



urllib2.HTTPError: HTTP Error 403: Forbidden 解决方法 & requests get 403 error
参考:
- https://stackoverflow.com/questions/13303449/urllib2-httperror-http-error-403-forbidden
- https://segmentfault.com/q/1010000000470724
通过测试应该是request中header的问题。
1 class S0819MtimeTiantangPipeline(object): 2 def process_item(self, item, spider): 3 headers = { 4 "Host": 'img31.mtime.cn', 5 "User-Agent": 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:53.0) Gecko/20100101 Firefox/53.0', 6 "Accept": 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 7 "Accept-Language": 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 8 "Accept-Encoding": 'gzip, deflate', 9 "Connection": 'keep-alive', 10 "Upgrade-Insecure-Requests": 1, 11 } 12 13 req = urllib2.Request(url=item['addr'], headers=headers) 14 res = urllib2.urlopen(req) 15 16 file_name = os.path.join(os.path.curdir, "down_pic", item['name'] + '.jpg') 17 with open(file_name, 'wb') as fp: 18 fp.write(res.read())
下面是我怎么得到正确的header的方法:
1. 准备:
Firefox浏览器+HttpFox插件
2. 步骤
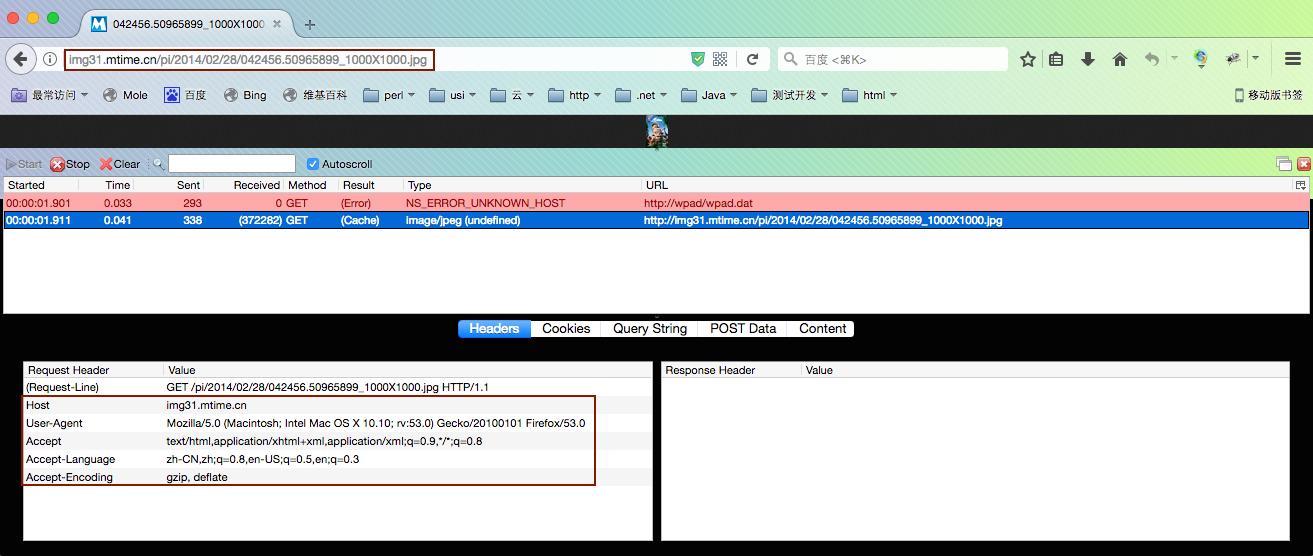
1. 打开HttpFox,然后将一个你要request的url输入到Firefox浏览框里,回车
例: http://img31.mtime.cn/pi/2014/02/28/042456.50965899_1000X1000.jpg
2. 如下图选取所需要的header
注:
1. 现在用requests抓取www.mtime.com图片又出现这个403问题了,有可能是被爬取的网站防采集程序给屏蔽了,现在还没找到方法,待处理。。。。
403 Forbidden 是HTTP协议中的一个状态码(Status Code)。可以简单的理解为没有权限访问此站。
该状态表示服务器理解了本次请求但是拒绝执行该任务,该请求不该重发给服务器。在HTTP请求的方法不是“HEAD”,并且服务器想让客户端知道为什么没有权限的情况下,服务器应该在返回的信息中描述拒绝的理由。在服务器不想提供任何反馈信息的情况下,服务器可以用404 Not Found代替403 Forbidden比如:choovin。
有人说缺少cookie或者是_xsrf,但是用FixeFox的httpfox抓出来的get信息里没有用到cookie和_xsrf呀(抓取时不需要登录)。
From: https://www.zhihu.com/question/29926060
Update:
应该是我的IP因为爬取同一个网站太快而被暂时屏蔽了。
这篇文章非常好: http://www.cnblogs.com/junrong624/p/5533655.html
Update:
每个网站请求时间隔delay 1s 后解决问题,这个.....降低了别人服务器的压力,延长了自己的工作时间^_^(快速采集是一种恶习 From:《Python 网络数据采集》).
其它优化时间方法:
1. 因为异步采集的有:
http://img21.mtime.cn
http://img31.mtime.cn
http://img5.mtime.cn
网址分别整理到三个列表里,每次请求一个列表里的一个网址,等只剩一个列表时在每个请求delay 1s.
2. 变换IP
不负自己

