
程序员编程艺术第三十六~三十七章、搜索智能提示suggestion,附近点搜索
第三十六~三十七章、搜索智能提示suggestion,附近地点搜索
作者:July。致谢:caopengcs、胡果果。
时间:二零一三年九月七日。
题记
写博的近三年,整理了太多太多的笔试面试题,如微软面试100题系列,和眼下这个程序员编程艺术系列,真心觉得题目年年变,但解决问题的方法永远都是那几种,用心准备后,自会发现一切有迹可循。
故为更好的帮助人们找到工作,特准备在北京举办一系列面试&算法讲座。时间定为周末,每次一个上午或下午,受众对象为要找工作或换工作或对算法感兴趣的朋友,费用前期暂愿交就交,交多少全由自己决定。主讲人:我和目前zoj排名第一的caopengcs博士。9月15日为第1次讲座:http://weibo.com/1580904460/A8N6oAFZ4?mod=weibotime。
OK,切入正题。上面说整理过很多笔试面试题,但好的笔试面试题真心难求,包括在编程艺术系列每一章的选题,越到后面越难挑,而本文写两个跟实际挂钩的问题,它们来自此文http://blog.csdn.net/v_july_v/article/details/7974418 的第3.6题,和第87题,即
- 第三十六章、搜索引擎中中的关键词智能提示suggestion;
- 第三十七章、附近地点的搜索;
第三十六章、搜索关键词智能提示suggestion
请问,如何设计此系统,使得空间和时间复杂度尽量低。
题目分析:本题来源于去年2012年百度的一套实习生笔试题中的系统设计题(为尊重愿题,本章主要使用百度搜索引擎展开论述,而不是google等其它搜索引擎,但原理不会差太多。然脱离本题,平时搜的时候,鼓励用...),题目比较开放,考察的目的在于看应聘者解决问题的思路是否清晰明确,其次便是看能考虑到多少细节。
- 直接上Trie树「Trie树的介绍见:从Trie树(字典树)谈到后缀树」 + TOP K「hashmap+堆,hashmap+堆 统计出如10个近似的热词,也就是说,只存与关键词近似的比如10个热词」
解法一、Trie树 + TOP K
步骤一、trie树存储前缀后缀
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
1.2、树的构建
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
现在回到例子中,如果我们用最傻的方法,对于每一个单词,我们都要去查找它前面的单词中是否有它。那么这个算法的复杂度就是O(n^2)。显然对于100000的范围难以接受。现在我们换个思路想。假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
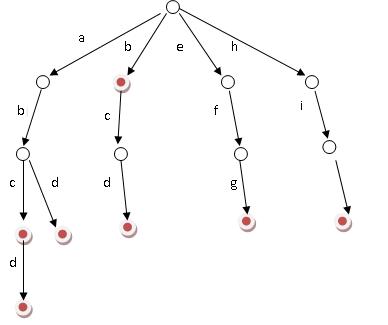
ok,如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。”
步骤二、TOP K算法统计热词
当每个搜索引擎输入一个前缀时,下面它只会展示0~10个候选词,但若是碰到那种候选词很多的时候,如何取舍,哪些展示在前面,哪些展示在后面?这就是一个搜索热度的问题。
如本题描述所说,在去年的这个时候,当我在搜索框内搜索“北京”时,它下面会提示以“北京”为前缀的诸如“北京爱情故事”,“北京公交”,“北京医院”,且“ 北京爱情故事”展示在第一个:
为何输入“北京”,会首先提示“北京爱情故事”呢?因为去年的这个时候,正是《北京爱情故事》这部电影上映正火的时候(其上映日期为2012年1月8日,火了至少一年),那个时候大家都一个劲的搜索这部电影的相关信息,当10个人中输入“北京”后,其中有8个人会继续敲入“爱情故事”(连起来就是“北京爱情故事”)的时候,搜索引擎对此当然不会无动于衷。
也就是说,搜索引擎知道了这个时间段,大家都在疯狂查找北京爱情故事,故当用户输入以“北京”为前缀的时候,搜索引擎猜测用户有80%的机率是要查找“北京爱情故事”,故把“北京爱情故事”在下面提示出来,并放在第一个位置上。
但为何今年这个时候再次搜索“北京”的时候,它展示出来的词不同了呢?
原因在于随着时间变化,人们对北京爱情故事这部影片的关注度逐渐下降,与此同时,又出现了新的热词,新的电影,故现在虽然同样是输入“北京”,后面提示的词也相应跟着起了变化。那解决这个问题的办法是什么呢?如开头所说:定期分析某段时间内的人们搜索的关键词,统计出搜索次数比较多的热词,继而当用户输入某个前缀时,优先展示热词。
故说白了,这个问题的第二个步骤便是统计热词,我们把统计热词的方法称为TOP K算法,此算法的应用场景便是此文http://blog.csdn.net/v_july_v/article/details/7382693中的第2个问题,再次原文引用:
“寻找热门查询,300万个查询字符串中统计最热门的10个查询
原题:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
解答:由上面第1题,我们知道,数据大则划为小的,如一亿个Ip求Top 10,可先%1000将ip分到1000个小文件中去,并保证一种ip只出现在一个文件中,再对每个小文件中的ip进行hashmap计数统计并按数量排序,最后归并或者最小堆依次处理每个小文件的top10以得到最后的结果。
但如果数据规模本身就比较小,能一次性装入内存呢?比如这第2题,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去(300万个字符串假设没有重复,都是最大长度,那么最多占用内存3M*1K/4=0.75G。所以可以将所有字符串都存放在内存中进行处理),而现在只是需要一个合适的数据结构,在这里,HashTable绝对是我们优先的选择。
所以我们放弃分而治之/hash映射的步骤,直接上hash统计,然后排序。So,针对此类典型的TOP K问题,采取的对策往往是:hashmap + 堆。如下所示:
- hashmap统计:先对这批海量数据预处理。具体方法是:维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内用Hash表完成了统计;
- 堆排序:第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是:O(N) + N' * O(logK),(N为1000万,N’为300万)。
别忘了这篇文章中所述的堆排序思路:‘维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(x入堆,用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。’--第三章续、Top K算法问题的实现。
当然,你也可以采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。”
相信,如此,也就不难理解开头所提出的方法了:Trie树+ TOP K「hashmap+堆,hashmap+堆 统计出如10个近似的热词,也就是说,只存与关键词近似的比如10个热词」。
而且你以后就可以告诉你身边的伙伴们,为何输入“结构之”,会提示出来一堆以“结构之”为前缀的词拉:
方法貌似成型了,但有哪些需要注意的细节呢?如@江申_Johnson所说:“实际工作里,比如当前缀很短的时候,候选词很多的时候,查询和排序性能可能有问题,也许可以加一层索引trie(这层索引可以只索引频率高于某一个阈值的词,很短的时候查这个就可以了。数量不够的话再去查索引了全部词的trie树);而且有时候不能根据query频率来排,而要引导用户输入信息量更全面的query,或者或不仅仅是前缀匹配这么简单。”
扩展阅读
除了上文提到的trie树,三叉树或许也是一个不错的解决方案:http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/。此外,StackOverflow上也有两个讨论帖子,大家可以看看:①http://stackoverflow.com/questions/2901831/algorithm-for-autocomplete,②http://stackoverflow.com/questions/1783652/what-is-the-best-autocomplete-suggest-algorithm-datastructure-c-c。
第三十七章、附近地点搜索
题目详情:找一个点集中与给定点距离最近的点,同时,给定的二维点集都是固定的,查询可能有很多次,时间复杂度O(n)无法接受,请设计数据结构和相应的算法。
题目分析:此题是去年微软的三面题,类似于一朋友@陈利人 出的这题:附近地点搜索,就是搜索用户附近有哪些地点。随着GPS和带有GPS功能的移动设备的普及,附近地点搜索也变得炙手可热。在庞大的地理数据库中搜索地点,索引是很重要的。但是,我们的需求是搜索附近地点,例如,坐标(39.91, 116.37)附近500米内有什么餐馆,那么让你来设计,该怎么做?
解法一、R树二维搜索
假定只允许你初中数学知识,那么你可能建一个X-Y坐标系,即以坐标(39.91, 116.37)为圆心,以500的长度为半径,画一个园,然后一个一个坐标点的去查找。此法看似可行,但复杂度可想而知,即便你自以为聪明的说把整个平面划分为四个象限,一个一个象限的查找,此举虽然优化程度不够,但也说明你一步步想到点子上去了。
即不一个一个坐标点的查找,而是一个一个区域的查找,相对来说,其平均查找速度和效率会显著提升。如此,便自然而然的想到了有没有一种一次查找定位于一个区域的数据结构呢?
若看过博客内之前介绍R树的这篇文章http://blog.csdn.net/v_JULY_v/article/details/6530142#t2 的读者立马便能意识到,R树就是解决这个区域查找继而不断缩小规模的问题。特直接引用原文:
“R树的数据结构
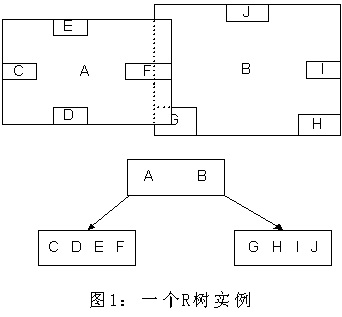
R树是B树在高维空间的扩展,是一棵平衡树。每个R树的叶子结点包含了多个指向不同数据的指针,这些数据可以是存放在硬盘中的,也可以是存在内存中。根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。这种方式使我们不必遍历所有数据即可获得答案,效率显著提高。下图1是R树的一个简单实例:
我们在上面说过,R树运用了空间分割的理念,这种理念是如何实现的呢?R树采用了一种称为MBR(Minimal Bounding Rectangle)的方法,在此我把它译作“最小边界矩形”。从叶子结点开始用矩形(rectangle)将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割。有点不懂?没关系,继续往下看。在这里我还想提一下,R树中的R应该代表的是Rectangle(此处参考wikipedia上关于R树的介绍),而不是大多数国内教材中所说的Region(很多书把R树称为区域树,这是有误的)。我们就拿二维空间来举例。下图是Guttman论文中的一幅图:
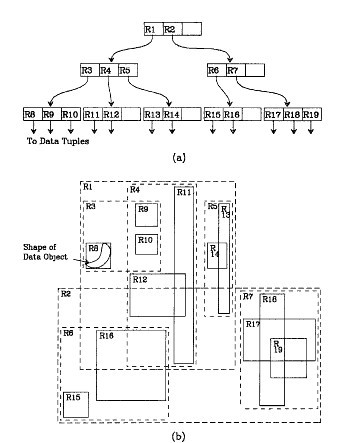
我来详细解释一下这张图。
- 先来看图(b),首先我们假设所有数据都是二维空间下的点,图中仅仅标志了R8区域中的数据,也就是那个shape of data object。别把那一块不规则图形看成一个数据,我们把它看作是多个数据围成的一个区域。为了实现R树结构,我们用一个最小边界矩形恰好框住这个不规则区域,这样,我们就构造出了一个区域:R8。R8的特点很明显,就是正正好好框住所有在此区域中的数据。
- 其他实线包围住的区域,如R9,R10,R12等都是同样的道理。这样一来,我们一共得到了12个最最基本的最小矩形。这些矩形都将被存储在子结点中。
- 下一步操作就是进行高一层次的处理。我们发现R8,R9,R10三个矩形距离最为靠近,因此就可以用一个更大的矩形R3恰好框住这3个矩形。
- 同样道理,R15,R16被R6恰好框住,R11,R12被R4恰好框住,等等。所有最基本的最小边界矩形被框入更大的矩形中之后,再次迭代,用更大的框去框住这些矩形。
我想大家都应该理解这个数据结构的特征了。用地图的例子来解释,就是所有的数据都是餐厅所对应的地点,先把相邻的餐厅划分到同一块区域,划分好所有餐厅之后,再把邻近的区域划分到更大的区域,划分完毕后再次进行更高层次的划分,直到划分到只剩下两个最大的区域为止。要查找的时候就方便了。
下面就可以把这些大大小小的矩形存入我们的R树中去了。根结点存放的是两个最大的矩形,这两个最大的矩形框住了所有的剩余的矩形,当然也就框住了所有的数据。下一层的结点存放了次大的矩形,这些矩形缩小了范围。每个叶子结点都是存放的最小的矩形,这些矩形中可能包含有n个数据。
地图查找的实例
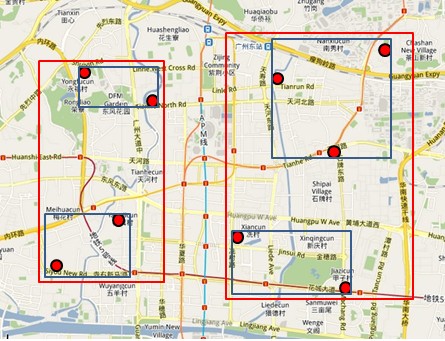
讲完了基本的数据结构,我们来讲个实例,如何查询特定的数据。又以餐厅为例,假设我要查询广州市天河区天河城附近一公里的所有餐厅地址怎么办?
- 打开地图(也就是整个R树),先选择国内还是国外(也就是根结点);
- 然后选择华南地区(对应第一层结点),选择广州市(对应第二层结点),
- 再选择天河区(对应第三层结点);
- 最后选择天河城所在的那个区域(对应叶子结点,存放有最小矩形);
遍历所有在此区域内的结点,看是否满足我们的要求即可。怎么样,其实R树的查找规则跟查地图很像吧?对应下图:
一棵R树满足如下的性质:
- 除非它是根结点之外,所有叶子结点包含有m至M个记录索引(条目)。作为根结点的叶子结点所具有的记录个数可以少于m。通常,m=M/2。
- 对于所有在叶子中存储的记录(条目),I是最小的可以在空间中完全覆盖这些记录所代表的点的矩形(注意:此处所说的“矩形”是可以扩展到高维空间的)。
- 每一个非叶子结点拥有m至M个孩子结点,除非它是根结点。
- 对于在非叶子结点上的每一个条目,i是最小的可以在空间上完全覆盖这些条目所代表的店的矩形(同性质2)。
- 所有叶子结点都位于同一层,因此R树为平衡树。
叶子结点的结构
先来探究一下叶子结点的结构。叶子结点所保存的数据形式为:(I, tuple-identifier)。
其中,tuple-identifier表示的是一个存放于数据库中的tuple,也就是一条记录,它是n维的。I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。I=(I0,I1,…,In-1)。其结构如下图所示:

下图描述的就是在二维空间中的叶子结点所要存储的信息。
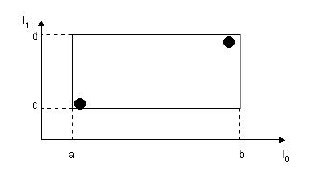
在这张图中,I所代表的就是图中的矩形,其范围是a<=I0<=b,c<=I1<=d。有两个tuple-identifier,在图中即表示为那两个点。这种形式完全可以推广到高维空间。大家简单想想三维空间中的样子就可以了。这样,叶子结点的结构就介绍完了。
非叶子结点
非叶子结点的结构其实与叶子结点非常类似。想象一下B树就知道了,B树的叶子结点存放的是真实存在的数据,而非叶子结点存放的是这些数据的“边界”,或者说也算是一种索引(有疑问的读者可以回顾一下上述第一节中讲解B树的部分)。
同样道理,R树的非叶子结点存放的数据结构为:(I, child-pointer)。
其中,child-pointer是指向孩子结点的指针,I是覆盖所有孩子结点对应矩形的矩形。这边有点拗口,但我想不是很难懂?给张图:
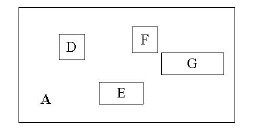
D,E,F,G为孩子结点所对应的矩形。A为能够覆盖这些矩形的更大的矩形。这个A就是这个非叶子结点所对应的矩形。这时候你应该悟到了吧?无论是叶子结点还是非叶子结点,它们都对应着一个矩形。树形结构上层的结点所对应的矩形能够完全覆盖它的孩子结点所对应的矩形。根结点也唯一对应一个矩形,而这个矩形是可以覆盖所有我们拥有的数据信息在空间中代表的点的。
我个人感觉这张图画的不那么精确,应该是矩形A要恰好覆盖D,E,F,G,而不应该再留出这么多没用的空间了。但为尊重原图的绘制者,特不作修改。”
但R树有些什么问题呢?如@宋枭_CD所说:“单纯用R树来作索引,搜索附近的地点,可能会遍历树的很多个分支。而且当全国的地图或者全省的地图时候,树的叶节点数目很多,树的深度也会是一个问题。一般会把地理位置上附近的节点(二维地图中点线面)预处理成page(大小为4K的倍数),在这些page上建立R树的索引。”
解法二、GeoHash算法索引地理位置信息
我在微博上跟一些朋友讨论这个附近点搜索的问题时,除了谈到R树,有几个朋友都指出GeoHash算法可以解决,故才了解了下GeoHash算法,此文http://blog.nosqlfan.com/html/1811.html 清晰阐述了MongoDB借助GeoHash算法实现地理位置索引的原理,特引用其内容加以说明,如下:
“支持地理位置索引是MongoDB的一大亮点,这也是全球最流行的LBS服务foursquare 选择MongoDB的原因之一。我们知道,通常的数据库索引结构是B+ Tree,如何将地理位置转化为可建立B+Tree的形式。首先假设我们将需要索引的整个地图分成16×16的方格,如下图(左下角为坐标0,0 右上角为坐标16,16):
单纯的[x,y]的数据是无法建立索引的,所以MongoDB在建立索引的时候,会根据相应字段的坐标计算一个可以用来做索引的hash值,这个值叫做geohash,下面我们以地图上坐标为[4,6]的点(图中红叉位置)为例。我们第一步将整个地图分成等大小的四块,如下图:
划分成四块后我们可以定义这四块的值,如下(左下为00,左上为01,右下为10,右上为11):
db.map.ensureIndex({point : "2d"}, {min : 0, max : 16, bits : 4})本章完。
参考链接及推荐阅读
- 2012年九月十月笔试面试八十题:http://blog.csdn.net/v_july_v/article/details/7974418;
- 从Trie树(字典树)谈到后缀树:http://blog.csdn.net/v_july_v/article/details/6897097;
- 教你如何迅速秒杀掉:99%的海量数据处理面试题:http://blog.csdn.net/v_july_v/article/details/7382693;
- 从B树、B+树、B*树谈到R树:http://blog.csdn.net/v_july_v/article/details/6530142;
- 图解 MongoDB 地理位置索引的实现原理:http://blog.nosqlfan.com/html/1811.html;
- 《Hbase实战》第8章、在HBase上查询地理信息系统;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号