网格切割算法
【博物纳新】专栏回归啦~ 这个专栏是UWA旨在为开发者推荐新颖、易用、有趣的开源项目,帮助大家在项目研发之余发现世界上的热门项目、前沿技术或者令人惊叹的视觉效果,并探索将其应用到自己项目的可行性。很多时候,我们并不知道自己想要什么,直到某一天我们遇到了它。
更多精彩内容请关注:lab.uwa4d.com
一、概览
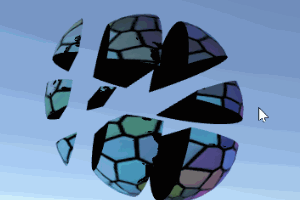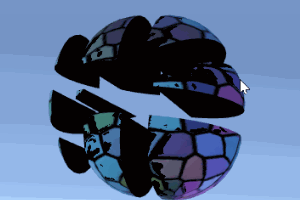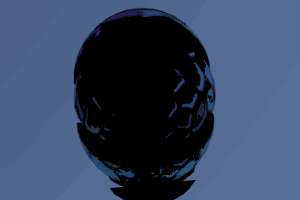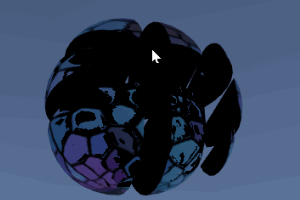

该示例展示了一种简单的3D网格切割算法。在运行状态下,通过在屏幕上拖拽划线,被线条划过的物体就会被线条分成左右两部分。
如果某些游戏需要包含切割物体之类的玩法,或者项目需要对物体切割的辅助工具,那么该插件可以作为良好的借鉴材料。
开源地址:https://lab.uwa4d.com/lab/5b3e3197d6d8c0171a9469b5
二、原理概述
该工具的原理可以分为划线、切割、补齐三部分。
1、划线部分:通过捕捉鼠标在屏幕上的拖拽轨迹,从而获取到切割平面的基本数据信息(如法向量等);
2、切割部分:通过添加点和三角面等操作,把原本的Mesh切割成若干个独立的Mesh,再附着给各个被切开的Objects;
3、补齐部分:把每个被切割的物体的切面补上新的面。
三、具体实现
3.1 划线
这一部作为一个直观的操作,逻辑并不多,主要是要清楚这一部在准备什么数据。下图就是该步骤的主要逻辑:

该方法在MouseSlice.cs脚本中,从中我们可以知道切割物体需要的就是三个三维向量start、end和depth。这三个变量的收集来源ScreenLineRenderer.cs的Update():
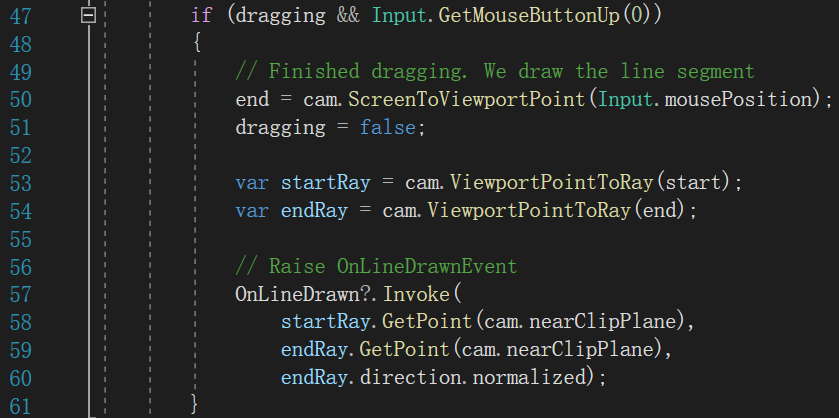
从上图可知,start和end对应于上图的startRay和endRay,分别是从摄像机位置出发,指向划线的起点和终点的两条射线,而depth是endRay的归一化向量。
划线切割物体的本质是划了一个平面来切割3D物体,之所以看起来是一条线是因为摄像机恰好在该平面上,该平面如下图所示。这样看来图1中63行的输入(某个点和法向量)就容易理解了,因为一个点和平面的一条法向量可以确定一个平面。

3.2 切割
切割物体时,我们可以注意到每次切割物体其实都是在实例化一个新的物体:
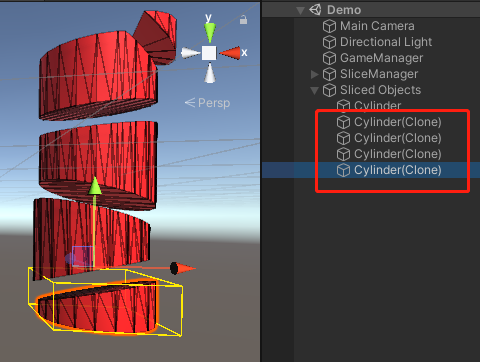
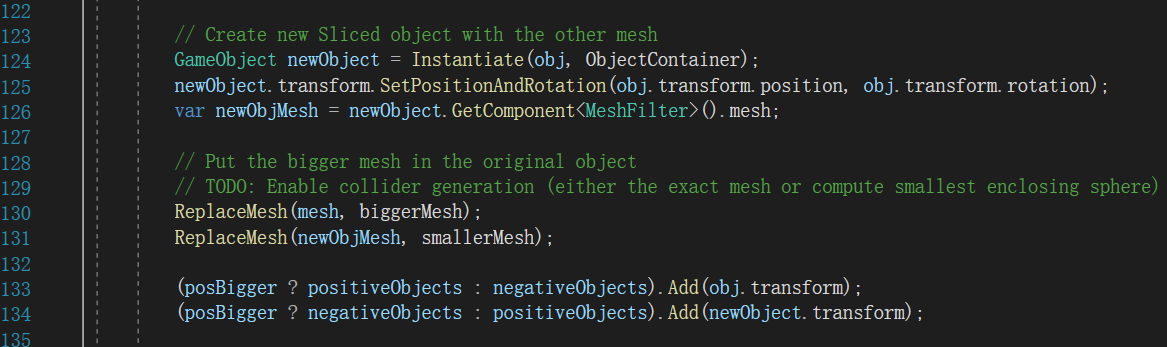
对应代码来自MouseSlice.cs中的SliceObject方法(如下图),从该代码可知,原Mesh会被分开成biggerMesh和smallerMesh两个网格,然后分别更替原物体和新增物体的Mesh(130-131行)。
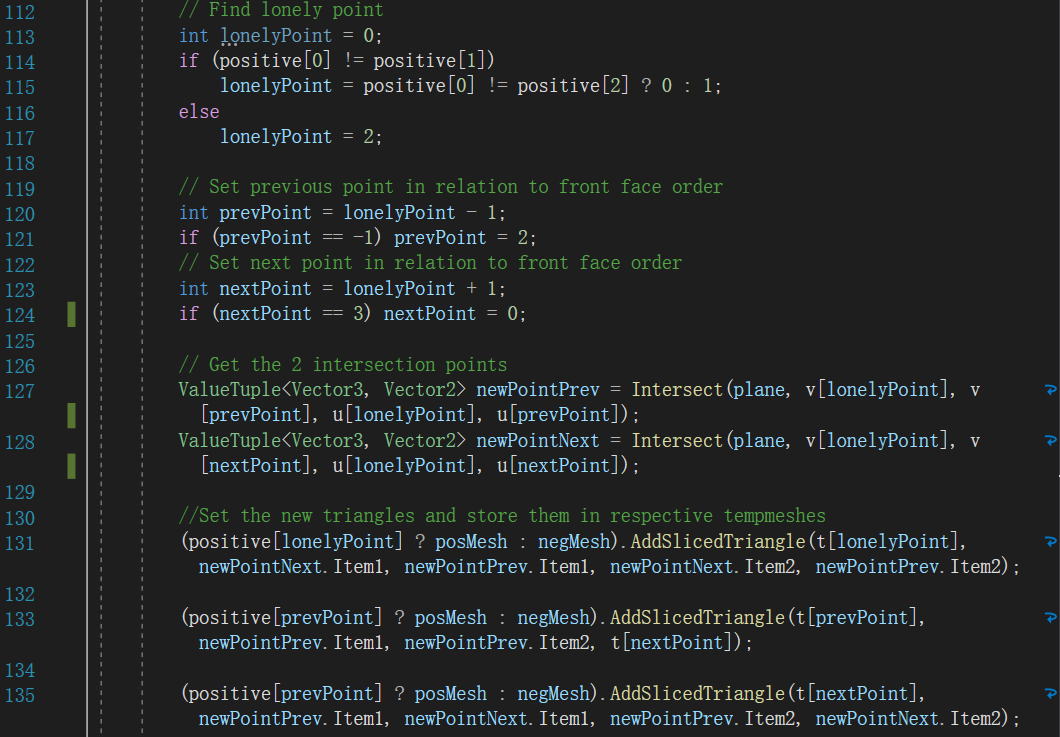
切割过程是一个添加点的过程。把过程聚焦到每个三角面,如果某个三角面会被切割,那该三角形必定会新增两个点。对应的代码如下:

图中遍历每个三角面,如果会与切割平面相交,那么新增的两个点会加入addedPairs,而关于相交计算的部分在TrianglePlaneIntersect()中。
下图是TrianglePlaneIntersect()中的片段:
这一段代码如果搭配着下图会比较容易理解:
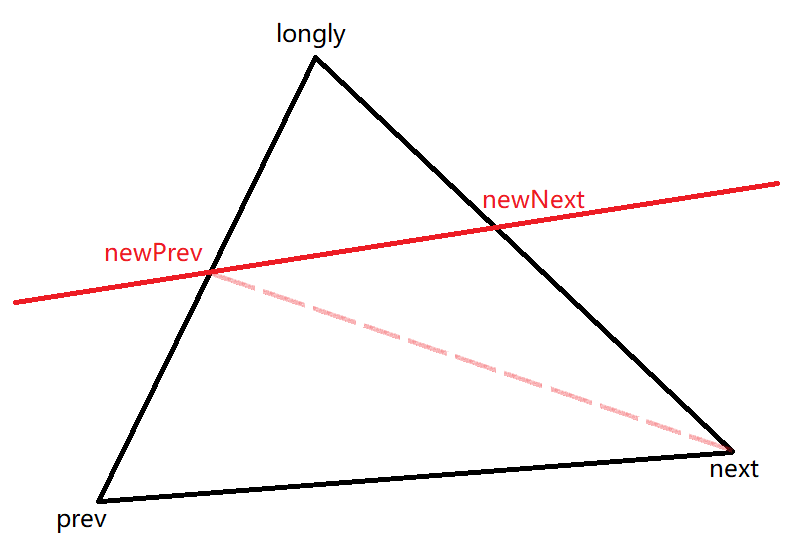
longlyPoint指的就是被切平面(红色实线)单独分到一侧的点,而127和128行得到的newPointPrev和newPointNext就是上图中两个红色的点newPrev和newNext。131-135行是在添加由新的点组成的三角形,以上图为例,从上到下分别添加了(longly,newPrev,newNext)、(prev,newPrev,next)和(next,newPrev,newNext)三个三角形,并且以是否与切割平面法线同侧为标准分别加入了不同的Mesh中。
这一步基本已经完成了切割,毕竟“添加点”和“添加三角形”就是切割网格的本质。但是如果只做到这一步,只会得到如下的效果图,所以对于切面的各个三角面仍然需要补齐。

3.3 补齐
该部分是在补齐由切割平面新增的两个截面,对应的代码段就是MeshCutter.cs中的FillBoundaryFace():
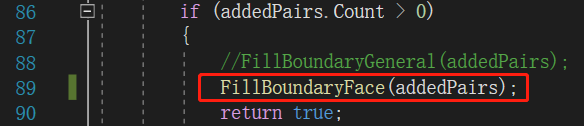
该函数的详细代码如下:
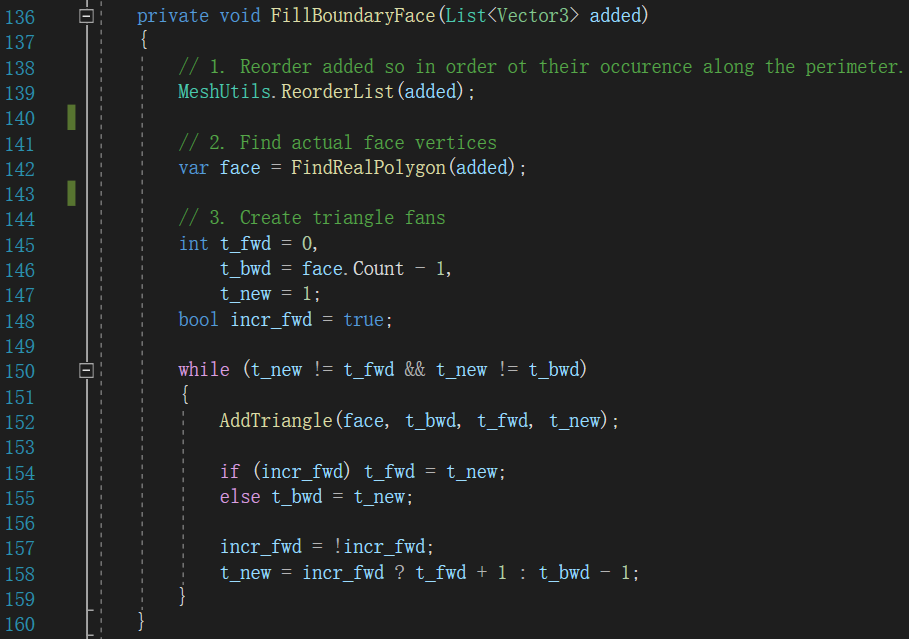
基本思想就是在切割面所新形成的点集中,按序添加三角形。从158行可以看出,这里是双向遍历的。单向和双向所构成的三角面如下示例:
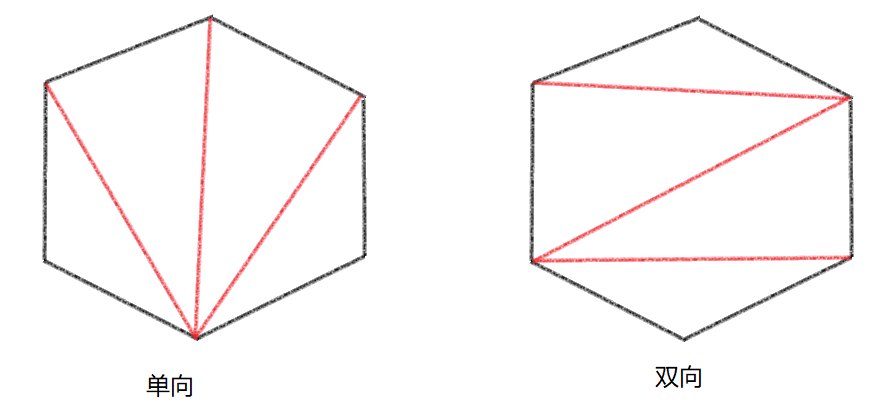
图中黑线是待补齐的平面,红线则是通过循环补的三角面。那么为何要用稍显复杂的双向循环来补齐呢?因为单个顶点的复用会使得大量三角形都比较“狭长”,那么被共用多次的顶点附近的像素在光栅化阶段参与三角形遍历的次数就会增多,也就是Overshading现象会比较严重,这会增大GPU的压力。这就是为何大多数建模软件中,Mesh网格都尽量避免多个三角形共用单个顶点的原因。
相关知识可参考:https://zhuanlan.zhihu.com/p/57661927
而该步骤之后,被切割平面分开的两个物体块就补齐了切割面:

四、性能分析
通过UWA GOT Online在中等配置机型OPPO A72(6G RAM)上做了测试,测试场景为同时切20个圆柱体,测试时间60秒,从第20秒开始切割。
下图是CPU耗时曲线图:
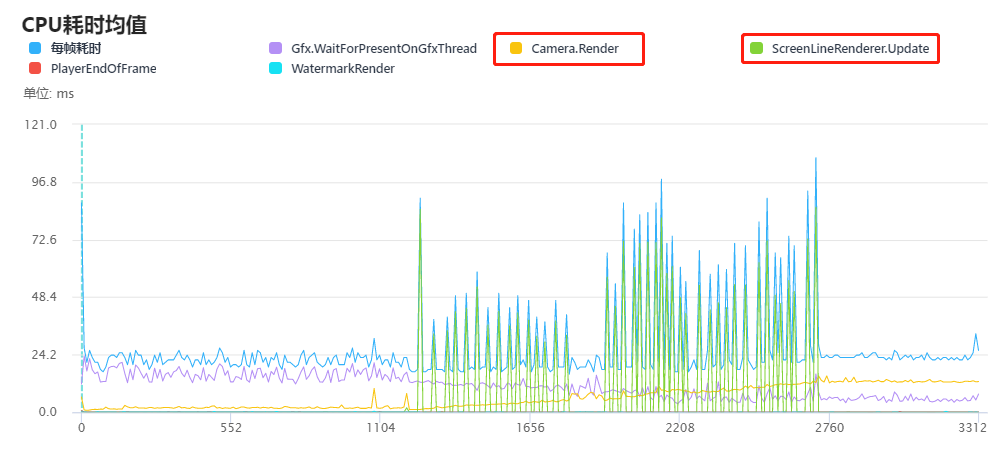
从图中可以看到,从开始切割(约1200帧处)之后,耗时主要集中在Camera.Render和ScreenLineRenderer.Update上。首先我们注意到ScreenLineRenderer.Update的耗时原因是划线操作引起的即时性的峰值耗时,该项可以通过游戏玩法来优化(比如我们可以用发射子弹等其他方式来替代划线切割),这里我们主要研究Camera.Render的耗时。上图中,随着切割出的物体块越来越多,Camera.Render的耗时稳步上升,下图是在物体块很多时的某帧的堆栈耗时:
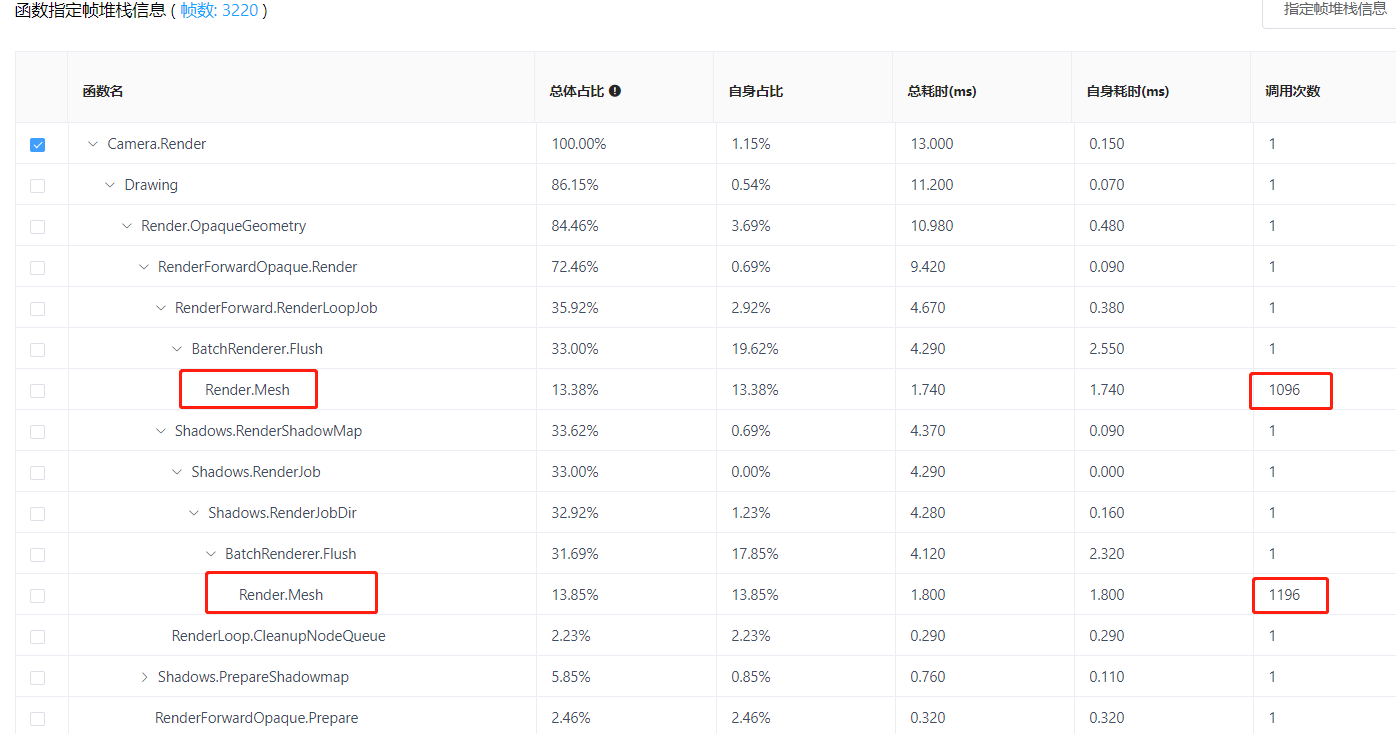
通过对比测试开始和结尾附近的帧的堆栈耗时,可以发现耗时增加最快的是上图红框中的Render.Mesh。该项的耗时通常由物体中未合批的物体数量决定,从调用次数来看,该项的耗时就是由于分割了过多物体块且未进行合批优化导致的结果。
为了对比说明,下图展示了可以进行动态合批的相同测试案例的堆栈耗时:
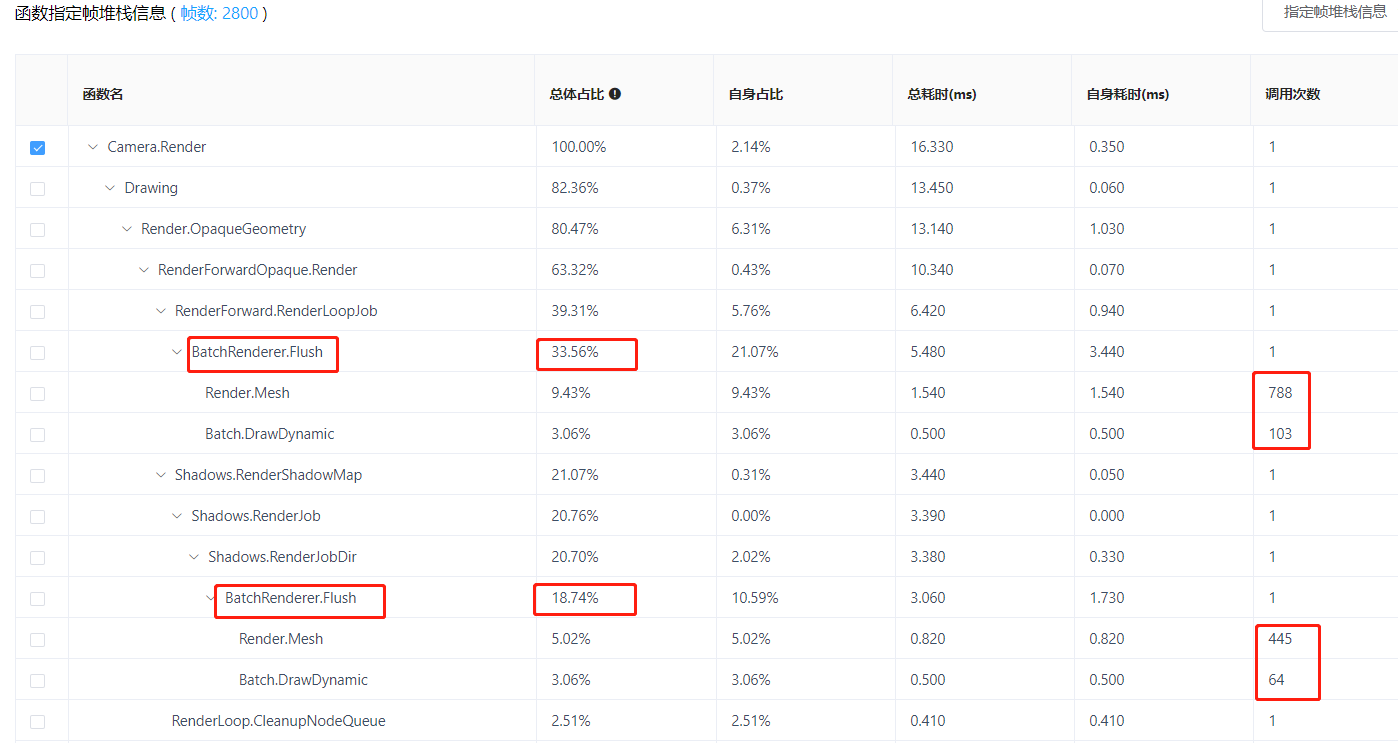
从该图可以看出BatchRenderer.Flush的总体占比比未合批时的占比低了大概12%,Render.Mesh调用次数也减少了许多(至于为何主要比较“总体占比”,是因为两次实验很难切出相同数量的物体块)。但其实动态合批的数量不算太多,因为物体块的顶点数量很容易超过300:

所以动态合批提升性能的幅度通常是不确定的,拿该项目为例,如果切割的是一些简单的、顶点数量比较小的物体,那么动态合批的性能提升应该会更大。
除此之外,GPU的耗时增幅也比较可观:
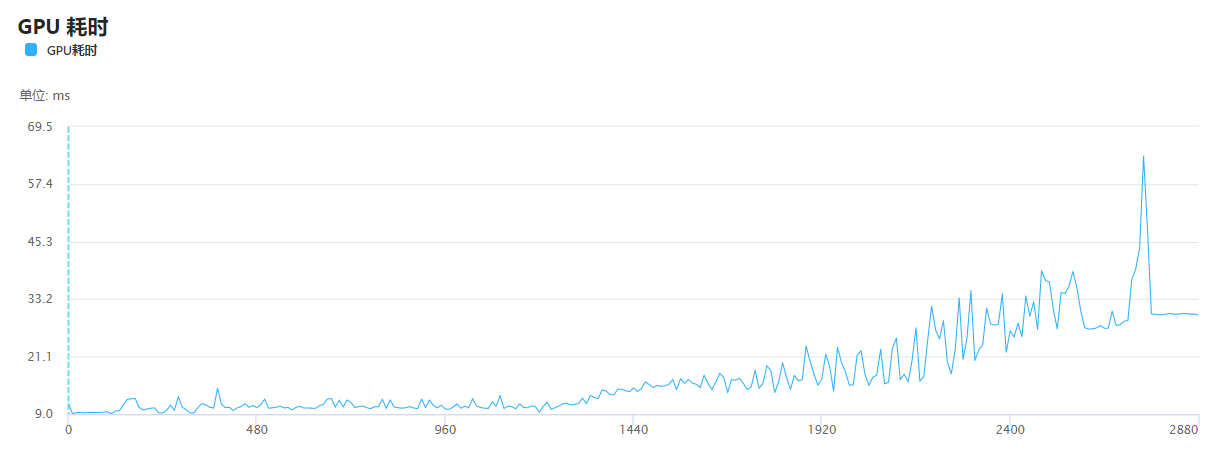
从图中可以看出,除了由ScreenLineRenderer.Update引起的峰值耗时外,均值上升主要是由顶点和三角面数的迅速增加造成的。
综上所述,如果需要使用该插件,那么最好满足:1、物体顶点数不多,且不需要分割出太多物体块;2、支持动态合批。
测试报告地址:https://www.uwa4d.com/u/got/perfanalysis.html/overview?project=28189&type=4
作者发布项目时的介绍使用的是日文编写,为了方便大家阅读,UWA开源库已将其翻译成中文版本,欢迎大家共同学习。
今天的推荐就到这儿啦,或者它可直接使用,或者它需要您的润色,或者它启发了您的思路......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号