Kubernetes-2:Pod(k8s最小单元)概念及网络通讯方式
Pod概念及网络通讯方式
什么是Pod?
Pod是Kubernetes的最小单元。
一个Pod是一组紧密相关的容器,是一起运行在同一个工作节点上,以及同一个Linux命名空间中。每个Pod就像是一个独立的逻辑机器,拥有自己的IP、主机名、进程等,运行一个独立的应用程序。
Pod是逻辑主机,一个Pod中的所有的容器都运行在同一个逻辑机器上,其他Pod中的容器,即使运行在用一个工作节点上,也会出现在不同的节点上。即一个Pod包含多个容器时,那些容器总是运行在同一个工作节点上,一个Pod决不能跨多个工作节点
例如:
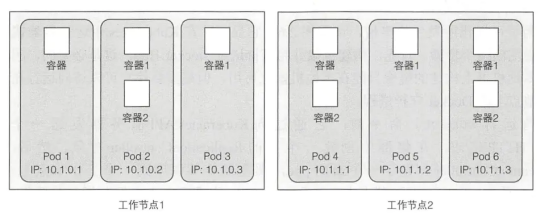
Pod和容器概念的区分
为什么k8s会使用Pod为最小单元,而不是Docker容器
1、更利于扩展
k8s不仅仅支持Docker容器,也支持rkt甚至用户自定义容器。Kubernetes不依赖于底层某一种具体的规则去实现容器技术,而是通过CRI这个抽象层操作容器,这样就会需要Pod这样一个东西,Pod内部再管理多个业务上紧密相关的用户业务容器,就会更有利用业务扩展Pod而不是容器。
2、更容易定义一组容器的状态
如果没有Pod,我们直接使用一组容器去跑一个业务,那么其中一个或若干个容器出现问题,我们如何去定义这一组容器的状态呢?通过Pod我们就很容易解决,一组业务容器跑在同一个Pod中,这个Pod会有一个pause容器,这个容器跟其他的业务容器都没有关系,以这个pause容器状态来代表Pod的状态。
3、利用容器间文件共享,以及通信
pause容器有一个IP地址和一个存储卷,Pod中的其他容器共享pause容器的IP地址和存储,这样就达到了文件共享和通信。
Pod与容器的区别:Pod是指一组容器,可以指多个或一个,容器只能代表一个。
Pod的类型
自主式Pod:指定调度到某节点,如节点down,Pod无法自动恢复
控制器管理的Pod:诸多控制器类型,看下边详解
控制器类型及作用
1、ReplicationController
用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来代替;而如果异常多出来的容易也会自动回收。在新版本的k8s中建议使用ReplicaSet来代替它
2、ReplicaSet
其跟ReplicationController没有什么本质区别,只是名字不一样,并且ReplicaSet支持集合式的selector(支持根据条件批量删除或创建)
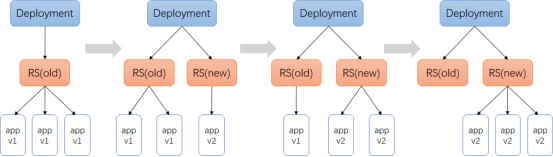
3、Deployment(推荐)
虽然ReplicaSet可以独立使用,但一般还是建议使用Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持rolling-update滚动更新但Deployment支持)
典型的应用场景包括:
定义Deployment来创建Pod和ReplicaSet
滚动升级和回滚应用
扩容和缩容
暂停和继续Deployment
滚动更新流程
4、HPA(HorizontalPodAutoScale)
Horizontal Pod AutoScaling 仅适用于Depolyment和ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩缩容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容
5、StatefullSet
StatefullSet是为了解决有状态服务的问题(对应Depolyment和ReplicaSets是为无状态服务而设计),其应用场景包括:
稳定的持久化储存,即Pod重新调度后还能访问到相同的持久化数据,基于PVC来实现
稳定的网络标志,即Pod重新调度其PodName和HostName不变,基于Headless Service(即没有Cluster IP 的 Service)来实现
有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候还要依据定义的顺序依次进行(即从0到N-1,在下一个Pod运行之前所有的Pod必须都是Running和Ready状态),基于init containers来实现
有序收缩,有序删除(从N-1到0)
6、DaemonSet
DaemonSet确保全部(或者一些)Node上运行一个Pod的副本。当有Node加入集群时,也会为它们新增一个Pod。当有Node从集群中移除时,这些Pod也会被回收。删除DaemonSet会删除它创建的所有Pod
典型用法:
运行集群存储daemon,例如在每个Node上运行glusterd、ceph
在每个Node上运行日志收集daemon,例如Logstash、Fluentd
在每个Node上运行监控daemon,例如Prometheus Node Exporter
7、Job、Cron Job(类似于Linux的at和crontab)
Job负责批处理任务,即仅执行一次任务,它保证批处理任务的一个或多个Pod成功结束
Cron Job管理基于时间的Job,即
在给定时间点仅运行一次
周期性的给定时间点运行
不同情况下网络通信方式
1、同一个Pod内部通讯:
>> 同一个Pod共享同一个网络命名空间(pause容器),同一个Linux协议栈
2、Pod1至Pod2
>> Pod1与Pod2不在同一台主机,Pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同的Node之间的通信只能通过宿主机的物理网卡进行,将Pod的IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问,使用的是Flannel网络规划服务如下图:
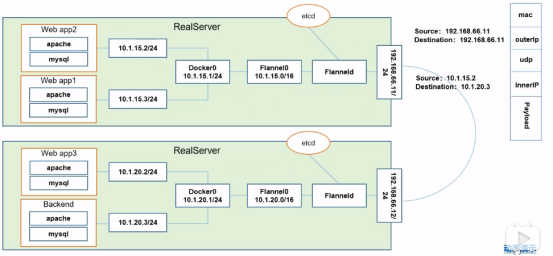
etcd在Flannel中的作用:
存储管理Flannel可分配的IP地址段资源
监控ETCD中每个Pod的实际地址,并在内存中建立维护Pod节点路由器
>> Pod1与Pod2在同一台机器中,由docker0网桥直接转发请求至Pod2
3、Pod至Service的网络
>> 目前基于性能考虑,全部用iptables(旧版本)和LVS(新版本)维护和转发
4、Pod到外网
>> Pod向外网发送请求,查找路由表,转发数据包到宿主机网卡,宿主机网卡完成路由选择后,iptables执行Masquerade(SNAT),把源地址更改为宿主机网卡地址,向外网发送请求
5、外网访问Pod
>> 通过Service网络,nodeport 类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号