CEPH-3:cephfs功能详解
ceph集群cephfs使用详解
一个完整的ceph集群,可以提供块存储、文件系统和对象存储。
本节主要介绍文件系统cephfs功能如何灵活的使用,集群背景:
$ ceph -s
cluster:
id: f0a8789e-6d53-44fa-b76d-efa79bbebbcf
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 24h)
mgr: a(active, since 14h)
mds: cephfs:1 {0=cephfs-a=up:active} 1 up:standby-replay
osd: 1 osds: 1 up (since 24h), 1 in (since 26h)
rgw: 1 daemon active (my.store.a)
data:
pools: 10 pools, 200 pgs
objects: 719 objects, 1.3 GiB
usage: 54 GiB used, 804 GiB / 858 GiB avail
pgs: 200 active+clean
io:
client: 852 B/s rd, 1 op/s rd, 0 op/s wr
cephfs文件系统介绍
cephfs介绍
cephfs即ceph filesystem,是一个基于ceph集群且兼容POSIX标准的文件共享系统,创建cephfs文件系统时需要在ceph集群中添加mds服务。cephfs支持以内核模块方式加载也支持fuse方式加载。无论是内核模式还是fuse模式,都是通过调用libcephfs库来实现cephfs文件系统的加载。
fuse用户态和kernel内核态两种挂载cephfs的优劣式:
- fuse 客户端最容易与服务器做到代码级的同步,但是内核客户端的性能通常更好。
- 这两种客户端不一定会提供一样的功能,如 fuse 客户端可支持客户端强制配额,但内核客户端却不支持。
- 遇到缺陷或性能问题时,最好试试另一个客户端,以甄别此缺陷是否特定于客户端
mds组件介绍
mds是该服务负责处理POSIX文件系统中的metadata部分,实际的数据部分交由ceph集群中的OSD处理,mds提供了一个带智能缓存层的共享型连续文件系统,可以大大减少 OSD 读写操作频率。
cephfs元数据使用的动态子树分区,把元数据划分名称空间下对应到不同的mds,写入元数据的时候将元数据按照名称保存到不同主mds上,类似于nginx中的缓存目录分层。
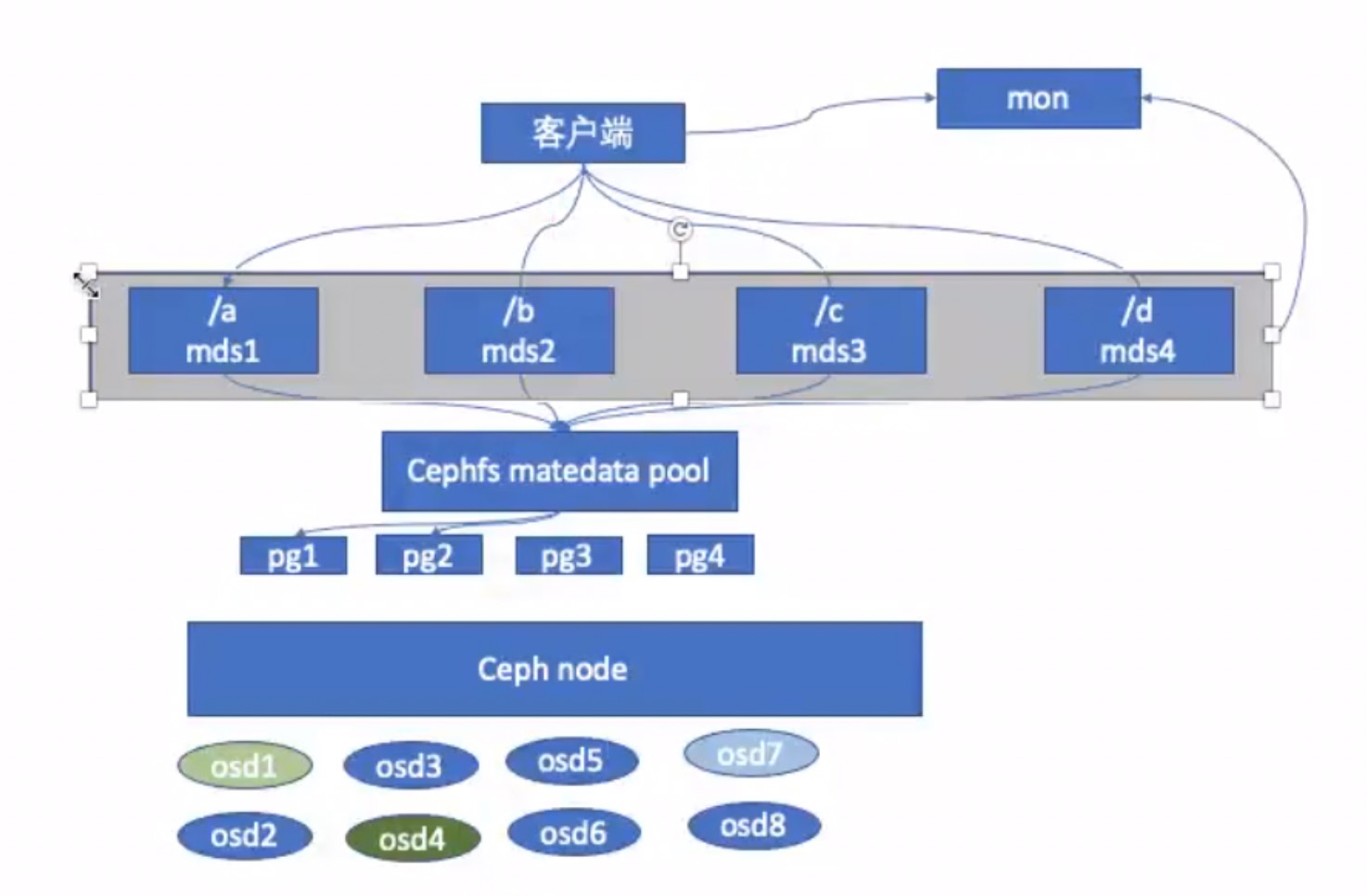
cephfs工作流程
- 创建cephfs时会指定两个存储池,一个专门来存储元数据,一个专门来存储实际文件;
- 客户端在写(读)文件时,首先写(读)mds服务缓存中文件的元数据信息,当然保存在mds的元数据最终还是要落盘到osd pool中的;
- mds和rados之间通过journal metadate交互,这个journal是记录文件写入日志的,这个也是存放到OSD当中;
- 最终客户端得到元数据信息,获取rados对某个文件的IO操作,实现文件读写。
cephfs状态查看
$ ceph fs status
cephfs - 0 clients
======
+------+----------------+----------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+----------------+----------+---------------+-------+-------+
| 0 | active | cephfs-a | Reqs: 0 /s | 30 | 25 |
| 0-s | standby-replay | cephfs-b | Evts: 0 /s | 24 | 17 |
+------+----------------+----------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 289k | 760G |
| cephfs-data0 | data | 805 | 760G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
+-------------+
$ ceph mds stat
cephfs:1 {0=cephfs-a=up:active} 1 up:standby-replay
cephfs使用演示
cephfs安装步骤已经通过上节部署文档中演示过,此处不再赘述,仅介绍本次演示所涉及到的pool名称:
$ ceph fs ls
name: cephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data0 ]
$ ceph osd lspools
cephfs-metadata #用来存放mds数据
cephfs-data0 #用来存放data数据
先通过第一种方法:以内核模块方式挂载(一般都用此种方式)
首先要确认内核模块是否加载
# lsmod | grep ceph
ceph 363016 0
libceph 306750 2 rbd,ceph
dns_resolver 13140 1 libceph
libcrc32c 12644 4 xfs,libceph,nf_nat,nf_conntrack
先创建用来专门挂载的ceph用户
## 创建 client.mfan 用户,并授权可读 MON、可读写mds 和 可读写执行名称cephfs-data0的OSD
$ ceph auth add client.mfan mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data0'
added key for client.mfan
## 输出密钥
$ ceph auth get client.mfan -o /etc/ceph/ceph.client.mfan.keyring
exported keyring for client.mfan
## 测试访问集群
$ ceph -s --user mfan
cluster:
id: f0a8789e-6d53-44fa-b76d-efa79bbebbcf
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 42h)
mgr: a(active, since 33h)
mds: cephfs:1 {0=cephfs-a=up:active} 1 up:standby-replay
osd: 1 osds: 1 up (since 42h), 1 in (since 44h)
rgw: 1 daemon active (my.store.a)
data:
pools: 10 pools, 200 pgs
objects: 719 objects, 1.3 GiB
usage: 55 GiB used, 803 GiB / 858 GiB avail
pgs: 200 active+clean
io:
client: 852 B/s rd, 1 op/s rd, 0 op/s wr
获取用户名和密钥
$ ceph auth get client.mfan
exported keyring for client.mfan
[client.mfan]
key = AQD600NibhPBJxAAzKeTOcQ17xaPhEdZ8npehg==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data0"
命令行挂载cephfs,有两种方式:
第一种:
## 挂载
# mount -t ceph 10.153.204.13:6789:/ /home/cephfs-data/ -o name=mfan,secret=AQD600NibhPBJxAAzKeTOcQ17xaPhEdZ8npehg==
参数说明:
-o:指定挂载参数
name:认证用户
secret:用户密钥
# df -h | grep 'ceph-data'
10.153.204.13:6789:/ 760G 0 760G 0% /home/cephfs-data
我这里只有一台mon,如果多台mon,可以并写如:10.153.204.13:6789,10.153.204.14:6789,10.153.204.15:6789:/
第二种:
## 创建用户secret文件
# ceph auth get-key client.mfan > /etc/ceph/mvfan.secret
## 使用secret文件挂载
# mount -t ceph 10.153.204.13:6789:/ /home/cephfs-data2/ -o name=mfan,secretfile=/etc/ceph/mvfan.secret
测试读写
## 测试写
# dd if=/dev/zero of=/home/ceph-data/test.dbf bs=8k count=200000 conv=fdatasync
200000+0 records in
200000+0 records out
1638400000 bytes (1.6 GB) copied, 4.93594 s, 332 MB/s
## 测试读
# dd if=/home/ceph-data/test.dbf of=/dev/null bs=4k count=100000000
400000+0 records in
400000+0 records out
1638400000 bytes (1.6 GB) copied, 1.18977 s, 1.4 GB/s
加入fstab中
echo "10.153.204.13:6789:/ /home/ceph-data ceph \
name=mfan,secret=AQD600NibhPBJxAAzKeTOcQ17xaPhEdZ8npehg==,_netdev,noatime 0 0" >> /etc/fstab
_netdev: 文件系统居于需要网络连接的设备上,系统联网时才挂载
noatime: 不更新文件系统的inode存取时间
再通过第二种方法:以fuse方式方式挂载
需要先安装ceph-fuse包
yum install -y ceph-fuse
执行挂载
# ceph-fuse -m 10.153.204.13:6789 /home/cephfs-data
ceph-fuse[9511]: starting ceph client2022-03-30T17:25:00.938+0800 7fc7431f7f80 -1 init, newargv = 0x55d4924a7b60 newargc=9
ceph-fuse[9511]: starting fuse
# ps -ef | grep fuse
root 9511 1 0 17:25 pts/1 00:00:00 ceph-fuse -m 10.153.204.13:6789 /home/cephfs-data
# df -Th | grep cephfs-data
ceph-fuse fuse.ceph-fuse 759G 2.2G 757G 1% /home/cephfs-data
卸载命令
fusermount -u /home/cephfs-data/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号