排序3 - 快速排序和归并排序
为什么要把快速排序和归并排序放在一起写?因为它们都涉及到一个通用的算法——分治法。
分治法
分治法顾名思义,分而治之,也即把一个较大的问题分解为若干个较小的问题解决,然后再把子问题的解合并为原来问题的解。
分治法一般分为三个步骤:
- 分
- 治
- 合
什么问题适合用分治法解决?一般有如下三个特征:
- 可分,问题可以分解为若干个规模较小的相同问题。
- 可治,问题规模更小更容易解决。
- 可合,该问题分解出的子问题的解可以合成原问题的解。
最好子问题之间相互独立,不包含公共子问题,不然虽然可以求解,但是重复计算开销较大,不如使用动态规划求解。
不同问题,分治法解决的难度也不一样,有的容易分不容易合,有的容易合但是不容易分。另外,分治法一般和递归一起出现。
快速排序
快排的大名可谓是如雷贯耳,jdk源码中用的就是快速排序。快速排序是典型的分治法应用,每趟排序将数组分为基准项、比基准项小的一组和大于等于其的另一组三个部分,然后对两个子数组再递归的调用自己。结合分治法来看,一趟比较就是一趟切分,当元素个数小于3的时候就能保证,切分后为有序。另外,快排不需要刻意的去把子问题的解合成为原问题的解,子问题解决了,原问题自动得解。
说得好像比较抽象,快排的算法伪代码如下:
quickSort(A, left, right) splitPoint ← split(A, left, right); quicksort(A, left, splitPoint - 1); quickSort(A, splitPoint + 1, right);
盗个图,看下示例,其中绿色块为比较基准元:

说白了,一趟遍历,就是将原数组切分成两个子数组,之前鄙人写过一个python版本,是自己想出来的。简单的说,设第一个为基准元,遍历整个数组,发现比基准元小的元素就插入第二个位置,然后下个插入第三个位置,依次类推。整个过程维护两个指针,一个指向当前遍历的位置,另一个指向下一个小于基准元的元素应当插入的位置。代码如下:
1 @staticmethod 2 def quick_sorter(data_list, start, end): 3 """ 4 :param data_list 5 :p_type: list 6 :return: sorted_list 7 : r_type: list 8 """ 9 if start == 0 and end == len(data_list) and not my_sorter.check_data(data_list): 10 11 return 12 13 flag = data_list[start] 14 index = start 15 16 for i in xrange(start + 1, end): 17 if data_list[i] < flag: # 将小于flag的元素依次插入下个位置 18 data_list[index] = data_list[i] 19 data_list[i] = data_list[index + 1] 20 index += 1 21 22 data_list[index] = flag 23 24 if index - start > 1: 25 my_sorter.quick_sorter(data_list, start, index) 26 if end - index > 1: 27 my_sorter.quick_sorter(data_list, index + 1, end) 28 29 return data_list
虽然思想上实现了快排,后来看了经典的快排之后,发现自己这个版本元素交换次数太多了。经典快排算法也是维护两个指针,一个从前往后,一个从后往前,第一个指针一旦发现比基准元大的元素则停止,然后第二个指针一旦发现比基准元小的元素停止,然后两个位置的元素相互交换,从而保证两个指针所指过的元素,一个全部比基准元小,一个大于等于基准元。这种办法比我的好理解,而且交换次数较少,因为第一个指针对比基准元小的元素不操作,同样第二个指针对大于等于基准元的元素不操作。姜还是老的辣呀!贴上实例图:
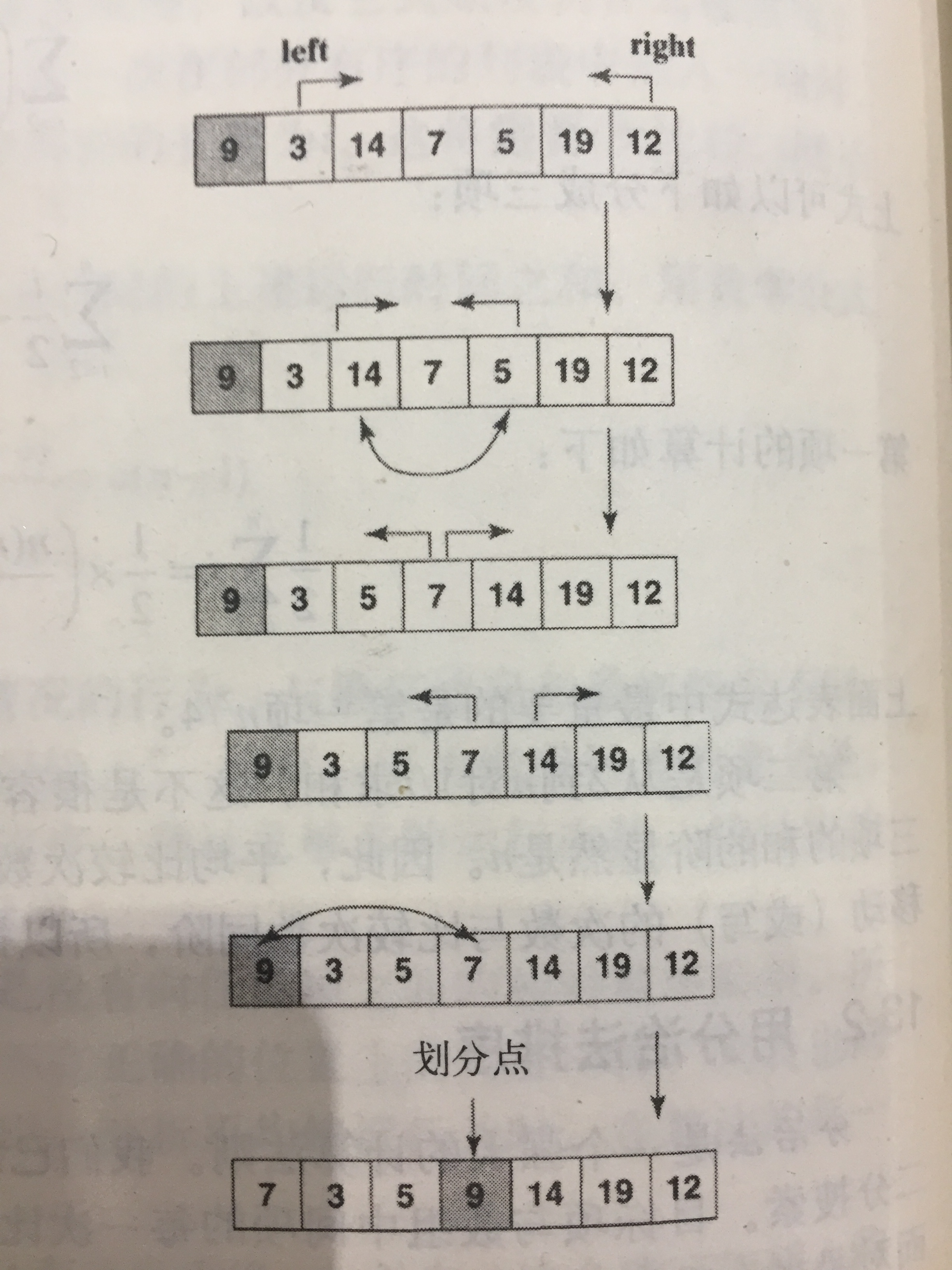
给出其实现的伪代码:
split(A, lo, hi) flag ← A[lo]; left ← lo+1; right ← hi; while(left<=right) do while(left<=right and A[left]<flag) do left ← left+1; end while while(left<=right and A[right]>=flag) do right ← right-1; end while if(left<right) then swap A[left] with A[right]; left ← left+1; right ← right-1; end if end while swap A[lo] with A[right]; return right;
快排的复杂度和稳定性
快排是分治法的应用,快排之所以快是因为每次都将其分成了两个子数组,使得下次比较需要的比较次数变少。什么是最好情况,什么又是最坏情况,举个例子:
像上图快排树为平衡树的时候是最好情况,完全偏斜树(也即输入数组为有序状态)是最坏情况。最好情况下,树高为 lg n, 树的层数对应着递归的深度,每层比较的时间复杂度为O(n),整棵树的时间复杂度对应快排的时间复杂度,也即O(n lg n)。最坏情况下,完全偏斜树,树高为 n,每层比较的时间复杂度为 O(n), 总的时间复杂度为O(n2)。
所以我们要尽量避免有序情况的发生,怎么做?随机选择基准元,选择后将其与第一个元素对换,在运行之前的算法即可。还有一种办法,选择第一个、最后一个、中间那个,三个元素的中间值,这样可以一定程度的缓解病态。
快排是基于递归来实现的,递归树的树高平均为lg n, 所以平均空间复杂度为O(lg n),最坏情况下空间复杂度为O(n)。
另外,在最后交换基准元的步骤中,可能会破坏相同元素之间的相对位置,所以为不稳定排序算法。
一个问题
在快排中,把一个子数组一分为二后,对两个子数组递归调用,那么先排序哪个数组?
当然不管排序哪个数组,都能解决问题。但是不同的子数组排序顺序带来的空间消耗不同。要知道,每次递归调用,都会先把当前情况入栈,调用结束后再出栈。如果我们优先排序长度较大的子数组,那么较小的数组就需要入栈。由于较大的子数组的递归深度较较小的子数组更深,如此深入下去,小的子数组入栈越来越多,带来的空间消耗就会越来越严重。所以好的办法,应当是优先排序长度较小的子数组。
归并排序
归并排序也是分治法的应用,与快排不同,快排最难的是切分原问题的过程,而归并排序切分简单,难点在于将子问题的解合成为原问题的解。
简单描述归并排序的过程,归并排序分为两个阶段:
- 向下切分阶段。遍历原数组,找到原数组中间元素的位置,以该元素为切分点,将原数组切分为两部分。递归切分,直到子数组长度为1停止。
- 向上合并阶段。从长度为1的子数组出发,两两合并子数组,每次合并,保证新数组为有序。直到整个数组的元素全部合并。
给个书上的实例图,感受一下:
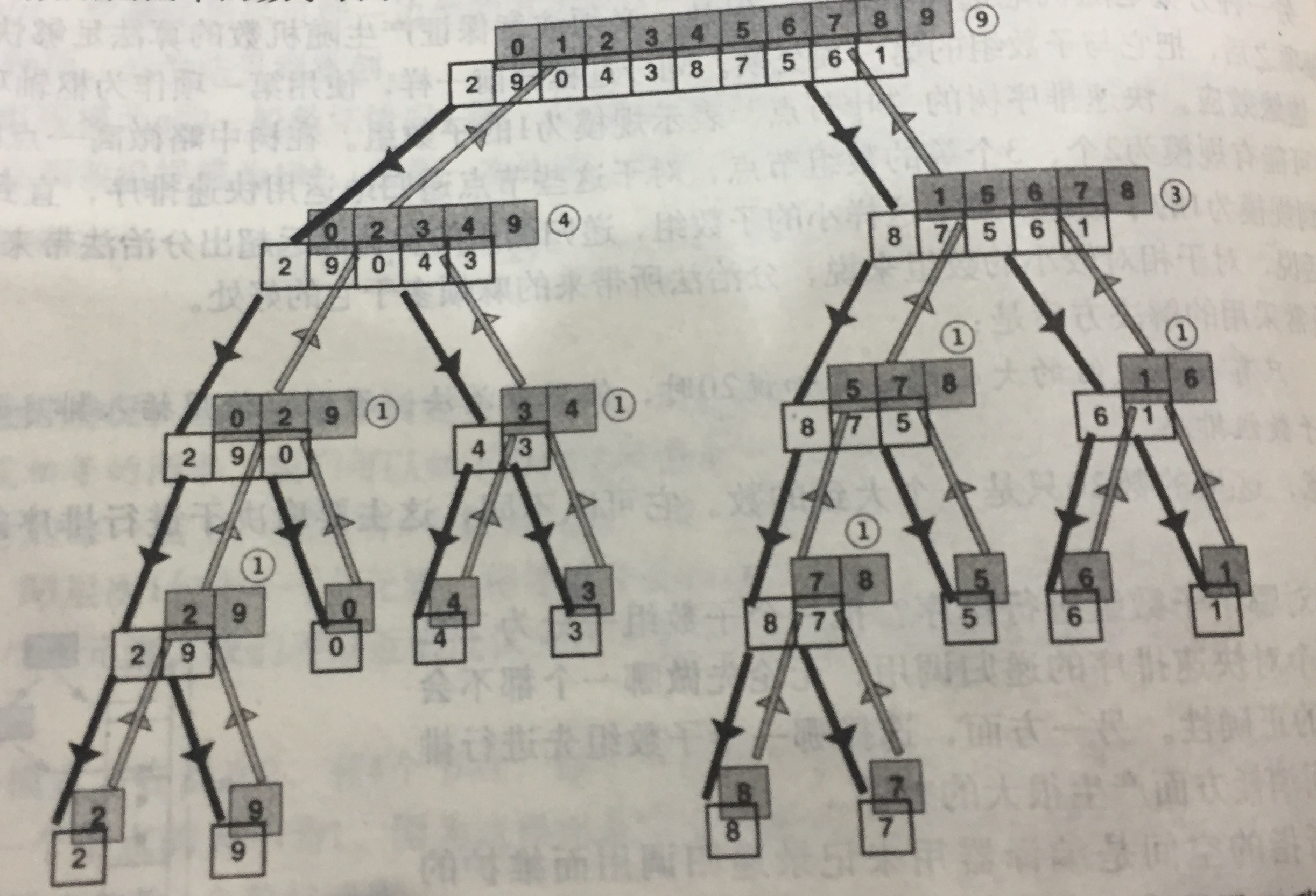
因为每次都是从中间位置切分数组,递归排序树明显是个二叉平衡树。
归并排序的复杂度和稳定性
请原谅我绕过代码直接讨论复杂度,因为我们需要先确定递归排序的数据结构。
什么鬼?不是对数组排序吗?
是的,之前都是对数组排序,这里同样可以使用数组。但如果采用数组的话,在向上合并的过程中,两个有序子数组合成实质上是将值赋给新数组,最后再拷贝回去,这样会有O(n)的空间消耗。当然,我们不能忽略数组在向下切分过程的好处,因为可以随机访问,所以只需要O(1)的时间。但向上合并呢,没错,每层都需要O(n)的时间复杂度,结合树高 lg n,总的时间复杂度为 O(n lg n),空间复杂度为O(n)。
如果采用链表呢?链表的向上合成过程,时间复杂度同数组为 O(n lg n),但不需要额外空间,只需要改变节点指向就可以了。链表的弊端是向下切分的过程,每层的遍历时间复杂度为O(n),结合树高,向下切分过程的时间复杂度为O(n lg n)。算上合并的时间,总的时间复杂度依旧是O(n lg n),空间复杂度为O(lg n)。
元素位置变化只发生在向上合成阶段,由于合并是依次比较,没有破坏之前元素的相对位置,所以为稳定排序。
归并排序的实现
以链表为数据结构实现递归排序,整个递归排序的伪代码如下:
mergeSort(A, length) if length>1 then splitMap ← split(A, length) B ← splitMap.get("pointer"); Blength ← splitMap.get("secondLength"); mergeSort(A, length-Blength); mergeSort(B, Blength); merge(A, length-Blength, B, Blength); end if
向下切分的过程在split中实现,太过简单就不写了,写下难点merge的伪代码:
merge(A, lenA, B, lenB) if(lenA==0) then return B; else if(lenB==0) then return A; end if if(A.data <= B.data) then #设置初始节点 new ← A; A ← A.next; lenA ← lenA-1; else new ← B; B ← B.next; lenB ← lenB-1; end if pre ← new; while(lenA>0 and lenB>0) do #合并子数组直至一个数组全部合并完成 if(A.data<=B.data) then pre.next ← A; A ← A.next; lenA ← lenA-1; else pre.next A ← B; B ← B.next; lenB ← lenB-1; end if pre ← pre.next; if(lenA>0) then # 检查是否有一个数组还有元素没有合并 pre.next ← A; else if(lenB>0) then pre.next ← B; end if return new;
可能有轻微的小错误,还望大神轻喷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号