

程序员编程艺术:第三章续、Top K算法问题的实现
程序员编程艺术:第三章续、Top K算法问题的实现
作者:July,zhouzhenren,yansha。
致谢:微软100题实现组,狂想曲创作组。
时间:2011年05月08日
微博:http://weibo.com/julyweibo 。
出处:http://blog.csdn.net/v_JULY_v 。
wiki:http://tctop.wikispaces.com/。
-----------------------------------------------
前奏
在上一篇文章,程序员面试题狂想曲:第三章、寻找最小的k个数中,后来为了论证类似快速排序中partition的方法在最坏情况下,能在O(N)的时间复杂度内找到最小的k个数,而前前后后updated了10余次。所谓功夫不负苦心人,终于得到了一个想要的结果。
简单总结如下(详情,请参考原文第三章):
1、RANDOMIZED-SELECT,以序列中随机选取一个元素作为主元,可达到线性期望时间O(N)的复杂度。
2、SELECT,快速选择算法,以序列中“五分化中项的中项”,或“中位数的中位数”作为主元(枢纽元),则不容置疑的可保证在最坏情况下亦为O(N)的复杂度。
本章,咱们来阐述寻找最小的k个数的反面,即寻找最大的k个数,但此刻可能就有读者质疑了,寻找最大的k个数和寻找最小的k个数,原理不是一样的么?
是的,的确是一样,但这个寻找最大的k个数的问题的实用范围更广,因为它牵扯到了一个Top K算法问题,以及有关搜索引擎,海量数据处理等广泛的问题,所以本文特意对这个Top K算法问题,进行阐述以及实现(侧重实现,因为那样看起来,会更令人激动人心),算是第三章的续。ok,有任何问题,欢迎随时不吝指正。谢谢。
说明
关于寻找最小K个数能做到最坏情况下为O(N)的算法及证明,请参考原第三章,寻找最小的k个数,本文的代码不保证O(N)的平均时间复杂度,只是根据第三章有办法可以做到而已(如上面总结的,2、SELECT,快速选择算法,以序列中“五分化中项的中项”,或“中位数的中位数”作为主元或枢纽元的方法,原第三章已经严格论证并得到结果)。
第一节、寻找最小的第k个数
在进入寻找最大的k个数的主题之前,先补充下关于寻找最k小的数的三种简单实现。由于堆的完整实现,第三章:第五节,堆结构实现,处理海量数据中已经给出,下面主要给出类似快速排序中partition过程的代码实现:
寻找最小的k个数,实现一:
寻找最小的第k个数,实现二:
寻找最小的第k个数,实现三:
测试:
The average time of searching a date in the array size of 5000 is 0
The average time of searching a date in the array size of 50000 is 1
The average time of searching a date in the array size of 500000 is 12
The average time of searching a date in the array size of 5000000 is 114
The average time of searching a date in the array size of 50000000 is 1159
Press any key to continue
通过测试这个程序,我们竟发现这个程序的运行时间是线性的?
或许,你还没有意识到这个问题,ok,听我慢慢道来。
我们之前说,要保证这个算法是线性的,就一定要在枢纽元的选取上下足功夫:
1、要么是随机选取枢纽元作为划分元素
2、要么是取中位数的中位数作为枢纽元划分元素
现在,这程序直接选取了数组中第一个元素作为枢纽元
竟然,也能做到线性O(N)的复杂度,这不是自相矛盾么?
你觉得这个程序的运行时间是线性O(N),是巧合还是确定会是如此?哈哈,且看1、@well:根据上面的运行结果不能判断线性,如果人家是O(n^1.1) 也有可能啊,而且部分数据始终是拟合,还是要数学证明才可靠。2、@July:同时,随机数组中选取一个元素作为枢纽元!=> 随机数组中随机选取一个元素作为枢纽元(如果是随机选取随机数组中的一个元素作为主元,那就不同了,跟随机选取数组中一个元素作为枢纽元一样了)。3、@飞羽:正是因为数组本身是随机的,所以选择第一个元素和随机选择其它的数是等价的(由等概率产生保证),这第3点,我与飞羽有分歧,至于谁对谁错,待时间让我考证。
关于上面第3点我和飞羽的分歧,在我们进一步讨论之后,一致认定(不过,相信,你看到了上面程序更新的注释之后,你应该有几分领会了):
- 我们说输入一个数组的元素,不按其顺序输入:如,1,2,3,4,5,6,7,而是这样输入:5,7,6,4,3,1,2,这就叫随机输入,而这种情况就相当于上述程序主函数中所产生的随机数组。然而选取随机输入的数组或随机数组中第一个元素作为主元,我们不能称之为说是随机选取枢纽元。
- 因为,随机数产生器产生的数据是随机的,没错,但你要知道,你总是选取随机数组的第一个元素作为枢纽元,这不叫随机选取枢纽元。
- 所以,上述程序的主函数中随机产生的数组对这个程序的算法而言,没有任何意义,就是帮忙产生了一个随机数组,帮助我们完成了测试,且方便我们测试大数据量而已,就这么简单。
- 且一般来说,我们看一个程序的 时间复杂度,是不考虑 其输入情况的,即不考虑主函数,正如这个 kth number 的程序所见,你每次都是随机选取数组中第一个元素作为枢纽元,而并不是随机选择枢纽元,所以,做不到平均时间复杂度为O(N)。
所以:想要保证此快速选择算法为O(N)的复杂度,只有两种途径,那就是保证划分的枢纽元元素的选取是:
1、随机的(注,此枢纽元随机不等同于数组随机)
2、五分化中项的中项,或中位数的中位数。所以,虽然咱们对于一切心知肚明,但上面程序的运行结果说明不了任何问题,这也从侧面再次佐证了咱们第三章中观点的正确无误性。
updated:
非常感谢飞羽等人的工作,将上述三个版本综合到了一起(待进一步测试):
说明:@飞羽:因为预先设定了K,经过分割算法后,数组肯定被划分为array[0...k-1]和array[k...length-1],注意到经过Select_K_Version操作后,数组是被不断地分割的,使得比array[k-1]的元素小的全在左边,题目要求的是最小的K个元素,当然也就是array[0...k-1],所以输出的结果就是前k个最小的数:
7 8 9 54 6 4 11 1 2 33
4 1 2 6 7 8 9 11 33
7 6 4 1 2 8 9 11 33
7 8 9 6 4 11 1 2 33
Press any key to continue
(更多,请参见:此狂想曲系列tctop修订wiki页面:http://tctop.wikispaces.com/)
第二节、寻找最大的k个数
把之前第三章的问题,改几个字,即成为寻找最大的k个数的问题了,如下所述:
查找最大的k个元素
题目描述:输入n个整数,输出其中最大的k个。
例如输入1,2,3,4,5,6,7和8这8个数字,则最大的4个数字为8,7,6和5。
分析:由于寻找最大的k个数的问题与之前的寻找最小的k个数的问题,本质是一样的,所以,这里就简单阐述下思路,ok,考验你举一反三能力的时间到了:
1、排序,快速排序。我们知道,快速排序平均所费时间为n*logn,从小到大排序这n个数,然后再遍历序列中后k个元素输出,即可,总的时间复杂度为O(n*logn+k)=O(n*logn)。
2、排序,选择排序。用选择或交换排序,即遍历n个数,先把最先遍历到得k个数存入大小为k的数组之中,对这k个数,利用选择或交换排序,找到k个数中的最小数kmin(kmin设为k个元素的数组中最小元素),用时O(k)(你应该知道,插入或选择排序查找操作需要O(k)的时间),后再继续遍历后n-k个数,x与kmin比较:如果x>kmin,则x代替kmin,并再次重新找出k个元素的数组中最大元素kmin‘(多谢jiyeyuran 提醒修正);如果x<kmin,则不更新数组。这样,每次更新或不更新数组的所用的时间为O(k)或O(0),整趟下来,总的时间复杂度平均下来为:n*O(k)=O(n*k)。
3、维护k个元素的最小堆,原理与上述第2个方案一致,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk(不然,就如上述思路2所述:直接用数组也可以找出最大的k个元素,用时O(n*k))。
4、按编程之美第141页上解法二的所述,类似快速排序的划分方法,N个数存储在数组S中,再从数组中随机选取一个数X,把数组划分为Sa和Sb俩部分,Sa>=X>=Sb,如果要查找的k个元素小于Sa的元素个数,则返回Sa中较大的k个元素,否则返回Sa中所有的元素+Sb中最大的k-|Sa|个元素。不断递归下去,把问题分解成更小的问题,平均时间复杂度为O(N)(编程之美所述的n*logk的复杂度有误,应为O(N),特此订正。其严格证明,请参考第三章:程序员面试题狂想曲:第三章、寻找最小的k个数、updated 10次)。
.........
其它的方法,在此不再重复了,同时,寻找最小的k个数借助堆的实现,代码在上一篇文章第三章已有给出,更多,可参考第三章,只要把最大堆改成最小堆,即可。
第三节、Top K 算法问题
3.1、搜索引擎热门查询统计
题目描述:
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
分析:这个问题在之前的这篇文章十一、从头到尾彻底解析Hash表算法里,已经有所解答。方法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27);
第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。
即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆(K1>K2>....Kmin,Kmin设为堆顶元素),然后遍历300万的Query,分别和根元素Kmin进行对比比较(如上第2节思路3所述,若X>Kmin,则更新并调整堆,否则,不更新),我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
ok,本章里,咱们来实现这个问题,为了降低实现上的难度,假设这些记录全部是一些英文单词,即用户在搜索框里敲入一个英文单词,然后查询搜索结果,最后,要你统计输入单词中频率最大的前K个单词。ok,复杂问题简单化了之后,编写代码实现也相对轻松多了,画的简单示意图(绘制者,yansha),如下:
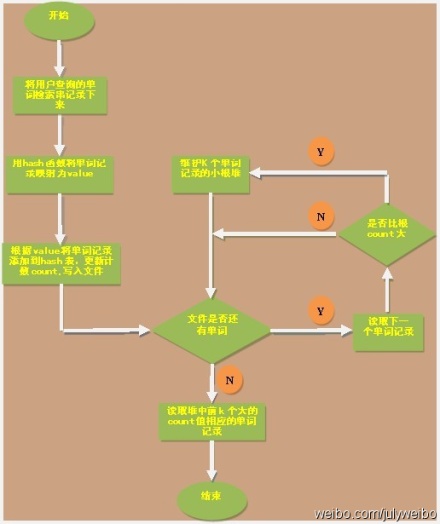
完整源码:
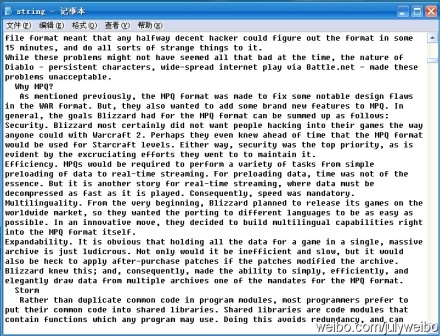
程序测试:咱们接下来,来对下面的通过用户输入单词后,搜索引擎记录下来,“大量”单词记录进行统计(同时,令K=10,即要你找出10个最热门查询的单词):
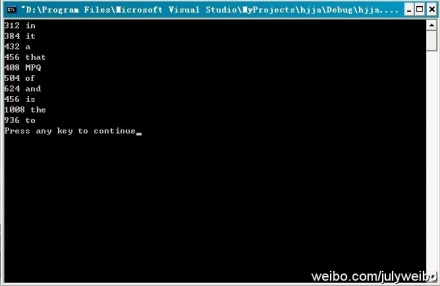
运行结果:根据程序的运行结果,可以看到,搜索引擎记录下来的查询次数最多的10个单词为(注,并未要求这10个数要有序输出):in(312次),it(384次),a(432),that(456),MPQ(408),of(504),and(624),is(456),the(1008),to(936)。
3.2、统计出现次数最多的数据
题目描述:
给你上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据。
分析:上千万或上亿的数据,现在的机器的内存应该能存下(也许可以,也许不可以)。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了。当然,也可以堆实现。
ok,此题与上题类似,最好的方法是用hash_map统计出现的次数,然后再借用堆找出出现次数最多的N个数据。不过,上一题统计搜索引擎最热门的查询已经采用过hash表统计单词出现的次数,特此,本题咱们改用红黑树取代之前的用hash表,来完成最初的统计,然后用堆更新,找出出现次数最多的前N个数据。
同时,正好个人此前用c && c++ 语言实现过红黑树,那么,代码能借用就借用吧。
完整代码:
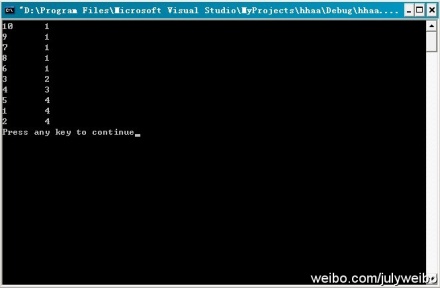
程序测试:咱们来对下面这个小文件进行测试:
运行结果:如下图所示,
问题补遗:
ok,由于在遍历红黑树采用的是递归方式比较耗内存,下面给出一个非递归遍历的程序(下述代码若要运行,需贴到上述程序之后,因为其它的代码未变,只是在遍历红黑树的时候,采取非递归遍历而已,同时,主函数的编写也要稍微修改下):
updated:
后来,我们狂想曲创作组中的3又用hash+堆实现了上题,很明显比采用上面的红黑树,整个实现简洁了不少,其完整源码如下:
完整源码:
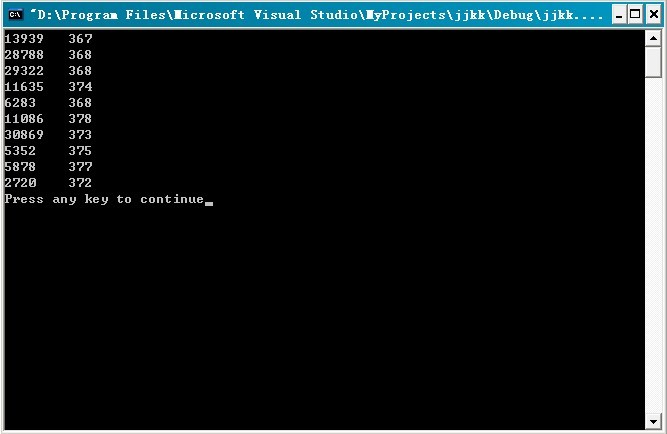
程序测试:对65047kb的数据量文件,进行测试统计(不过,因其数据量实在太大,半天没打开):
运行结果:如下,
第四节、海量数据处理问题一般总结
关于海量数据处理的问题,一般有Bloom filter,Hashing,bit-map,堆,trie树等方法来处理。更详细的介绍,请查看此文:十道海量数据处理面试题与十个方法大总结。
余音
反馈:此文发布后,走进搜索引擎的作者&&深入搜索引擎-海量信息的压缩、索引和查询的译者,梁斌老师,对此文提了点意见,如下:1、首先TopK问题,肯定需要有并发的,否则串行搞肯定慢,IO和计算重叠度不高。其次在IO上需要一些技巧,当然可能只是验证算法,在实践中IO的提升会非常明显。最后上文的代码可读性虽好,但机器的感觉可能就会差,这样会影响性能。2、同时,TopK可以看成从地球上选拔k个跑的最快的,参加奥林匹克比赛,各个国家自行选拔,各个大洲选拔,层层选拔,最后找出最快的10个。发挥多机多核的优势。
预告:程序员面试题狂想曲、第四章,本月月底之前发布(尽最大努力)。
修订
程序员面试题狂想曲-tctop(the crazy thingking of programers)的修订wiki(http://tctop.wikispaces.com/)已于今天建立,我们急切的想得到读者的反馈,意见,建议,以及更好的思路,算法,和代码优化的建议。所以,
- 如果你发现了狂想曲系列中的任何一题,任何一章(http://t.cn/hgVPmH)中的错误,问题,与漏洞,欢迎告知给我们,我们将感激不尽,同时,免费赠送本blog内的全部博文集锦的CHM文件1期;
- 如果你能对狂想曲系列的创作提供任何建设性意见,或指导,欢迎反馈给我们,并真诚邀请您加入到狂想曲的wiki修订工作中;
- 如果你是编程高手,对狂想曲的任何一章有自己更好的思路,或算法,欢迎加入狂想曲的创作组,以为千千万万的读者创造更多的价值,更好的服务。
Ps:狂想曲tctop的wiki修订地址为:http://tctop.wikispaces.com/。欢迎围观,更欢迎您加入到狂想曲的创作或wiki修订中。
联系July
•email,zhoulei0907@yahoo.cn
•blog,http://blog.csdn.net/v_JULY_v 。
•weibo,http://weibo.com/julyweibo 。
作者按:有任何问题,或建议,欢迎以上述联系方式call me,真诚的谢谢各位。
July、狂想曲创作组,二零一一年五月十日。
版权所有,本人对本blog内所有任何内容享有版权及著作权。实要转载,请以链接形式注明出处。

