

个人作业报告
一 、基本要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客
二、基本功能
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
三、PSP
|
PSP2.1 |
任务内容 |
计划完成需要的时间(min) |
实际完成需要的时间(min) |
|
Planning |
计划 |
30 |
30 |
|
Estimate |
估计时间并做出规划 |
30 |
30 |
|
Development |
开发 |
2400 |
2700 |
|
Analysis |
需求分析 (包括学习新技术) |
30 |
30 |
|
Design Spec |
生成设计文档 |
10 |
10 |
|
Design Review |
设计复审 (和同事审核设计文档) |
10 |
10 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
5 |
5 |
|
Design |
具体设计 |
30 |
30 |
|
Coding |
具体编码 |
120 |
130 |
|
Code Review |
代码复审 |
10 |
10 |
|
est |
测试(自我测试,修改代码,提交修改) |
15 |
30 |
|
Reporting |
报告 |
30 |
43 |
|
Test Report |
测试报告 |
25 |
30 |
|
Size Measurement |
计算工作量 |
2 |
3 |
|
Postmortem & Process Improvement Plan |
事后总结 ,并提出过程改进计划 |
3 |
10 |
四、代码编写思路及优化
1.由于需要统计所有文件夹下文件,想先实现递归遍历目标路径下所有文件并输出对应的绝对路径,用于fopen函数。然而遍历所有文件路径并存于结构体数组中后循环调用时,却出现了debug assert的警告框。一开始毫无头绪并不知道这个警告框到底提示是什么方面出的错误,几番百度搜索之后无果。于是从头开始,每一步可能出错的地方都进行判断,最终发现存储文件路径有乱码,导致崩溃。简单的问题由于对VS不熟悉以及长时间没有编写C语言,导致我花了大量时间去排错,不过也慢慢熟练了一些。
2.在能成功打开所有文件后,开始对一个小的自己写的txt进行字符和换行数的统计,使用getc得到字符进行统计即可。放到整个文件下也统计出了数目,没有涉及数组等容易出错的方面所以没有崩溃。
3.接下来尝试对单个文件进行单词数的统计。一开始选用结构体数组,在统计小文件是没有问题,然而一旦放到大文件中,需要存储的单词有几百万个,直接就造成数组越界导致崩溃。于是想申请一个500万的数组,然而失败了。而且一旦单词数多了以后每次都要遍历查重,非常耗时。
4.决定舍弃结构体数组,使用哈希表。建立一个指针数组,指针指向存储单词和频率以及指针的结构体。由于一个单词包含4个字母,所以决定先使用前3个字母来作为一种映射。比如aaa开头的单词对应HASH[0],aab对应HASH[1],以此类推,共需要26*26*26大的哈希表。由于数据结构的时候已经学习过链表哈希表的操作,所以很快就写出了creat_hash、find_data_in_hash、insert_data_in_hash。其中用到了大量字符串的函数操作,例如使用strnicmp,strcmp等来进行单词的查重对比。小文件成功测试通过,大文件中保存了所有单词。
5.接下来的问题就是如何在整个百万的海量单词中比较快的找出前10名频率及其对应的单词。由于数据量比较庞大,决定使用快速排序。虽然总的单词数有几百万,然而实际出现的频率确不多,因为大部分都是频率为1、2、4等等。所以我通过遍历哈希表,取出了所有的频率放在frequency数组中,大致有2000+的频率个数,所以对此数组进行快速排序,得出一个有序的数组。从其中拿出前10的频率,再一次遍历哈希表,一旦发现有频率相等的,即输出此单词。并以一个count记录输出的单词数,一旦超出10个则跳出循环。
6.整个流程放到大文件中,运行时间大致在4分半,还是比较长的。接下来进行词组的统计。一开始打算在读取字符进行单词操作的同时进行词组的存储查重,结果测试小文件时候也发现了问题:新读取了更小的单词,则无法对已经保存的词组进行相应的替换。最后发现必须先读取完全部的单词后,才能对词组作出正确的替代。于是就只想出执行两遍、读取两遍字符的办法。创建两个哈希表,结构一样。读入每个单词后,查找原先保存单词的哈希表,找出ASCII值最小的单词,进行替换,再把之后的单词也进行替换,两者中间用空格连接,作为一个新的单词存入哈希表中。
7.由于使用的相同的哈希表,所以查找、插入的函数与之前单词相关的基本类似,而且更为简单,因为之前单词的对比要考虑大小写、数字,但是词组在组成之前已经查找了最小的进行替换,所以直接strcmp比较即可。统计完成后,输出前10的词组的操作也和之前类似。整个程序运行时间30分钟,第一部分单词的操作5分钟不到,第二部分对词组的操作花了整整25分钟。成功运行了结果,结果数据也还可以,于是考虑进行优化。
8.使用VS的性能探查器发现对词组的操作函数count_group占了67.90%,其中的查找单词哈希表的操作耗时较多。于是优化从这一步下手。思考之后发现将哈希表扩大,减少横向挂起的结构体即可有效提高查找的效率,而代价是映射函数复杂一点点。所以采用26*26*26*26大小的哈希数组,映射时前4个字母进行换算即可,aaaa对应0,aaab对应1。接着又发现之前遍历文件夹时将路径存储在了文件中再打开读出的方式非常的没有必要,于是将遍历到的绝对路径放于数组中,再直接从数组中拿出。
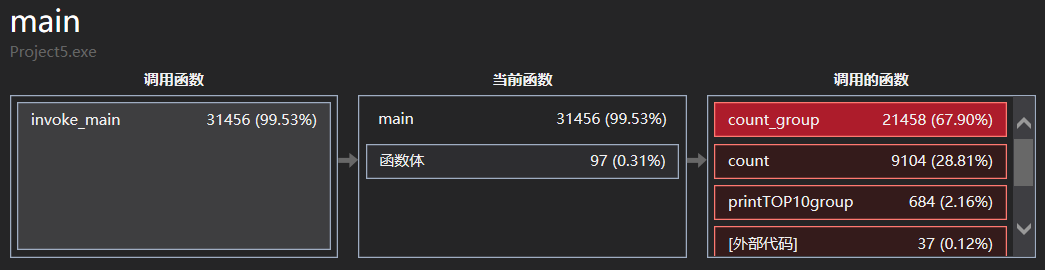
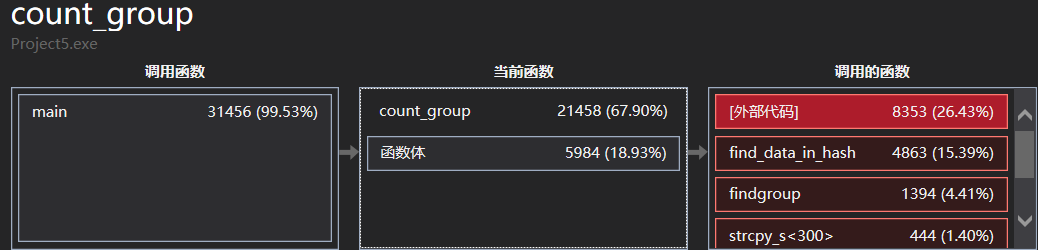
9.解决Linux平台移植问题:其中最主要的就是递归遍历文件的操作,windows下用io.h中的findfirst等函数,而linux中虽然成功的找到了io.h,却没有对应函数,于是换成了dirent.h中的opendir,其他函数也对应替换,总体思路一样,递归遍历将绝对路径存储在变量中,在取出用于fopen,即解决了移植问题。测速发现快于windows。linux下并不支持对结构体进行初始化定义,会报警告,于是去掉了初始化,在需要清空的地方手动处理。Linux下的字符、单词、换行总数皆与windows有差异,不过top10的单词词组频率确一致。
10.Linux性能分析:使用g++自带的性能分析工具gprof,编译时加上参数-pg -g生成gmon.out并再以命令行打开即可查看到相关函数调用次数、占用时间。可以看到对词组的操作函数count_group相比对单词的操作count函数,一个占22.14,一个占16.33。原因是收集到词组后每次都要查询单词哈希表找到最小ASCII单词。而查找单词的函数find_data_in_hash调用了33282154次,远高于其他函数(和每次调用该函数都一起要用的计算键值的函数calculate_key次数一样),用时也高达56.70%。这是扩大了哈希表指针数组大小后的结果,之前使用26*26*26大小的时候,用时更加长,高达79.14%。扩大哈希表指针数组(从26^3到26^4次),减小横向挂起的优化,使得查找单词的这一函数用时从79.14%降低到56.70%,因此该步优化效果显著。
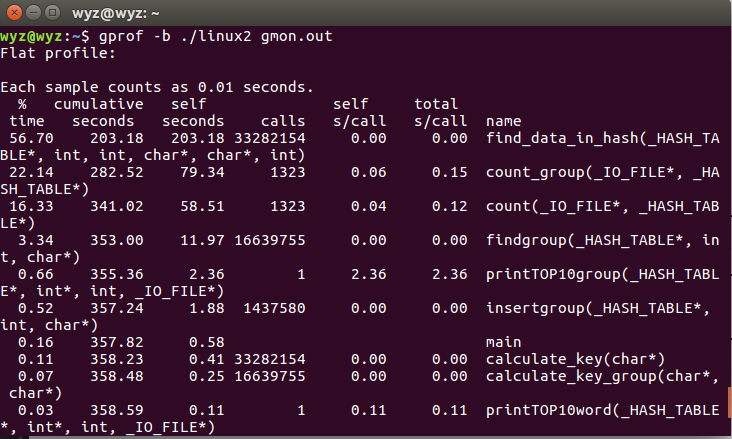
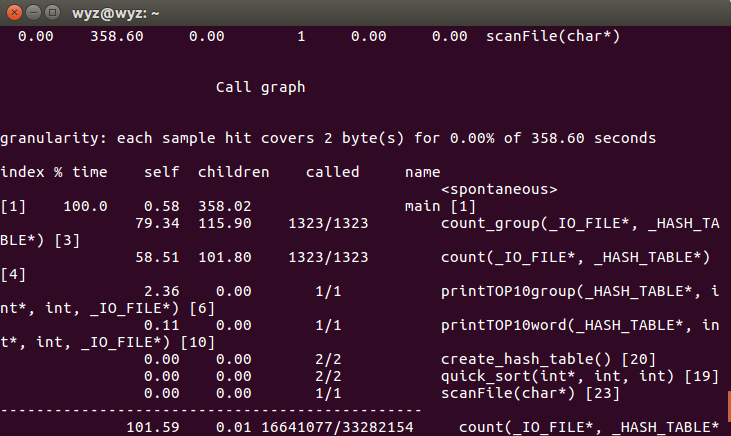
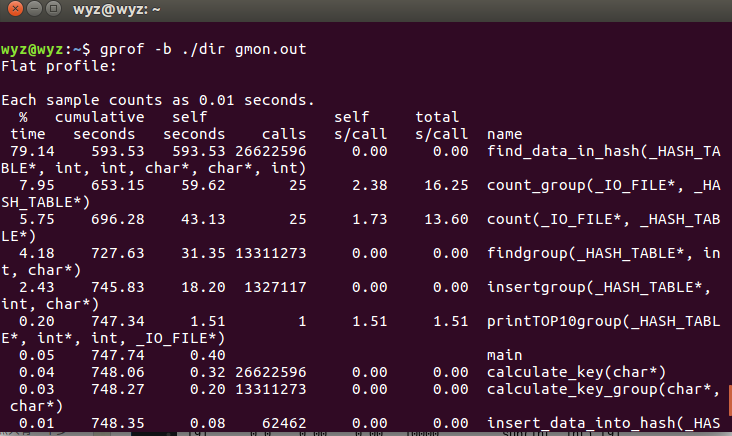 此图是优化前(用了稍微小一点的文件测试)
此图是优化前(用了稍微小一点的文件测试)
五、运行结果
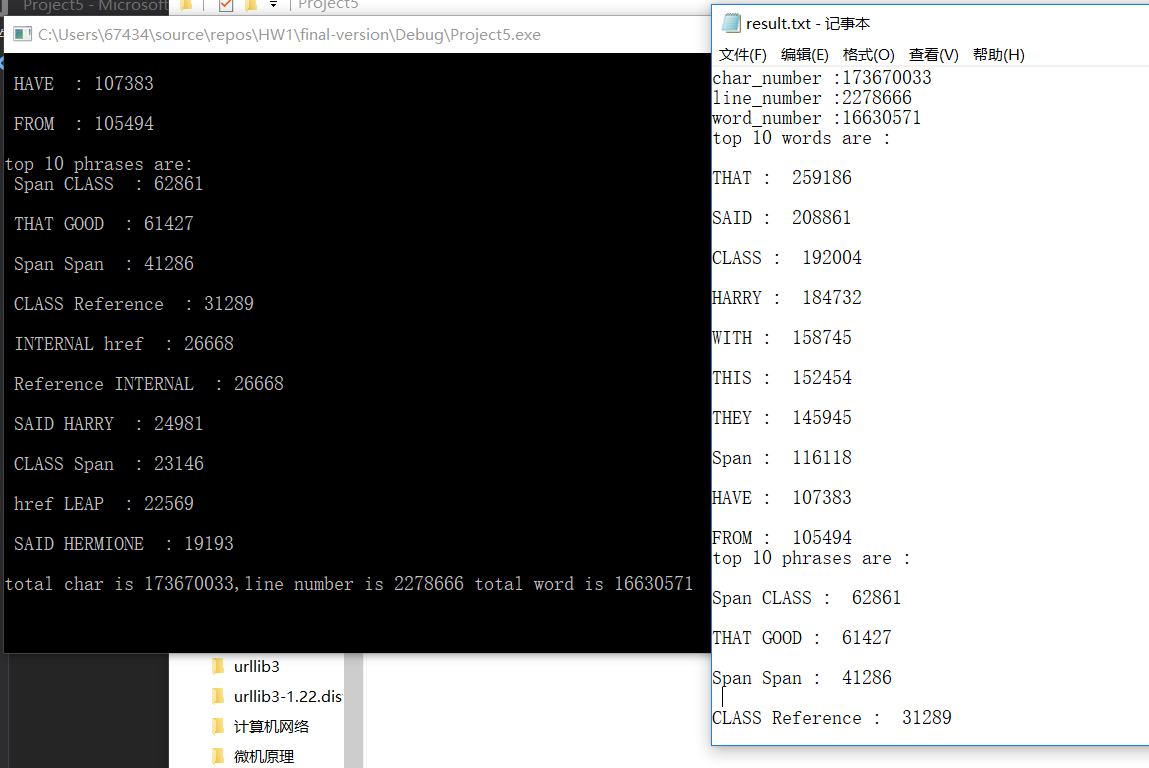
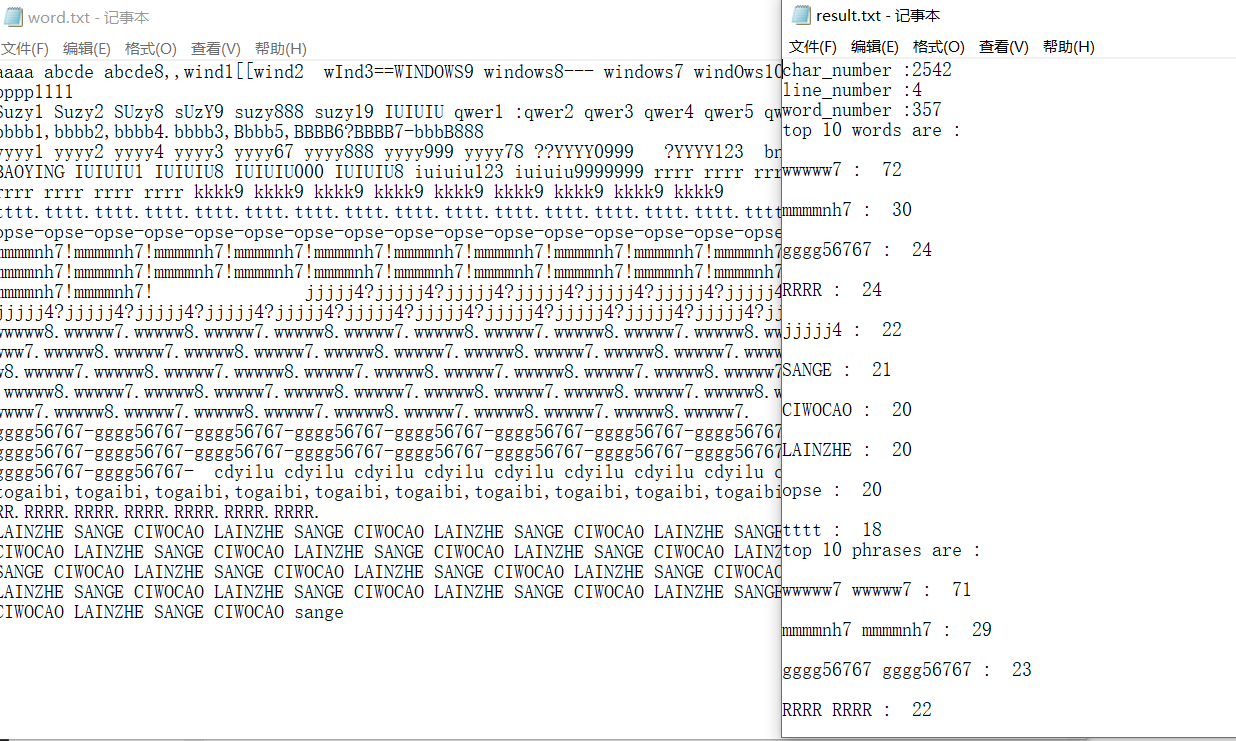

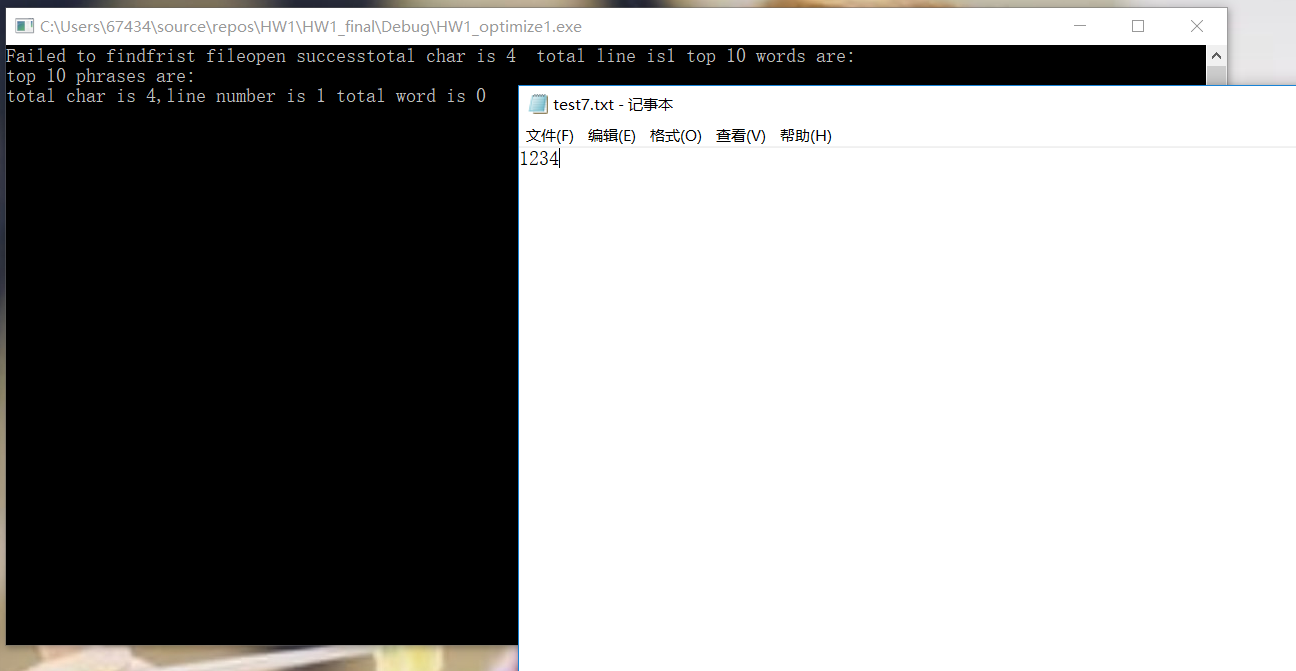
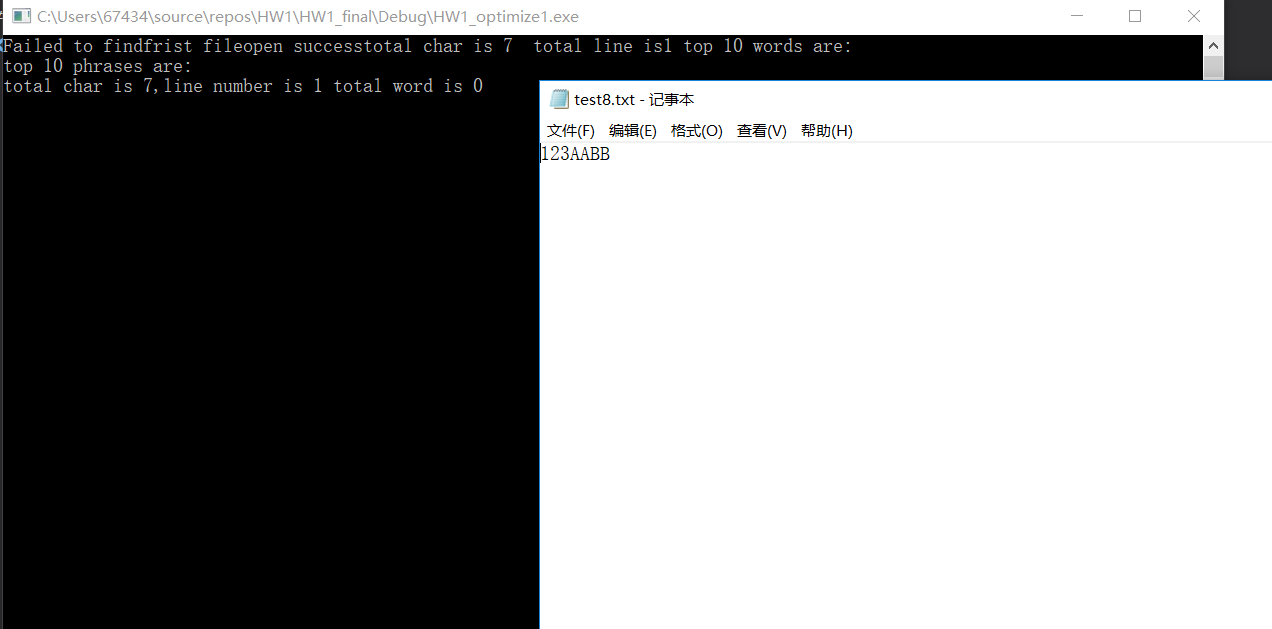
空文档以及一些自己写的小文件测试正确,比如ASCII小的正确替代计数、词组中的单词也一定是ASCII最小的单词;数字开头的也没有判定为单词;单纯的数字开头也没有记录进单词;newsample的结果字符、单词总数与助教提供答案有些不同不过单词和词组内容、频率完全一致。
六、总结体会
1.回顾了大量以前数据结构的知识,由于当初学的还算可以,所以重拾的也比较快,哈希表、快速排序的函数很快便能正确运行并且使用到整个项目中去。
2.一开始并不熟练,遇到bug后调试的效率比较低,各种大文件崩溃、结果莫名其妙等等。不过慢慢的就熟练了很多,看到跳出来的debug assert大致就知道哪个地方出了错因为已经看到这些框好多遍了。。
3.在与别人的交流中不断发现自己算法的漏洞并且听取别人好的思路真的非常有帮助。
4.之前最多用matlab写过几百行的算法但是并没有写过这么长的C语言,所以在代码的可读性上还是非常欠缺。虽然尽力保证每个变量名、函数名一读就懂,但是还是忍不住去使用一些只有自己知道的常量变量。。整个代码有些部分也显得非常冗余庞杂,还需要练习。。
七、部分函数代码(词组的略微有些不同)
int insert_data_into_hash(HASH_TABLE* pHashTbl, int data, int wordlength, char danci[])//用于向哈希表中插入单词及其频率
{
NODE* pNode;
if (NULL == pHashTbl)
return -1;
if (NULL == pHashTbl->value[data])
{
pNode = (NODE*)malloc(sizeof(NODE));//申请空间存入数据
memset(pNode, 0, sizeof(NODE));
strcpy(pNode->danci, danci); //将要存入的单词放入申请的空间中
pNode->frequency = 1;
pNode->next = NULL;
pHashTbl->value[data] = pNode; //将申请的、存入数据的空间由哈希表指针指向
return 1;
}
pNode = pHashTbl->value[data];
while (NULL != pNode->next)
pNode = pNode->next;
pNode->next = (NODE*)malloc(sizeof(NODE));
memset(pNode->next, 0, sizeof(NODE));
strcpy(pNode->next->danci, danci);
pNode->next->frequency = 1;
pNode->next->next = NULL;
pNode = pNode->next;
return 1;
}
int find_data_in_hash(HASH_TABLE* pHashTbl, int data, int wordlength, char danci[], char smallword[], int onlyfind)//用于查找哈希表中是否已存在相同数据
{
NODE* pNode;
int j, flagend = 0, insertornot = 0;
if (NULL == pHashTbl)
return -1;
if (NULL == (pNode = pHashTbl->value[data]))
{
insertornot = insert_data_into_hash(pHashTbl, data, wordlength, danci); //对应位置还没有任何数据,则调用插入函数存放数据
if (insertornot == -1)
printf("insert error");
return 1;
}
while (pNode)
{
for (j = wordlength - 1; j >= 0; j--) //对应位置有数据,则对比是否为同一单词
{
if ((danci[j] <= 122 && danci[j] >= 97) || (danci[j] <= 90 && danci[j] >= 65))
{
flagend = j;
break;
}
}
for (j = word - 1; j > 0; j--)
{
if ((pNode->danci[j] <= 122 && pNode->danci[j] >= 97) || (pNode->danci[j] <= 90 && pNode->danci[j] >= 65))
{
if (flagend < j)
{
flagend = j;
break;
}
}
}
if (strncasecmp(pNode->danci, danci, flagend + 1) == 0) //不区分大小写对比
{
if (onlyfind != 1) //由于在词组操作中,也会用到该查找函数,此时不能算入出现频率,所以通过onlyfind变量来控制是否提高频率次数
{
pNode->frequency++;
}
if (strcmp(pNode->danci, danci) > 0) //比较出较小的ASCII码,将小的赋值给指针对应位置
strcpy(pNode->danci, danci);
strcpy(smallword,pNode->danci);
return 2;
}
else if (pNode->next == NULL)
{
insertornot = insert_data_into_hash(pHashTbl, data, wordlength, danci);
if (insertornot == -1)
printf("insert error");
return 1;
}
pNode = pNode->next;
}
return 1;
}
int calculate_key(char temp[]) { //用于计算一个单词在哈希表中对应的位置
int qianwei = 0, baiwei = 0, shiwei = 0, gewei = 0,data=0;
if (temp[0] <= 90 && temp[0] >= 65)
qianwei = temp[0] + 32; //将单词第一位对应为千位,第二位对应百位,第三位对应十位,第四位对应个位
else
qianwei = temp[0];
if (temp[1] <= 90 && temp[1] >= 65) //不区分大小写
baiwei = temp[1] + 32;
else
baiwei = temp[1];
if (temp[2] <= 90 && temp[2] >= 65)
shiwei = temp[2] + 32;
else
shiwei = temp[2];
if (temp[3] <= 90 && temp[3] >= 65)
gewei = temp[3] + 32;
else
gewei = temp[3];
data = (qianwei - 97) * 17576 + (baiwei - 97) * 676 + (shiwei - 97) * 26 + gewei - 97;
if(data>=0&&data<hash_size) //若读入了数字 容易造成data小于0的情况,故必须排除
return data;
else
return -1;
}
int count(FILE*fp, HASH_TABLE*pHashTbl) {
char ch, temp[word] = { 0 }, smallword[word] = { 0 };
int charnumber = 0, i = 0, j = 0, flag = 0;
int shiwei = 0, gewei = 0, data = 0, wordlength = 0, findornot, baiwei = 0,qianwei=0;
charnumber = 0;
while (!feof(fp))
{
// printf("char is %c and ASCII is %d\n",ch,ch);
ch = fgetc(fp);
if ((ch >= 48 && ch <= 57) || (ch >= 97 && ch <= 122) || (ch >= 65 && ch <= 90))
{
temp[i++] = ch; //读入字母或数字则存入字符数组中
charnumber++;
}
else //遇到分隔符则对已经收集到数组中的数据进行判断是否为单词
{
if (ch == '\n')
linenumber++;
else if(ch>31&&ch<=127)
charnumber++;
if (i>1024||i<4 || (temp[0] <= 57 && temp[0] >= 48) || (temp[1] <= 57 && temp[1] >= 48) || (temp[2] <= 57 && temp[2] >= 48) || (temp[3] <= 57 && temp[3] >= 48))
{
for (j = 0; j < word; j++) //若长度大于1024小于4或前4个中有数字,则不算单词,清空用于存储的数组,开始下一轮
temp[j] = '\0';
i = 0;
}
else {
data=calculate_key(temp); //调用函数求对应哈希表中的位置
wordlength = i;
if(data>=0&&data<hash_size) //防止data越界导致崩溃
findornot = find_data_in_hash(pHashTbl, data, wordlength, temp, smallword, 0);
if (findornot == -1)
printf("hash is empty");
for (j = 0; j < word; j++)
temp[j] = '\0';
i = 0;
}
}
}
if (i >= 4) //若文件的末尾直接是EOF,按照上面的流程将有一部分字符留在temp中,需要再次拿出来做判断
{
data=calculate_key(temp);
printf("temp is %s data is %d",temp,data);
wordlength = i;
if(data>=0&&data<hash_size)
findornot = find_data_in_hash(pHashTbl, data, wordlength, temp, smallword, 0);
if (findornot == -1)
printf("hash is empty");
for (j = 0; j < word; j++)
temp[j] = '\0';
}
return charnumber;
}
void printTOP10word(HASH_TABLE*pHashTbl, int frequency_value[], int k, FILE*fp_result) { //输入前10频率数组,找到对应的单词并输出
int j = 0, m = 0, i = 0, count = 0;
NODE * pNode = NULL;
char TOPword[word] = { 0 };
fprintf(fp_result, "top 10 words are :\n");
for (i = k; i > k - 11 && i >= 0 && count <= 10; i--)
{
for (j = 0; j < hash_size && count <= 10; j++) {
if (pHashTbl->value[j] != NULL) {
pNode = pHashTbl->value[j];
while (pNode != NULL) {
if (pNode->frequency == frequency_value[i]) { //找到对应频率的单词
if (count >= 10) //记录输出的单词数,超过10个则不再输出
break;
else
{
strcpy(TOPword, pNode->danci);
printf(" %s : %d\n\n", TOPword, frequency_value[i]);
fprintf(fp_result, " \n%s : %d\n", TOPword, frequency_value[i]);
count++;
}
}
pNode = pNode->next;
}
}
}
}
}


