浅谈Unity纹理串流系统Mipmap Streaming System
写在前面
Unity自从2018.3版本开始推出了纹理串流系统,即Texture Streaming System,在Unity官方文档中,其名为The Mipmap Streaming System。虽然说纹理串流系统是一项比较先进的技术,若使用得当可以有效减少纹理占用内存与提高加载速度,但在使用的过程中依然会面临不少的坑,导致目前实际使用该系统的项目并不算多。本文将浅谈Unity的纹理串流系统,对该系统的运行策略进行合理猜测,并对其众多的参数与Texture原生的一些参数进行测试,对其进行简单分析和总结,如果有不对的地方欢迎批评斧正。
Unity版本:2021.3.12f1
Platform: Antroid
渲染管线:URP
测试机:HUAWEI P30 测试工程
Github地址:https://github.com/recaeee/Unity-Mipmap-And-Texture-Streaming
Mipmap
Mipmap本身原理在此就不做过多介绍(Mip实际是原始纹理的下采样版本),网上有很多相关文章,推荐观看GAMES 101课程,,其主要目的就是解决摩尔纹等现象(Pixel和Texel实际尺寸不匹配)。当一个Texture开启Mipmap后,其占用的内存会变为原本的4/3倍。值得注意的是,Mipmap本身是针对于3D物体而言的,对于如UI使用的Texture,我们几乎是不需要对其开启Mipmap的。
首先在这里详细说一下Unity在运行时是如何使用Mipmap的(不开启Texture Streaming,只考虑移动平台,各平台原理类似,内存结构可能有所不同)。
参考Unity官方文档:
https://docs.unity3d.com/cn/2021.3/Manual/texture-mipmaps-introduction.html
- 当渲染一个使用Mipmap纹理的GO时,CPU会先从磁盘上把该Texture的所有Mip等级都加载到显存中。
- 当GPU对纹理进行采样时,它会根据当前像素的纹理坐标和GPU计算的两个内部值DDX和DDY来确定要使用的Mipmap等级,也就是根据像素在场景中覆盖的实际大小找到与之匹配的Texel大小,根据该Texel大小决定要使用的Mip等级。补充说明,DDX和DDY提供有关当前像素旁边和上方像素的UV的信息,包括距离和角度,GPU使用这些值来确定有多少纹理细节对相机可见。
纹理串流 Texture Streaming
在Unity中,纹理串流技术叫做The Mipmap Streaming System,其作用是让Unity根据摄像机的位置只加载对应Mipmap Level的纹理到显存中,而不是把所有Mipmap Level全加载到显存中让GPU根据摄像机位置使用对应的Mipmap Level。
1. Mipmap加载疑问
在这里,我有一点疑问,在开启Texture Streaming后,如果说加载的Mipmap Level为2,那更高级的Mipmap Level会加载进显存吗?因此我搭建了测试工程进行试验。
在测试工程中我使用了一张2048*2048且开启Mipmap的纹理,首先不开启Texture Streaming,打包到真机测试,抓取内存,发现这张Texture共占用了2.7M的内存。而在不开启Mipmap时,该纹理占用内存为2.0MB,可得开启Mipmap后该纹理占用内存变为原来的1.35倍(与4/3倍接近)。因为0级Mip占用内存2M,我们可以大致推算出1级Mip占用内存为0.5MB,2级Mip占用内存为128KB,3级Mip占用内存为32KB。

接下来开启Texture Streaming并通过Texture Streaming System使Mip加载到Mip1等级,抓取内存,如下图所示Texture占用了0.7MB,由此得出,仅仅Mip0被卸载,而Mip1~n都依然在显存中。

同理,再让其加载到Mip2,抓取内存,如下图所示Texture占用了171KB,推理可得出为(2.7-2-0.5)MB,接近0.2MB。

由此可得出结论:一张Texture具有0~n级Mip,开启Texture Streaming之后,如果Unity计算出的Mip等级为x,则Unity会将该Texture的x~n级Mip都加载到显存中,也可以理解为丢弃掉0~(x-1)级Mip。(在后文中所说加载Mip等级x,意思都是加载Mip等级x~n。)
其实也非常有道理,对于使用开启Mipmap的纹理的一个GO,我们不一定只会用到1张Mip,因为如果GO是一个长条型,远处的像素可能还是会使用更高等级的Mip。只是说Texture Streaming System会把必不可能用到的几个低等级的Mip丢弃,不加载到显存中(或者从显存中卸载)。
2. Texture Streaming加载逻辑
在开启Texture Streaming后,Unity使用Mipmap的方式会发生一定变化,因为显存中只会存储需要加载的Mipmap Level。其运行时使用步骤大致如下(开启Texture Streaming,不考虑纹理串流预算、MaxLevelReduction等因素,后面会详细说明)。
(1)当渲染一个使用Mipmap纹理的GO时,CPU将最低Mipmap等级(人为设置)的Mip异步加载到显存中。
(2)GPU先使用这些低级Mipmap渲染GO。
(3)CPU计算出该GO必不可能用到Mip等级,比如计算出x意味着只可能会用到x+1~n级Mip,将x+1~n级Mip加载到显存中。
(4)当GPU对纹理进行采样时,它会根据当前像素的纹理坐标和GPU计算的两个内部值DDX和DDY来确定要使用的Mipmap等级,也就是根据像素在场景中覆盖的实际大小找到与之匹配的Texel大小,根据该Texel大小决定要使用的Mip等级。补充说明,DDX和DDY提供有关当前像素旁边和上方像素的UV的信息,包括距离和角度,GPU使用这些值来确定有多少纹理细节对相机可见。
2.1 纹理异步加载 AUP
使用Texture Streaming有一个好处是,加载一个物体时会先异步加载一个较高等级的Mip,让物体被较快地渲染出来,之后再使用较低等级的Mip,展现高精度的纹理细节。反应到游戏内就是,加载物体时,先呈现出较为模糊的纹理,再呈现出较为精细的纹理。
这里提几句纹理异步加载的原理(异步上传管线AUP),主要参考了官方文档和文章《优化加载性能:了解异步上传管线AUP》。
在同步上传管线中,Unity必须在单个帧中同时加载纹理或网格的元数据(标头数据)、纹理的每个Texel或网格的每个顶点数据(二进制数据)。在异步上传管线中,Unity必须在单个帧中仅加载标头数据,并在后续帧中将二进制数据流式传输到GPU。
同步上传管线中,在项目构建时,Unity会将同步加载的网格或纹理的标头数据和二进制数据都写入同一.res文件(res即Resource)。在运行时,当程序同步加载纹理或网格时,Unity将该纹理或网格的标头数据和二进制数据从.res文件(磁盘中)加载到内存(RAM)中。当所有数据都位于内存中时,Unity随后将二进制数据上传到GPU(DrawCall前)。加载和上传操作都发生在主线程上的单个帧中。
异步上传管线中,在项目构建时,Unity会将标头数据写入到一个.res文件,而将二进制数据写入到另一个.resS文件(S应该指Streaming)。在运行时,当程序异步加载纹理或网格时,Unity将标头数据从.res文件(磁盘中)加载到内存(RAM)中。当标头数据位于内存中时,Unity随后使用固定大小的环形缓冲区(一块可配置大小的缓冲区)将二进制数据从.resS文件(磁盘中)流式传输到GPU。Unity使用多个线程通过几帧流式传输二进制数据。
此外需要注意的是,如果项目构建在安卓平台,需要启用LZ4压缩才能启用纹理异步加载(而因为Texture Streaming System使用到了纹理异步加载,因此Texture Streaming System的前提条件也是LZ4压缩)。
从Unity 2018.3 beta开始,资源上传管线Async Upload Pipeline用于异步加载纹理和网格(可读写纹理和网格、压缩网格不适用于AUP)。
在AUP异步加载纹理时,第一帧将会加载.res标头数据(纹理的元数据)到内存中,再流式传输.resS二进制数据(纹理的每个Texel)。在流式传输.resS过程中,AUP会执行以下逻辑。
(1)等待CPU上的环形缓冲区内出现空余的内存空间。
(2)CPU从磁盘上的.resS文件中读取一部分二进制数据,将其填入第1步中环形缓冲区的空余内存内。
(3)执行一些后期处理过程,例如纹理解压、网格碰撞生成、每个平台的修复等。
(4)以时间切片的方式在渲染线程进行上传,即每一帧花n个时间切片的CPU时间将环形缓冲区内的数据(数据量由时间切片的持续时间决定)传递给GPU。
(5)释放环形缓冲区上已传递给GPU过的内存。
AUP在运行时可控制的参数包含三个,分别为QualitySettings.asyncUploadTimeSlice(即每帧内第4步时间切片的时间总量)、QualitySettings.asyncUploadBufferSize(环形缓冲区的大小)、QualitySettings.asyncUploadPersistentBuffer(决定完成当前所有读取工作后,是否释放环形缓冲区)。这三个参数具体如何使用可参考文章《优化加载性能:了解异步上传管线AUP》,在此不做过多深入。
3. 使用Texture Streaming
以下为使用Texture Streaming的一些说明。
3.1 设置参数
这一块比较多参考官方文档,更详细的说明请参考官方文档。

Add All Cameras:是否对项目中的所有摄像机开启纹理串流。(默认开启)
Memory Budget:设置开启纹理串流时加载的纹理内存最大值。(默认512MB)
Renderers Per Frame:设置CPU每帧纹理串流系统处理多少个Renderers(即对于一个Renderer,在CPU端计算出需要传递哪几级Mipmap并传递给显存)。该值较低时会降低每帧CPU处理纹理串流的压力,但会增加Unity加载Mipmap的延迟。
Max Level Reduction:设置当超过纹理预算时纹理串流能丢弃的最大Mipmap数。(默认是2,意味着最多丢弃2张最低级的Mipmap)同时,这个值也决定了纹理初始化加载时会加载Max Level Reduction级的Mipmap。
Max IO Requests:设置纹理串流系统的纹理文件IO请求的最大数量。(默认是1024)
3.2 让纹理支持Mipmap Streaming
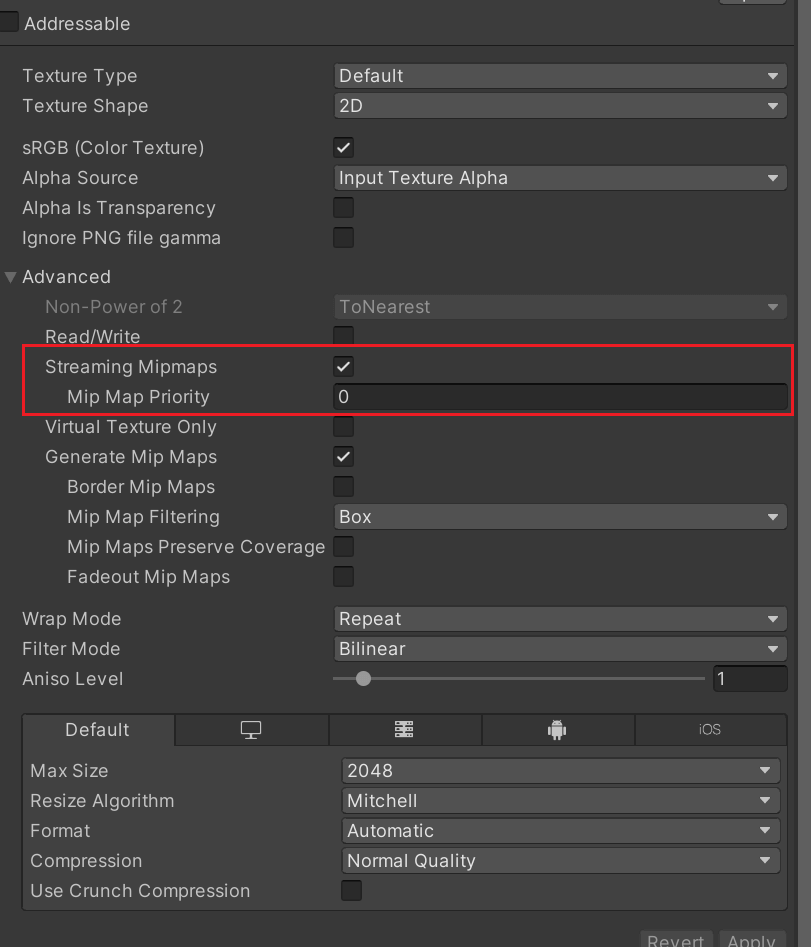
选中需要启用纹理串流的Texture Asset,在其Inspector的Advanced标签下勾选Streaming Mipmaps。对于安卓平台开发,需要在Build Settings中使用LZ4或者LZ4HC的压缩格式。Unity需要这些压缩方式来实现异步纹理加载,异步纹理加载是实现纹理串流系统的必要技术。
在对Texture Asset勾选Streaming Mipmaps之后,出现Mip Map Priority属性,该属性表示该纹理在Mipmap Streaming System中分配资源的优先级。Priority值越大,优先级越高,其范围为[-128,127]。
Lightmaps同样支持纹理串流,操作方式和Texture Asset一样。但是在Unity重新生成光照贴图时,其设置会重置为默认值。通过在Project Settings里可以设置生成光照贴图时对应纹理串流系统的默认配置。
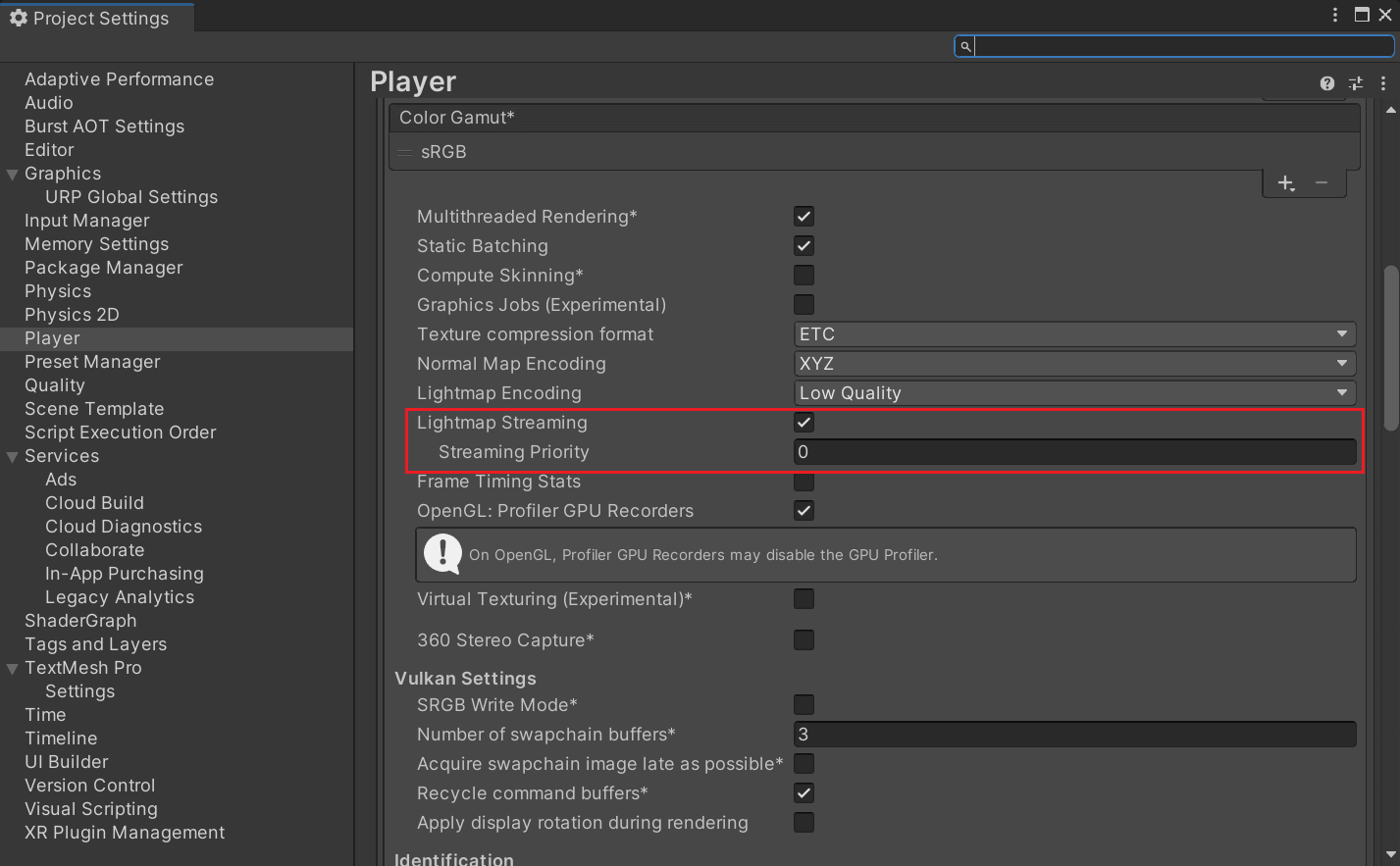
3.3 配置Mipmap Streaming
首先,我们需要配置Memory Budget,即内存预算,当运行时Texture占用内存超过Memory Budget时,Unity会自动丢弃没有使用到的Mipmaps,通过设置Max Level Reduction属性可以控制Unity丢弃的Mipmaps。同时Max Level Reduction也代表了Mipmap Streaming System在初始加载一张Texture时加载的Mipmap等级。
注意:Max Level Reduction在Mipmap Streaming System中优先级比Memory Budget高,意味着即使会超出Budget,纹理依旧会加载Max Level Reduction级别的Mip到显存中。
3.4 配置摄像机
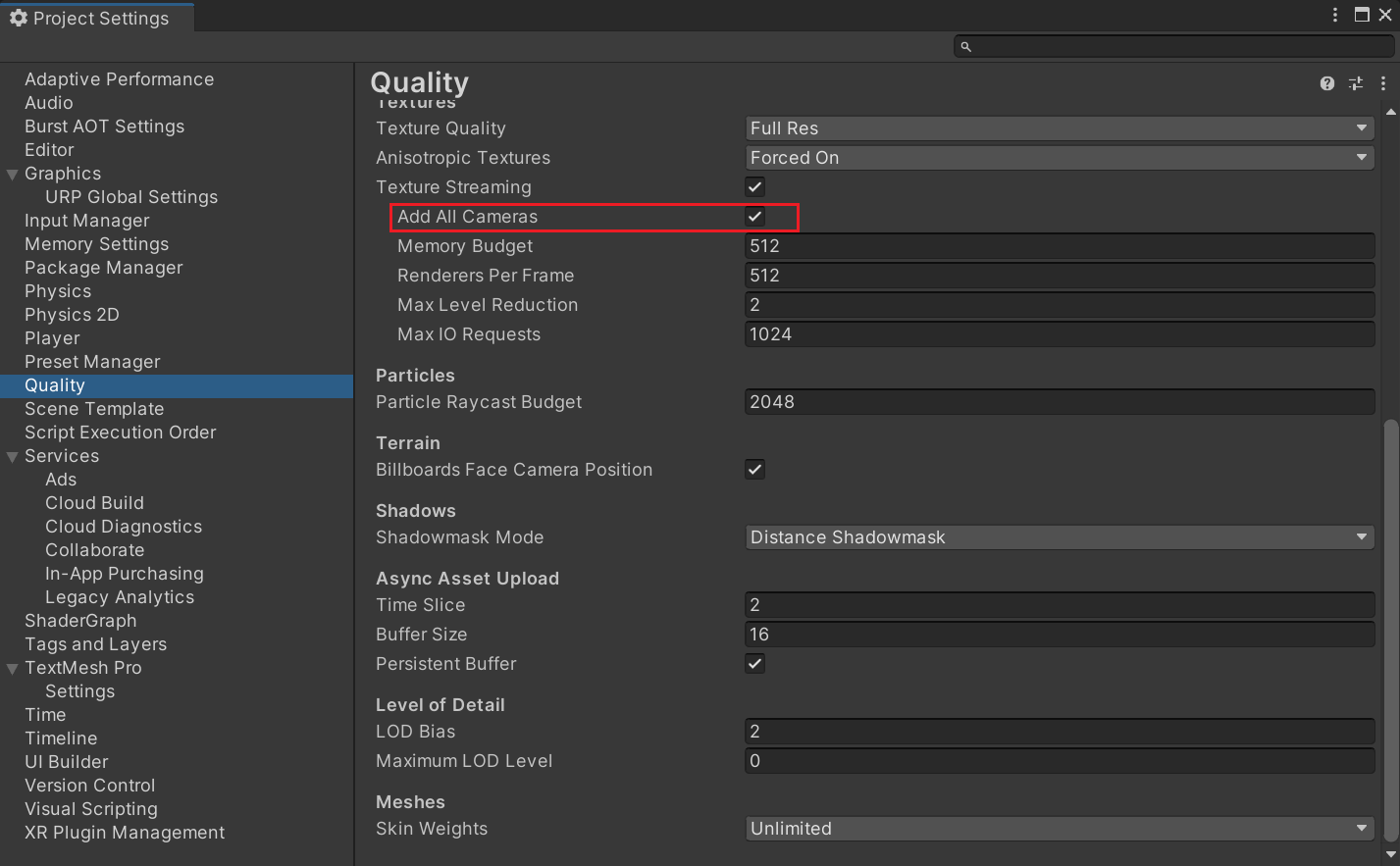
当开启Mipmap Streaming System后,Unity默认会对所有摄像机启用它。我们可以通过在Quality Settings中通过设置Add All Cameras来配置是否对所有摄像机开启Mipmap Streaming System。
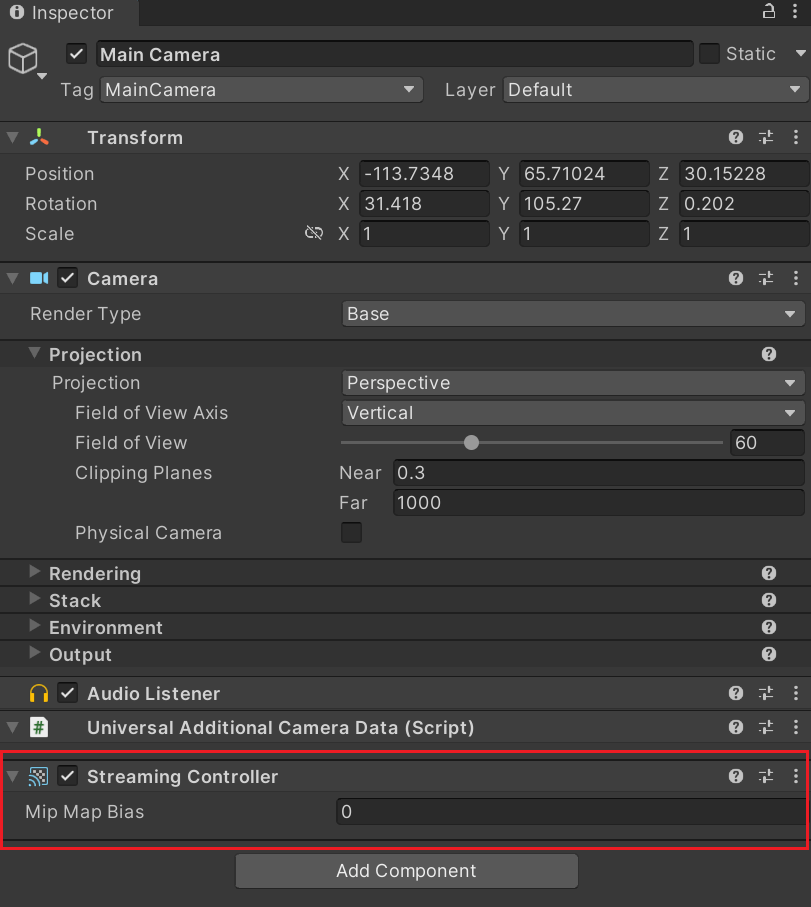
如果说想对单独的摄像机做配置,我们需要在摄像机上增加一个Streaming Controller组件,如果不想要让这个摄像机开启纹理串流,则直接Disable这个组件。同时这个组件也允许我们去调整该摄像机的Mip偏移。
如果说项目中UI使用单独一个摄像机渲染,那我们就没必要对UICamera也开启纹理串流,因此没必要在QualitySettings中激活Add All Cameras,只需要在渲染场景的摄像机上增加Streaming Controller组件。
3.5 配置启用环境
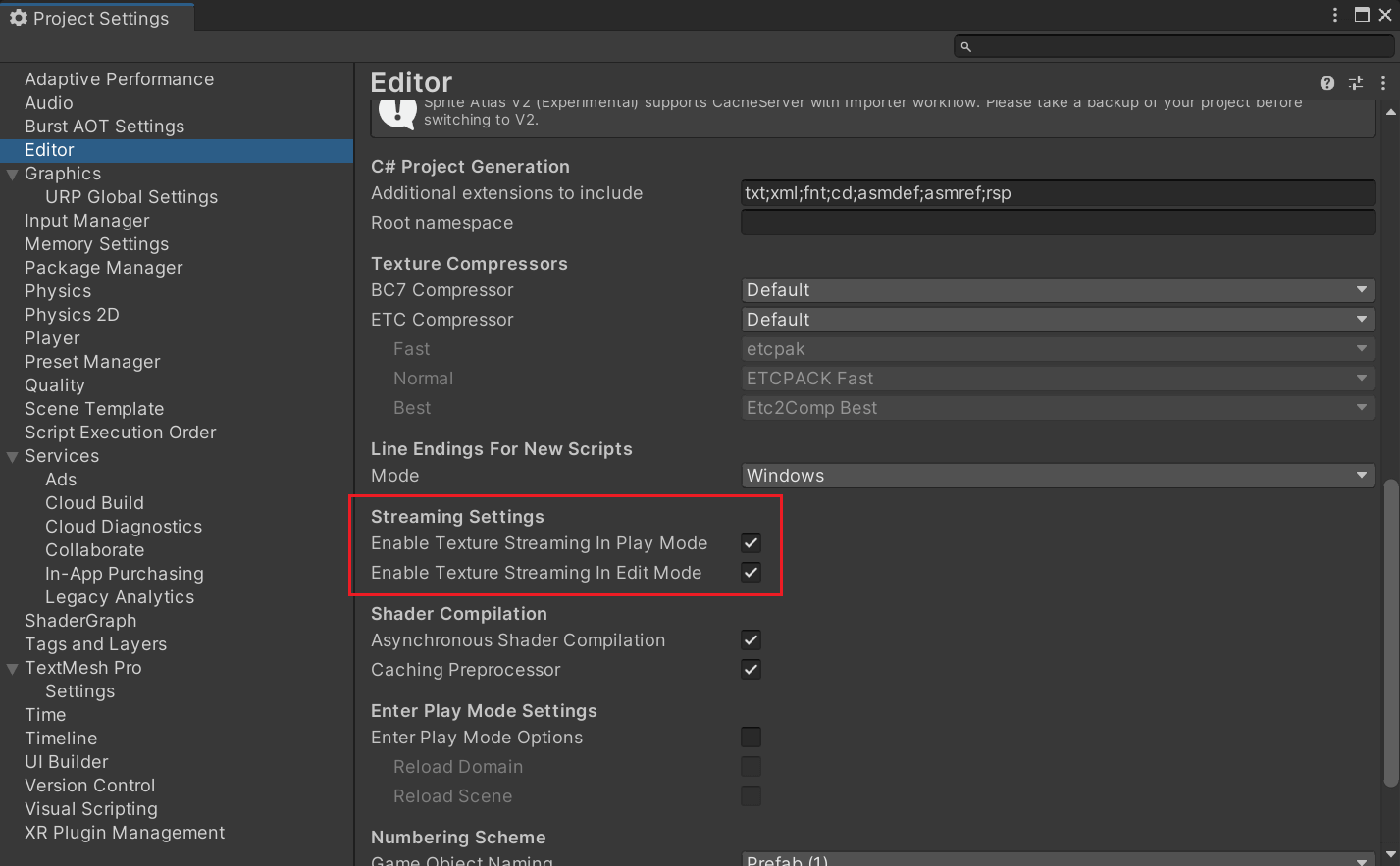
Mipmap Streaming默认只在Play Mode下启用,我们可以在Editor Settings中设置它在Editor、Play两个Mode中是否启用。
3.6 调试Mipmap串流
在Built-in管线中,Unity的Scene视图中的下拉菜单中会有一个Texture Streaming的绘制模式,它会根据游戏对象在Mipmap系统中的状态,显示为绿色、红色和蓝色。具体可以参考官方文档。
对于非Built-in管线,可能就需要在管线中手动实现Shader替换(比如插入一个Render Feature)。
3.7 一些常用参数
Texture.currentTextureMemory:所有纹理当前使用的内存量。
Texture.streamingTextureDiscardUnusedMips:该值默认为False,当其设置为True时,Unity会强制纹理串流系统去丢弃所有未使用的Mipmap而不是缓存它们。因为纹理串流系统也是使用一个类似内存池的管理方式,假设物体距离摄像机变远,此时计算出的Mip等级变高,但纹理串流系统不会立即卸载低级Mip并使用计算出的Mip,而是当其他纹理需要加载且Budget不够时再考虑卸载当前内存池中未使用到的Mips,即从远到近查找未使用的Mip(这一点经过测试验证过,测试结果如下两图所示)。


从这点看出,当Texture.streamingTextureDiscardUnusedMips未开启时,Mipmap Streaming System的卸载无用Mip逻辑是被动触发的(类似于事件,当新纹理加载且预算不足时触发,应该是会降低CPU计算量,也是利用上缓存,减少IO消耗)。而当Texture.streamingTextureDiscardUnusedMips开启后,Mipmap Streaming System的卸载逻辑变为每帧主动触发,即每帧都会严格按照Mip计算出的等级实际应用于GO上。
4. Texture Streaming System管理策略
其实网上对于Texture Streaming System具体的解析少之又少,在此我首先参考UWA学堂《Unity引擎加载模块和内存管理的量化分析及优化方法》中对Texture Streaming System策略进行简单概括,有兴趣的同学可以购买原课程观看。
对于整个纹理串流系统来说,最重要的两个参数就是Memory Budget(纹理串流预算)和Max Level Reduction()。Memory Budget决定了当纹理内存占用到多少之后Unity开始真正使用Texture Streaming System去管理Mipmap的内存;Max Level Reduction决定了最大加载的Mipmap等级(Mipmap等级越高越模糊)。对于Memory Budget来说,Unity的默认值为512MB,但是对于一般的手机项目而言,设置为200MB左右比较合适(但实际看需要修改该值)。
对于运行时,Texture Streaming System管理策略概括如下:
(1)当Non Streamed Texture(未开启Mipmap Streaming的Texture)需要被加载时,其会被完全加载到内存中,如果加载的Texture具有Mipmap 0~n,则Mipmap 0~n都会被加载到内存中。
(2)在加载Scene时,如果Budget足够,Scene中的GO所使用的Texture会完全加载,即加载Mipmap 0~n级;如果Budget不足,则按Max Level Reduction加载。
(3)动态加载的GO Texture在Load和Instantiate时(在此时可能并未实际渲染该物体),Unity会始终首先加载其Max Level Reduction级的Mipmap到内存中,这样做的好处是加载速度会变快,因为只需要加载一个Mipmap等级,占用的内存会少,另外Texture Streaming System会为其使用纹理异步加载。
(4)在我们实际需要渲染GO时(当Instantiate GO后,我们可能需要立刻渲染该物体,或者该物体Active后出现在摄像机内等等情况),CPU会按照当前空闲的纹理串流预算和摄像机和物体之间的距离等等因素去计算当前需要加载的Mipmap等级。如果Budget足够,则加载计算出的Mipmap等级;如果Budget不足,则依然加载Max Level Reduction级别的Mipmap。
(5)在运行时,当我们需要加载一个新的Texture且当前纹理占用内存超过了预算,Texture Streaming System会想办法开始减少Texture占用的内存。对于Scene自带的所有GO,Unity会以距离摄像机从远到近的顺序重新计算来判断其是否真正需要加载当前其Mipmap等级,如果不需要则会卸载其过高的Mipmap等级,以此给出内存空间给到新加载的Texture。此时,对于需要加载的新Texture,如果其计算出的Mipmap等级可以加载(即空闲内存足够)则加载其计算出来的Mipmap等级;如果不能加载(在按策略卸载部分GO不需要的Mipmap后,内存还是不够),则加载Max Level Reduction级别的Mipmap。从这一点也可以看出,对于一个Texture,其实际加载的最大Mipmap等级就是Max Level Reduction(即使会超出Budget也会加载这一等级)。
5. 几个关键点
此外,UWA课堂中也提到了几个使用Texture Streaming System的关键点,也算是他们踩过的坑。
(1)移动端一定要通过代码设置QualitySettings.streamingMipmapsActive = true。如果只是在QualitySettings中手动勾选,则Editor下会起作用,但移动端可能会出现不起作用的情况。
(2)Unity版本升级后,可能会使纹理变糊。解决方法:开一个新项目,把所有Mesh、Texture原封不动拷贝过去。
(3)不要相信Editor Profiler,直接在真机上测试。这一点非常重要,在Editor下的纹理占用内存量会比真机大得多(可能是使用的资源路径不同),同一情况下,在Editor下纹理占用可能到达300MB,但在真机上可能只有30MB。因此一切Texture Streaming相关的测试一定要放在真机上进行!
(4)在不激活Texture.streamingTextureDiscardUnusedMips的情况下,Mip被丢弃的时机(指已加载的Mip从显存中卸载)应该只有一个,即当前纹理串流预算不足,且需要加载新的Mip Streaming Texture,此时从远到近查找不需要使用的Mip卸载。这也就意味着直接拉远镜头并不会立即触发Mip等级的降低,因为之前我以为拉远了镜头就应该使用模糊的Mip了,这一点比较重要,一开始以为是Bug。
6. Mipmap偏移MipmapBias
在实际项目中,我们可能需要针对不同性能的机型使用Mipmap偏移。要想达到Mipmap偏移有几种方法:
(1)QualitySettings.masterTextureLimit:其默认值为0,将其值设置为x,会对所有开启Mipmap的Texture2D资源(不管是否开启Mipmap Streaming)使用第x级Mipmap。
(2)Texture.mipMapBias:对于单个Texture设置其Mipmap偏移。
(3)Streaming Controller组件上的Mip Map Bias:此值只在QualitySettings.AddAllCamera未启用,且在Camera上激活Streaming Controller时起作用。此设置会针对当前摄像机需要渲染的Renderer其使用的Texture(开启Mipmap Streaming的Texture)进行Mipmap偏移,比较推荐使用这一种方法。
在第三种方法中,MipmapBias的优先级是低于MaxLevelReduction的,举例来说如果当前MaxLevelReduction=3,MipmapBias=2,计算出的Mip等级为2,理论上应该使用Mip4,但因为MaxLevelReduction=3,所以最后会加载Mip3(即加载Mip3 ~ n到显存中)。
接下来对三种使用方法进行测试。
对于方法1,其实际使用的Mip等级并不会反应在Texture.loadedMipmapLevel上,Texture.loadedMipmapLevel返回的是串流系统当前加载的Mipmap级别。通过QualitySettings.masterTextureLimit进行Mip偏移会将低等级Mip从显存中卸载,达到内存优化的效果。测试结果如下图所示。

对于方法2,其控制单个纹理的Mipmap偏移。该方法对开启Mipmap的纹理起作用,与是否开启Streaming无关。
对于方法3,它是在Mipmap Streaming System中对Mip进行偏移的,其使用条件比较繁琐,但其也是最合理的一种使用方法,即只对需要的摄像机、需要的纹理进行开启Mipmap偏移。对于方法3,因为涉及到了Mipmap Streaming System的管理测换,因此进行了比较详细的测试。
首先测试不开启MipmapBias的情况,进入测试场景,Budget为10,MaxLevelReduction为5,摄像机上的MipmapBias为0,目前已使用纹理内存为7.5MB,低于Budget。

此时降低Budget到7(实际纹理占用内存为8),触发了Budget不足时卸载Mip的逻辑,此时wlop纹理的Mip等级变为了1,即从显存中卸载了Mip0。
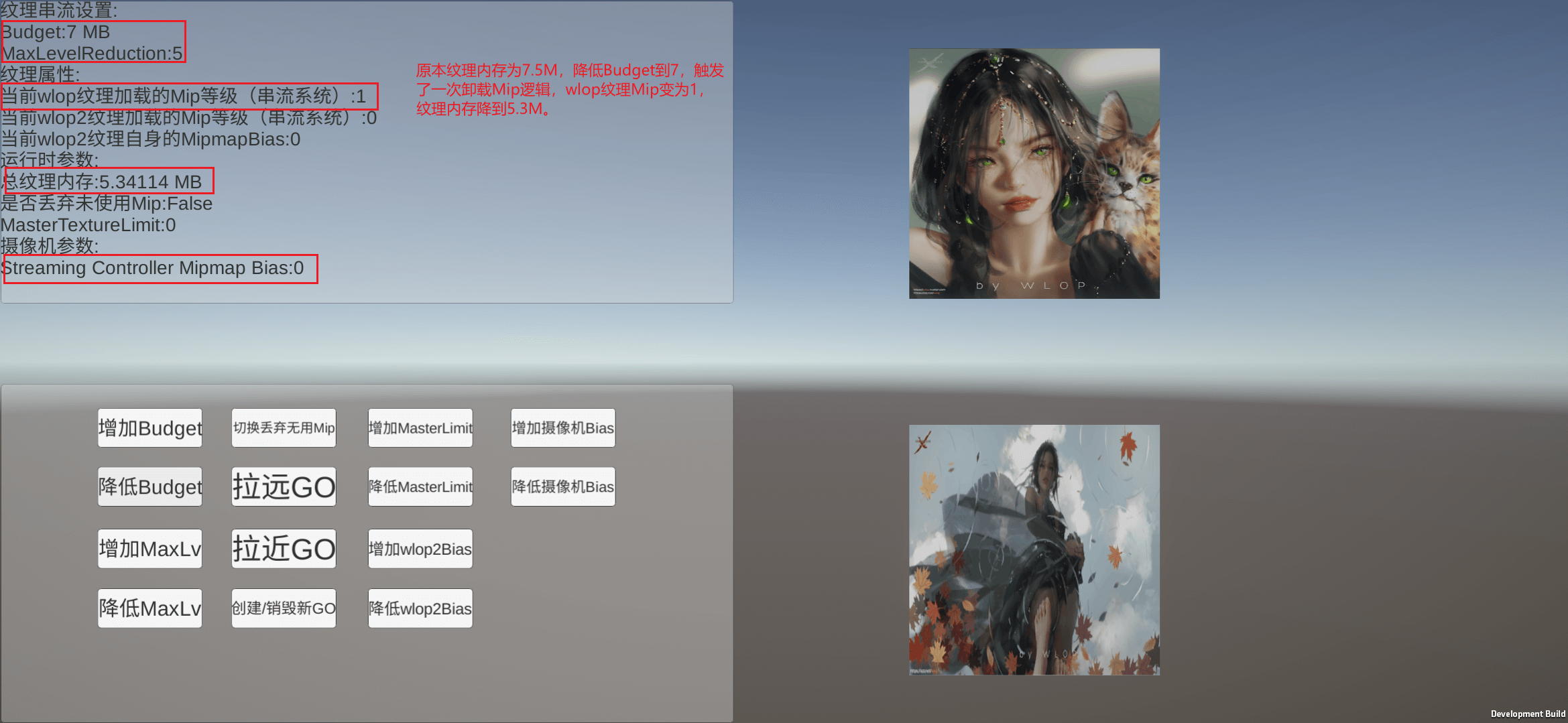
接下来测试MipmapBias=2的情况,进入场景,MipmapBias调整到2,如下图所示,虽然目前我们将MipmapBias调整到了2,但是wlop纹理使用的Mip等级依然是0,内存也没变化,因此调整MipmapBias并不会即时生效。
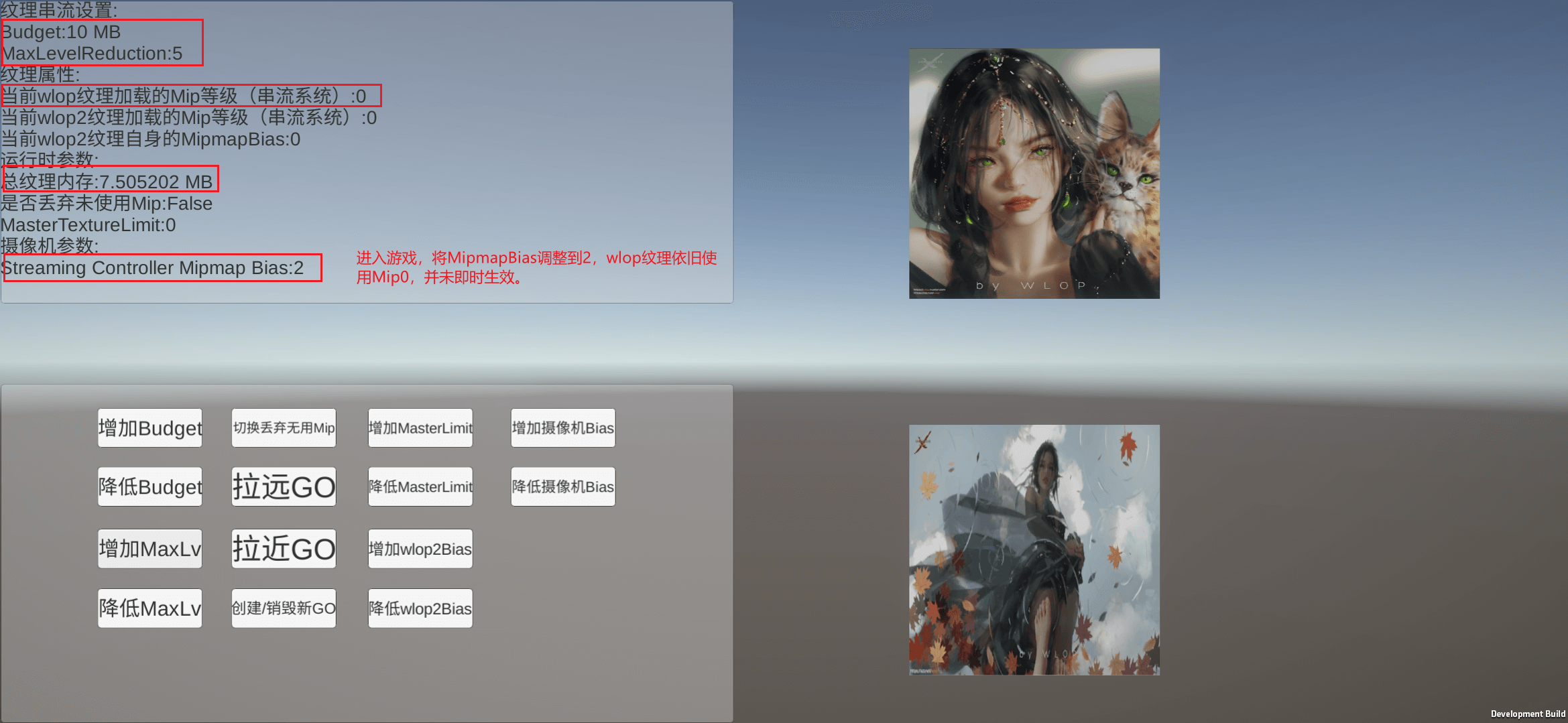
然后再将Budget降低到7触发卸载逻辑,如下图所示,wlop纹理的Mip等级变化为3(MipmapBias为0时变化为1),此时MipmapBias生效。

从这点看出,MipmapBias会在Mipmap Streaming System计算Mip等级的时候才生效(在Texture.streamingTextureDiscardUnusedMips开启后会实时生效,在前文中提到过,开启后Mip计算逻辑会每帧主动触发),而计算Mip等级的时机也就是第4点Texture Streaming System管理策略里提到的那些。虽然说这里我是通过调整Budget来触发的卸载逻辑,但至于真正项目里是否需要动态调整Budget网上也没有相关人提到过(目前实际使用该系统的商业项目应该也只占少数),因此不确定该方法能否实际应用。
7. 调试纹理串流系统
在Built-in管线中,Unity原生提供了Mipmap Streaming的调试工具,具体可参考官方文档。由于本文使用的是URP管线,无法使用Unity原生工具,因此自己参考官方提供的调试Shader手写了一个简单的Shader来用于调试。为了不在每个Shader中增加一个Pass用于调试,我选择在运行时将所有材质的Shader替换成调试Shader的方法,毕竟不用考虑性能(本来考虑RenderFeature的方法,比较好热插拔,但是就关于如何获取原材质的MainTex问题难以得到解决,因此使用这种方法)。
在该调试用Shader中,由于不考虑性能问题,我写得比较粗糙,用了很多if判断,在实际运用中,大家可以根据需要自己编写Shader使用。大致思路就是,首先每一帧需要执行一个Texture.SetStreamingTextureMaterialDebugProperties(),通过每帧执行该函数,Unity会把每个材质上使用到的开启Mipmap Streaming的纹理的一些Mipmap信息(例如该纹理的Mip总数、当前使用的Mip等级等)传递给着色器,在着色器中通过类似"_MainTex_Mipinfo"(写法类似_MainTex_ST)来获取。然后就可以在Shader里根据当前Mip等级反应出不同的颜色用于将Mip等级可视化了。
我写的Shader代码如下。
Shader "Tool Shaders/MipmapDebugger"
{
Properties
{
_MainTex("Main Tex",2D) = "white"{}
_NonMipColor("Non Mip Color",Color) = (0.5,0,0.2,1)
[Header(Debug Color)]
_Mip0Color("Mip 0 Color",Color) = (0,1,0,1)
_Mip1Color("Mip 1 Color",Color) = (0,0.7,0,1)
_Mip2Color("Mip 2 Color",Color) = (0,0.5,0,1)
_Mip3Color("Mip 3 Color",Color) = (0,0.3,0,1)
_MipHigherColor("Mip Higher Color",Color) = (0,0.2,0,1)
[Header(Debug Settings)]
_BlendWeight("Blend Weight",Range(0,1)) = 0.7
}
Subshader
{
Pass
{
HLSLPROGRAM
#pragma vertex MipmapDebugPassVertex;
#pragma fragment MipmapDebugPassFragment;
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary//Core.hlsl"
TEXTURE2D(_MainTex);SAMPLER(sampler_MainTex);float4 _MainTex_ST;float4 _MainTex_MipInfo;
float4 _NonMipColor, _Mip0Color, _Mip1Color, _Mip2Color, _Mip3Color, _MipHigherColor;
float _BlendWeight;
struct Attributes
{
float3 positionOS:POSITION;
float2 uv:TEXCOORD0;
};
struct Varyings
{
float4 positionCS: SV_POSITION;
float2 uv:TEXCOORD0;
};
int GetMipCount(Texture2D tex)
{
int mipLevel,width,height,mipCount;
mipLevel = width = height = mipCount = 0;
//in参数:mipmapLevel
//out参数:width:纹理宽度,以纹素为单位
//out参数:height:纹理高度,以纹素为单位
//out参数:mipCount:纹理mipmap级别数
tex.GetDimensions(mipLevel,width,height,mipCount);
return mipCount;
}
float3 GetCurMipColorByManualColor(float4 mipInfo)
{
//mipInfo:
//x:系统设置的maxReductionLevel
//y:纹理的mip总数
//z:纹理串流系统计算出应该使用的纹理Mip等级
//w:当前加载的Mip等级
int desiredMipLevel = int(mipInfo.z);
int mipCount = int(mipInfo.y);
int loadedMipLevel = int(mipInfo.w);
if(mipCount == 0)
{
return _NonMipColor;
}
else
{
if(loadedMipLevel == 0)
{
return _Mip0Color;
}
else if (loadedMipLevel == 1)
{
return _Mip1Color;
}
else if(loadedMipLevel == 2)
{
return _Mip2Color;
}
else if(loadedMipLevel == 3)
{
return _Mip3Color;
}
else if(loadedMipLevel > 3)
{
return _MipHigherColor;
}
else
{
return _NonMipColor;
}
}
}
float4 GetCurMipColorByAuto(float4 mipInfo)
{
//mipInfo:
//x:系统设置的maxReductionLevel
//y:纹理的mip总数
//z:纹理串流系统计算出应该使用的纹理Mip等级
//w:当前加载的Mip等级
int desiredMipLevel = int(mipInfo.z);
int mipCount = int(mipInfo.y);
int loadedMipLevel = int(mipInfo.w);
float mipIntensity = 1 - (float)loadedMipLevel / (float)mipCount;
return float4(mipIntensity,0,0,1);
}
Varyings MipmapDebugPassVertex(Attributes input)
{
Varyings output;
output.positionCS = TransformObjectToHClip(input.positionOS);
output.uv = input.uv;
return output;
}
float4 MipmapDebugPassFragment(Varyings input):SV_TARGET
{
float3 originColor = SAMPLE_TEXTURE2D(_MainTex,sampler_MainTex,input.uv);
float3 debugColor = GetCurMipColorByManualColor(_MainTex_MipInfo);
float3 blendedColor = lerp(originColor,debugColor,_BlendWeight);
return float4(blendedColor,1);
}
ENDHLSL
}
}
}
其效果如下视频所示,未开启Mipmap Streaming的纹理将会显示为粉红色,开启Mipmap Streaming的纹理会根据其当前使用的Mip等级呈现不同程度的绿色,绿色越鲜艳代表Mip等级越低。
8. 总结
目前Unity提供的Mipmap Streaming System是一项还算比较先进的技术,如果使用得当可以达到较好地降低纹理内存、加快加载速度的效果,但是在使用的过程中会遇到很多坑,比如其参数与Texture自带的一些参数关系较为混乱、Unity官方并未对其运作原理进行详细解释等,大部分时候只能靠我们去做实验去猜测其运行逻辑,算是比较难驾驭的一项技术,因此也很少看到项目会使用到技术并分享该技术的使用方法(虽然说不同类型的游戏,其使用方法肯定不会相同,但是我仍未看到过一套比较成熟的使用方案)。目前我对Unity纹理串流系统的认识依然比较浅薄,理解也算是比较浅层,也希望能有一些使用过这项技术的同学能分享一些自己的见解吧。
参考
- Mipmaps introduction
- The Mipmap Streaming system API
- 优化加载性能:了解异步上传管线AUP
- Unity3D研究院之给每个贴图指定不同mipmap减低纹理带宽(一百一十四)
- Texture Streaming的使用疑问
- Unity Texture Streaming
- 浅谈Unity中的Mipmap与Texture Streaming技术
- 没弄懂的 Texture Mipmap Streaming (Unity 2018.2)
- Unity引擎加载模块和内存管理的量化分析及优化方法
图片来自WLOP
这是侑虎科技第1348篇文章,感谢作者欧几里得范数供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
作者主页:https://www.zhihu.com/people/ou-ji-li-de-fan-shu-34
再次感谢欧几里得范数的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号