
记一个男默女泪的 BUG
姗姗来迟的词频统计代码 BUG 的发现
1. 此前提交的第一次代码作业总结博客
http://www.cnblogs.com/ustczwq/p/8680704.html
2. BUG 本天成,妙手偶得之
虽然代码已经提交,但总是感觉哪个地方不太对,bug 存在得过于莫名其妙。然后,随手打开代码,稍微调试了一下,当我发现 bug 的时候,不知道该说些什么好,只想讲脏话。
出现 bug 的地方:

改过之后:
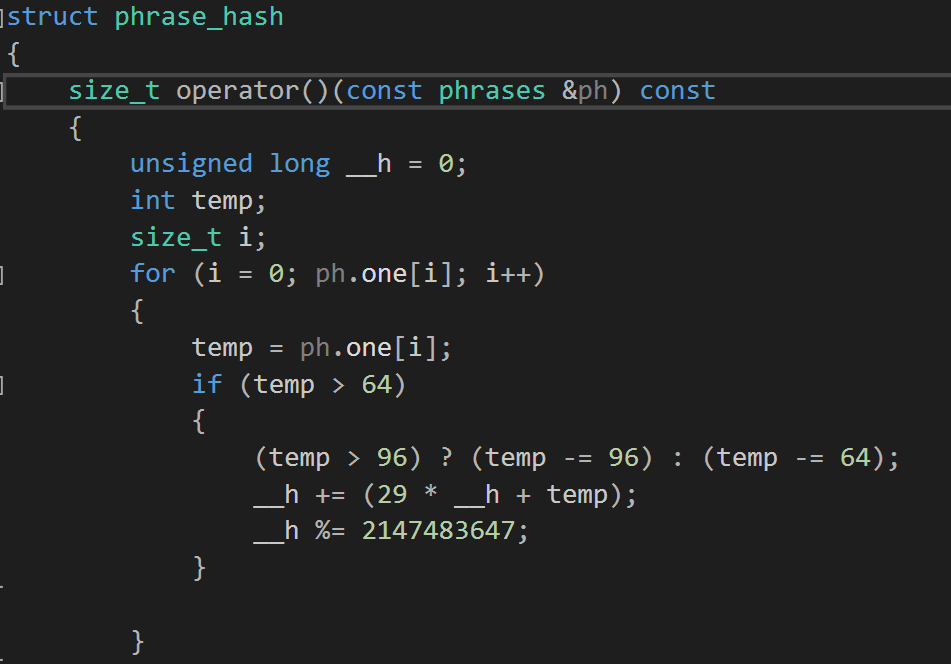
看出来了吧,妈卖批,三目运算符没赋值。改完之后,输出结果立马正确。怪不得用 unordered_map 的时候哈希表的查询出问题了,我 TM 定义的哈希函数有问题。虽然迟了,但那种优化是对的,简单补一篇,算是对原博客的完善。
3. 加了几个等于号之后的源代码


1 #include "io.h" 2 #include "math.h" 3 #include "stdio.h" 4 #include "string.h" 5 #include "stdlib.h" 6 #include "unordered_map" 7 8 using namespace std; 9 10 #define small 2 11 12 int wordnum = 0; 13 int charnum = 0; 14 int linenum = 0; 15 16 struct wordsdata //存放单词信息 17 { 18 char words[1024]; //单词字符串 19 int number; //出现次数 20 wordsdata *next; 21 }; 22 struct phrases 23 { 24 char *one; 25 char *two; 26 int num; 27 }; 28 29 int wordcmp(char *str1, char *str2); 30 int gettop(struct wordsdata **word); 31 int getwords(char *path, struct wordsdata **word); 32 int getfiles(char *path, struct _finddata_t *fileinfo, long handle); 33 34 struct phrase_cmp 35 { 36 bool operator()(const phrases &p1, const phrases &p2) const 37 { 38 return ((wordcmp(p1.one, p2.one) < 2) && (wordcmp(p1.two, p2.two) < 2)); 39 } 40 41 }; 42 struct phrase_hash 43 { 44 size_t operator()(const phrases &ph) const 45 { 46 unsigned long __h = 0; 47 int temp; 48 size_t i; 49 for (i = 0; ph.one[i]; i++) 50 { 51 temp = ph.one[i]; 52 if (temp > 64) 53 { 54 (temp > 96) ? (temp -= 96) : (temp -= 64); 55 __h += (29 * __h + temp); 56 __h %= 2147483647; 57 } 58 59 } 60 for (i = 0; ph.two[i]; i++) 61 { 62 temp = ph.two[i]; 63 if (temp > 64) 64 { 65 (temp > 96) ? (temp -= 96) : (temp -= 64); 66 __h += (29 * __h + temp); 67 __h %= 2147483647; 68 } 69 } 70 71 return size_t(__h); 72 } 73 74 }; 75 76 typedef unordered_map<phrases, int, phrase_hash, phrase_cmp> Char_Phrase; 77 Char_Phrase phrasemap; 78 struct wordsdata *fourletter[26 * 26 * 26 * 26] = {}; //按首四字母排序 79 80 int main() 81 { 82 int j = 0; 83 long handle = 0; // 用于查找的句柄 84 struct _finddata_t fileinfo; // 文件信息的结构体 85 char *path = __argv[1]; 86 87 getfiles(path, &fileinfo, handle); 88 89 gettop(fourletter); 90 91 system("pause"); 92 return 1; 93 } 94 95 int getfiles(char *path, struct _finddata_t *fileinfo, long handle) 96 { 97 handle = _findfirst(path, fileinfo); //第一次打开父目录 98 if (handle == -1) 99 return -1; 100 101 102 do 103 { 104 //printf("> %s\n", path); //显示目录名 105 106 if (fileinfo->attrib & _A_SUBDIR) //如果读取到子目录 107 { 108 if (strcmp(fileinfo->name, ".") != 0 && strcmp(fileinfo->name, "..") != 0) 109 { 110 char temppath[1024] = ""; //记录子目录路径 111 long temphandle = 0; 112 struct _finddata_t tempfileinfo; 113 strcpy(temppath, path); 114 strcat(temppath, "/*"); 115 116 temphandle = _findfirst(temppath, &tempfileinfo); //第一次打开子目录 117 if (temphandle == -1) 118 return -1; 119 120 do //对子目录所有文件递归 121 { 122 if (strcmp(tempfileinfo.name, ".") != 0 && strcmp(tempfileinfo.name, "..") != 0) 123 { 124 strcpy(temppath, path); 125 strcat(temppath, "/"); 126 strcat(temppath, tempfileinfo.name); 127 getfiles(temppath, &tempfileinfo, temphandle); 128 } 129 } while (_findnext(temphandle, &tempfileinfo) != -1); 130 131 _findclose(temphandle); 132 }//递归完毕 133 134 } //子目录读取完毕 135 else 136 getwords(path, fourletter); 137 138 139 } while (_findnext(handle, fileinfo) != -1); 140 141 _findclose(handle); //关闭句柄 142 143 return 1; 144 145 } 146 147 int getwords(char *path, struct wordsdata **word) 148 { 149 FILE *fp; 150 int j = 0; 151 int cmp = 0; 152 int num = 0; //计算首四位地址 153 char temp = 0; //读取一个字符 ACSII 码值 154 int length = 0; 155 156 char present[1024] = ""; //存储当前单词 157 158 char address[4] = ""; 159 struct wordsdata *q = NULL; 160 struct wordsdata *pre = NULL; 161 struct wordsdata *neword = NULL; 162 struct wordsdata *now = NULL; 163 struct wordsdata *previous = NULL; 164 struct phrases *newphrase = NULL; 165 166 if ((fp = fopen(path, "r")) == NULL) 167 { 168 //printf("error!!! \n", path); 169 return 0; 170 } 171 linenum++; 172 while (temp != -1) 173 { 174 //读取字符串 175 temp = fgetc(fp); 176 if (temp > 31 && temp < 127) 177 charnum++; 178 if (temp == '\n' || temp == '\r') 179 linenum++; 180 181 while ((temp >= '0' && temp <= '9') || (temp >= 'a' && temp <= 'z') || (temp >= 'A' && temp <= 'Z')) 182 { 183 if (length != -1 && length < 4) 184 { 185 if (temp >= 'A') //是字母 186 { 187 present[length] = temp; 188 address[length] = (temp >= 'a' ? (temp - 'a') : (temp - 'A')); 189 length++; 190 } 191 else //不是字母 192 length = -1; 193 } 194 else if (length >= 4) 195 { 196 present[length] = temp; 197 length++; 198 } 199 temp = fgetc(fp); 200 if (temp > 31 && temp < 127) 201 charnum++; 202 if (temp == '\n' || temp == '\r') 203 linenum++; 204 } // end while 205 206 //判断是否为单词 207 if (length >= 4) 208 { 209 wordnum++; 210 211 //计算首四位代表地址 212 num = address[0] * 17576 + address[1] * 676 + address[2] * 26 + address[3]; 213 214 //插入当前单词 215 if (word[num] == NULL) 216 { 217 word[num] = new wordsdata; 218 neword = new wordsdata; 219 neword->number = 1; 220 neword->next = NULL; 221 strcpy(neword->words, present); 222 word[num]->next = neword; 223 now = neword; 224 } 225 else 226 { 227 pre = word[num]; 228 q = pre->next; 229 cmp = wordcmp(q->words, present); 230 231 while (cmp == small) 232 { 233 pre = q; 234 q = q->next; 235 if (q != NULL) 236 cmp = wordcmp(q->words, present); 237 else 238 break; 239 } 240 if (q != NULL && cmp <= 1) 241 { 242 now = q; 243 q->number++; 244 if (cmp == 1) 245 strcpy(q->words, present); 246 } 247 248 else 249 { 250 neword = new wordsdata; 251 neword->number = 1; 252 strcpy(neword->words, present); 253 pre->next = neword; 254 neword->next = q; 255 now = neword; 256 } 257 } 258 259 if (previous != NULL) 260 { 261 newphrase = new phrases; 262 263 newphrase->one = previous->words; 264 newphrase->two = now->words; 265 266 unordered_map<phrases, int>::const_iterator got = phrasemap.find( *newphrase); 267 if (got != phrasemap.end()) 268 { 269 phrasemap[*newphrase]++; 270 } 271 else 272 { 273 phrasemap.insert(pair<phrases, int>(*newphrase, 1)); 274 } 275 } 276 previous = now; 277 278 //当前单词置空 279 for (int j = 0; present[j] && j < 1024; j++) 280 present[j] = 0; 281 } 282 length = 0; 283 } 284 285 fclose(fp); 286 return 1; 287 } 288 289 int wordcmp(char *str1, char *str2) 290 { 291 char *p1 = str1; 292 char *p2 = str2; 293 char q1 = *p1; 294 char q2 = *p2; 295 296 if (q1 >= 'a' && q1 <= 'z') 297 q1 -= 32; 298 299 if (q2 >= 'a' && q2 <= 'z') 300 q2 -= 32; 301 302 while (q1 && q2 && q1 == q2) 303 { 304 p1++; 305 p2++; 306 307 q1 = *p1; 308 q2 = *p2; 309 310 if (q1 >= 'a' && q1 <= 'z') 311 q1 -= 32; 312 313 if (q2 >= 'a' && q2 <= 'z') 314 q2 -= 32; 315 } 316 317 while (*p1 >= '0' && *p1 <= '9') 318 p1++; 319 while (*p2 >= '0' && *p2 <= '9') 320 p2++; 321 322 if (*p1 == 0 && *p2 == 0) //两单词等价 323 return strcmp(str1, str2); //等价前者字典顺序小返回-1,大返回1,完全相等返回0 324 325 if (q1 < q2) //前者小 326 return 2; 327 328 if (q1 > q2) //后者小 329 return 3; 330 331 return 4; 332 } 333 334 int gettop(struct wordsdata **word) 335 { 336 int i = 0, j = 0; 337 struct wordsdata *topw[12] = {}; 338 struct phrases *toph[12] = {}; 339 struct wordsdata *w = NULL; 340 FILE *fp; 341 fp = fopen("result.txt", "w"); 342 fprintf(fp,"characters:%d \nwords:%d \nlines:%d\n", charnum,wordnum, linenum); 343 344 for (j = 0; j < 12; j++) 345 { 346 toph[j] = new struct phrases; 347 toph[j]->num = 0; 348 topw[j] = new struct wordsdata; 349 topw[j]->number = 0; 350 } 351 for (i = 0; i < 456976; i++) 352 { 353 if (word[i] != NULL) 354 { 355 w = word[i]->next; 356 while (w != NULL) 357 { 358 topw[11]->number = w->number; 359 topw[11]->next = w; 360 j = 11; 361 while (j > 1 && topw[j]->number > topw[j - 1]->number) 362 { 363 topw[0] = topw[j]; 364 topw[j] = topw[j - 1]; 365 topw[j - 1] = topw[0]; 366 j--; 367 } 368 w = w->next; 369 } 370 } 371 } 372 for (j = 1; j < 11; j++) 373 { 374 if (topw[j]->number) 375 fprintf(fp,"\n%s :%d", topw[j]->next->words, topw[j]->number); 376 } 377 for (Char_Phrase::iterator it = phrasemap.begin(); it != phrasemap.end(); it++) 378 { 379 toph[11]->one = it->first.one; 380 toph[11]->two = it->first.two; 381 toph[11]->num = it->second; 382 j = 11; 383 while (j > 1 && toph[j]->num > toph[j - 1]->num) 384 { 385 toph[0] = toph[j]; 386 toph[j] = toph[j - 1]; 387 toph[j - 1] = toph[0]; 388 j--; 389 } 390 } 391 fprintf(fp, "\n"); 392 for (j = 1; j < 11; j++) 393 { 394 if (toph[j]->num) 395 fprintf(fp,"\n%s %s :%d", toph[j]->one, toph[j]->two, toph[j]->num); 396 } 397 fclose(fp); 398 return 1; 399 }

