数据挖掘、数据分析之协同过滤、推荐系统、关联分析
总结:构建基于人的协同过滤模型,以自己的评价或者购买过的商品构建输入向量,计算与模型中其他人的的相似度,然后sum(相似度*评分)/sum(所有评价过此商品的人的相似度)来计算物品推荐值。
对于大规模的物品时,不可能对实时的为每个人计算相似度,然后进行物品的推荐,此时的做法是构建基于物品的协同过滤模型,然后依次计算每件物品与其他物品的相似度,取前n件物品、相似度记录下来,当用户登录时,从其评价过的商品中选取评价分数最高的m件商品及分数,然后选出m件商品的相似商品,根据评分*相似度,来计算排名,进行推荐;同时可以按照sum(相似度*评分)/sum(此人评价的所有商品的相似度)来给模型中的用户打分,从而调整数据。
基于用户的协同过滤模型:
集合{
persion1:{商品1:评分1, 商品2:评分2, 商品3:评分3}...
}
基于物品的协同过滤模型:
集合{
商品:{persion1:评分1, persion2:评分2, ...}
...
}
...
}
模型:
集合{
persion1:{商品1:评分1, 商品2:评分2, 商品3:评分3}
...
}
定义:
从用户的购买行为中,寻找相近的用户:
方法:将每个人与所有其他人进行对比,计算其相似度评价值
1.欧几里德距离:
公式:1/(1+sqrt(pow(p1.f1-p2.f1)+pow(p1.f2-p2.f2))
2.皮尔逊相似度
公式:
方法:将每个人与所有其他人进行对比,计算其相似度评价值
1.欧几里德距离:
公式:1/(1+sqrt(pow(p1.f1-p2.f1)+pow(p1.f2-p2.f2))
2.皮尔逊相似度
公式:
公式一:
公式二:
公式三:
公式四:
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数同时,R中cor()函数计算的就是皮尔逊系数
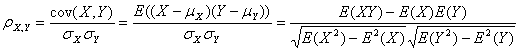

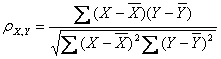

python代码:![]()
 对应的是第三个公式
对应的是第三个公式当数据不是很规范时,比如某人的评价总是相对于平均水平偏高很大时,会倾向于给出更好的结果
采用二元线性曲线拟合的方法,先用所有人对两件商品的评价构造拟合曲线,然后根据曲线计算每个人的皮尔逊相似度
从一定程度上修正了夸大分值的情况,同时能避免这样的情况:
两个人对一些物品的评价总是相差一定的分值,两者应该有非常高的相似度,但是用欧几里得距离则得不到两者近似的结论
方法的选择取决于具体的应用,可以尝试多种方法,以取得最好的实际效果
推荐物品:
通过相关算法能得到和自己爱好相同的人的排名,但是根据这样的结果来推荐物品,就显得随性了。
处理方法:sum(相似度*评分)/sum(所有评价过此商品的人的相似度)来计算物品推荐值
匹配相似商品,基于物品:
转换模型为:
集合{
商品:{persion1:评分1, persion2:评分2, ...}
...
}
根据欧几里得距离或者皮尔逊相似度求计算商品的相似度,可以计算输入商品的相同类型的商品
2.大数据场景:
上述的方法用于数以千计的用户时是没有问题的,但是对淘宝这样的网站而言会耗费大量的时间在用户相似度的比较间
两种方法:基于用户的协同过滤和基于物品的协同过滤,基于物品的协同过滤效果更好一些
思路:预先计算好每件物品与其相近的其他物品,当用户登录后,从其评价过的商品里选出排名前几位的物品,构造一个相似度和相近物品的加权列表,包含了选中物品最为相近的其他物品
设计技巧:不必不停的计算与每样物品最为相近的其他物品
3.基于用户物品、过滤
在数据的稀疏程度上的不同也存在精准度上的差异:对密集型数据,两者的效果几乎一样;但是对于稀疏数据集,基于物品的协同过滤效果更好!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号