

程序员编程艺术(算法卷):第十章、如何给10^7个数据量的磁盘文件排序
第十章、如何给10^7个数据量的磁盘文件排序
作者:July,yansha,5,编程艺术室。
出处:http://blog.csdn.net/v_JULY_v 。
前奏
经过几天的痛苦沉思,最终决定,把原程序员面试题狂想曲系列正式更名为程序员编程艺术系列,同时,狂想曲创作组更名为编程艺术室。之所以要改名,我们考虑到三点:1、为面试服务不能成为我们最终或最主要的目的,2、我更愿把解答一道道面试题,ACM题等各类程序设计题目的过程,当做一种艺术来看待,3、艺术的提炼本身是一个非常非常艰难的过程,但我们乐意接受这个挑战。
同时,本系列程序编程艺术-算法卷,大致分为三个部分:第一部分--程序设计,大凡如面试题目,ACM题目,研究生复试上机的题目,poj的题目,只要是好的,值得设计或深究的题目,我们都不拒绝。第二部分--算法研究,主要以我个人此前写的原创作品-十三个经典算法研究系列为题材,力争通俗易懂,详略得当的剖析各类经典的算法,并予以编程实现。第三部分--编码素养,主要包括程序员编码过程中一些编码规范等各类及其需要注意的问题。
如果有可能的话,此TAOPP系列将采取TAOCP那样的形式,出第一卷、第二卷、...。编程艺术来自哪里?编程采取合适的数据结构?寻求更高效的算法?或者,好的编码规范?希望,本TAOPP系列最终能给你一个完整的答复。
ok,如果任何人对本编程艺术系列有任何意见,或发现了本编程艺术系列任何问题,漏洞,bug,欢迎随时提出,我们将虚心接受并感激不尽,以为他人创造更好的价值,更好的服务。
第一节、如何给磁盘文件排序
问题描述:
输入:一个最多含有n个不相同的正整数的文件,其中每个数都小于等于n,且n=10^7。
输出:得到按从小到大升序排列的包含所有输入的整数的列表。
条件:最多有大约1MB的内存空间可用,但磁盘空间足够。且要求运行时间在5分钟以下,10秒为最佳结果。
分析:下面咱们来一步一步的解决这个问题,
1、归并排序。你可能会想到把磁盘文件进行归并排序,但题目要求中,你只有1MB的内存空间可用,所以,归并排序这个方法不行。
2、位图方案。熟悉位图的朋友可能会想到用位图来表示这个文件集合。例如正如编程珠玑一书上所述,用一个20位长的字符串来表示一个所有元素都小于20的简单的非负整数集合,边框用如下字符串来表示集合{1,2,3,5,8,13}:
0 1 1 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0
上述集合中各数对应的位置则置1,没有对应的数的位置则置0。
参考编程珠玑一书上的位图方案,针对我们的10^7个数据量的磁盘文件排序问题,我们可以这么考虑,由于每个7位十进制整数表示一个小于1000万的整数。我们可以使用一个具有1000万个位的字符串来表示这个文件,其中,当且仅当整数i在文件中存在时,第i位为1。采取这个位图的方案是因为我们面对的这个问题的特殊性:1、输入数据限制在相对较小的范围内,2、数据没有重复,3、其中的每条记录都是单一的整数,没有任何其它与之关联的数据。
所以,此问题用位图的方案分为以下三步进行解决:
- 第一步,将所有的位都置为0,从而将集合初始化为空。
- 第二步,通过读入文件中的每个整数来建立集合,将每个对应的位都置为1。
- 第三步,检验每一位,如果该位为1,就输出对应的整数。
经过以上三步后,产生有序的输出文件。令n为位图向量中的位数(本例中为1000 0000),程序可以用伪代码表示如下:
不过很快,我们就将意识到,用此位图方法,严格说来还是不太行,空间消耗10^7/8还是大于1M(1M=1024*1024空间,小于10^7/8)。
既然如果用位图方案的话,我们需要约1.25MB(若每条记录是8位的正整数的话,则10000000/(1024*1024*8) ~= 1.2M)的空间,而现在只有1MB的可用存储空间,那么究竟该作何处理呢?
3、多路归并。把这个文件分为若干大小的几块,然后分别对每一块进行排序,最后完成整个过程的排序。k趟算法可以在kn的时间开销内和n/k的空间开销内完成对最多n个小于n的无重复正整数的排序。比如可分为2块(k=2,1趟反正占用的内存只有1.25/2M),1~4999999,和5000000~9999999先遍历一趟,处理1~4999999的数据块(用5000000/8=625000个字的存储空间来排序0~4999999之间的整数),然后再第二趟,对5000001~1000000这一数据块处理。
4、读者思考。经过上述思路3的方案之后,现在有两个局部有序的数组了,那么要得到一个完整的排序的数组,接下来改怎么做呢?或者说,如果是K路归并,得到k个排序的子数组,把他们合并成一个完整的排序数组,如何优化?或者,我再问你一个问题,K路归并用败者树 和 胜者树 效率有什么差别?这些问题,请读者思考。
第二节、多路归并算法的c++实现
在此之前,你还得了解归并排序的过程,因为下面的多路归并算法就是基于这个流程的。其实归并排序就是2路归并,而多路归并算法就是把2换成了k,即多(k)路归并。下面,举个例子来说明下此归并排序算法,如下图所示,我们对数组8 3 2 6 7 1 5 4进行归并排序:

好的,由第一节,我们已经知道,当数据量大到不适合在内存中排序时,可以利用多路归并算法对磁盘文件进行排序。
我们以一个包含很多个整数的大文件为例,来说明多路归并的外排序算法基本思想。假设文件中整数个数为N(N是亿级的),整数之间用空格分开。首先分多次从该文件中读取M(十万级)个整数,每次将M个文件在内存中使用快排序之后存入临时文件,然后使用多路归并将临时文件中的数据牌号序存入输出文件。显然,该排序算法需要对每个整数做2次磁盘读和2次磁盘写。以下是本程序的流程图:
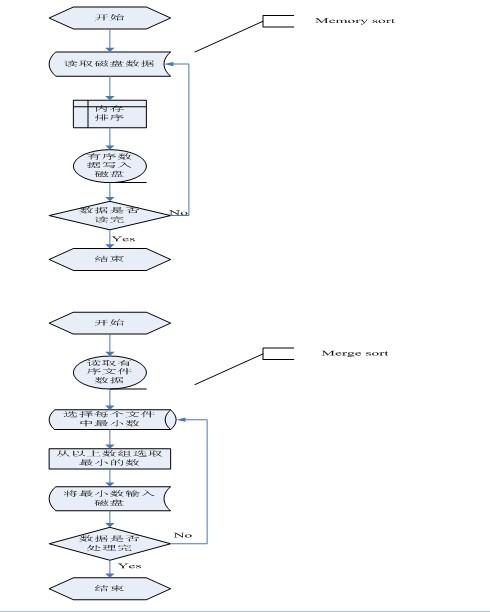
本程序是基于以上思想对包含大量整数文件的从小到大排序的一个简单实现,这里没有使用内存缓冲区,在归并时简单使用一个数组来存储每个临时文件的第一个元素。下面是多路归并排序算法的c++实现代码(在第四节,将给出多路归并算法的c实现):
程序测试:读者可以继续用小文件小数据量进一步测试。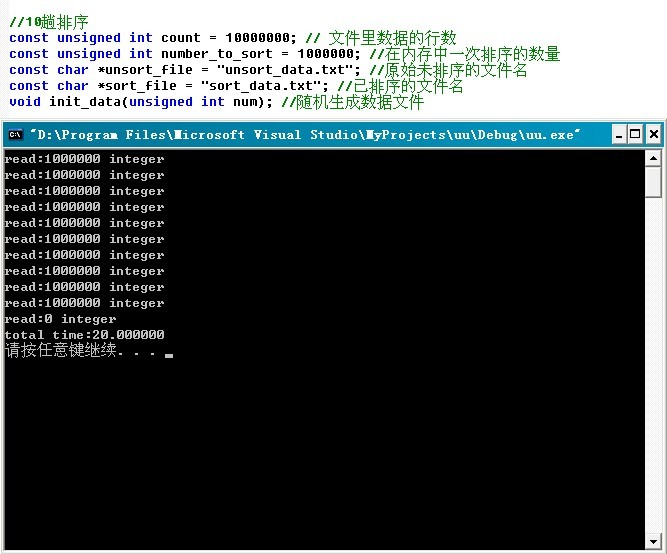
第三节、磁盘文件排序的编程实现
下面,我们来编程实现上述磁盘文件排序的问题,本程序由两部分构成:
1、内存排序
由于要求的可用内存为1MB,那么每次可以在内存中对250K的数据进行排序,然后将有序的数写入硬盘。
那么10M的数据需要循环40次,最终产生40个有序的文件。
2、归并排序
- 将每个文件最开始的数读入(由于有序,所以为该文件最小数),存放在一个大小为40的first_data数组中;
- 选择first_data数组中最小的数min_data,及其对应的文件索引index;
- 将first_data数组中最小的数写入文件result,然后更新数组first_data(根据index读取该文件下一个数代替min_data);
- 判断是否所有数据都读取完毕,否则返回2。
完整代码如下:
其中,生成数据文件data.txt的代码如下:
程序测试:
1、咱们对1000W数据进行测试,打开半天没看到数据,
2、编译运行上述程序后,data文件先被分成40个小文件data[1....40],然后程序再对这40个小文件进行归并排序,排序结果最终生成在result文件中,自此result文件中便是由data文件的数据经排序后得到的数据。
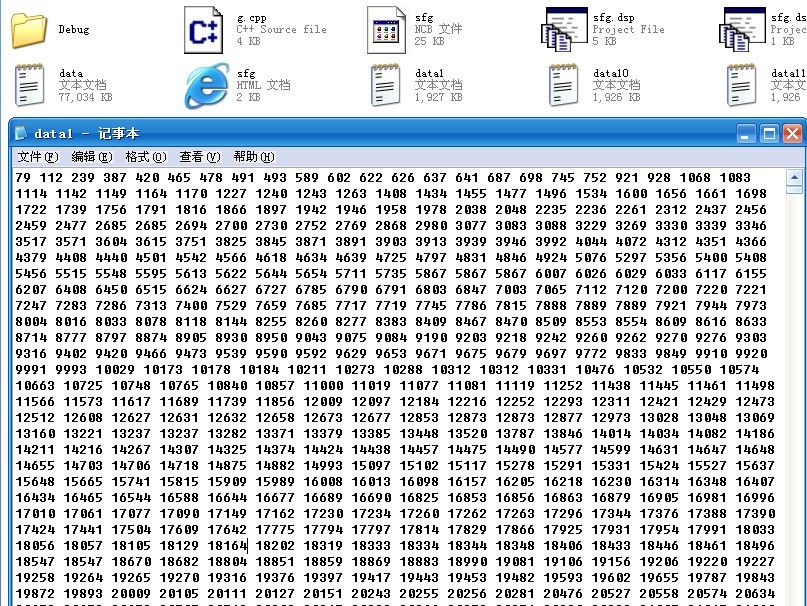
3、且,我们能看到,data[i],i=1...40的每个文件都是有序的,如下图:
4、最终的运行结果,如下:

updated:
再次对上述程序进行测试后,发现了问题,比如对20个数进行5路归并排序,如下,在result文件里头少了data原来存在的数据19,具体解决方案,待续。


程序修正:
我们不在乎是否能把一个软件产品或一本书最终完成,我们更在乎的是,在完成这个产品或创作这本书的过程中,读者学到了什么,能学到什么?所以,不要一味的马上就想得到一道题目的正确答案,请跟着我们一起逐步走向山巅。
通过上面的20个数的测试,我们已经知道,问题出在这段代码中(原因已在代码注释中给出):
根据上面的问题,我们应该对上段代码作如下修改,以保证程序完全准确:
最终,程序才得以正确,同样还是采取20个数的5路归并测试(读者可以进一步测试):
补遗:
同时,还发现了一个小问题,就是同样是利用随机生成数据函数srand((unsigned)time(NULL)); 当要随机产生很大的数据量时,文件中的数据是不重复的,而当要产生20个小数据量的文件时,去发现如上面的数据那般,产生了重复数据。这个问题,一直不得其解。待时间考证。
第四节、多路归并算法的c实现
本多路归并算法的c实现原理与上述c++实现一致,不同的地方体现在一些细节处理上,且对临时文件的排序,不再用系统提供的快排,即上面的qsort库函数,是采用的三数中值的快速排序(个数小于3用插入排序)的。而我们知道,纯正的归并排序其实就是比较排序,在归并过程中总是不断的比较,为了从两个数中挑小的归并到最终的序列中。ok,此程序的详情请看:
程序测试:
在此,我们先测试下对10000000个数据的文件进行40趟排序,然后再对100个数据的文件进行4趟排序(读者可进一步测试)。如弄几组小点的数据,输出ID和数据到屏幕,再看程序运行效果。
- 10个数, 4组
- 40个数, 5组
- 55个数, 6组
- 100个数, 7组


(备注:1、以上所有各节的程序运行环境为windows xp + vc6.0 + e5200 cpu 2.5g主频,2、感谢5为本文程序所作的大量测试工作)
本章完。
版权所有,本人对本blog内所有任何内容享有版权及著作权。网络转载,请以链接形式注明出处。

