目标检测 | Spatially Sparse Convolution
Spatially Sparse Convolution
导言
为什么需要稀疏化?
在3D表示中,除了点云(Point Cloud)和网格模型(Mesh),我们常常还会使用到一种称为体素(Voxel)的表示方式。类似于像素(Pixel),这种表示方式将空间均匀地切割为一个个方块,TSDF和占据网格(Occupancy Network)都可以视为体素的一种变形。
最朴素的体素表示方式,这是一种稠密(Dense)的表示形式,我们给定一个\(L\times W\times H\)的包围盒,体素尺寸为\(1\times 1\times 1\),那么我们将得到一个\(L\times W\times H\)的\(bool\)矩阵:
那么假设我们有一个\(70.4m\times80m\times4m\)的室外点云场景(KITTI点云格式的感知范围),给定每个体素大小为\(0.16m\times0.16m\times4m\)(PointPillar将点云体素化的参数),那么将得到一个大小为\(440\times 500\times1=220,000\)的体素网格,而最终有效的体素数量不会超过\(40,000\)个,即利用率不会超过\(18\%\),稠密表示形式下,有\(80\%\)的存储空间是被浪费的。
我们在模拟器中简单采集一帧点云做个实验就可以看到,当体素大小为\(0.05m\)时,基本保留原始点云的细节,但此时占用率不足千分之一。
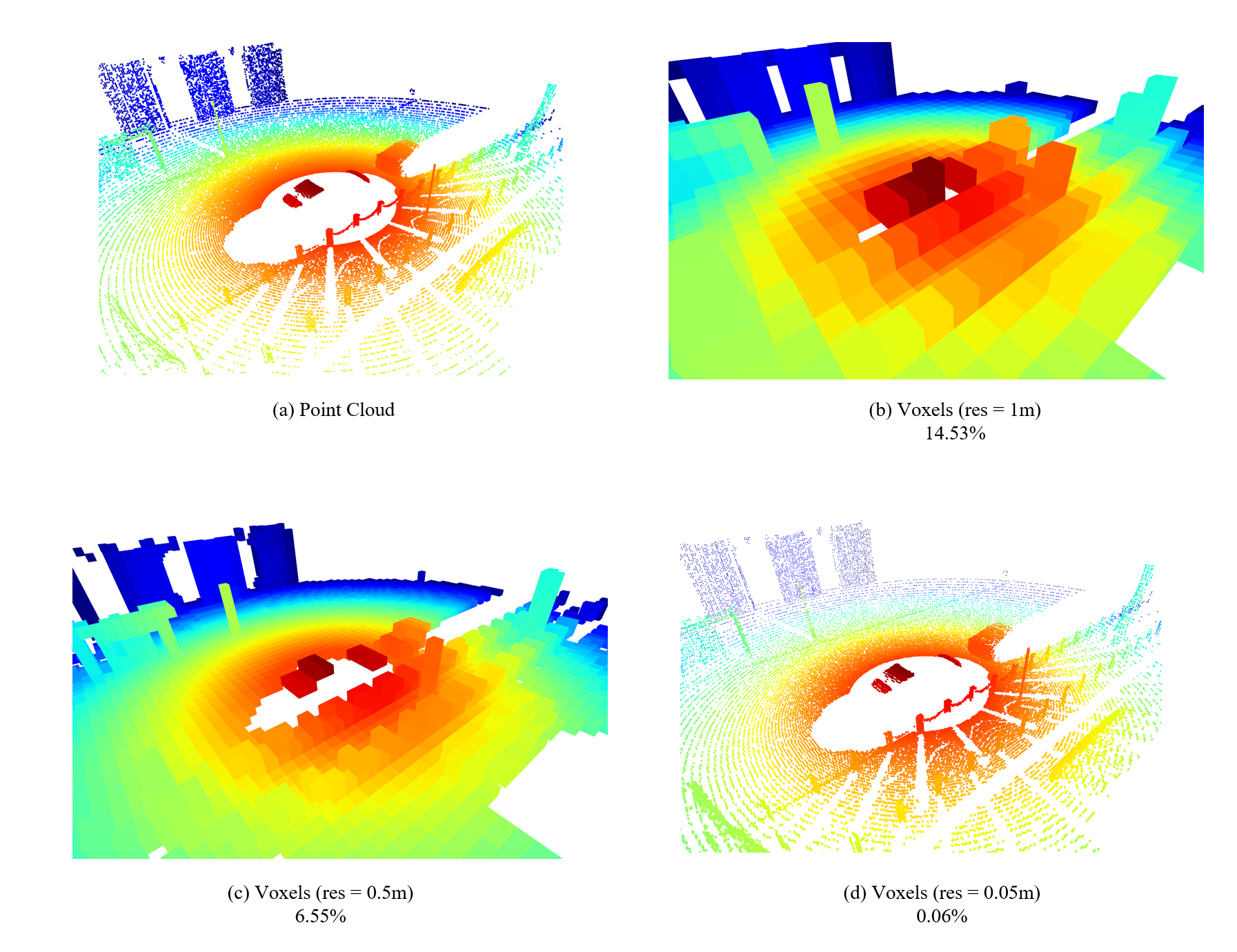
所以只表示有效体素的稀疏化表示就这样提出了,这种表示有效降低了内存的冗余,并加速了对体素的处理。
稀疏卷积
最常用的稀疏卷积分为Spatially Sparse Convolution(SparseConv)和Submanifold Sparse Convolution(SubMConv),前者是常规卷积操作的稀疏化版本,后者是保证不破坏特征图稀疏度的卷积操作。
现代通用版本的SparseConv实现出自于SECOND: Sparsely Embedded Convolutional Detection
SubMConv出自于3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
稀疏卷积主要分为四个步骤:
- 张量稀疏化
- 建立indice pair
- 稀疏特征收集
- 稀疏卷积计算
稀疏卷积
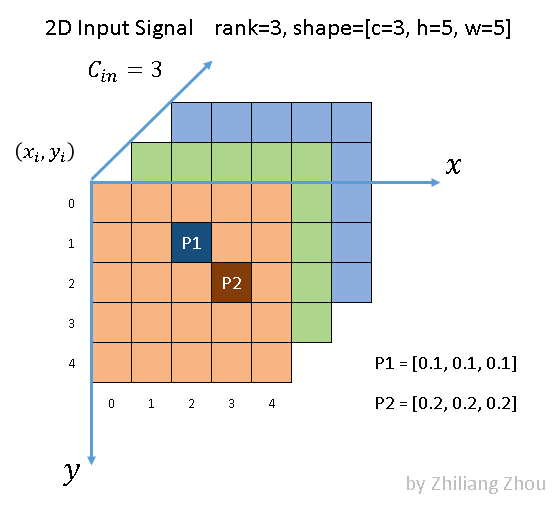
我们给出一个简单的稀疏卷积例子
如下图所示,P1与P2两个输入分别在SparseConv与SubMConv所关联的输出为A1与A2
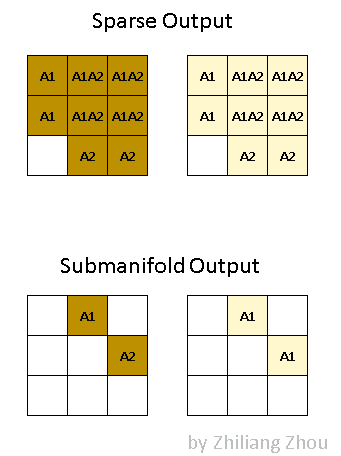
张量稀疏化
张量稀疏化就是顾名思义将一个张量从稠密表示形式变换为稀疏表示形式,我们给出常用的COO内存的定义,给定一个张量\(\mathbf X\in \mathbf{R}^{N_1\times N_2\times\cdots \times N_m}\)与稀疏维度\(d\ge1\),得到一个索引\(\mathbf{I}\in\mathbf{R}^{n\times d}\)以及值\(\mathbf{V}\in\mathbf{R}^{n\times N_{d+1}\times\cdots \times N_m}\),其中\(n\ge 0\)为张量中的非\(0\)量的数量
- 给定\(\mathbf X\in\mathbf{R}^{2\times 2} = \begin{bmatrix} 0 & 2 \\ 3 & 0 \end{bmatrix}\),\(d=2\),得到\(\mathbf I\in{2\times 2} =\text{[[0, 1], [1, 0]]}\)以及\(\mathbf{V}\in\mathbf{R}^{2}=\text{[2., 3.]}\)
- 给定\(\mathbf X\in\mathbf{R}^{2\times 2\times 2} = \begin{bmatrix} \begin{bmatrix} 0 & 0 \\ 1 & 2 \end{bmatrix} \\ \begin{bmatrix} 0 & 0 \\ 3 & 4 \end{bmatrix} \end{bmatrix}\),\(d=2\),得到\(\mathbf I\in{2\times 2} =\text{[[0, 1], [1, 1]]}\)以及\(\mathbf{V}\in\mathbf{R}^{2\times2}=\text{[[1., 2.],[3., 4.]]}\)
五种内存管理形式
建立indice pair
在输入中,稀疏矩阵中非空量我们称为active input (actIn),那么每个actIn在输出中存在关联的量称为active output (actOut)
indice pair是一个\(k\times n\)的表结构,每个元素是一个索引对\((i, j)\),表示的是\(\text{actIn}[i]\)乘以卷积核中的第\(k\)个权重,其结果输出到\(\text{actOut}[j]\)中,建立indice pair如下进行:
-
初始化actOut
-
计算actIn所关联的每个actOut
给定一个\(\text{actIn}[i]=(x,y)\),可以算出每个输出坐标\((x^\prime,y^\prime)\)以及其对应卷积核位移\(k\)
在actOut寻找\((x^\prime,y^\prime)\)是否存在,没有就开辟一个新空间,返回其索引\(j\)
建立索引indicePair[k].append(i,j)
可以如下写成伪代码形式:
vector[K] get_indice_pair(act_in: vector, act_out: vector) {
initialize indice_pair = vector[K];
for i in enumerate(act_in.length()) {
pos_act_In = act_in[i];
for k, {x, y} in get_valid_out_pos(pos_act_In) {
j = act_out.find({x, y});
if(j == -1) {
j = act_out.length();
act_out.append({x, y});
}
indice_pair[k].append({i, j});
}
}
return indice_pair;
}
如果是SubMConv操作,在get_valid_out_pos中检查输出坐标在输入所对应的坐标中是否为actIn,否则过滤掉即可
注意:这里只是为了方便理解把indice pair写成了\(k\times n\)的表,实际indice pair一般都是一张\(2\times k\times n\)的表,其中\(\text{indice_pair}(0,k,n)=i,\ \text{indice_pair}(1,k,n)=j\),这样在特征收集与计算阶段就只需要读入半张表,提高性能
稀疏特征收集
这一步的目的在于通过indice_pair收集读入指定位置的特征feats,用于下一步的卷积计算。我们可以用公式表示:
稀疏卷积计算
稀疏卷积计算分为两步:相乘与求和
-
相乘阶段
相乘阶段的目的在于将特征feats与指定位置的权重相乘
\[\text{feats}^\prime\in \mathbf{R}^{k\times n\times f} = \text{feats} \in\mathbf{R}^{k\times n\times f} \odot \text{kernal}\in \mathbf{R}^{k} \]其中$\odot $是逐元素乘积
-
求和阶段
将上一阶段相乘的特征进行求和
\[\mathbf I = \text{actOut},\mathbf{V}(j)=\sum_{k}\text{feats}^\prime(k,n) \\\text{where}\ \text{indice_pair}[n]=\{i, j\} \]可以如下写成伪代码形式:
vector[K] sparse_scatter_add_cpu(act_out: vector[N], indice_pair: vector[K], feats: Tensor[k, n, f], kernal[k]) { feats = feats * kernal; \\Tensor[k, n, f] value = tensor::zeros((act_out.length(), feats.size(2))); \\Initialize a full 0 Tensor with size [N, f] for k in range(K) { for index in range(indice_pair[k].length()) { {i, j} = indice_pair[k, index]; value[j] += feats[k, index]; } } return value; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号