词频统计——软工第一次个人作业
词频统计
1.项目要求和基本功能
项目要求
- 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
- 使用性能测试工具进行分析,找到性能的瓶颈并改进
- 对代码进行质量分析,消除所有警告,http://msdn.microsoft.com/en-us/library/dd264897.aspx
- 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
- 使用Github进行代码管理
- 撰写博客
基本功能
- 统计文件的字符数(只需要统计Ascii码,汉字不用考虑)
- 统计文件的单词总数
- 统计文件的总行数(任何字符构成的行,都需要统计)
- 统计文件中各单词的出现次数,输出频率最高的10个。
- 对给定文件夹及其递归子文件夹下的所有文件进行统计
- 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
- 在Linux系统下,进行性能分析,过程写到blog中(附加题)
2.PSP表格
| Statu | Stages | 预估耗时/min | 实际耗时/min |
| Accept | 【计划】 | 30 | 20 |
| Accept | 估计时间 | 30 | 20 |
| Accept | 【开发】 | 1330 | 1910 |
| Accept | 需求分析 | 20 | 30 |
| Accept | 设计文档 | 30 | 30 |
| Accept | 设计复审 | 10 | 5 |
| Accept | 代码规范 | 10 | 5 |
| Accept | 具体设计 | 60 | 60 |
| Accept | 具体编码 | 600 | 1000 |
| Accept | 代码复审 | 300 | 300 |
| Accept | 测试 | 300 | 480 |
| Accept | 【记录用时】 | 10 | 10 |
| Accept | 【测试报告】 | 30 | 60 |
| Accept | 【算工作量】 | 10 | 10 |
| Accept | 【总结改进】 | 60 | 60 |
| Accept | 【合计】 | 1470 | 2090 |
3.解题思路
数据结构:
全局变量
unsigned long characterNum;//存放字符数 unsigned long wordNum; //存放单词数 unsigned long lineNum; //存放行数
采用结构体数组(动态内存)存储单词及其出现次数


struct wordInfo { char* wordStr; char** nextWordPoint; int* nextWordFrequency; int presentNextWordNum; int frequency; int strlength; int wordLength;//不包含最后的数字部分 }; struct alphaArray { wordInfo* wordArray; int presentWordArrayLength; }; struct wordStatisticsResult { char* wordStr; int wordFrequency; }; struct phaseStatisticsResult { char* firstStr; char* secondStr; int phaseFrequency; };
遍历文件的方法:
_findfirst,_findnext函数实现(Windows平台),参考例程
readdir函数实现(Linux平台),参考例程
具体实现方案:
1>主函数:
初始化各变量
遍历给定文件夹中的每个文件
只读方式打开符合要求的文件
单词统计,词组统计
循环至所有文件遍历完成
关闭文件
输出统计结果
2>单词统计:
遍历字符并统计
判断是否是换行符并统计
建立缓冲区域存储一个单词中连续的字符
采集单词字符串
生成单词的哈希值(散列函数使用ELFHash、冲突解决方案采用二次探测)
根据首字母和哈希值确定单词的存储位置并存储单词信息
将当前单词的地址存储到前一个单词的结构体中,以实现词组频率统计
3>词组统计:
存储单词
返回当前单词在词表中的位置
如果不是第一个单词
根据位置得到字符串指针
在前一个单词的结构体中查找是否存在该指针
如果存在 该指针对应计数加一
如果不存在 存储该指针,初始化数量为1
记录该位置
最后遍历即可得到所有词组出现频率
4.代码实现
(1)初始化词表
1 void dictionaryInit(struct alphaArray* dictionary) 2 { 3 int i, j, k; 4 characterNum = 0; 5 wordNum = 0; 6 lineNum = 0; 7 for (i = 0; i < alphabet; i++) 8 { 9 (dictionary + i)->wordArray = (wordInfo*)malloc(sizeof(wordInfo)*wordArrayLength); 10 (dictionary + i)->presentWordArrayLength = wordArrayLength; 11 if ((dictionary + i)->wordArray == NULL) exit(-1); 12 for (j = 0; j < (dictionary + i)->presentWordArrayLength; j++) 13 { 14 ((dictionary + i)->wordArray + j)->wordStr = (char*)malloc(sizeof(char)*wordStrLength); 15 if (((dictionary + i)->wordArray + j)->wordStr == NULL) exit(-1); 16 *(((dictionary + i)->wordArray + j)->wordStr) = '\0'; 17 ((dictionary + i)->wordArray + j)->frequency = 0; 18 ((dictionary + i)->wordArray + j)->strlength = wordStrLength; 19 ((dictionary + i)->wordArray + j)->wordLength = 0; 20 ((dictionary + i)->wordArray + j)->nextWordPoint = (char**)malloc(sizeof(char*)*nextWordNum); 21 if (((dictionary + i)->wordArray + j)->nextWordPoint == NULL) exit(-1); 22 ((dictionary + i)->wordArray + j)->nextWordFrequency = (int*)malloc(sizeof(int)*nextWordNum); 23 if (((dictionary + i)->wordArray + j)->nextWordFrequency == NULL) exit(-1); 24 for (k = 0; k < nextWordNum; k++) 25 { 26 *(((dictionary + i)->wordArray + j)->nextWordPoint + k) = NULL; 27 *(((dictionary + i)->wordArray + j)->nextWordFrequency + k) = 0; 28 } 29 ((dictionary + i)->wordArray + j)->presentNextWordNum = nextWordNum; 30 } 31 } 32 }
申请初始内存空间并将所有值置零。
(2)遍历文件夹
a)Windows平台
1 void traverseFileandCount(char* filePath, struct alphaArray* dictionary) 2 { 3 _finddata_t FileInfo; 4 char* presentPath; 5 char* newPath; 6 presentPath = (char*)malloc(sizeof(char)*filePathLength); 7 if (presentPath == NULL) exit(-1); 8 newPath = (char*)malloc(sizeof(char)*filePathLength); 9 if (newPath == NULL) exit(-1); 10 strcpy_s(presentPath, filePathLength, filePath); 11 strcat_s(presentPath, filePathLength, "\\*"); 12 long Handle = _findfirst(presentPath, &FileInfo); 13 if (Handle == -1L) exit(-1); 14 do { 15 if (FileInfo.attrib & _A_SUBDIR) 16 { 17 if ((strcmp(FileInfo.name, ".") != 0) && (strcmp(FileInfo.name, "..") != 0)) 18 { 19 generatePath(FileInfo, filePath, newPath); 20 traverseFileandCount(newPath, dictionary); 21 } 22 } 23 else 24 { 25 generatePath(FileInfo, filePath, presentPath); 26 count(presentPath, dictionary); 27 } 28 } while (_findnext(Handle, &FileInfo) == 0); 29 _findclose(Handle); 30 free(presentPath); 31 free(newPath); 32 }
b)Linux平台
1 void traverseFileandCount(char* path, struct alphaArray* dictionary) 2 { 3 DIR *pDir; //定义一个DIR类的指针 4 struct dirent *ent=NULL; //定义一个结构体 dirent的指针,dirent结构体见上 5 int i = 0; 6 char childpath[512]; //定义一个字符数组,用来存放读取的路径 7 pDir = opendir(path); // opendir方法打开path目录,并将地址付给pDir指针 8 memset(childpath, 0, sizeof(childpath)); //将字符数组childpath的数组元素全部置零 9 while ((ent = readdir(pDir)) != NULL) 10 //读取pDir打开的目录,并赋值给ent, 同时判断是否目录为空,不为空则执行循环体 11 { 12 if (ent->d_type&DT_DIR) 13 /*读取 打开目录的文件类型 并与 DT_DIR进行位与运算操作,即如果读取的d_type类型为DT_DIR 14 (=4 表示读取的为目录)*/ 15 { 16 if (strcmp(ent->d_name, ".") == 0 || strcmp(ent->d_name, "..") == 0) 17 //如果读取的d_name为 . 或者.. 表示读取的是当前目录符和上一目录符, 18 //则用contiue跳过,不进行下面的输出 19 continue; 20 sprintf(childpath, "%s/%s", path, ent->d_name); 21 //如果非. ..则将 路径 和 文件名d_name 付给childpath, 并在下一行prinf输出 22 //printf("path:%s\n",childpath);原文链接这里是要打印出文件夹的地址 23 traverseFileandCount(childpath, dictionary); 24 //递归读取下层的字目录内容, 因为是递归,所以从外往里逐次输出所有目录(路径+目录名), 25 //然后才在else中由内往外逐次输出所有文件名 26 } 27 else 28 //如果读取的d_type类型不是 DT_DIR, 即读取的不是目录,而是文件, 29 //则直接输出 d_name, 即输出文件名 30 { 31 //cout<<ent->d_name<<endl; 输出文件名 32 //cout<<childpath<<"/"<<ent->d_name<<endl; 输出带有目录的文件名 33 sprintf(childpath, "%s/%s", path, ent->d_name); 34 //你可以唯一注意的地方是下一行 35 //目前childpath就是你要读入的文件的path了,可以作为你的读入文件的函数的参数 36 count(childpath, dictionary);//这里就是你的处理文件的接口!, 37 } 38 } 39 }
(3)计数
1 void count(char* path, struct alphaArray* dictionary) 2 { 3 FILE* fp; 4 bool firstWordSign = 1; 5 int i = 0; 6 int finalAlphaPosition = 0; 7 int tempWordStrLength = wordStrLength; 8 int presentWordOffset; 9 char ch, *tempWordStr; 10 unsigned long hash; 11 struct wordInfo* lastWordInfo = NULL, *presentWordInfo = NULL; 12 tempWordStr = (char*)malloc(sizeof(char)*wordStrLength); 13 if (tempWordStr == NULL) exit(-1); 14 if (fopen_s(&fp, path, "r") != 0) exit(-1); 15 do 16 { 17 ch = fgetc(fp); 18 characterNumandLineNum(ch); 19 if (!isDigitorAlpha(ch)) 20 { 21 tempWordStr[i] = '\0'; 22 if (isWord(tempWordStr)) 23 { 24 hash = storeTempWord(dictionary, tempWordStr, finalAlphaPosition); 25 getOffset(presentWordOffset, tempWordStr[0]); 26 presentWordInfo = ((dictionary + presentWordOffset)->wordArray + hash); 27 if (!firstWordSign) 28 storePhaseInfo(lastWordInfo, presentWordInfo); 29 lastWordInfo = presentWordInfo; 30 firstWordSign = 0; 31 } 32 i = 0; 33 finalAlphaPosition = 0; 34 tempWordStr[0] = '\0'; 35 } 36 else 37 { 38 if (i < wordStrLength) 39 { 40 if (isAlpha(ch)) finalAlphaPosition = i; 41 tempWordStr[i++] = ch; 42 } 43 /*if (i >= tempWordStrLength) 44 { 45 tempWordStrLength *= 2; 46 tempWordStr = (char*)realloc(tempWordStr, sizeof(char)*tempWordStrLength); 47 if (tempWordStr == NULL) exit(-1); 48 }*/ 49 } 50 } while (ch != EOF); 51 free(tempWordStr); 52 lineNum++; 53 fclose(fp); 54 }
(4)存储单词信息
1 unsigned long storeTempWord(struct alphaArray* dictionary, char* tempWordArray, int lastAlphaPosition) 2 { 3 unsigned long hash = 0; 4 int i = 0, j = 0, offset; 5 char* wordstrPoint; 6 struct alphaArray* page; 7 hash = ELFHash(tempWordArray, lastAlphaPosition); 8 getOffset(offset,tempWordArray[0]); 9 page = dictionary + offset; 10 hash = hash % (page->presentWordArrayLength); 11 //hash=hash%wordArrayLength; 12 wordstrPoint = (page->wordArray + hash)->wordStr; 13 while (!isEmpty(wordstrPoint) && isDifferent(page->wordArray + hash, tempWordArray, lastAlphaPosition)) 14 { 15 i++; 16 if (i > (page->presentWordArrayLength)) 17 { 18 enlargeWordArrayLength(page); 19 i = 0; 20 } 21 hash += i * i; 22 hash = hash % (page->presentWordArrayLength); 23 wordstrPoint = (page->wordArray + hash)->wordStr; 24 } 25 /*while ((int)strlen(tempWordArray) >= (page->wordArray + hash)->strlength) 26 enlargeStrLength(page, hash);*/ 27 if ((int)strlen(tempWordArray) >= (page->wordArray + hash)->strlength) 28 *(tempWordArray + (page->wordArray + hash)->strlength - 1) = '\0'; 29 wordstrPoint = (page->wordArray + hash)->wordStr; 30 if (isEmpty(wordstrPoint)) 31 { 32 strcpy_s(wordstrPoint, strlen(tempWordArray)+1, tempWordArray); 33 (page->wordArray + hash)->wordLength = lastAlphaPosition; 34 } 35 else 36 { 37 if (strcmp(wordstrPoint, tempWordArray) > 0) 38 strcpy_s(wordstrPoint, strlen(tempWordArray)+1, tempWordArray); 39 } 40 (page->wordArray + hash)->frequency++; 41 wordNum++; 42 return hash; 43 }
(5)存储词组信息
1 void storePhaseInfo(struct wordInfo* lastWordInfo, struct wordInfo* presentWordInfo) 2 { 3 int i = 0, k = 0; 4 bool stored = 0; 5 for (i = 0; i < (lastWordInfo->presentNextWordNum);) 6 { 7 if ((*(lastWordInfo->nextWordFrequency + i)) != 0) 8 { 9 if ((*(lastWordInfo->nextWordPoint + i)) == presentWordInfo->wordStr && !stored) 10 { 11 (*(lastWordInfo->nextWordFrequency + i))++; 12 stored = 1; 13 } 14 else 15 i++; 16 } 17 else 18 break; 19 } 20 if (i == (lastWordInfo->presentNextWordNum)) 21 { 22 lastWordInfo->nextWordPoint = (char**)realloc(lastWordInfo->nextWordPoint, sizeof(char*)*(lastWordInfo->presentNextWordNum) * 2); 23 if (lastWordInfo->nextWordPoint == NULL) exit(-1); 24 lastWordInfo->nextWordFrequency = (int*)realloc(lastWordInfo->nextWordFrequency, sizeof(int)*(lastWordInfo->presentNextWordNum) * 2); 25 if (lastWordInfo->nextWordFrequency == NULL) exit(-1); 26 for (k = (lastWordInfo->presentNextWordNum); k < (lastWordInfo->presentNextWordNum)*2; k++) 27 { 28 *(lastWordInfo->nextWordPoint + k) = NULL; 29 *(lastWordInfo->nextWordFrequency + k) = 0; 30 } 31 (lastWordInfo->presentNextWordNum) *= 2; 32 } 33 if (!stored) 34 { 35 *(lastWordInfo->nextWordPoint + i) = presentWordInfo->wordStr; 36 (*(lastWordInfo->nextWordFrequency + i))++; 37 stored = 1; 38 } 39 }
(6)ELF哈希函数
1 unsigned long ELFHash(char* tempWordArray, int lastAlphaPosition) 2 { 3 unsigned long hash = 0, i = 0, x = 0; 4 char *hashStr; 5 hashStr = (char*)malloc(sizeof(char)*(lastAlphaPosition + 1)); 6 if (hashStr == NULL) exit(-1); 7 for (i = 0; i <= (unsigned long)lastAlphaPosition; i++) 8 { 9 if (tempWordArray[i] >= 'a'&&tempWordArray[i] <= 'z'|| tempWordArray[i]>='0'&&tempWordArray[i]<='9') 10 *(hashStr + i) = tempWordArray[i]; 11 else 12 *(hashStr + i) = tempWordArray[i] - 'A' + 'a'; 13 } 14 for (i = 0; i <= (unsigned long)lastAlphaPosition; i++) 15 { 16 hash = (hash << 4) + *(hashStr + i); 17 if ((x = hash & 0xf0000000) != 0) 18 { 19 hash ^= (x >> 24); 20 hash &= ~x; 21 } 22 } 23 hash &= 0x7fffffff; 24 free(hashStr); 25 return hash; 26 }
(7)频率前十单词词组统计
1 void topFrequencyWordStatistics(struct alphaArray* dictionary, struct wordStatisticsResult* topFrequencyWord) 2 { 3 int i = 0, j = 0; 4 int minWordFrequency = 0; 5 for (i = 0; i < topFrequencyWordNum; i++) 6 { 7 (topFrequencyWord + i)->wordStr = NULL; 8 (topFrequencyWord + i)->wordFrequency = 0; 9 } 10 for (i = 0; i < alphabet; i++) 11 { 12 for (j = 0; j < (dictionary + i)->presentWordArrayLength; j++) 13 { 14 if (((dictionary + i)->wordArray + j)->frequency > minWordFrequency) 15 updateTopFrequencyWord(topFrequencyWord, ((dictionary + i)->wordArray + j), minWordFrequency); 16 } 17 } 18 sortTopFrequencyWord(topFrequencyWord); 19 puts("Top 10 word:"); 20 for (i = 0; i < topFrequencyWordNum; i++) 21 printf("%s\t%d\n", (topFrequencyWord + i)->wordStr, (topFrequencyWord + i)->wordFrequency); 22 printf("\n"); 23 } 24 25 void updateTopFrequencyWord(struct wordStatisticsResult* topFrequencyWord, struct wordInfo* dictionary_i_j, int &minWordFrequency) 26 { 27 int i = 0; 28 for (i = 0; i < topFrequencyWordNum; i++) 29 { 30 if ((topFrequencyWord + i)->wordFrequency == minWordFrequency) 31 { 32 (topFrequencyWord + i)->wordStr = dictionary_i_j->wordStr; 33 (topFrequencyWord + i)->wordFrequency = dictionary_i_j->frequency; 34 minWordFrequency = dictionary_i_j->frequency; 35 } 36 } 37 for (i = 0; i < topFrequencyWordNum; i++) 38 { 39 if ((topFrequencyWord + i)->wordFrequency < minWordFrequency) 40 minWordFrequency = (topFrequencyWord + i)->wordFrequency; 41 } 42 } 43 44 void sortTopFrequencyWord(struct wordStatisticsResult* topFrequencyWord) 45 { 46 int i = 0, j = 0; 47 int minWordFrequency; 48 int minWordFrequencyPosition; 49 struct wordStatisticsResult tempWord; 50 for (i = 0; i < topFrequencyWordNum - 1; i++) 51 { 52 minWordFrequency = topFrequencyWord->wordFrequency; 53 minWordFrequencyPosition = 0; 54 for (j = 0; j < topFrequencyWordNum - i; j++) 55 { 56 if ((topFrequencyWord + j)->wordFrequency < minWordFrequency) 57 { 58 minWordFrequency = (topFrequencyWord + j)->wordFrequency; 59 minWordFrequencyPosition = j; 60 } 61 } 62 tempWord.wordStr = (topFrequencyWord + minWordFrequencyPosition)->wordStr; 63 tempWord.wordFrequency = minWordFrequency; 64 (topFrequencyWord + minWordFrequencyPosition)->wordStr = (topFrequencyWord + topFrequencyWordNum - i - 1)->wordStr; 65 (topFrequencyWord + minWordFrequencyPosition)->wordFrequency = (topFrequencyWord + topFrequencyWordNum - i - 1)->wordFrequency; 66 (topFrequencyWord + topFrequencyWordNum - i - 1)->wordStr = tempWord.wordStr; 67 (topFrequencyWord + topFrequencyWordNum - i - 1)->wordFrequency = tempWord.wordFrequency; 68 } 69 } 70 71 void topFrequencyPhaseStatistics(struct alphaArray* dictionary, struct phaseStatisticsResult* topFrequencyPhase) 72 { 73 int i = 0, j = 0, k = 0; 74 int minPhaseFrequency = 0; 75 for (i = 0; i < topFrequencyPhaseNum; i++) 76 { 77 (topFrequencyPhase + i)->firstStr = NULL; 78 (topFrequencyPhase + i)->secondStr = NULL; 79 (topFrequencyPhase + i)->phaseFrequency = 0; 80 } 81 for (i = 0; i < alphabet; i++) 82 { 83 for (j = 0; j < (dictionary + i)->presentWordArrayLength; j++) 84 { 85 for (k = 0; k < ((dictionary + i)->wordArray + j)->presentNextWordNum; k++) 86 { 87 if (*(((dictionary + i)->wordArray + j)->nextWordFrequency + k) > minPhaseFrequency) 88 updateTopFrequencyPhase(topFrequencyPhase, ((dictionary + i)->wordArray + j), k, minPhaseFrequency); 89 } 90 } 91 } 92 sortTopFrequencyPhase(topFrequencyPhase); 93 puts("Top 10 phase:"); 94 for (i = 0; i < topFrequencyPhaseNum; i++) 95 printf("%s %s\t%d\n", (topFrequencyPhase + i)->firstStr, (topFrequencyPhase + i) ->secondStr, (topFrequencyPhase + i)->phaseFrequency); 96 printf("\n"); 97 } 98 99 void updateTopFrequencyPhase(struct phaseStatisticsResult* topFrequencyPhase,wordInfo* dictionary_i_j,int offset,int &minPhaseFrequency) 100 { 101 int i = 0; 102 for (i = 0; i < topFrequencyPhaseNum; i++) 103 { 104 if ((topFrequencyPhase + i)->phaseFrequency == minPhaseFrequency) 105 { 106 (topFrequencyPhase + i)->firstStr = dictionary_i_j->wordStr; 107 (topFrequencyPhase + i)->secondStr = *(dictionary_i_j->nextWordPoint + offset); 108 (topFrequencyPhase + i)->phaseFrequency = *(dictionary_i_j->nextWordFrequency + offset); 109 minPhaseFrequency = (topFrequencyPhase + i)->phaseFrequency; 110 } 111 } 112 for (i = 0; i < topFrequencyPhaseNum; i++) 113 { 114 if ((topFrequencyPhase + i)->phaseFrequency < minPhaseFrequency) 115 minPhaseFrequency = (topFrequencyPhase + i)->phaseFrequency; 116 } 117 } 118 119 void sortTopFrequencyPhase(struct phaseStatisticsResult* topFrequencyPhase) 120 { 121 int i = 0, j = 0; 122 int minPhaseFrequency; 123 int minPhaseFrequencyPosition; 124 struct phaseStatisticsResult tempPhase; 125 for (i = 0; i < topFrequencyPhaseNum - 1; i++) 126 { 127 minPhaseFrequency = topFrequencyPhase->phaseFrequency; 128 minPhaseFrequencyPosition = 0; 129 for (j = 0; j < topFrequencyPhaseNum - i; j++) 130 { 131 if ((topFrequencyPhase + j)->phaseFrequency < minPhaseFrequency) 132 { 133 minPhaseFrequency = (topFrequencyPhase + j)->phaseFrequency; 134 minPhaseFrequencyPosition = j; 135 } 136 } 137 tempPhase.firstStr = (topFrequencyPhase + minPhaseFrequencyPosition)->firstStr; 138 tempPhase.secondStr = (topFrequencyPhase + minPhaseFrequencyPosition)->secondStr; 139 tempPhase.phaseFrequency = minPhaseFrequency; 140 (topFrequencyPhase + minPhaseFrequencyPosition)->firstStr = (topFrequencyPhase + topFrequencyPhaseNum - i - 1)->firstStr; 141 (topFrequencyPhase + minPhaseFrequencyPosition)->secondStr = (topFrequencyPhase + topFrequencyPhaseNum - i - 1)->secondStr; 142 (topFrequencyPhase + minPhaseFrequencyPosition)->phaseFrequency = (topFrequencyPhase + topFrequencyPhaseNum - i - 1)->phaseFrequency; 143 (topFrequencyPhase + topFrequencyPhaseNum - i - 1)->firstStr = tempPhase.firstStr; 144 (topFrequencyPhase + topFrequencyPhaseNum - i - 1)->secondStr = tempPhase.secondStr; 145 (topFrequencyPhase + topFrequencyPhaseNum - i - 1)->phaseFrequency = tempPhase.phaseFrequency; 146 } 147 }
(8)输出
1 void outputResult(struct alphaArray* dictionary) 2 { 3 int i = 0, j = 0, k = 0; 4 puts("Statistics result:"); 5 printf("characterNum:%lu\n", characterNum); 6 printf("wordNum:%lu\n", wordNum); 7 printf("lineNum:%lu\n\n", lineNum); 8 } 9 10 void outputToFile(struct wordStatisticsResult* topFrequencyWord,struct phaseStatisticsResult* topFrequencyPhase) 11 { 12 int i = 0; 13 FILE* fp; 14 fopen_s(&fp,"D:\\RGhw\\result.txt","wb"); 15 if (fp == NULL) exit(-1); 16 fputs("characterNum:", fp); 17 fprintf(fp, "%lu\r\n", characterNum); 18 fputs("wordNum:", fp); 19 fprintf(fp, "%lu\r\n", wordNum); 20 fputs("lineNum:", fp); 21 fprintf(fp, "%lu\r\n\r\n", lineNum); 22 fputs("Top 10 frequency words:\r\n", fp); 23 for (i = 0; i < topFrequencyWordNum; i++) 24 fprintf(fp,"%s: %d\r\n", (topFrequencyWord + i)->wordStr, (topFrequencyWord + i)->wordFrequency); 25 fputs("\r\n",fp); 26 fputs("Top 10 frequency phases:\r\n", fp); 27 for (i = 0; i < topFrequencyPhaseNum; i++) 28 fprintf(fp,"%s %s: %d\r\n", (topFrequencyPhase + i)->firstStr, (topFrequencyPhase + i)->secondStr, (topFrequencyPhase + i)->phaseFrequency); 29 fputs("\r\n", fp); 30 fclose(fp); 31 }
(9)释放空间
1 void dictionaryDestroy(struct alphaArray* dictionary) 2 { 3 int i, j; 4 for (i = 0; i < alphabet; i++) 5 { 6 for (j = 0; j < ((dictionary + i)->presentWordArrayLength); j++) 7 { 8 free(((dictionary + i)->wordArray + j)->wordStr); 9 free(((dictionary + i)->wordArray + j)->nextWordPoint); 10 free(((dictionary + i)->wordArray + j)->nextWordFrequency); 11 } 12 free((dictionary + i)->wordArray); 13 } 14 }
5.代码性能分析
(1)CPU和GPA使用情况
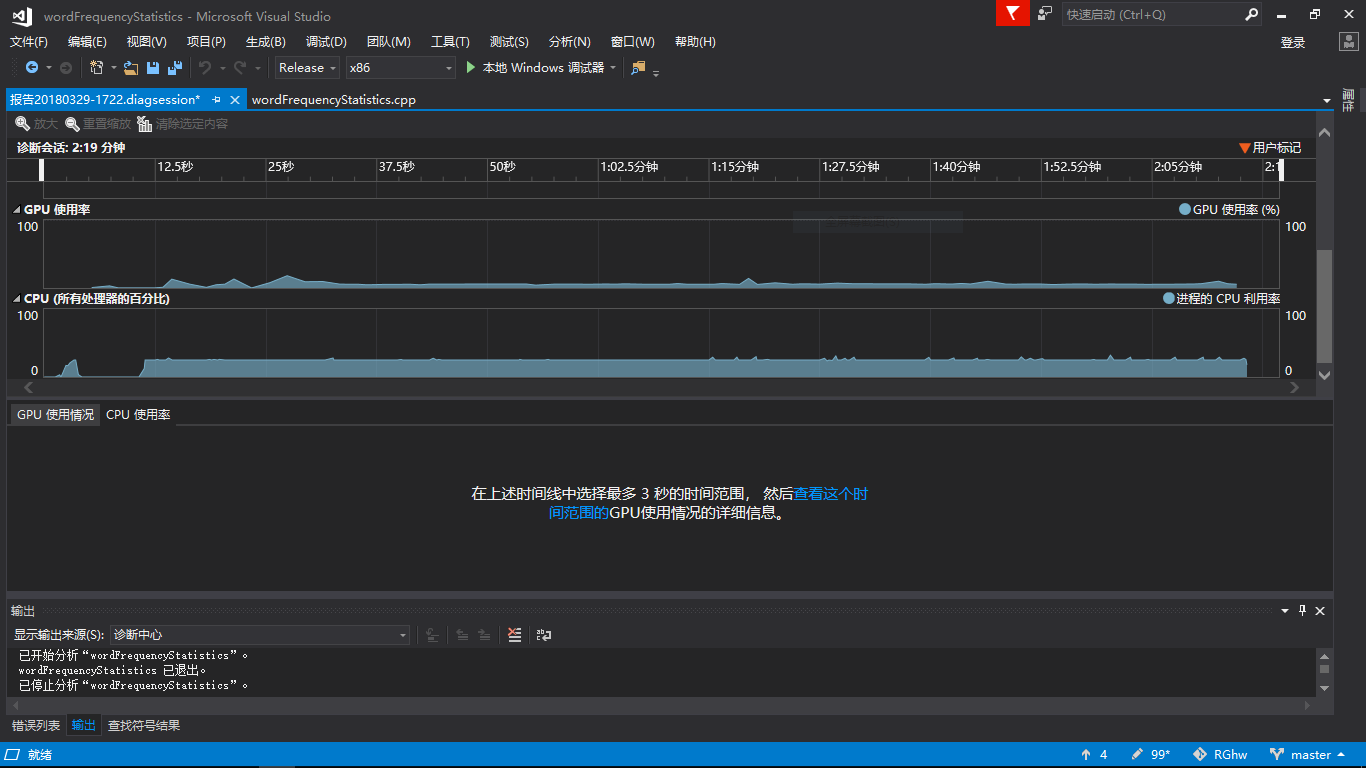
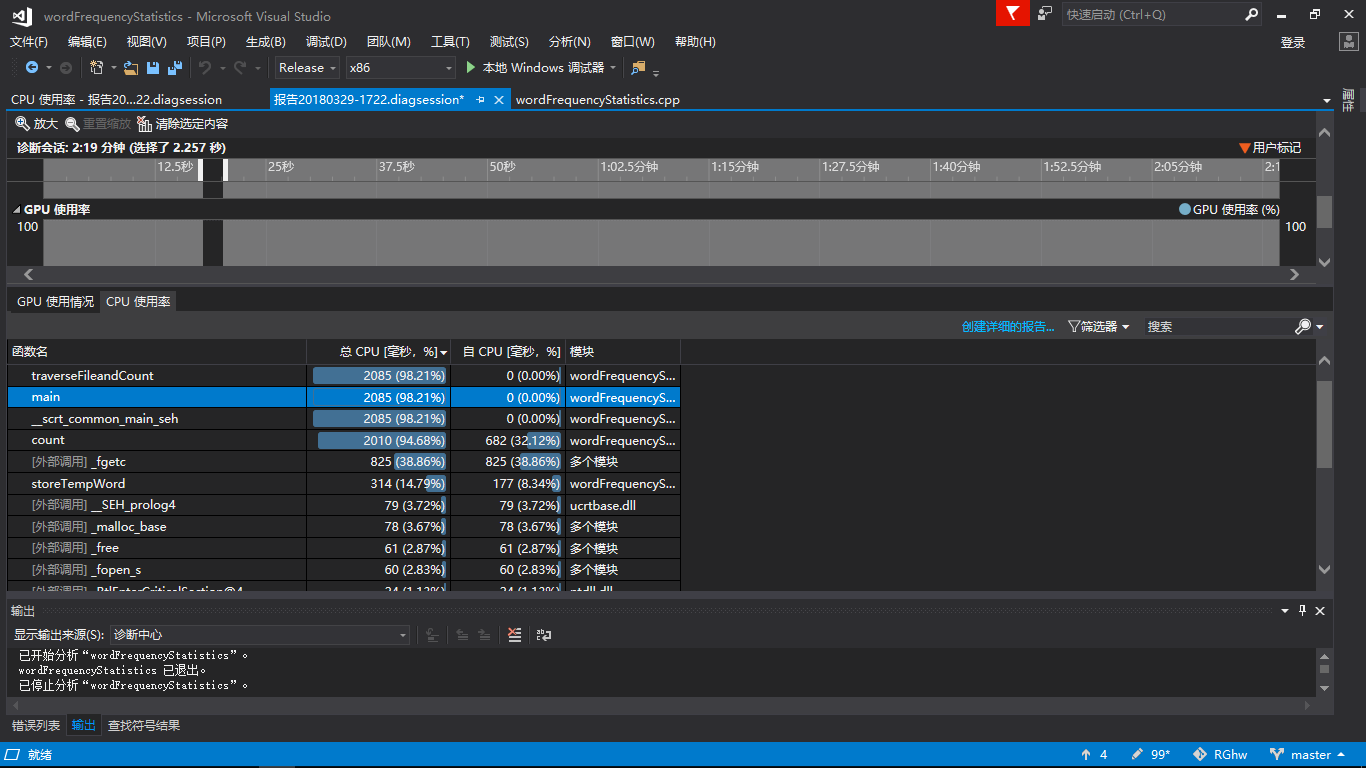
(2)各函数CPU占用细节
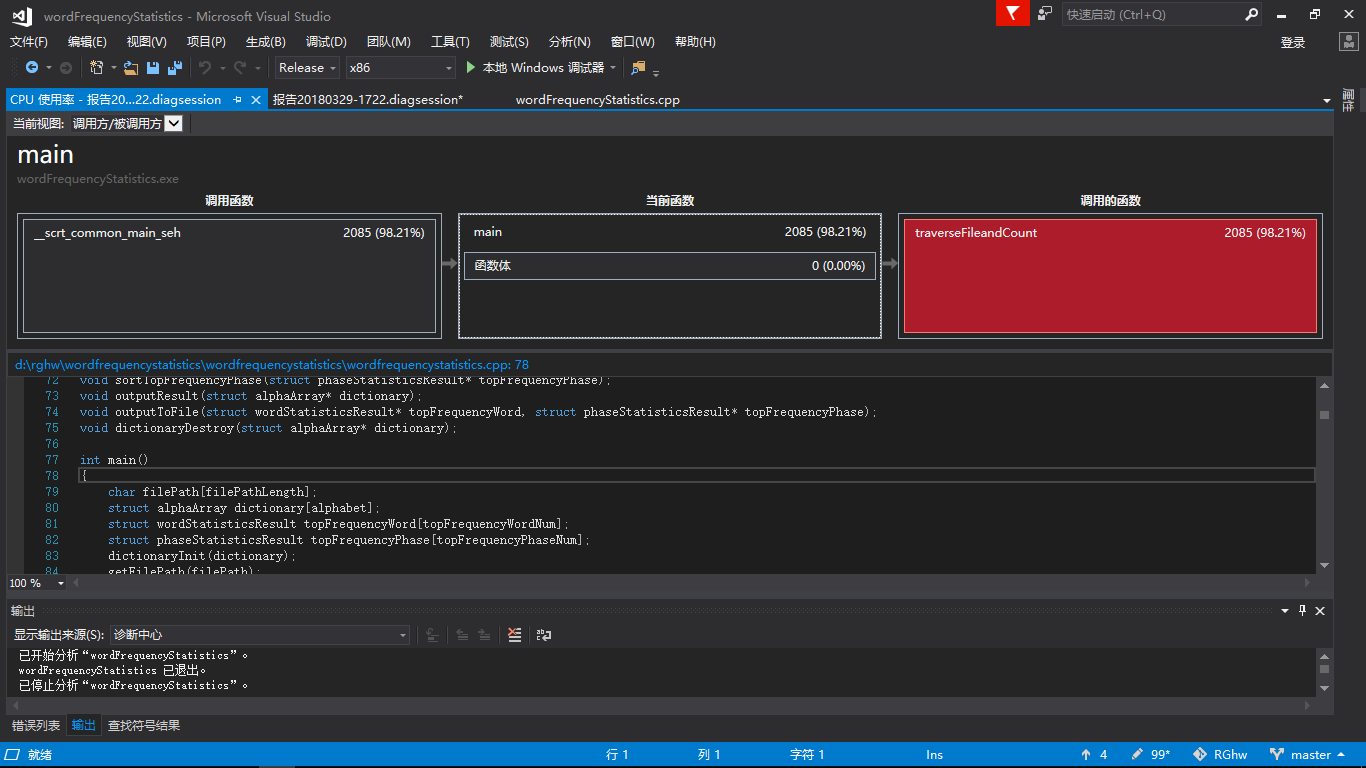
(3)main函数CPU占用细节
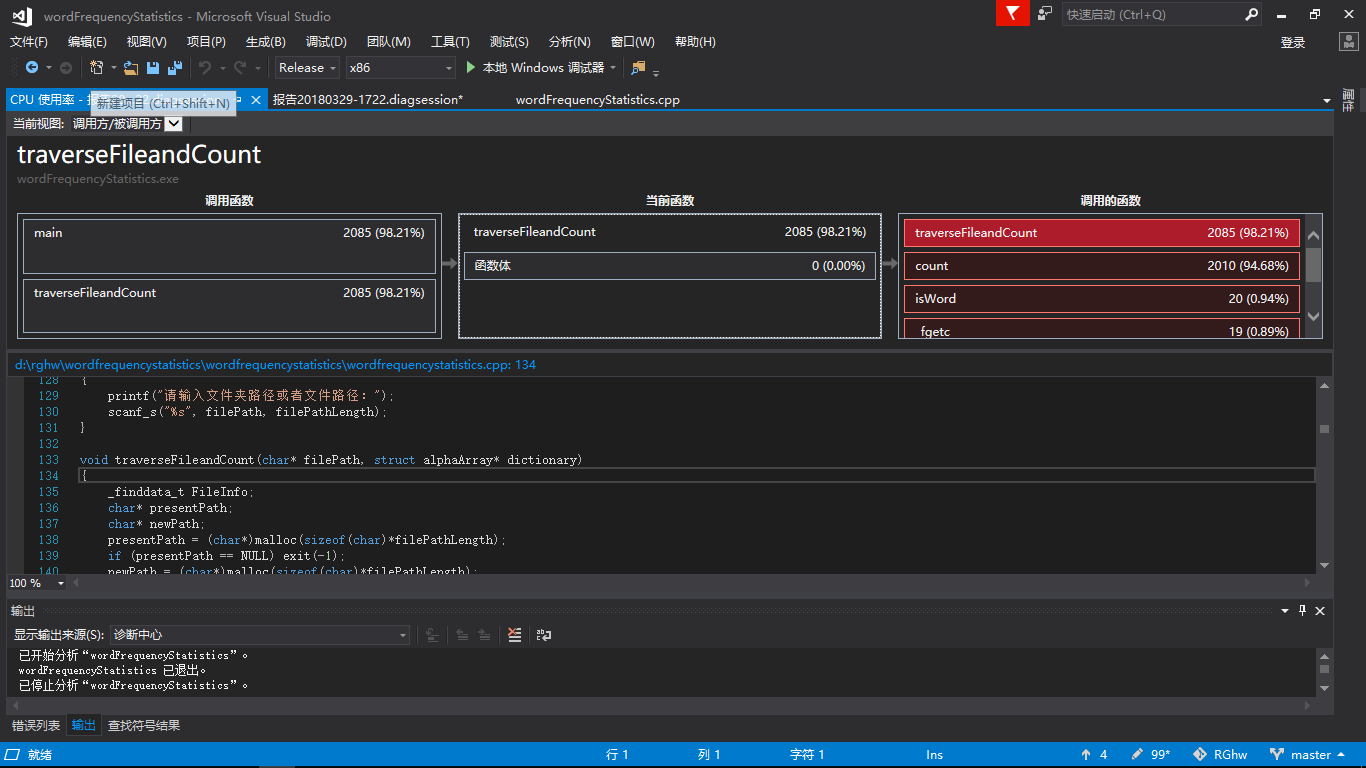
(4)遍历文件并进行统计函数(traverseFileandCount)CPU占用细节
(5)统计函数(count)CPU占用细节
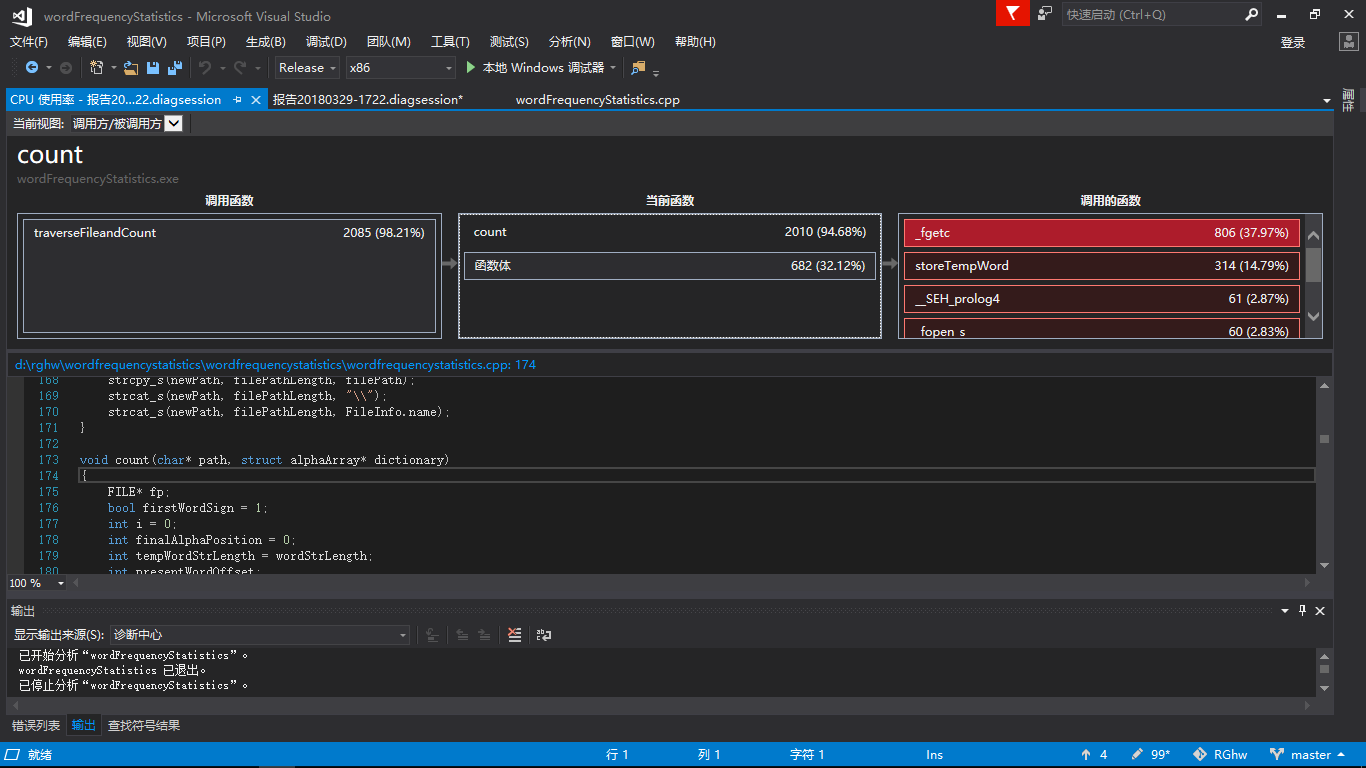
分析:
- 从性能分析来看,程序运行几乎所有的时间花费在统计函数上。
- 统计函数内部耗费时间最多的是fgetc()函数,说明每次对文件读取一个字节效率很低。之后有考虑过使用fread()函数(一次性将文件内容读入数组)来提高效率,不过由于时间关系并没有优化。
- 除了fgetc()之外,存储单词的函数也花费了较多的时间,原因可能是采用了动态内存,每次都要判断空间是否够用,并在不够用的情况下申请更大的空间。考虑到程序的健壮性,这一部分时间我觉得是必不可少的。
6.测试样例与分析
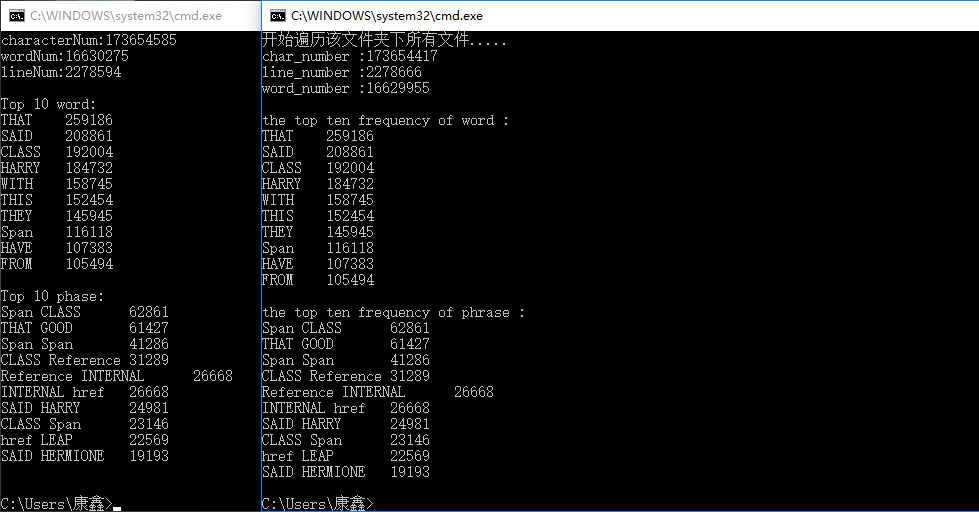
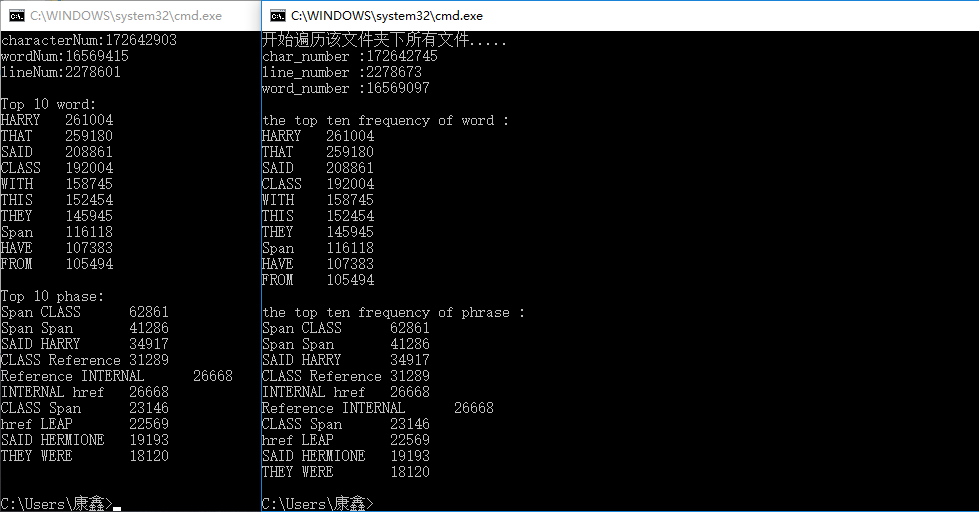
(1)助教提供的测试集
运行时间32秒(release模式下),运行结果如下(左侧为我的程序结果,右侧是助教的,后面都是这样,注:行数和单词数输出顺序和助教不一样):
前三项误差均在100左右,这可能和统计方法有关
单词和词组统计结果和助教一样
(2)空文件夹
(3)空文件
(4)只含一个词的文件
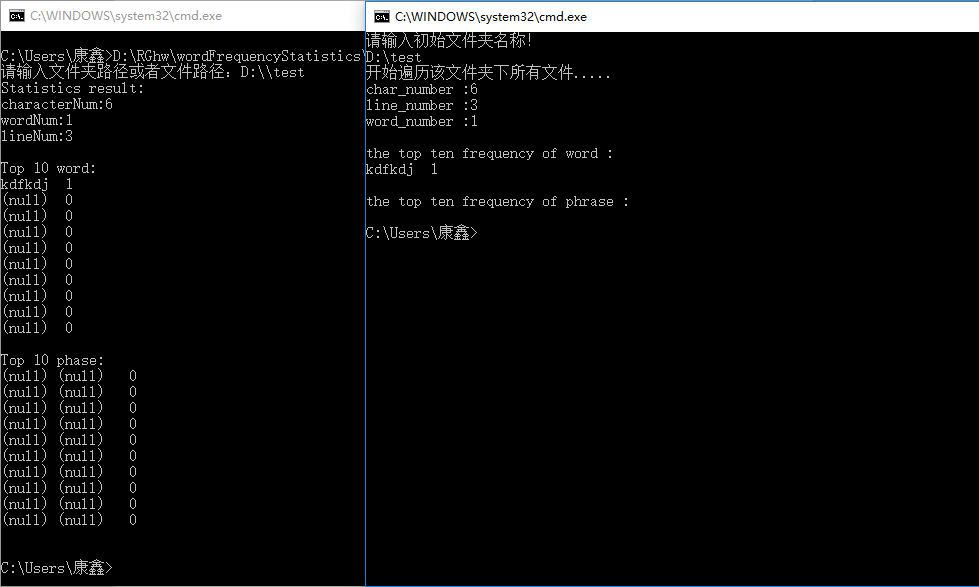
(5)同一类单词按照词典顺序输出
文件内容:

运行结果:
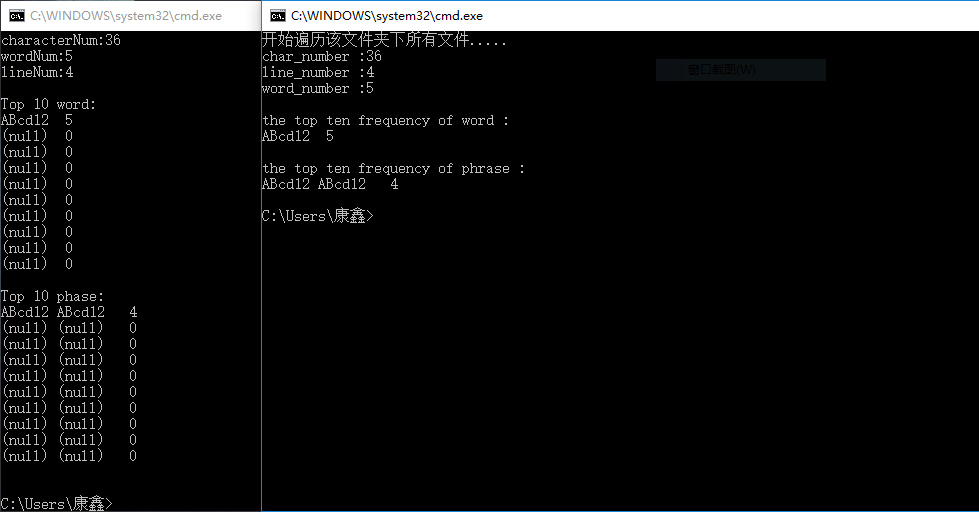
(6)词组按词典顺序输出
文件内容:
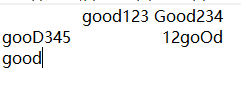
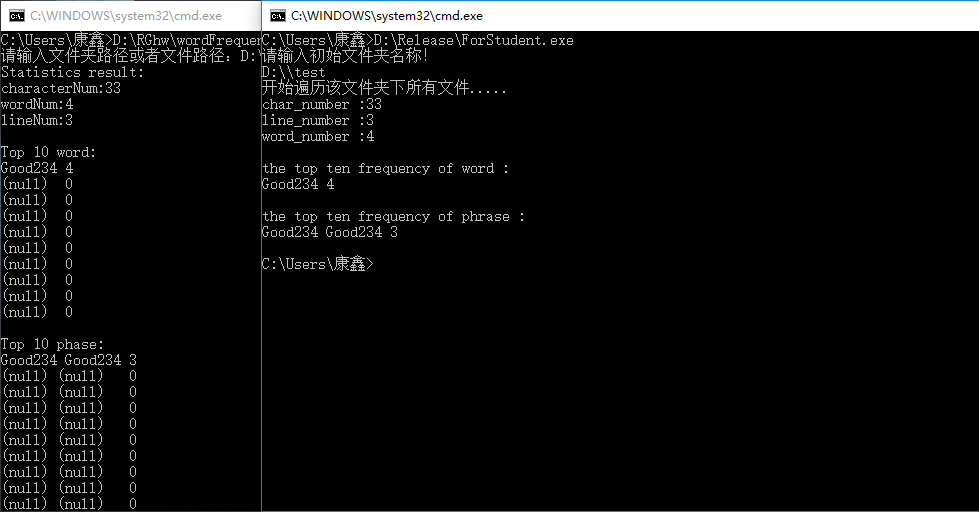
运行结果:
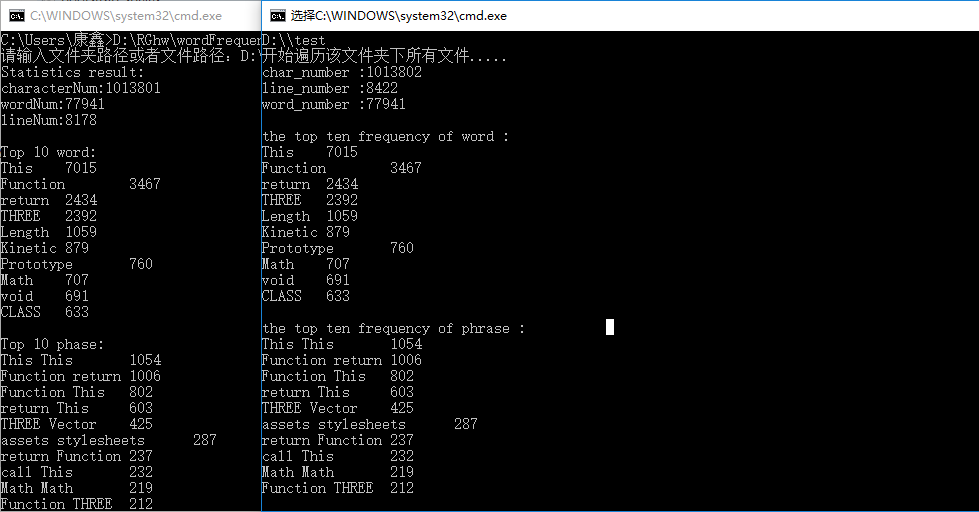
(7)不同类型的文件
文件夹:
运行结果:
(8)错误的路径
我的程序直接退出(exit(-1)),没有输出错误信息。
(9)第一版测试集
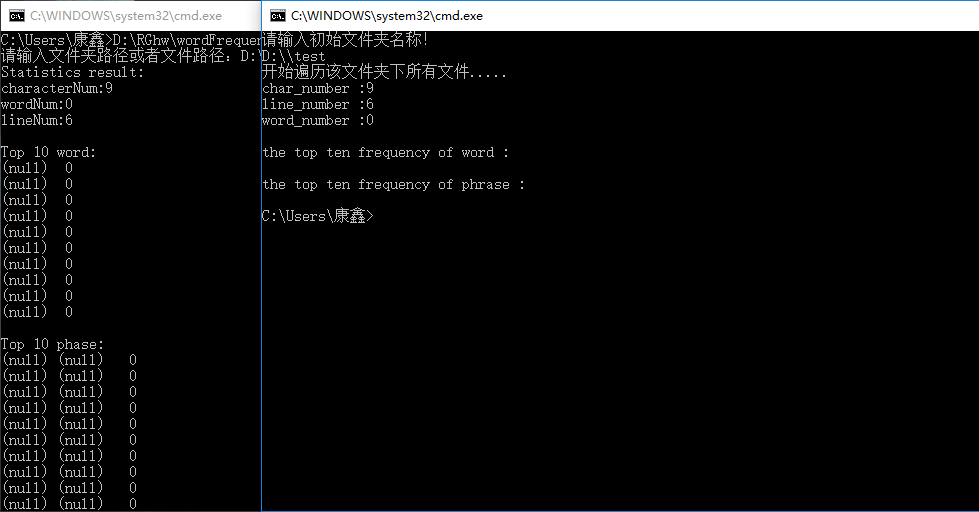
(10)图片文件
7.程序存在的问题
程序第一次成功运行后,我对测试集进行了统计,发现THAT这个单词输出了两个。也就是说同一个单词存放在两个不同的位置。一开始感觉很奇怪,百思不得其解。后来发现,问题出在动态内存上。为了保证程序的健壮性,我使用了动态内存。当词表存放不下单词的时候,程序会申请两倍的空间。但是我忽略了当词表容量发生变化的时候,根据哈希值确定的单词的存储位置也会发生变化。这造成了同样的单词,存放在了不同的地方。我想出的解决方案是,依次在一倍初始空间,两倍初始空间……进行查找,这样的话可以保证每一个单词只有一个确定的位置。不过发现这个问题的时候已经离DDL没多久了,所以我只是简单的扩大了初始空间去解决这个问题。
8.总结反思
总体过程上,由于最开始进行了大致规划,整个过程比较顺利。出现了两次卡壳:动态内存代码、虚拟机的使用。词表采用了动态内存,需要判断内存是否够用,不够用时要重新申请。写这部分代码的时候由于思路不够清楚,花费了较多时间。程序运行成功后就开始进行移植性的修改。为了进行测试,安装了ubuntu虚拟机。成功测试之后突然虚拟机挂掉了,重新安装了三次,仍然失败(心好累)。。所以最后输出文件的函数没办法验证。
代码规范上,相比以前稍有进步。这次代码编写时,我着重注意了变量命名和函数命名,以增强代码可读性。另外,我尽可能的将长函数拆分成若干个小函数,尽管这样仍然有四五十行的代码。
时间安排上,我只能说,我是先写软工作业然后写其他课程作业。
不足之处,虚拟机使用不熟练,出现问题不能尽快解决;代码性能分析不够详细;代码繁琐难读。
以后编程过程中会不断锻炼、改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号