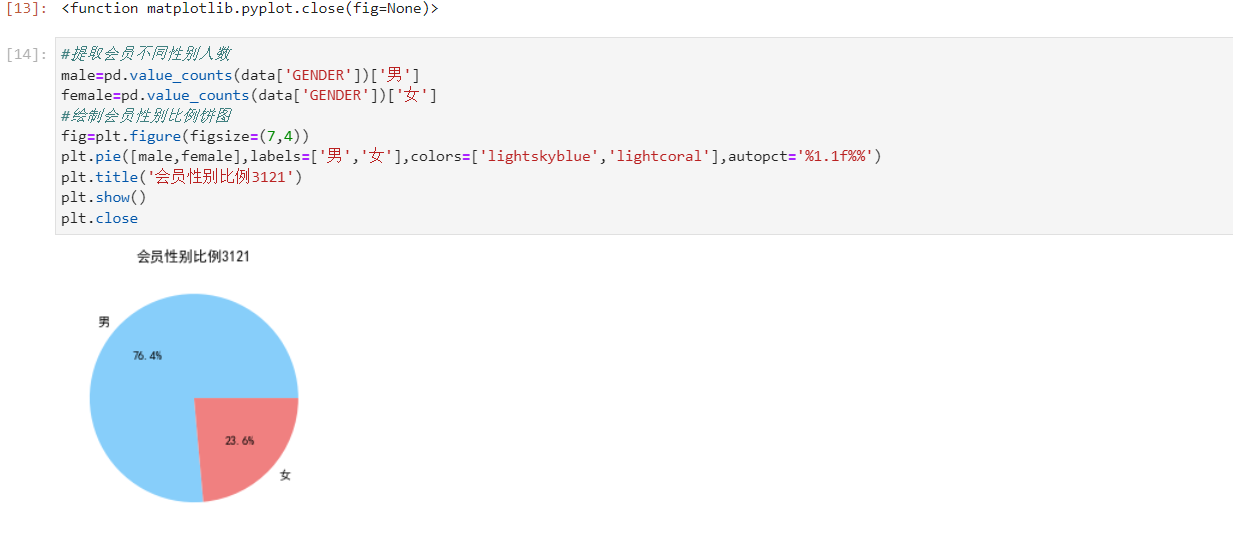
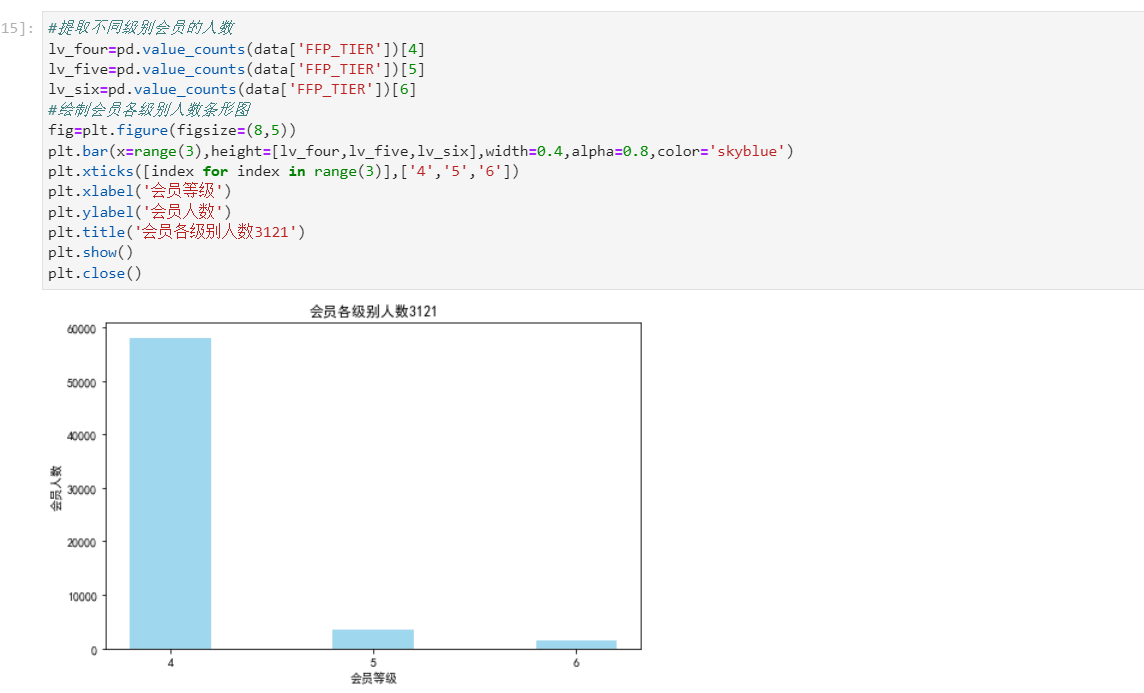

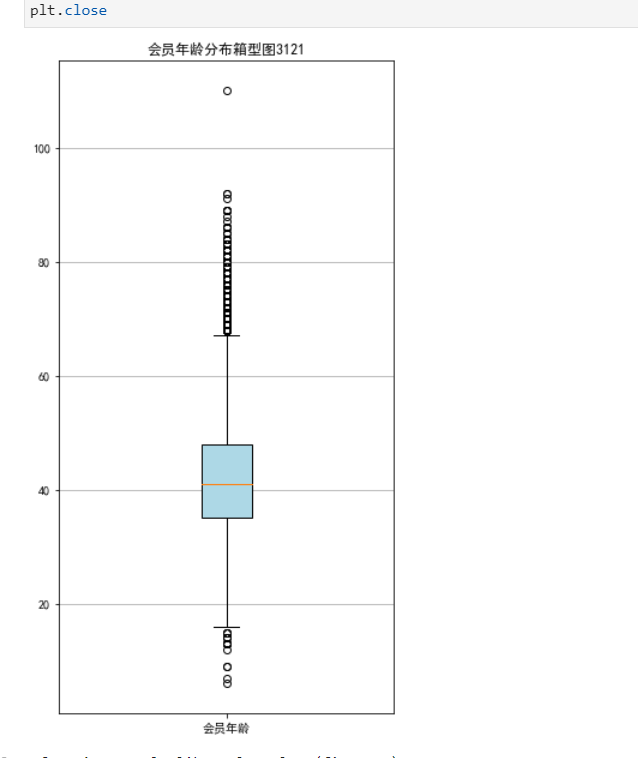
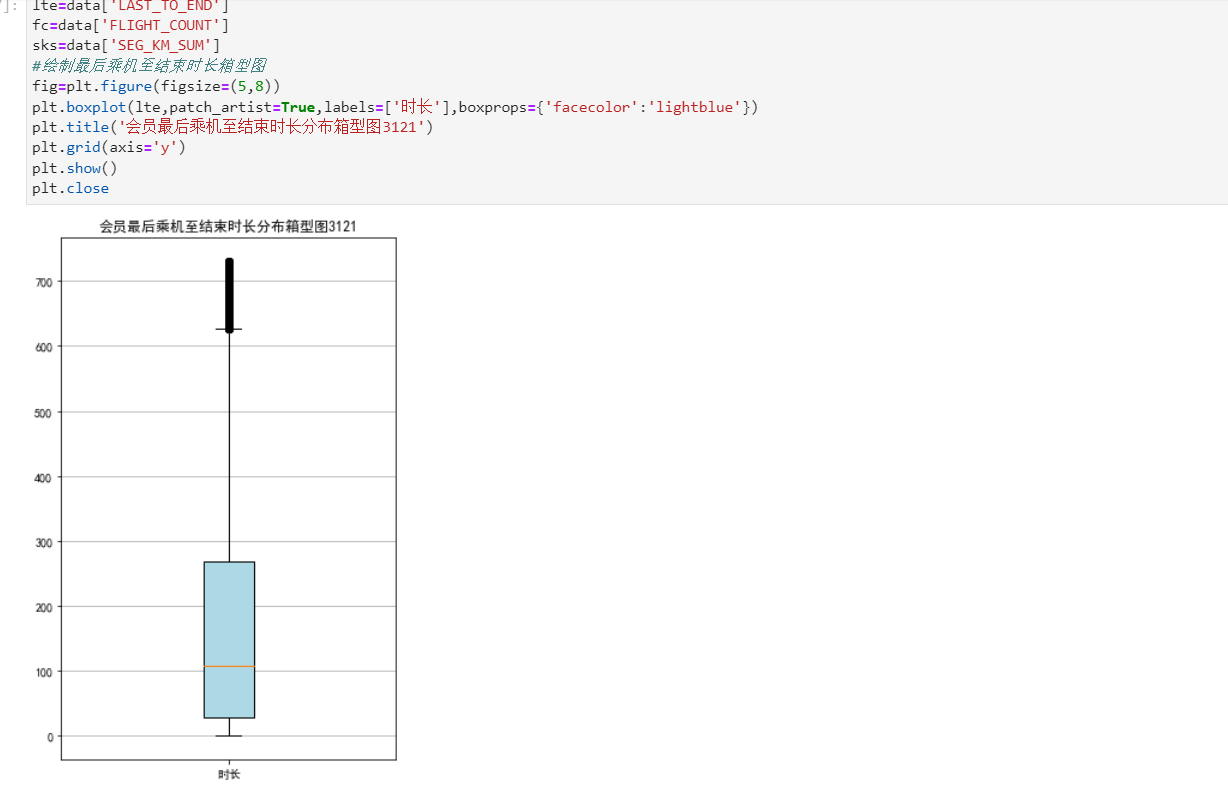
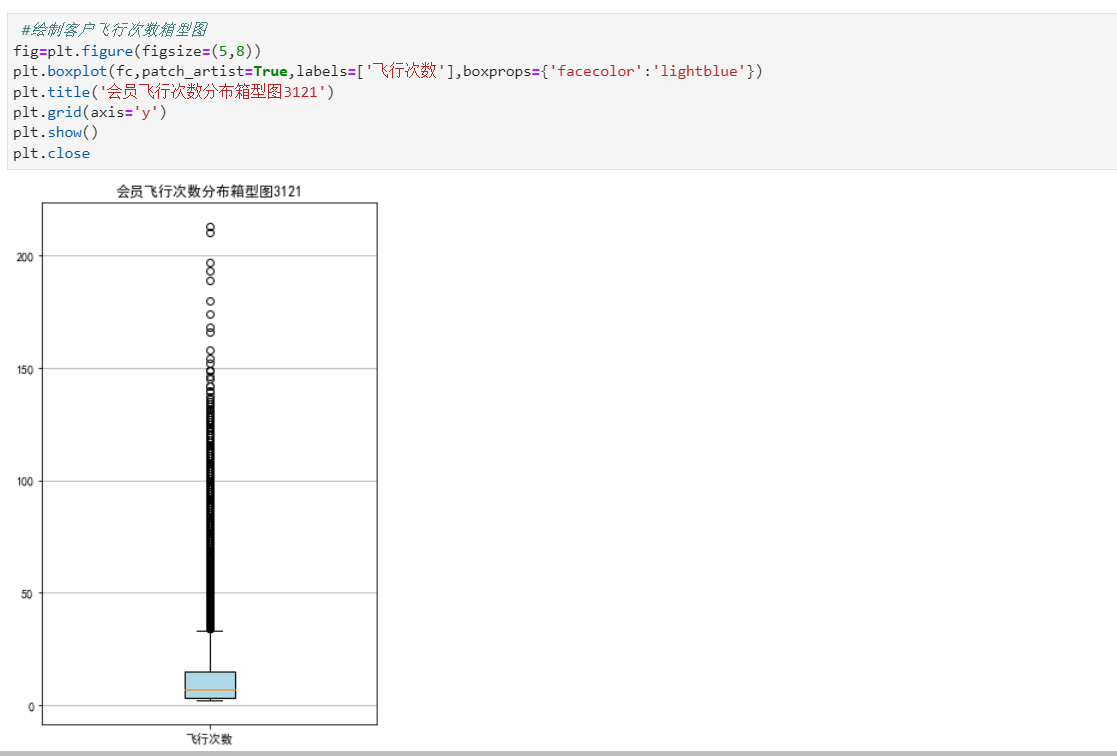

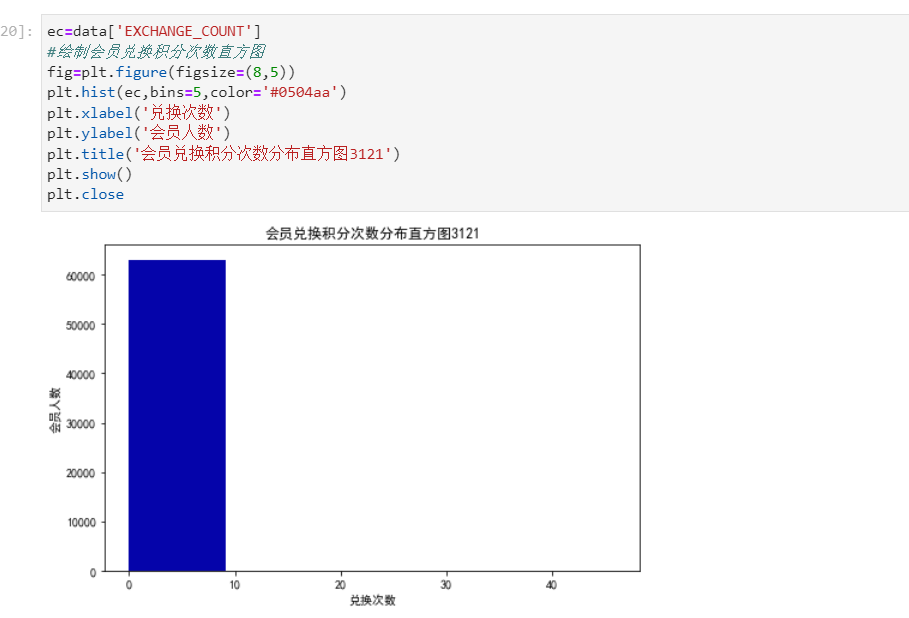
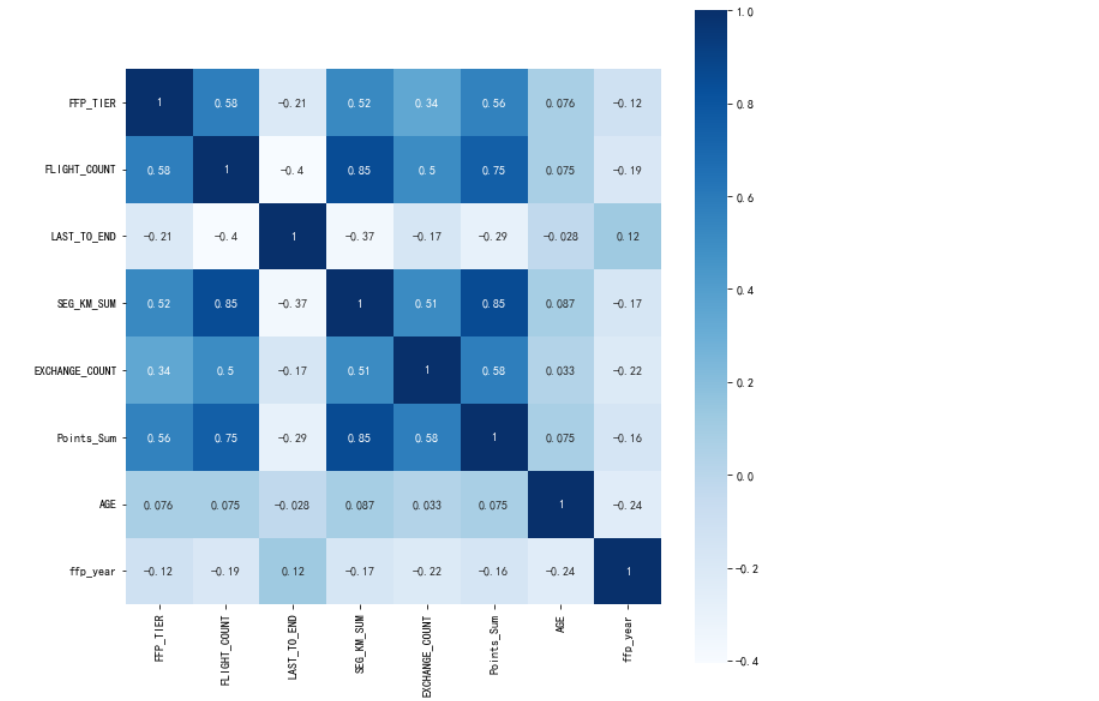
#提取属性并合并为新数据集 data_corr=data[['FFP_TIER','FLIGHT_COUNT','LAST_TO_END','SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum']] age1=data['AGE'].fillna(0) data_corr['AGE']=age1.astype('int64') data_corr['ffp_year']=ffp_year #计算相关性矩阵 dt_corr=data_corr.corr(method='pearson') print('相关性矩阵为:\n',dt_corr) #绘制热力图 import seaborn as sns plt.title("3121") plt.subplots(figsize=(10,10)) sns.heatmap(dt_corr,annot=True,vmax=1,square=True,cmap='Blues') plt.show() plt.closes
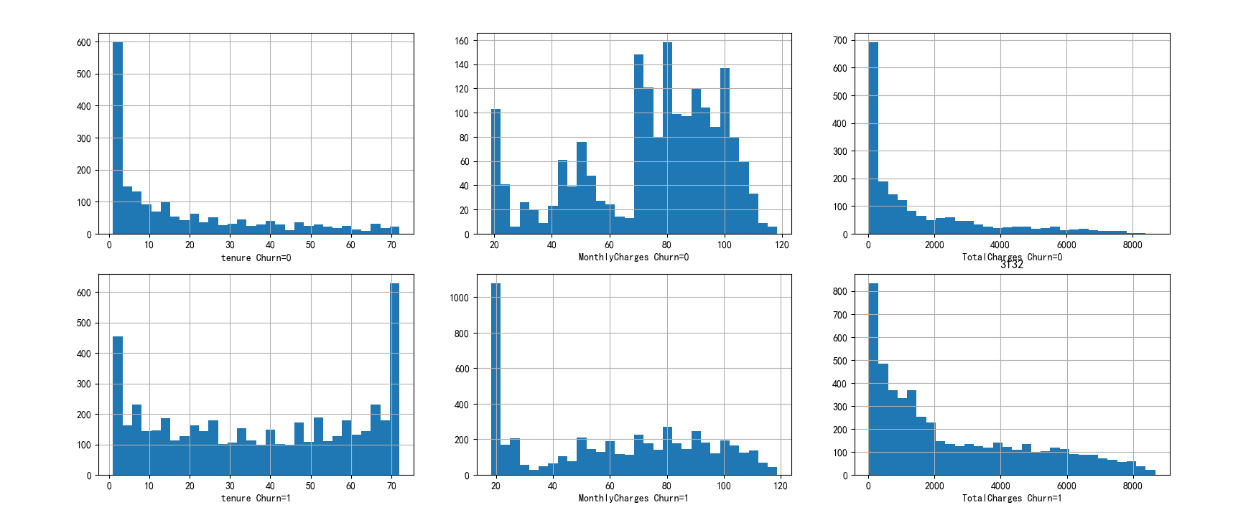
import numpy as np import pandas as pd datafile=r"C:\Users\Lenovo\Desktop\air_data.csv" cleanedfile=r"D:\data_cleaned.csv" airline_data=pd.read_csv(datafile,encoding='utf-8') print('原始数据的形状为:',airline_data.shape) #去除票价为空的记录 airline_notnull=airline_data.loc[airline_data['SUM_YR_1'].notnull()&airline_data['SUM_YR_2'].notnull(),:] print('删除确实记录后数据的形状为:',airline_notnull.shape) #只保留票价非零的,或者平均折扣率部位0且总飞行公里数大于0的记录 index1=airline_notnull['SUM_YR_1']!=0 index2=airline_notnull['SUM_YR_2']!=0 index3=(airline_notnull['SEG_KM_SUM']>0)&(airline_notnull['avg_discount']!=0) index4=airline_notnull['AGE']>100 airline=airline_notnull[(index1|index2)&index3&~index4] print('数据清洗后数据的形状为:',airline.shape) airline.to_csv(cleanedfile) import pandas as pd import numpy as np cleanedfile=r"D:\data_cleaned.csv" airline=pd.read_csv(cleanedfile,encoding='utf-8') #选取需求属性 airline_selection=airline[['FFP_DATE','LOAD_TIME','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']] print('筛选的属性前5行为:\n',airline_selection.head()) L=pd.to_datetime(airline_selection['LOAD_TIME'])-\ pd.to_datetime(airline_selection['FFP_DATE']) L=L.astype('str').str.split().str[0] L=L.astype('int')/30 #合并属性 airline_features = pd.concat([L,airline_selection.iloc[:,2:]],axis = 1) #行合并 print('构建的LRFMC特征前5行为:\n',airline_features.head()) #数据标准化 from sklearn.preprocessing import StandardScaler data = StandardScaler().fit_transform(airline_features) # np.savez(r'G:\data\data\airline_scale.npz',data) # print('标准化后LRFMC的5个属性为:\n',data[:5,:]) import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 import warnings warnings.filterwarnings('ignore') from scipy import stats from sklearn.preprocessing import StandardScaler from imblearn.over_sampling import SMOTE from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV, KFold from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, VotingClassifier, ExtraTreesClassifier import xgboost as xgb from sklearn import metrics import prettytable data = pd.read_csv(r'G:\data\data\WA_Fn-UseC_-Telco-Customer-Churn.csv') print(data.head().T) print(data.info()) data.drop("customerID", axis=1, inplace=True) # 转换成连续型变量 data['TotalCharges'] = pd.to_numeric(data.TotalCharges, errors='coerce') # 查看是否存在缺失值 data['TotalCharges'].isnull().sum() # 查看缺失值分布 data.loc[data['TotalCharges'].isnull()].T data.query("tenure == 0").shape[0] data = data.query("tenure != 0") # 重置索引 data = data.reset_index().drop('index',axis=1) # 查看各类别特征频数 for i in data.select_dtypes(include="object").columns: print(data[i].value_counts()) print('-'*50) data.Churn = data.Churn.map({'No':0,'Yes':1}) fig, ax= plt.subplots(nrows=2, ncols=3, figsize = (20,8)) plt.title("3121") for i, feature in enumerate(['tenure','MonthlyCharges','TotalCharges']): data.loc[data.Churn == 1, feature].hist(ax=ax[0][i], bins=30) data.loc[data.Churn == 0, feature].hist(ax=ax[1][i], bins=30, ) ax[0][i].set_xlabel(feature+' Churn=0') ax[1][i].set_xlabel(feature+' Churn=1') plt.show()