RealtimeGI实战篇(上)|稀疏体素与距离场搭建软件光线追踪
【USparkle专栏】如果你深怀绝技,爱“搞点研究”,乐于分享也博采众长,我们期待你的加入,让智慧的火花碰撞交织,让知识的传递生生不息!
开篇
我认为学习某样东西最好的方式就是在使用中摸爬滚打带着目标去边学边做,恰逢彼时腾讯在GDC 2023上发布了HSGI的演讲,体素软件光追+ReSTIR算法大放异彩,在那一刻想要RTX ON的心情达到了顶点,于是不知天高地厚地立下了要做一个软件光追管线复刻一下HSGI的目标。
斗转星移,四季更迭。在帕鲁之余,笔者完成了自己定下的一个一个小目标,对UE引擎有了一些基础的认识,也取得了一些微小的成果。思前想后决定赶在今年的尾巴做一个小小的总结,辞旧迎新结束这一年。
一、理论铺垫
实时GI的求解,其实就是求解渲染方程的过程。回顾整个计算的伪代码,小小的渲染方程竟藏着实时渲染的三座大山!(众所周知三座大山有四座。)
第一座山:可见性求解。首先我们需要找到对当前像素有光照贡献的所有可见点;
第二座山:材质的评估。对于每一个可见点,需要以某种手段评估其表面的材质以得到Base Color、Normal等材质属性;
第三座山:光照计算。万事俱备我们要根据可见点的材质,计算其收到的直接+间接光照,作为递归方程的返回值;
第四座山:降噪。我们只能遍历有限的可见点,因此蒙特卡洛估计器会返回嘈杂的结果。

对于硬件光线追踪管线来说,硬件提供了BVH遍历功能来解决可见性查询问题。此外硬件提供了Hit Shader,能在光线命中时执行一段用户自定义的连连看Shader来评估材质以及光照。对于降噪问题NVIDA贴心的提供了如NRD等各种降噪SDK。
对于小米加步枪一穷二白的软件光追来说,这三座大山都要我们自己一点点铲平。因此本文的重点将围绕前三座大山展开。在后续的文章中,我们将重点突破降噪这座大山。
二、核心思路省流速览
2.1 场景表达
腾讯在GDC 2023上发表的HSGI演讲提供了很棒的思路,笔者也沿用HSGI的思路,使用体素来作为GI场景的表达。这样自然而然地解决了材质评估和光照评估两座大山。
对于光线的每一个命中点,我们根据命中位置查询体素,就能得到这一点的Base Color、Normal等材质属性,我们称之为Material Cache;有了材质信息我们为每个体素计算其收到的直接+间接光照,光照结果存储回体素中,我们称之为Radiance Cache。
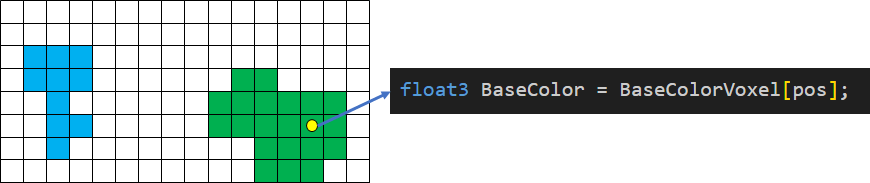
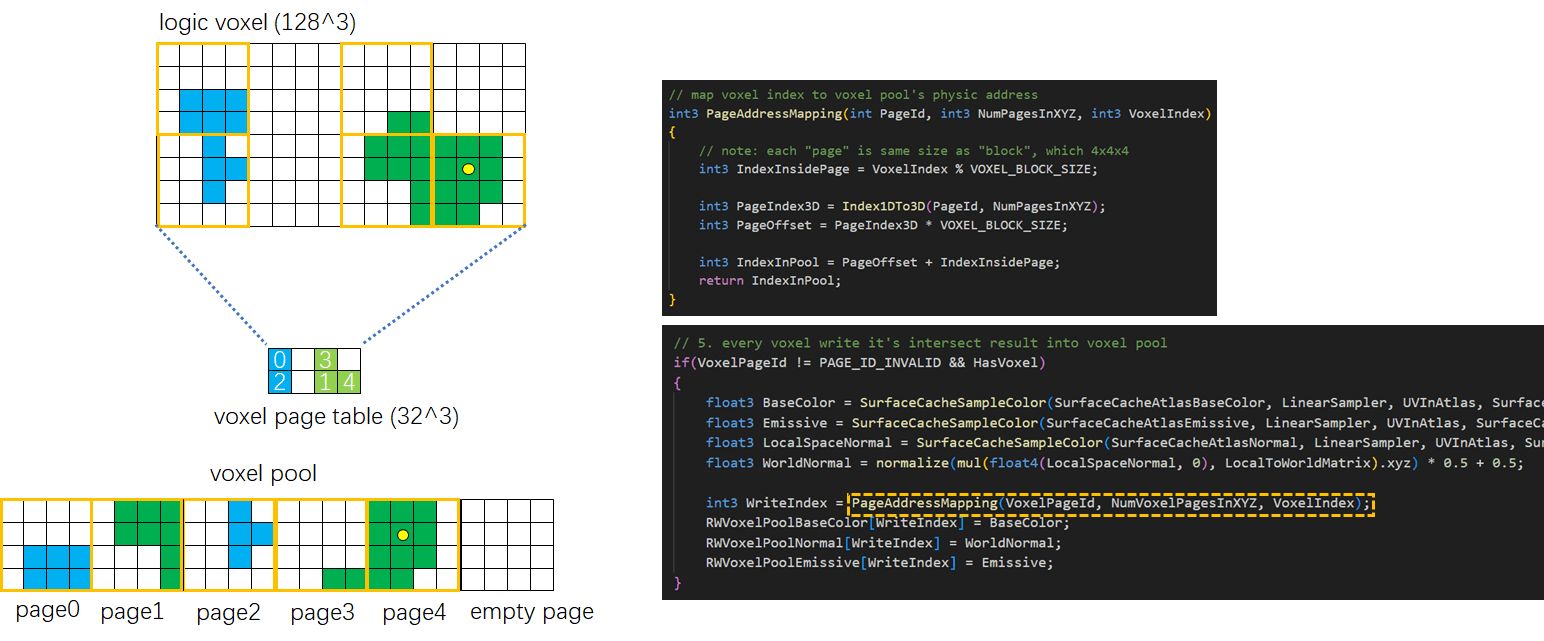
存储Base Color、Normal、Emissive和Radiance需要耗费巨量的内存,因此需要对其进行稀疏化处理。我们将整个体素分为若干个4x4x4的子块,称之为Voxel Block,这是体素内存分配的最小单位。只要一个Block内存在任意一枚体素,我们就为其在体素池子中分配完整的4x4x4个体素的空间。
与之对应需要有一个分辨率为“体素分辨率÷4”的页表,指明当前Block在体素池子中的实际位置。于是体素寻址的过程需要先根据体素的位置确定体素所属的Block,然后再访问页表拿到实际的地址偏移进行纹理采样。
2.2 体素化
在HSGI原文中使用的是基于光栅化的体素化,这需要在CPU端遍历所有的物体,挑选“与待更新的体素区域相交的物体”并发起Drawcall,此处笔者耍了一些花活,使用了一种不依赖光栅化的体素化方法,这样整个体素化的流程能完全被GPU接管。
受到Lumen的启发,我们为每个模型拍摄6个方向的Mesh Card,记录物体的深度、Base Color、Normal等信息。对于每个体素,我们将其位置转换到拍摄Mesh Card时的相机空间,像做Shadow Map一样判断体素深度和Mesh Card上记录的深度是否足够接近。如果两个深度足够接近我们认为该体素是有效的。

2.3 可见性查询
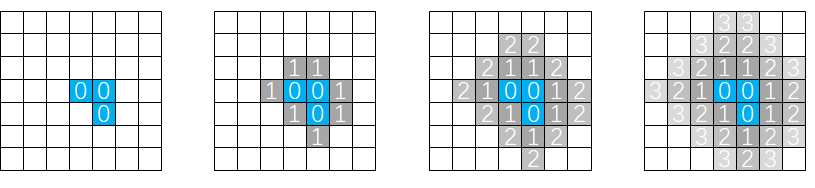
对于可见性查询这座大山,HSGI原文使用的是基于HDDA的光线步进,我这里使用的方案是无符号距离场。参考了Lumen生成Global DF的Mip Texture的策略,对于存在体素的格子我们标记其距离值为0作为初始值,然后进行距离场的传播,每个体素需要遍历自己周围上下左右前后6个体素来更新自己的距离值。每帧进行一次距离的传播,若干帧之后场景就会被距离场填满。
2.4 核心思路小结
核心思路其实非常简单,每个体素遍历所有物体的所有Mesh Card,判断体素是否命中Mesh Card的深度值。如果一个Cell里面存在体素,我们为其分配一个4x4x4大小的体素页面,将Base Color、Normal等材质属性写入体素池子中。最后我们标记无符号距离场的值为0,然后执行距离场的传播。
犹如把大象装进冰箱里面,看似简单的步骤需要依赖一系列的基础设施。我们怎样高效地筛选对体素有贡献的物体?怎样访问每个物体的Mesh Card?又该如何为体素分配内存页面?拿到了体素的材质属性我们怎么点亮整个体素场景?我们接着往下走,一步一步实现这些小目标。
三、物体剔除与GPU Scene
场景中有成百上千的物体,而3D纹理中又有成百上千的体素,我们不可能暴力地用两个for循环,每个体素遍历所有Object。如果一个体素落在了Object的包围盒外面,显而易见其无法对体素产生贡献,则我们可以跳过这个Object的检查,这就需要引入Object剔除的策略。
3.1 剔除流程
和UE引擎中的距离场更新类似,笔者使用环绕相机的体素ClipMap来进行远景的LOD表达。因此我们会对场景中的Object进行两次剔除。第一次剔除会排除那些不在ClipMap内的Object,得到每个ClipMap层级可见的Object列表。

接着我们将体素细分为更小的更新区块,我们称之为Update Chunk,第二次剔除会针对每个Update Chunk构建一个独立的Object列表(和Light Cluster的思路非常类似),有了更精细的剔除,每个体素只需找到自己所属的Chunk并且遍历与该Chunk相交的Object列表。

3.2 GPU Scene实现
对于剔除的操作我们也是在GPU上完成的,这就需要把全场景每个Object的包围盒、位置等信息(称之为Object Info)上传到GPU Buffer中。我们在GPU上开辟一块内存来存放Object Info,每帧增量地将CPU上有变化的Object Info同步到GPU Buffer上。
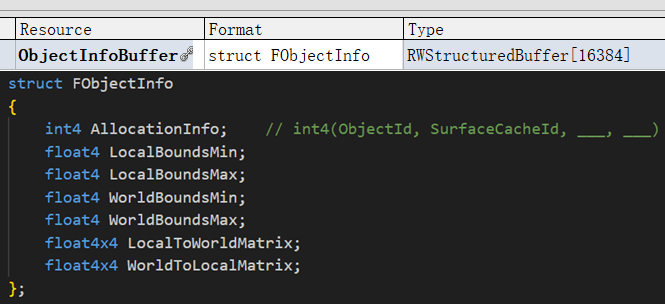
注:在UE引擎中这个功能叫做GPU Scene,出于练习的目的,以及要存储额外的如Mesh Card等信息,笔者自己实现了一套简易版本。下文中如果提到GPU Scene一般是代指我自己的丐版实现。
首先我们在CPU上实现了简易的线性分配器,用Free List链表来管理Object Info的分配,CPU和GPU两端的Object Info都共享一个数组下标索引,记作Object ID。每帧CPU端会将所有Dirty的Object Info上传到紧凑的Upload Buffer,接着在Compute Shader中根据Object ID将Object Info放到GPU Buffer正确的下标位置。

因为在CPU端我们是使用Free List来分配GPU Buffer的下标,这种简单的方式是不保证物体连续紧凑存放的。因此我们增加一个Pass将所有的Object Info中用于剔除的数据单独提取到一个小结构体并紧凑排放在MiniObjectInfoBuffer中。这样既可以减少剔除线程遍历物体时的Divergence,也可以减少每次读取Object Info的带宽开销。

3.3 物体剔除实现
以第一次剔除(针对ClipMap)为例,我们为每个Object分配一条线程,以N个物体(线程组大小)为一组进行剔除。我们总共需要派遣的线程组数目为“全场景物体数目÷N”。
首先通过Shared Memory记录线程组内每个Object的剔除结果;接着由线程组内第一个线程统计与ClipMap相交的Object数目,通过Interlocked指令在剔除结果Buffer中申请空间;最后各个线程将包围盒和Object ID写入Buffer。

这是一个非常基础且好用的GPU并行编程范式。后续的第二次物体剔除(针对Update Chunk)代码也是沿用同样的逻辑,同样对每N个Object分配一个线程组执行“剔除-统计-分配-写回”这几步。笔者这里就不再重复展示,有需要的读者可以访问GitHub获取完整的代码。

因为与ClipMap相交的Object数量无法确定,所以第二次针对Update Chunk的剔除我们使用的是Indirect Dispatch,这是一个二维的Dispatch,X轴代表ClipMap内的所有 Object,Y轴代表每个待更新的区块。

至此我们为每个待更新的区块,构建了与之相交的物体列表,大大加速了体素遍历Object的过程。不过为了执行体素化,我们还欠一味东风,那就是Mesh Card,接下来的小节将介绍其管理策略。
四、Mesh Card管理
一组Mesh Card提供了物体的几何信息(深度图)与材质信息的快照,也是本文中不依赖硬件光栅化的体素化算法的基石。和Lumen不同,在笔者的方案中Mesh Card不负责存储Radiance,因此它与场景Object的实例并非一一对应关系。使用了相同Mesh和Material的多个Object是可以共享同一组Mesh Card,可以将其类比为硬件光追中的BLAS概念。因此我们需要单独实现Mesh Card的分配器。

我们使用图集的策略来管理Mesh Card,配套一个四叉树分配器为每张Mesh Card在图集上分配物理空间;对于每组Mesh Card我们需要记录它们的数量、分辨率等信息;对于每个Mesh Card,我们要记录拍摄时的变换矩阵以及其在图集上的位置。和Object Info类似我们配套一个线性分配器即可。

和Object Info类似,所有的分配(图集空间、Mesh Card Info)都发生在CPU端,然后通过Upload Buffer将分配的结果同步到GPU 端。我们使用引用计数来管理每个Surface Cache(一组Mesh Card的集合),在Primitive新增或者删除时我们根据其用到的Mesh、Material算出一个Hash Key,增加或减少Key对应的Surface Cache的引用,在引用为0的边界情况我们还会通过四叉树分配器分配或释放图集空间。

物体实例在场景中可能具有不同的缩放,对于巨大的物体它需要更高分辨率的Mesh Card来保证精度。在物体加入场景时我们会为其默认分配最低分辨率,随着时间的推移我们每帧会随机检查一小部分Surface Cache,遍历所有引用它的Object计算引用者在世界空间中的最大尺寸,根据尺寸重新分配Mesh Card图集并重新发起Mesh Card捕获的Drawcall。

五、体素注入与页面分配
有了剔除后的物体列表,以及每个物体捕获的Mesh Card,我们终于可以开始进行体素化了!
5.1 体素注入
在笔者的实现中,将128x128x128的体素均匀划分为了8x8x8个更新区块(Update Chunk),也是上文提到的剔除和体素注入的最小单位。
当相机移动、场景中的Primitive移动时都要重新对相关联的Chunk进行体素注入。前者只需按照移动方向将前方Chunk置脏,后者则需要同时记录增加、删除的Primitive的两个包围盒所影响的Chunk,因为我们需要先擦除旧体素再注入新体素。在每帧盘点出Dirty的Chunk之后我们通过Upload Buffer将Chunk上传到GPU。

和2.2小结中描述的流程一致,我们为每个Update Chunk内的每个体素分配一个线程,遍历该体素所属的Update Chunk的Object List,对于每一个Object我们找到它对应的Surface Cache并遍历所有Mesh Card,逐个检查其深度图是否与体素相交。

和HSGI一样,我们这里也使用一个uint64来表示一个4x4x4的体素Block内的体素占用情况,我们称之为Voxel Bit Occupy Map,这样我们可以使用32x32x32分辨率的纹理来表达128x128x128分辨率的体素占用情况。

我们为每个4x4x4的体素Block分配一个4x4x4大小的线程组,通过Shared Memory 统计Block内体素的占位情况,然后由线程组内第一个线程负责将占位情况Pack成 uint64写入Bit Occupy Map,这里我们用两个uint32代替uint64以获得更好的兼容性。
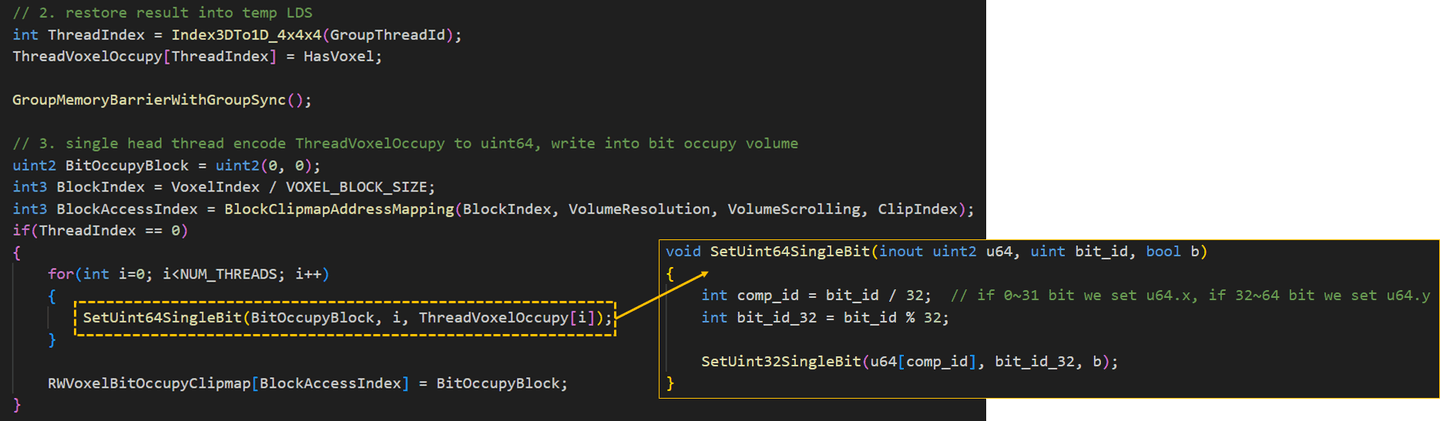
有了Bit Occupy Map我们可以将体素可视化出来。此处作为演示我还可视化了每个 Update Chunk (下图蓝色)以便观察体素更新的过程。因为使用了环绕地址映射,超出范围但是来不及更新的体素会被映射回前方。为了演示我特地将每帧允许体素注入的Chunk预算调的很低,实际运行时是不会出现来不及更新的Artifact的。
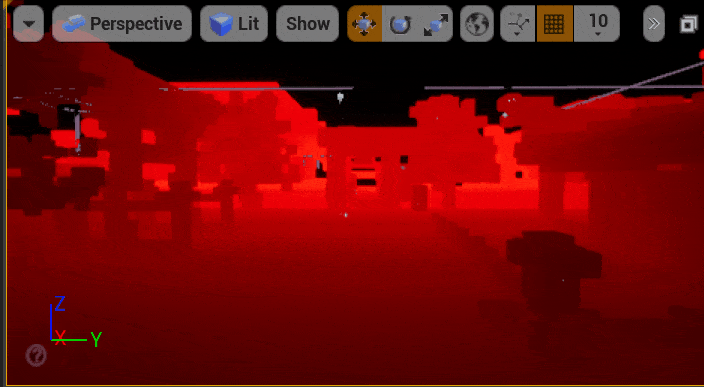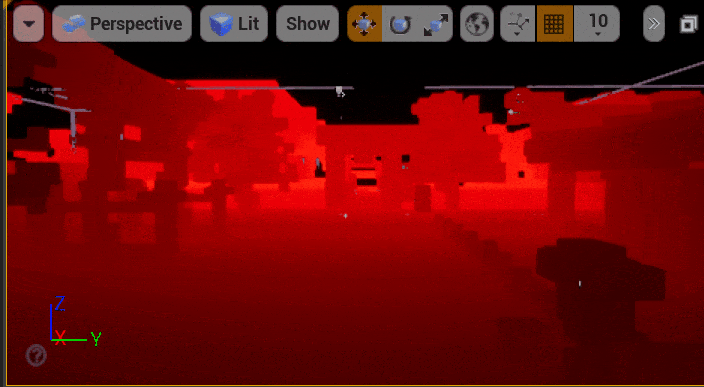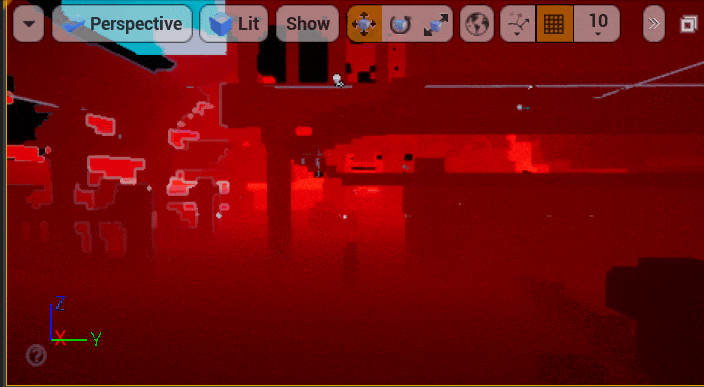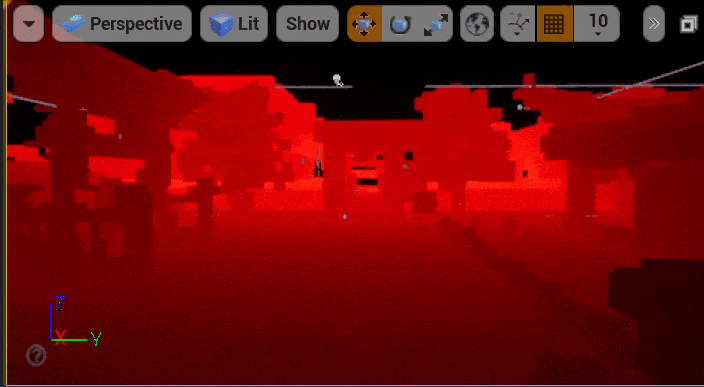
5.2 体素页面分配
只有Bit Occupy Map我们能得到场景的几何表达,这解决了可见性查询的问题,本小节将解决如何查询命中点的材质属性。Mesh Card不仅记录了物体的深度信息,还保存了物体的Base Color、Normal和Emissive等材质属性。我们使用和5.1小节体素注入中提到的“深度相交测试”相同的UV访问Mesh Card图集,即可拿到物体的材质属性。

不同Object实例在世界空间中World Normal各不相同,此外Mesh Card是不包含Radiance的,因此我们不能简单地用Mesh Card来表达逐Object实例的Surface信息。对于在体素注入中产生的每一个体素我们都应该独立地记录其Surface信息。如果把Mesh Card类比为硬件光追中的BLAS,那么带有物体材质信息和Radiance的体素则可以类比为TLAS。

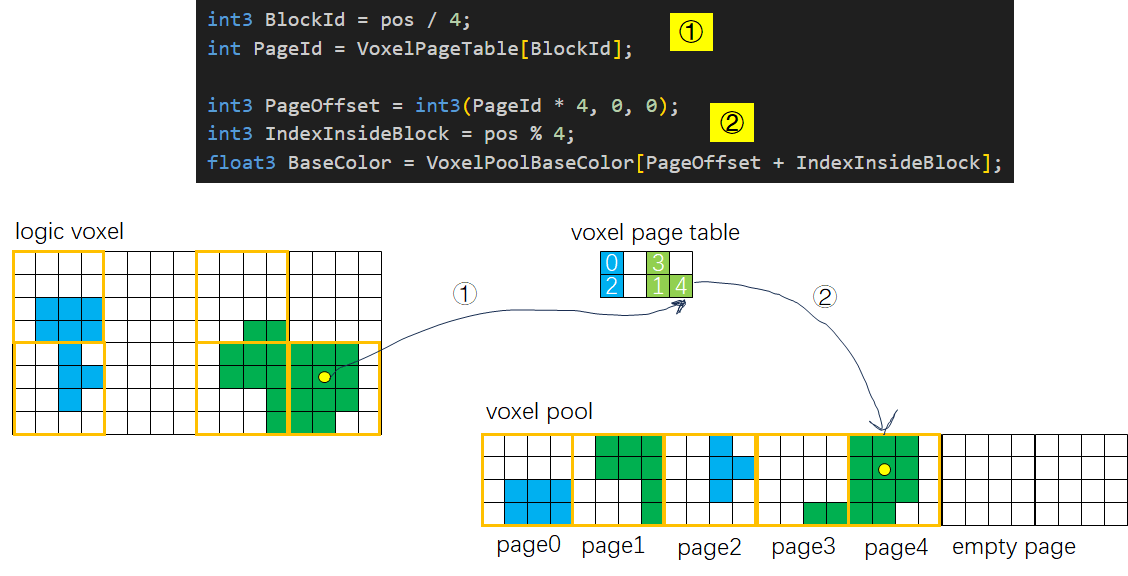
和Bit Occupy这种高度压缩的数据不同,材质属性是无法压缩的。每个体素都有其独自的Base Color,因此我们选择稀疏地分页存储材质属性。我们开辟一块固定大小的体素池子作为物理存储,同时配套一个指向Pool内空闲体素页面的Free List Buffer作为GPU上的线性分配器,此外还需要配套一个体素页表来为已经分配出去的体素页面建立“体素位置”到“物理存储地址”的映射。

和体素注入一样,体素页面的分配也是以4x4x4的Voxel Block为单位(这也是体素页面的大小),因此体素页面分配的流程完全可以合并到体素注入中。在每个线程组的第一个线程执行完Voxel Bit Occupy Map的写入之后,它还要负责为当前Block找到一个体素页面。
首先我们根据体素所在的Block的位置访问Page Table得到Page ID,如果当前Block存在体素而没有分配页面我们访问Page Free List获取一个空闲的Page,如果当前Block不存在体素却占用了一个有效的Page,我们将其插入到Page Release List中等待释放。最后的最后将Page ID写回Page Table,并记录在共享变量中方便组内其他线程访问。

在第一个线程分配完成体素Page之后,线程组内其他体素注入线程就可以将体素注入的结果写入Voxel Pool,首先访问Shared变量获取该体素所属的Block对应的Page,并计算在Pool中的地址。然后从Mesh Card中拿到Base Color等材质属性,写入Page对应的物理存储中。
在体素可视化以及后面的光线追踪中,我们也是通过同样的代码,先访问Page Table再访问Voxel Pool,这里就不重复展示了,感兴趣的读者可以移步GitHub浏览。有了稀疏体素我们获得了查询任意位置的Material信息的能力,可视化一发看下效果。

六、距离场
完成了体素注入,我们获得了一张1/4分辨率的Bit Occupy Map,其中的每一个像素都表达了4x4x4的Voxel Block中的体素占位情况。我们可以直接利用Bit Occupy Map进行光线追踪,上文的可视化就是这么来的。

利用Bit Occupy Map加速的HDDA光线追踪一次能跳过4个体素的距离,要想跳过更大的距离就要对其生成Mip。在笔者的实现中体素为128分辨率,为了保证Volume的循环寻址,最小一级Bit Occupy的Mip不能小于8(因为Update Chunk在xyz方向上各有8个),这导致Bit Occupy的Mip层级并不高。
经过性能的对比,最终笔者还是决定使用距离场的方案,因为距离场能快速跳过空白的区域。出于学习的目的,笔者的代码中仍保留了Bit Occupy Map纯体素追踪的算法,通过控制台变量r.RealtimeGI.UseDistanceField开关。
距离场是处处连续且有数值意义的,可是我们目前手头上只有非0即1的体素,怎么把场景的几何表达从体素转换到距离场呢?这里笔者参考了Lumen中Global Distance Field的做法:首先注入初始的距离值,然后进行若干次距离场的传播(类比于对体素做Bloom)就可以将距离场填充满整个场景。
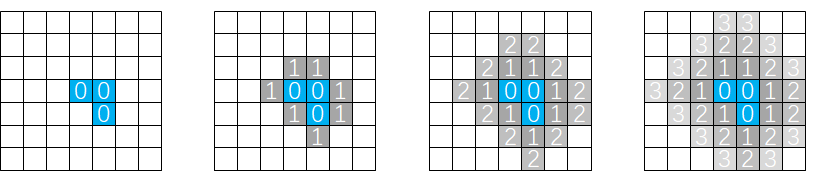
距离场是稠密的,我们开辟和体素等大小(128)的,格式为R8的3D纹理,用0~1的范围表达最多32个体素的距离。在体素注入的时候顺便将对应格子的距离标记为0即可获取距离场的“启动资金”。

我们每帧还会进行一次距离场的传播来填充空白区域的距离值,经过若干帧后距离场将会收敛。传播的算法也很简单,我们直接用邻居的距离值+1,然后和本像素的值比大小。

一个基本收敛的距离场大概长这样:

有了距离场我们就可以愉快地RTX ON了,首先将采样点相对Volume的位置映射到0~1的UV空间,采样对应UV的距离场并计算步进距离。值得注意的是距离场的距离并不代表实际空间中的距离值,因为我们的距离传播算法在对角线时会产生误差,因此需要开一下根号修正这个误差。

值得注意的是,当我们命中一个体素时不一定代表这个位置真的有体素。因为我们是使用线性插值采样器进行距离场采样的,所以在光线追踪器的视角上,距离场是“圆滑”的。这就导致命中点有可能在体素之外,所以在命中的时候我们要检查命中点所在体素的邻居体素,在它们之中找到最近且有填充的体素,以此来作为命中点。

来看一下在距离场视角下的体素场景:

七、体素光照
有了距离场和稀疏体素,我们解决了第一小节中提到的可见性查询、材质评估两座大山。最后一个问题则是怎么评估命中点的光照呢?
和材质属性类似,我们可以保存每个体素其接收到的Radiance,这样在我们光线命中体素的时候就可以像访问Base Color、Normal那样直接获取到体素的光照信息。我们将带有光照信息的体素称为Radiance Cache,而本节的内容就是怎么根据体素的材质去计算其受到的Radiance。
在开始之前,我们要申请一块双份加大的Voxel Pool来额外存储每个体素的Radiance,我们为每个体素存储法线方向+法线反方向两个方向的Radiance,这么做是为了保证厚度为1体素的墙壁,只有外面的一侧是接受阳光的,避免发生漏光。在光线命中时,我们也要根据光线的方向,选取合适的体素面的Radiance

7.1 体素直接光照
每个体素我们都能拿到其世界空间的位置、Base Color、Normal等信息,那直接N dot L一发其实就可以得到每个体素的来自方向光的直接光照。我们的计算流程可以类比为离屏的延迟渲染,只是G-Buffer的数据是从Voxel Pool里面拿到的。
因为体素并不是紧密填充的,如果我们强行遍历128^3的体素,那些没有填充(值为0)的体素会在每个线程组内产生大量的Divergence,最终会导致性能的急剧下降。我们要预先找到那些有填充(值为1)的体素,将它们紧密排列在紧凑的Valid Voxel Buffer中,再对这个紧凑Buffer进行遍历和计算。

我们为每一个Voxel Block (4x4x4 voxel) 分配一个线程,该线程从该Block对应的Bit Occupy Map中统计Block内有效的体素数目并写入Shared Memory,由组内第一个线程在紧凑Valid Voxel Buffer中分配空间,最后将结果写入Buffer中以备后续Pass使用。

紧接着是一次Indirect Dispatch遍历了Valid Voxel Buffer,对于每个体素我们首先从紧凑Buffer中取出它的下标,根据下标计算地址并从Voxel Pool中读取其材质信息。我们遍历其正面、背面的法线,通过N dot L计算方向光的直接光照,最后将Radiance写回Voxel Pool对应的位置。

对于方向光的Shadow,我们分两种情况。如果体素落在视锥体内我们采样CSM,否则我们朝方向光方向发射一条Shadow Ray进行可见性测试。我们还在进行测试的时候添加了一些法线方向的Bias以防止产生自遮挡现象。

在可视化体素的流程中,我们根据光线的方向采样双面的Voxel Radiance Pool就能看到每个体素受到方向光的Direct Lighting。

可视化看下效果:

这里还有一个小技巧,对于128^3x4的ClipMap来说,我们每帧计算全部体素的Radiance开销还是太大了。我们会选择2x2x2的棋盘格的模式去分帧更新体素的radiance,这样每帧的开销就只有全量更新的1/8,下图展示了光照剧变时Voxel来不及更新的情况。

7.2 体素间接光照
细心的读者肯定发现了,在上面的小节我们只计算了体素的直接光照,因此没有光源的地方是死黑的。其实现在的体素已经准备进行后续的Final Gather流程了,只不过我们得到的是一次反弹的结果。如果我们为每个体素计算间接光照,我们就得到了无限反弹的结果。
我们使用基于Probe的方案来计算每个体素受到的间接光照。对于每一个Block(4x4x4 Voxel)我们放置一个Probe并均匀的Trace射线,从Voxel Radiance Pool中获取命中点的光照,最后投影为球谐向量存储到一张3D纹理中,用来在下一帧的Voxel Lighting Pass为体素提供间接光。

和Direct Lighting的计算类似,我们要先有一个Pass挑选出非空的Voxel Block,在其中摆放Probe并将Probe的索引Pack到紧凑的Buffer以决定我们要Dispatch多少组线程。

值得注意的是Probe的放置条件。我们不能只在当前Block是存在体素时才放置Probe,我们也要考虑相邻Block的体素占位情况。当相邻的Block非空时,当前的Block也要摆放一个Probe,这样做是确保物体的双面都能受到间接光照。
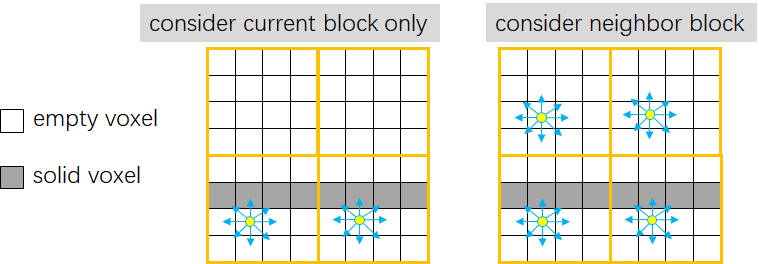
生成Probe的代码和筛选有效体素的Pass类似,先判断当前Block是否要摆放Probe,然后每组第一个线程统计、申请空间,最后各个线程将生成的Probe ID写入紧凑Buffer。我们同样使用了2x2x2的棋盘格策略进行分帧渲染,每帧只产生1/8的Probe。
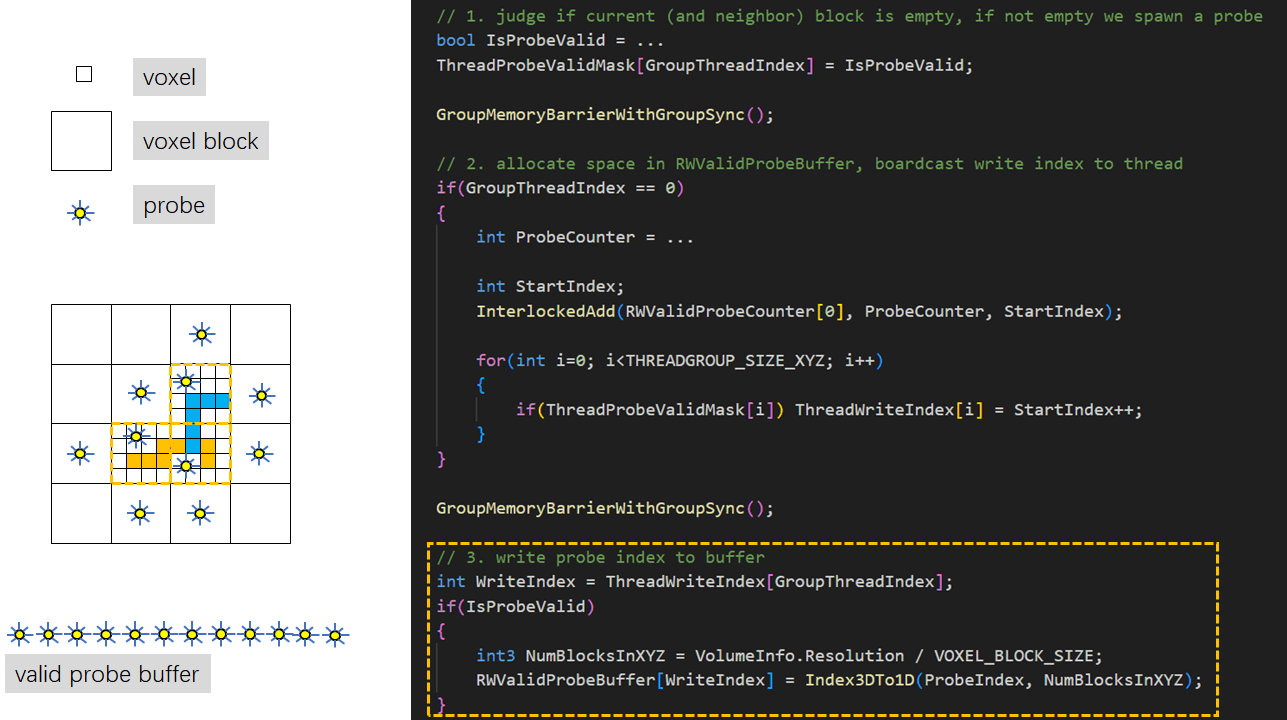
Probe摆放的位置不能存在体素,因此需要进行Probe Relocation,我们的策略是遍历代表当前Block体素占位情况的uint64,找到距离中心最近且为空的体素,在这个空的地方放置Probe就不会出现自相交的情况。因此我们需要一张额外的3D纹理来存储Probe Offset,每个Texel代表一个Probe。
可视化一发Probe看看,可以发现Probe是紧紧围绕物体摆放的,空的地方不会生成Probe,因为有Relocation机制,有体素的地方也不会有Probe。
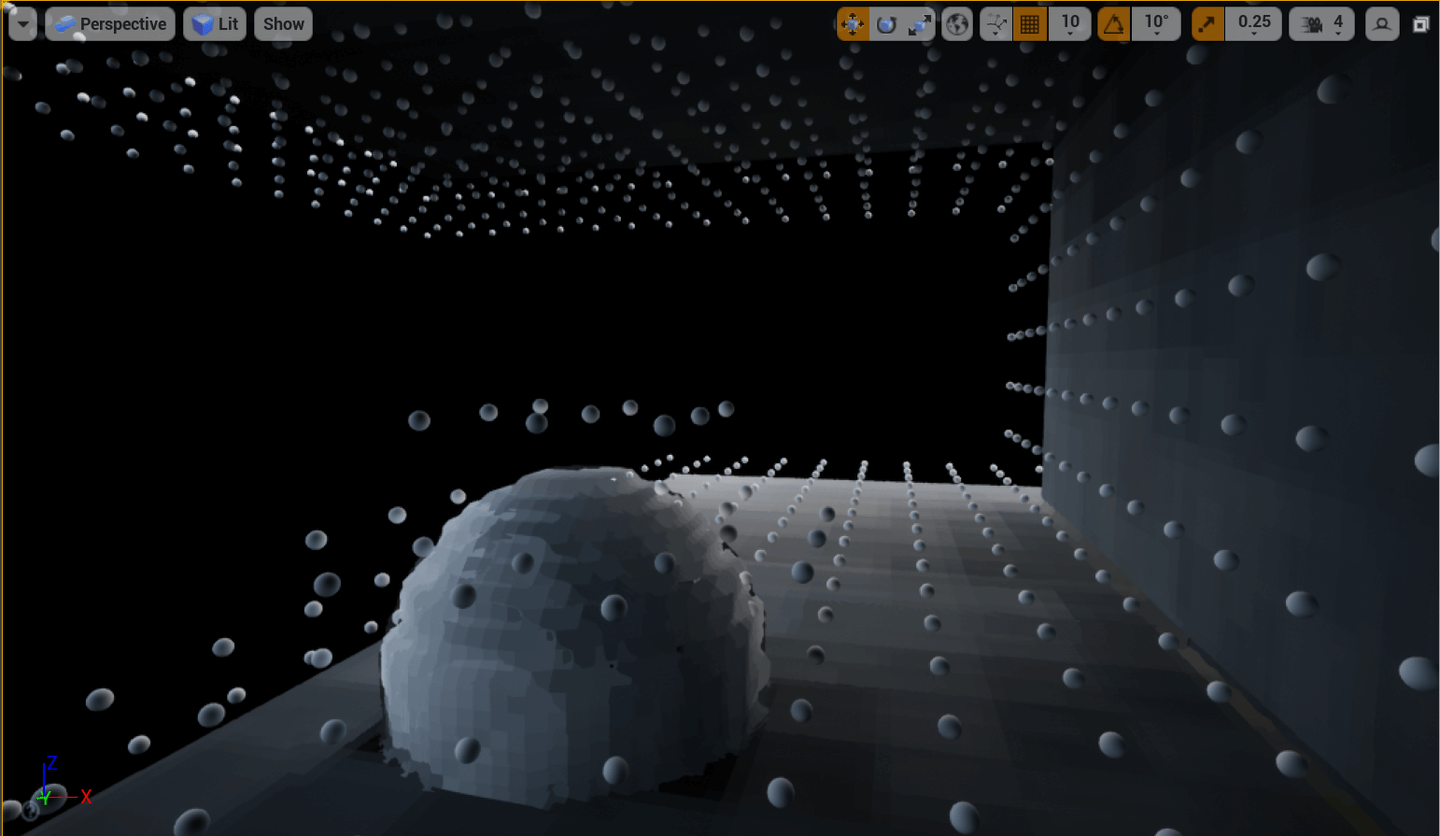
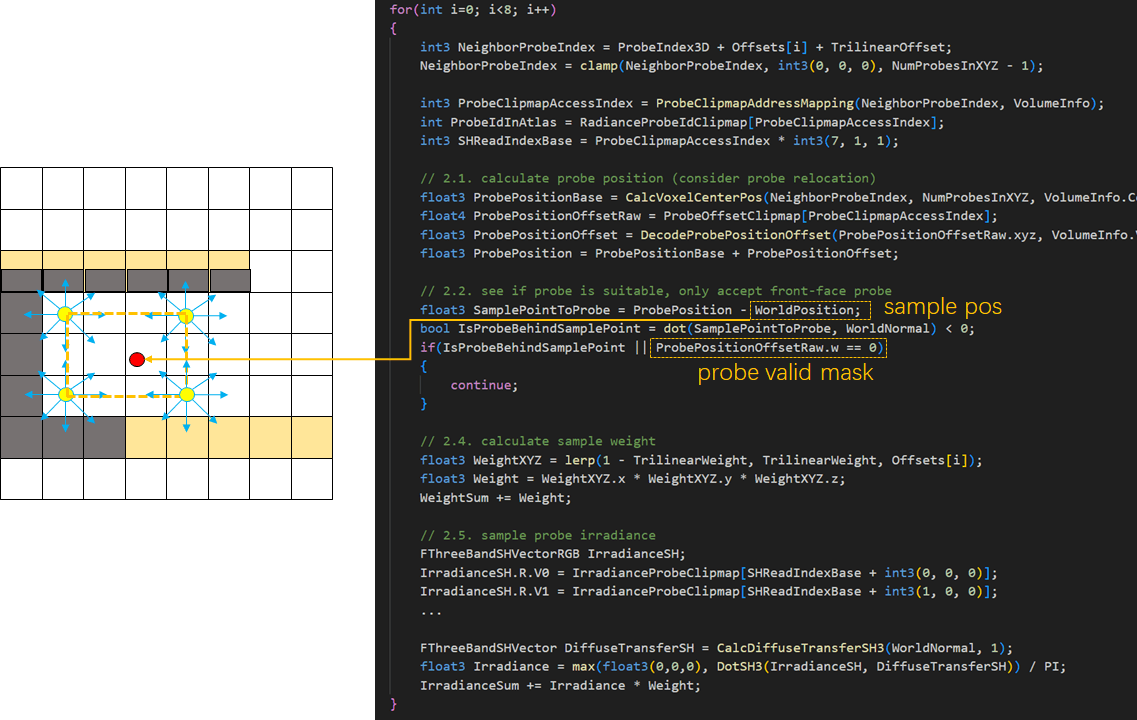
上面的图其实是带了间接光的体素,我们这就开始进行Probe Gather!这是一个Indirect Dispatch,我们根据上面选出的有效Probe的数目来决定要发射多少线程组,每个Probe对应一个线程组。
我们为每个Probe分配64个线程并发射64(或者128,取决于控制台变量)条射线,命中了体素则从Voxel Pool中取得Radiance,否则采样Skylight,将Radiance投影成SH系数存储到Shared Memory,最后进行Reduction并将结果存储到3D纹理。

回头修改Voxel Lighting Pass,我们根据体素的Index找到其所在的Block,因为Probe和Block是一一对应的,我们用Block Index采样上一帧算好的Probe SH的3D纹理即可获得当前体素的间接光照结果。代码也非常简单,采样2x2x2的Probe,根据采样点的法线、位置等信息决定接纳或者排除probe,最后手动进行三线性插值。
万事俱备!现在我们的体素是带了直接光+间接光的体素,光线Hit到一个点能够直接获取到Incoming Radiance。此时光看体素的颜色,整个GI已经初现端倪。
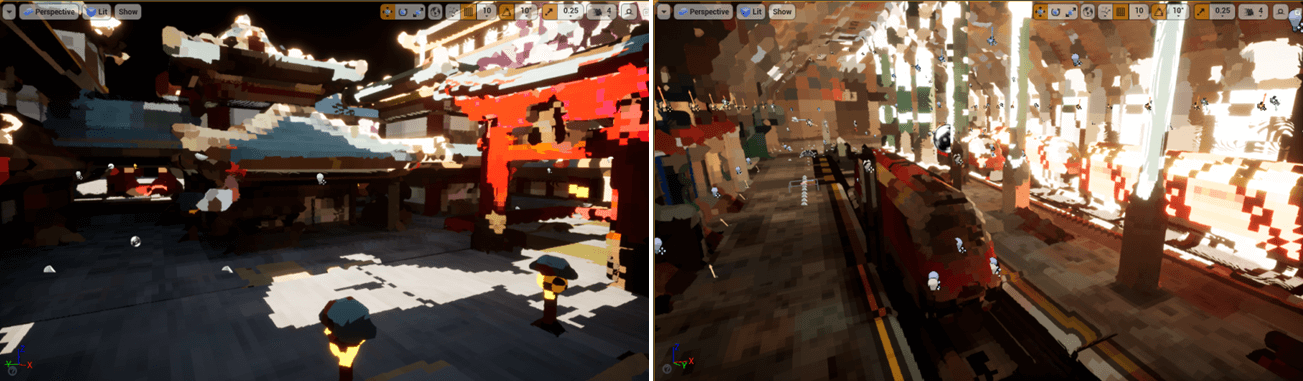
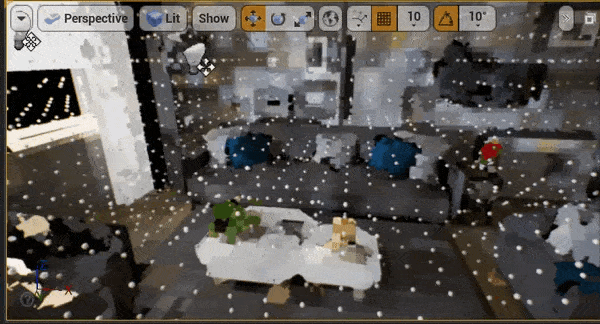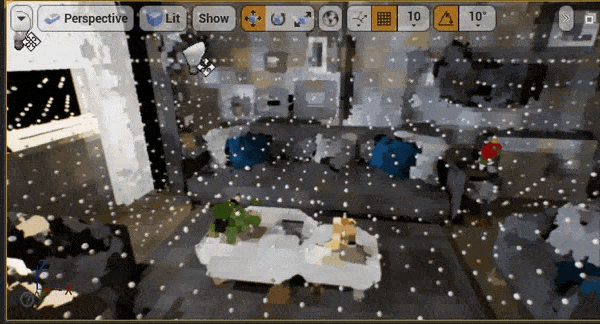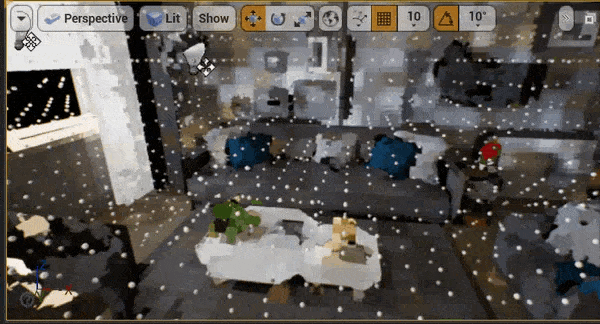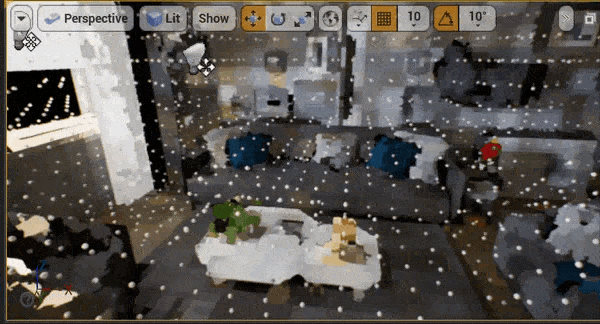
八、性能
我们用EPIC商店的免费场景Modular Asian Medieval City为例,该场景包含了8000个Primitive,其中进入体素场景GPU Scene的Primitive数量为7500。
笔者的电脑为3060 Laptop(挣韭者),使用的体素精度为最小ClipMap层级0.2m,每帧允许的Update Chunk为64个,此外为了开发方便控制台变量默认开启r.Shaders.Optimize=0,没有试过Cook后的情况。
UE引擎编辑器以4档位进行不间断相机移动以触发体素更新,体素注入部分会产生0.1~0.2ms的开销(图1)剩下0.5ms为距离场传播的开销(图2)。

对于体素光照部分,因为我们使用棋盘格的分帧更新策略,帧耗时会根据体素布局有跳变,平均在1.2ms。我们选取一个峰值帧进行查看,主要开销在为每一层级的体素计算直接光、以及Probe Gather计算间接光上面。
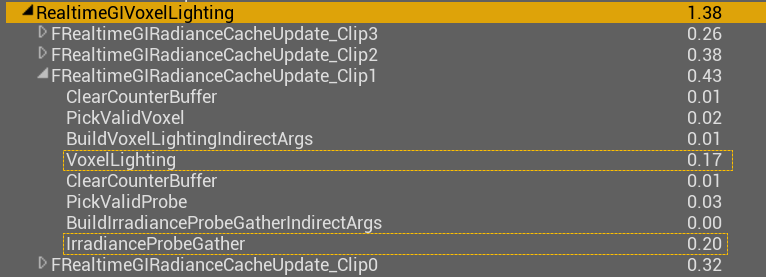
注:这里clip0的开销非常小是因为一个优化,最低层级的ClipMap不进行Probe Gather,而是复用上一层clip1的Probe Irradiance,这个优化在室外场景非常好用,但是室内场景容易漏光。
九、阶段性总结
到这里,历经艰难险阻。我们攻克了软件光追的三座大山,成功把大象装进冰箱。一起来看看我们都干了什么:
- 为了体素注入,我们实现了一套Mesh Card的生成和管理系统
- 为了高效地剔除Object,我们实现了一套简易的GPU Scene
- 为了存储体素的材质信息和Radiance,我们实现了一套简易的体素分页内存管理系统
- 为了可见性查询,我们实现了距离场和体素HDDA两种软件光线追踪算法
- 为了计算体素的直接光和间接光,我们实现了简易的离屏Deferred Shading,以及类似DDGI的Probe Gather系统
到这里我们的GI之旅其实才进行到一半。在后面的文章中我们将重点介绍如何对屏幕像素进行Final Gather、如何使用各种奇技淫巧来降噪。
十、代码仓库
https://github.com/AKGWSB/UnrealEngine/tree/4.27-akgi
引擎部分的代码位:
Engine\Source\Runtime\Renderer\Private\RealtimeGI
着色器部分位于:
Engine\Shaders\Private\RealtimeGI
十一、参考与引用
HSGI: Cross-Platform Hierarchical Surfel Global Illumination
Radiance Caching for Real-Time Global Illumination
UE5.1 Lumen Indirect Diffuse Lighting技术分析
这是侑虎科技第1738篇文章,感谢作者AKG4e3供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/long-ruo-li-21
再次感谢AKG4e3的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号