
UWA问答精选
1)Unity性能优化分析思路
2)资源打包关系依赖树
3)SpriteAtlas 中Include in Build的作用
4)使用Streaming Mipmap后纹理内存没有下降的疑问
5)URP Renderer Feature实现二次元描边,Cutout的处理问题
UWA每周推送的知识型栏目《厚积薄发 | 技术分享》已经伴随大家走过了330个工作周。精选了2022年上半年的精彩问答分享给大家,期待UWA问答继续有您的陪伴。
UWA 问答社区:answer.uwa4d.com
UWA QQ群2:793972859(原群已满员)
Unity
Q:Unity有多少优化点?比如合批:静态合批、SRP合批、GPU实例化、UGUI Reruild、光照烘焙、反射探针、光照探针、Shader.Parse、Shader.CreateGPUProgram、场景加载优化和GC优化,还有哪些优化点?
A1:大方向上可以从CPU、内存、GPU这三个方向切入。
细分一下可以从CPU、内存、渲染、资源优化、耗电优化、网络优化、卡顿优化、优化工具的选择掌握这几个点入手。
一、CPU优化
- 缓存计算结果
- 预处理
- 限帧法
- 主次法
- 多线程
- 引擎模块(动画、物理、粒子、导航)
- 逻辑优化
二、内存优化
- 缓存法
- 内存池
- 资源管理器
- 控制GC
- 逻辑优化
- Shader变体数量优化
三、渲染优化
- SetPassCall渲染状态切换频次控制
- DrawCall数量控制
- 带宽负载
- 显存占用
- GPU计算量
四、卡顿优化
- 降帧法
- 摊帧法
- 限制数量法
- 逻辑优化
- IO优化
- 使用进度条
五、资源优化
- 纹理优化
- UI优化
- 字体优化
- 模型优化
- 场景优化
- 粒子优化
- 材质优化
- 指定标准美术规范
- Shader变体数量优化
六、耗电优化
上面说到的优化点,或多或少都会影响到手机的耗电,也是优化耗电的措施,除此之外还有:
- 动态调整限帧
- 动态调整画质
七、网络优化
- 减少无用字段
- 降低字段精度
- 避免重复发送
- 网络异步化
- 压缩无效字节
- 压缩协议包
以上说的这些要点,大部分摘抄归纳自《移动游戏性能优化通用技法》。强烈建议多花些时间认真阅读一下这篇文章,然后以这篇文章作为指南,再去仔细研究里面提到的优化细节该如何展开。
感谢马三小伙儿@UWA问答社区提供了回答
A2:优化点肯定是无穷无尽的,这里搬运UWA的客户端性能优化思路,针对常见的引擎模块的相关问题都做了分析,讲的是比较全比较透的,常见的优化难题都罗列了。
《Unity性能优化 — 物理模块》
《Unity性能优化 — 动画模块》
《Unity性能优化系列 — 资源内存泄漏》
《Unity性能优化系列—Lua代码优化》
《粒子系统优化——如何优化你的技能特效》
《Unity性能优化系列—加载与资源管理》
《Unity性能优化系列—渲染模块》
《Unity性能优化 — UI模块》
《支持资源加载分析、场景分割》
《UWA报告使用小技巧,你get了吗?》
《UWA本地资源检测更新,助你严守项目性能的每个角落!》
感谢芭妮妮@UWA问答社区提供了回答
AssetBundle
Q:想做包体资源分析,大家有什么好的树显示工具或者思路推荐吗?有比较好的开源方案也可以。最简单就像N叉树一样,比如root一个文件名,然后展开整个树结构。
A1:我自己做了一个,供参考。都是用Unity自己的IMGUI最基本的接口去实现。
EditorWindows
GUI.Box
GUI.BeginGroup
GUI.Label
Handles.DrawBezier
Handles.DrawWireDisc
TreeView
基本上,组织好各个AssetBundle的依赖关系其实是很好呈现的。
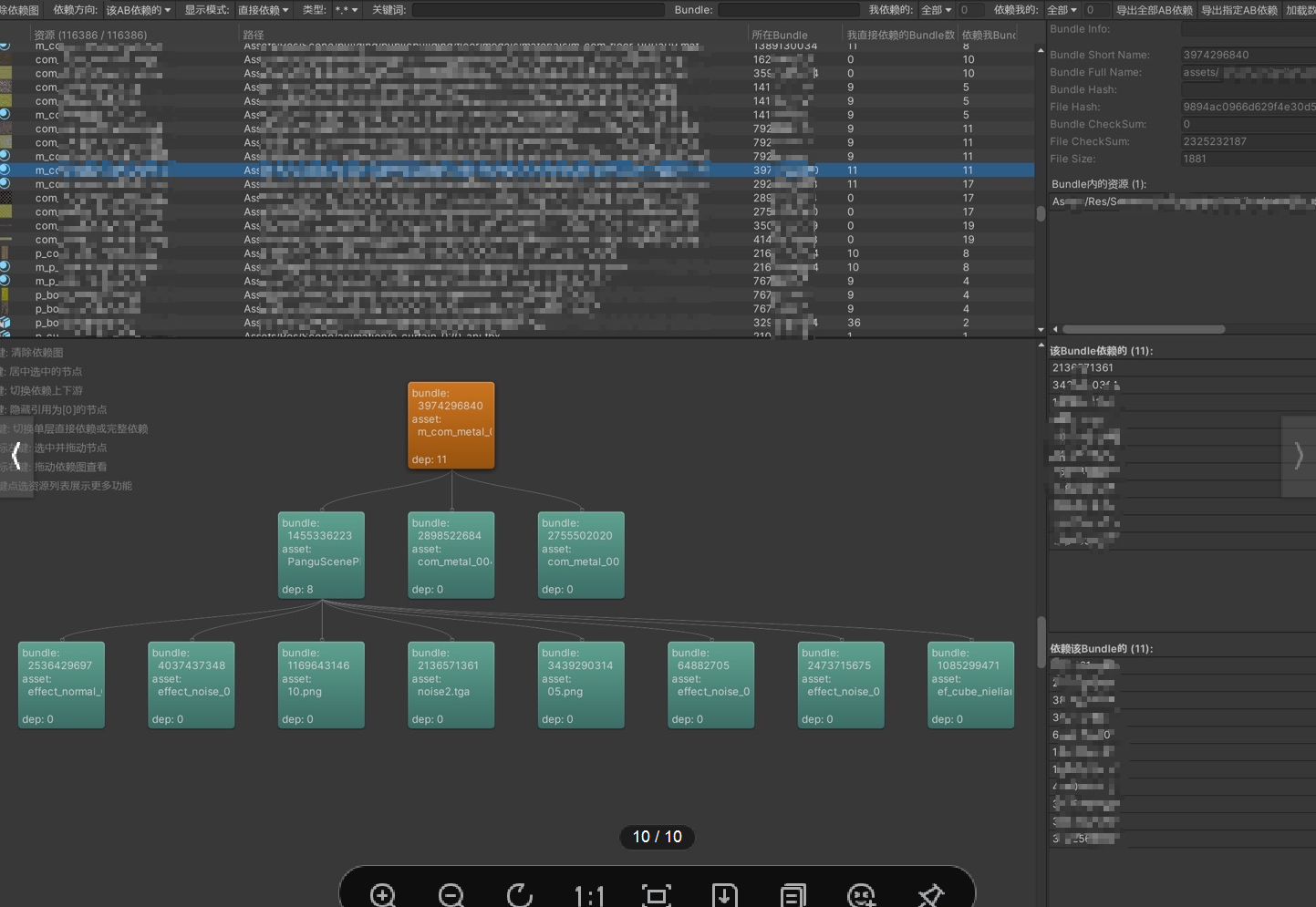
感谢黄程@UWA问答社区提供了回答
A2:推荐一款比较好用的插件,不止有依赖树,还有其他打包的资源数据可供分析:
https://assetstore.unity.com/packages/tools/utilities/build-report-tool-8162
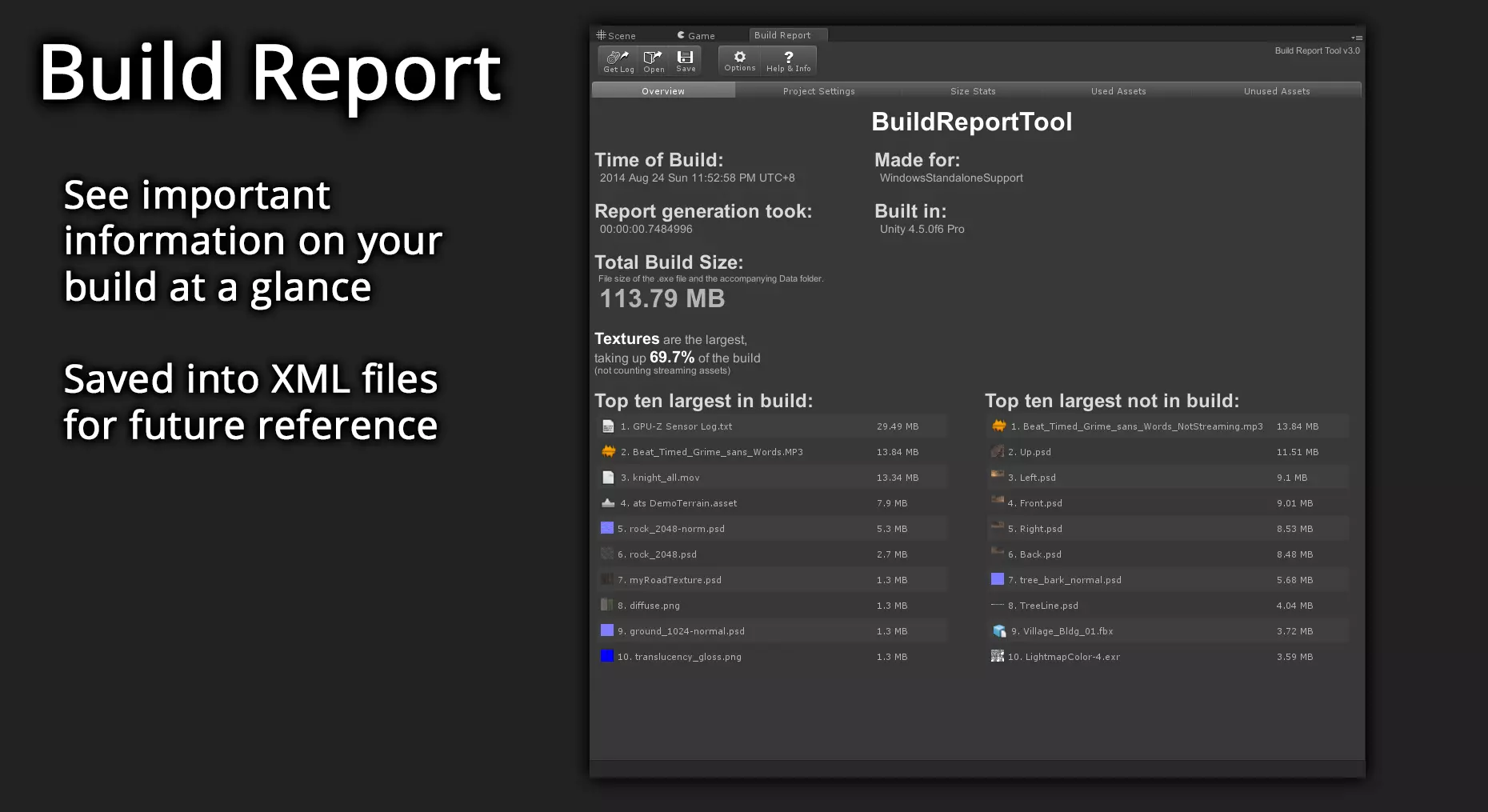
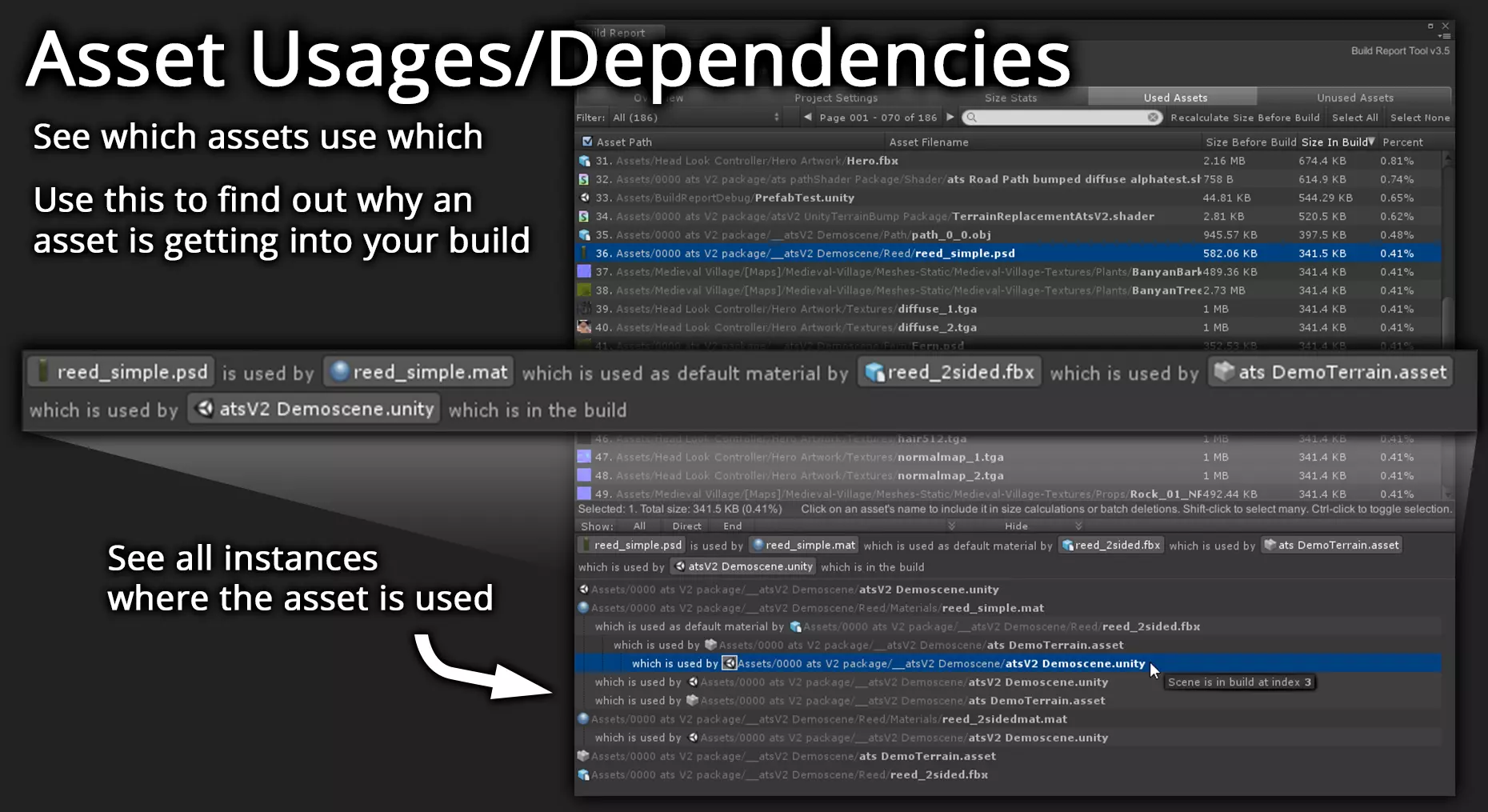
感谢郑骁@UWA问答社区提供了回答
AssetBundle
Q:SpriteAtlas中Include in Build的作用是什么?
A:专门做了一些测试,具体如下:
以下表达中Sprite对应的是Sprite类型的对象,Texture2D对应的是Texture2D的对象,这和Sprite对象是完全不同的东西,sactx表示生成的图集纹理。
测试情况包括2个变量:
- SpriteAtlas对象是否主动打包AssetBundle
- SpriteAtlas对象上是否勾选Include in Build
第一种情况,SpriteAtlas打包AssetBundle:
那这里要考虑的是SpriteAtlas引用的Sprite是否会单独打包,如果这些小Sprite不主动打包,是会被动进这个SpriteAtlas的AssetBundle里面的,如果其他的UI Prefab中,比如有个Image使用了一个小Sprite,那么这个小Sprite就冗余了。
这里勾不勾选Include in Build的区别在于:加载Image的时候,这个Image会不会自动显示,勾选了Include in Build,会自动显示图片,不勾选,则需要脚本添加回调来主动加载SpriteAtlas,并callback(spriteatlas)。第二种情况,SpriteAtlas不加入AssetBundle打包:
- 不勾选Include in Build
假设小的Sprite打包AssetBundle,在这个AssetBundle里面不会有sactx,这个sactx的Texture2D的纹理变成“消失”的状态,没有任何东西可以引用到这个sactx纹理,而且由于在工程里面有SpriteAtlas的存在,所以在小的Sprite的AssetBundle里面也不能让其本身对应的小的Texture2D纹理进AssetBundle包,所以图像就永远显示不出来了。- 勾选Include in Build
所有的小的Sprite所在的AssetBundle里面都会被动包含sactx的图,且会包含所有没有主动打包的小的Sprite。
如Sprite1和Sprite2是SpriteAtlas里面的两个小的Sprite。Sprite1主动打包,Sprite2不主动打包,那么Sprite1的AssetBundle里面是会有Sprite1和Sprite2以及sactx纹理。总结:
- 如果有Sprite加入了某个SpriteAtlas,那么任何真正使用到这个Sprite的资源都不会有对Sprite对应的小的Texture2D纹理的引用,而是对sactx图集纹理的引用。
- 如果SpriteAtlas不打包,必须勾选Include in Build,否则sactx纹理就“消失”了,在勾选Include in Build的前提下,而且SpriteAtlas中的所有小的sprite必须打包到同一个AssetBundle里面,否则sactx会冗余。
- 如果SpriteAtlas打包了AssetBundle,sactx永远不会冗余了(这里的冗余是指打包AssetBundle造成的冗余)。SpriteAtlas里面的小的Sprite也最好打包AssetBundle,不然这些小的Sprite就会冗余。勾选或者不勾选Include in Build都不影响各种依赖关系,唯一的区别是是否会主动显示图片,勾选了就会主动显示图片,不勾选就需要脚本控制来显示图片。
感谢Xuan@UWA问答社区提供了回答
Texture
Q:为什么我在项目中使用了Streaming Mipmap但是在GOT报告中看纹理内存没有下降?是没有正确生效还是统计有问题?
A:之前做过相关测试,发现GOT Online是可以统计到被Streaming Mipmap影响的纹理的正确内存的,所以我推测你遇到的情况大概率还是没有正确生效导致的。以下是对如何让一张纹理应用Streaming Mipmap的简单流程总结,其中会注明需要特别注意的一些条件(有些被官方文档收录,有些则文档中没有,但实验证明为必要):
在Project Settings-Quality中开启Texture Streaming选项。然而实验发现Editor中开启该选项而真机上却会失效的现象,导致所有纹理的Streaming Mipmap设置全部失效。所以为了确保生效,首先应该在代码中调用QualitySettings.streamingMipmapsActive API全局地开启这个选项,才能确保Streaming Mipmap可用。
调整1中设置的参数。比较重要的参数是Memory Budget参数和Max Level Reduction参数。Memory Budget表示纹理资源的预算,默认值是512MB,但根据UWA的大量项目数据来看,中低端机上一般为200MB左右。它的数值代表的是所有纹理资源的预算——即,它既包括了非流式的纹理、又包括了我们想要采用流式的纹理——但这个“预算”并不代表纹理资源可占用的上限,只是Unity判断对于一个开启Streaming Mipmap的纹理到底采用它的哪些Mipmap通道的参考值,非流式纹理能够轻易突破这个预算。
Max Level Reduction则是代表着Unity通过流式存储最高能取到哪一级的Mipmap通道,这个参数的优先级比Memory Budget要高,也就会造成实际内存超过预算的情况。(比如该参数为2时,则最多剔除Mipmap0和1通道,即便丢弃以后还远超出预算值也不会进一步剔除。)
也就是说,如果Memory Budget值设置的远高于项目中纹理实际占用的内存,则Texture Streaming可能完全不起效,所有开启Streaming Mipmap的纹理仍将保留它们的全部Mipmap通道。设置开启Streaming Mipmap的纹理。1、2中提到的设置只对开启了Streaming Mipmap的纹理起效,而这只是官方文档的说法,从实际操作来看,Texture Streaming只对同时满足以下三个条件的纹理生效:
1)开启了Streaming Mipmap且开启了Generate Mipmap的纹理(这一点官方文档中没有提及,事实上开启Generate Mipmap才会生成Mipmap通道供Streaming Mipmap剔除);
2)被即时加载的纹理(如一开始就已经在场景中被依赖的纹理,即便开启了Streaming Mipmap其内存也不会发生变化,通过AssetBundle加载和Res.Load()加载的纹理则可以),也即官方文档中这句话的实际含义:
如果是进行Android开发,还需要打开Build Setting,并将Compression Method设置为LZ4或LZ4HC。Unity需要使用其中一种压缩方法进行异步纹理加载,这是纹理串流系统所必需的操作。
3)Gfx部分内存(这里指的是纹理资源开启Read/Write选项时,复制到CPU端的那一部分内存是不受Streaming Mipmap影响的);Streaming Mipmap剔除Mipmap通道的规律。它的机制其实和Texture Quality是类似的。我们知道,开启Mipmap的纹理之所以会变成原来的4/3倍,实际上是它各个通道所占用的内存之和。举例而言,一个具有11个Mipmap通道的原大小为1MB的纹理(10241024分辨率、ASTC44格式),其内存占用为1+1/4+1/16+…的11项等比数列之和,即约4/3。等比数列的各项就对应了Mipmap0、Mipmap1、Mipmap2…等各个Mipmap通道。那么,当Max Level Reduction参数设置为2时,其实际意义就是保留Mipmap2和后续所有更小的通道,而剔除Mipmap0和Mipmap1通道,此时的内存大小为4/3MB-1MB-1/4MB=85.33KB。这和我在Profiler或GOT Online中看到的数据基本一致。
关于采用Streaming Mipmap方案的建议。根据上述实验和分析不难看出,Streaming Mipmap是确实具有一些优点的,对于对内存比较敏感,尤其是纹理内存占用很大的项目,采用Streaming Mipmap方案是非常合理和推荐的选项。与此同时,它的实际使用要求对项目中纹理资源的内存占用有相当的了解和规划——相关设置在Quality中,理所当然地应该考虑到不同设备Lod分级时不同的设置。在中低端机中,设置尽量低的Memory Budget和尽量高的Max Level Reduction;在高端机上则恰恰相反,在内存可接受范围内尽量开启最好的画面表现。除此之外,对于哪些纹理要开启Streaming Mipmap,一般是场景中3D物体的纹理,而UI模块采用的纹理则尽量关闭。因为Mipmap的意义主要在于适应纹理在距离镜头远近时的表现需要、避免失真等,而UI完全不需要这些,开启只会白白浪费内存和计算时间。
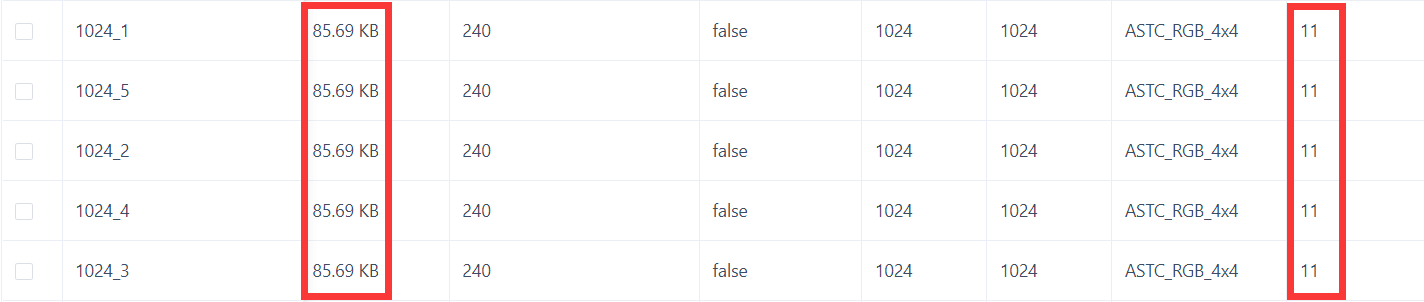
感谢Faust@UWA问答社区提供了回答
Rendering
Q:之前我们的卡通渲染是在Shader里写多个Pass来绘制的描边,最近尝试用SRP Batcher优化时发现,SRP Batcher不支持多个Pass的Shader。于是我尝试用URP Renderer Feature来渲染所有角色的描边。
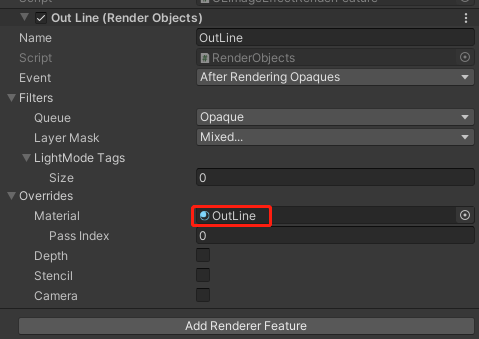
实现起来很简单,但有一个问题解决不了,就是Cutout的问题。

裙子的下边缘是用贴图的Alpha控制的,并不是真正的顶点。以前的Pass写在角色渲染的Shader里,可以用贴图来控制,但用Renderer Feature来处理后,所有角色模型的描边是用的同一个材质,不能再用模型各自的贴图的通道来处理了。显示效果就是Cutout的描边部分无法处理:

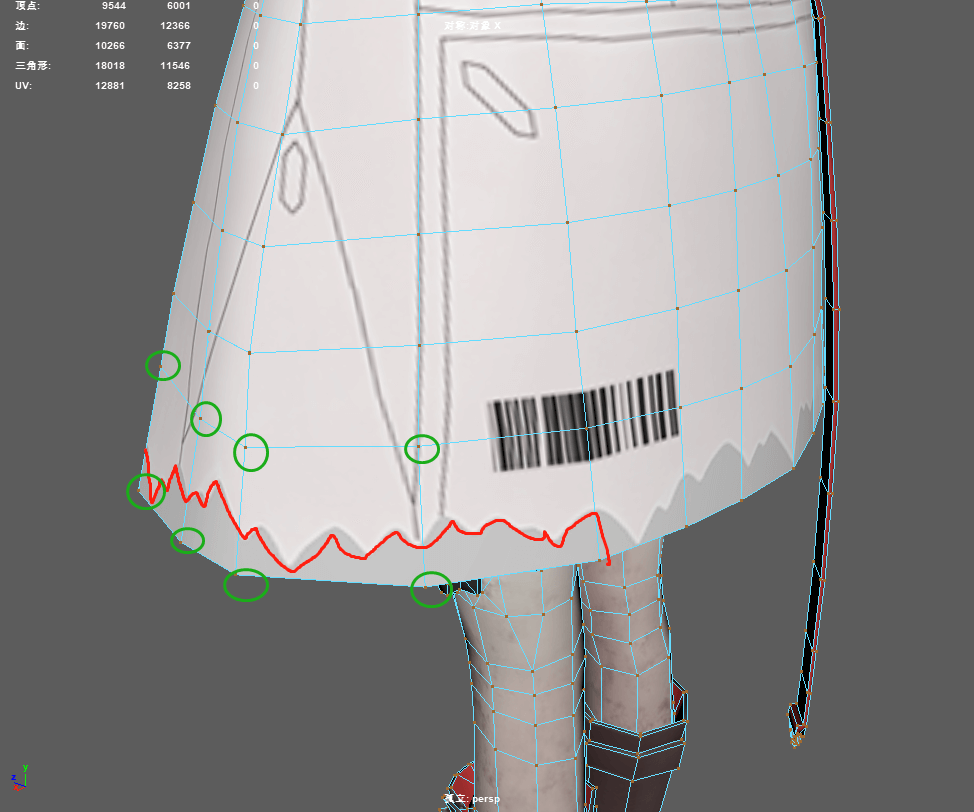
边缘比较复杂,但是控制的顶点就只有几个,感觉不太好实现。
现在模型顶点的颜色信息我已经用过了,RGB是描边颜色,A是描边粗细。我能想到的办法是用A的一些特殊值来特殊处理一下某些顶点(相当于Clip掉一些顶点,但肯定没有相关API),但又感觉似乎不太可行。不知道大家有没有遇到过,或者有没有什么好办法呢?
自己尝试了用顶点信息标记点,但有瑕疵,点关联的边会受影响,描边没了:

让美术加了一些点,基本也能解决(其实外边缘还是不会显示全,但已经看不太出来了):

但这方法还是不好。最好在Renderer Feature里可以获取到正在渲染的模型的材质信息。
是否可以把一个多Pass的Shader里的某个Pass弄到单独的Renderer Feature里画,而不是重新画一遍?比如画第一遍的时候禁用这个Pass,Renderer Feature画的时候再启用它?
A1:自定义一个LightMode,Render Feature里设置这个LightMode,这样材质球上的贴图数据什么就能有。
补充个截图大概是这样的:
对于自定义的LightMode,Unity默认忽略,只有Render Feature里手动指定了要画这个LightMode,Unity才会去绘制。

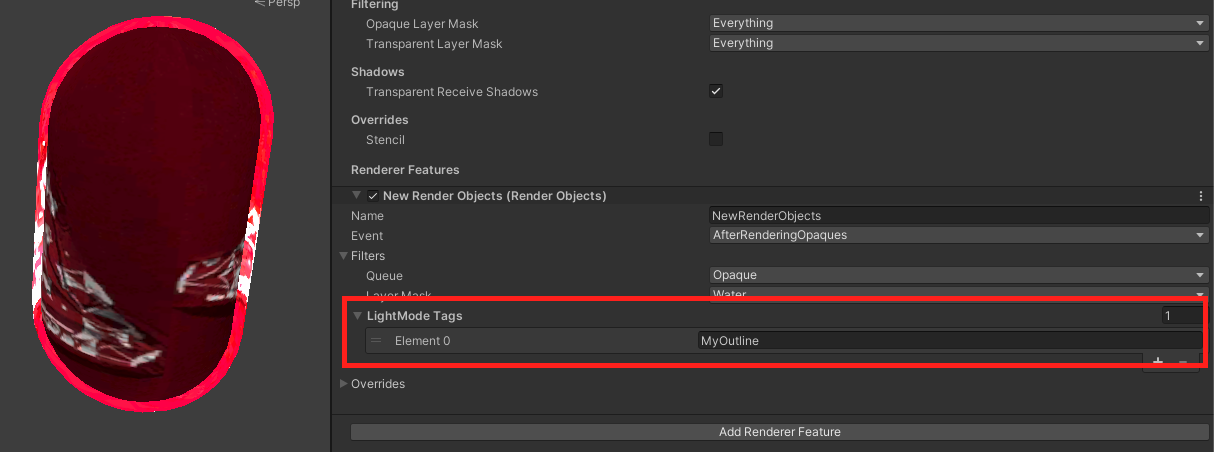
感谢jim@UWA问答社区提供了回答
A2:如下,这样SRP Batcher终于可以合批多Pass的Shader了:
不用禁用正常的渲染。
两个Pass,一个正常的Pass,一个自定义LightMode的Pass,lightMode的Pass渲染描边用ScriptableRendererFeature手动指定渲染自定义的LightMode。Unity不会去渲染你自定义的LightMode。
感谢题主仇磊@UWA问答社区提供了回答
封面图来源于网络
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859(原群已满员)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号