
Jmeter常用元件使用介绍
JMeter常用元件使用介绍
摘要:本篇文章主要讲解jmeter性能测试工具常用的元件使用介绍,方便大家在使用过程中遇到问题及时查阅参考。

一、测试计划(Test Plan)
作用:用来描述一个性能/接口测试脚本和场景设计,包含与本次测试所有相关的功能。也就是说,使用jmeter进行测试的所有内容都是于基于一个测试计划的。
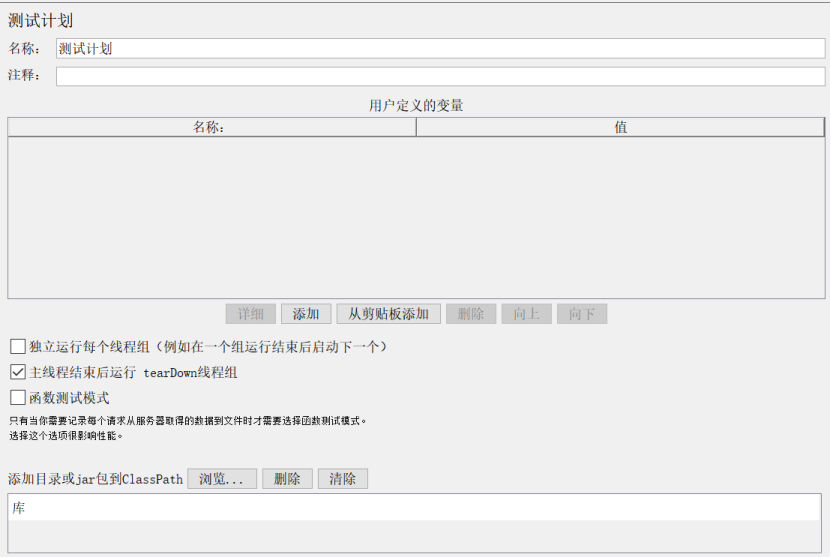
测试计划名称和注释:整个测试脚本保存的名称,和对该测试计划的注释,可以自定义,最好能表达脚本的意义。
用户定义的变量:在测试计划上可以添加用户定义的变量,相当于是全局变量。一般添加一些系统常用的配置。如果测试过程中想切换环境,切换配置,一般不建议在测试计划上添加变量,因为不方便启用和禁用,一般是在配置元件中添加用户自定义变量组件。
独立运行每个线程组:勾选后中,多个线程组时,等待前一个线程组执行完成后才开始下一个线程组;不勾选时,默认各线程组并行、随机执行
主线程结束后运行tearDown线程组:在主线程因错误结束执行时,如果勾选此选项,会执行tearDown线程组;如果不勾选,就不会执行tearDown线程组
函数测试模式(Functional Testing): 只有当你需要记录每个请求从服务器取得的数据到文件时才需要选择函数测试模式,选择这个选项很影响性能,在调试脚本的时候,可以开启,但是在压测数量时建议关闭。
添加目录或jar包到ClassPath:需要调用的外部jar包可以在这里进行添加设置。如添加json.jar。
备注:线程组中的取样器的执行顺序默认是从上到下执行,交替控制器、随机控制器、随机顺序控制器和循环控制器等可以改变取样器的执行顺序。
二、线程 用户Threads (Users)
作用:线程组元件是任何一个测试计划的开始点,在一个测试计划中的所有元件都必须在某个线程下,所有的任务都是基于线程组。
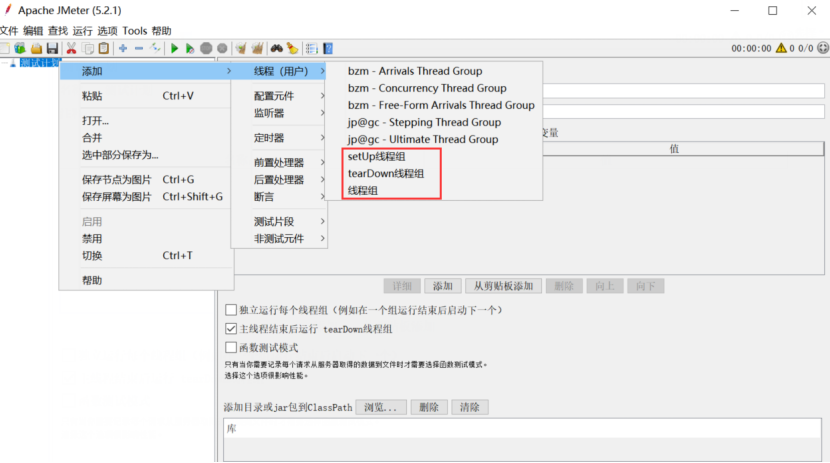
1、setup线程组
作用:它会在普通线程组执行之前被触发,类似于loadrunner的init。
2、teardown线程组
作用:它会在普通线程组执行之后被触发,类似于loadrunner的end
3、线程组(thread group)
作用:这个就是我们通常使用的线程,一个线程组可以看做一个虚拟用户组,线程组中的每个线程都可以理解为一个虚拟用户,多个用户同时去执行相同的一批次任务。每个线程之间都是隔离的,互不影响的。一个线程的执行过程中,操作的变量,不会影响其他线程的变量值。
备注:setup线程组和teardown只能迭代一次。
三、取样器(samplers)
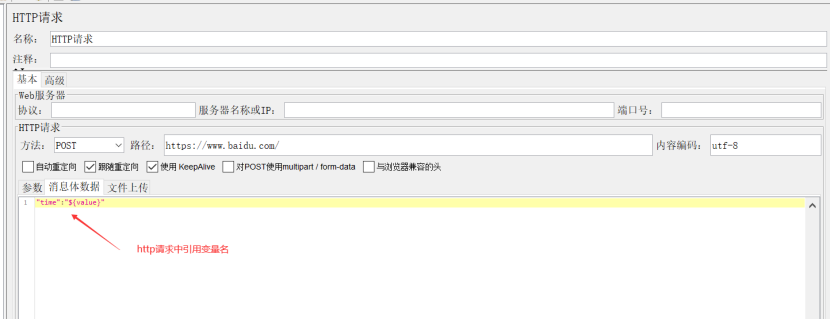
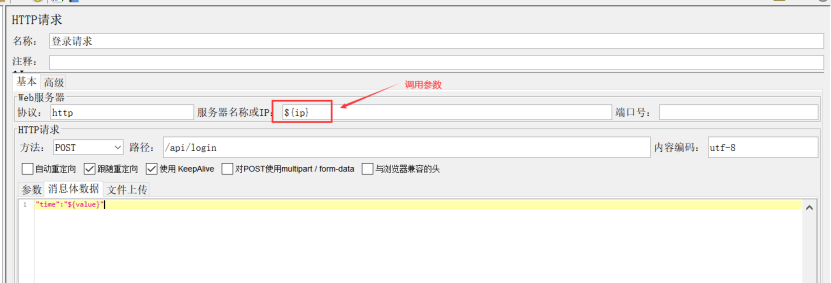
1、HTTP请求(HTTP Request)

协议:向目标服务器发送 http 请求时的协议,http/https,大小写不敏感,默认 http;
服务器名称或IP:http 请求发送的目标服务器名称或者 IP 地址;
端口号:目标服务器的端口号;
方法:发送 http 请求的方法(如,get、post等方法);
路径:目标的 URL 路径(不包括服务器地址和端口);
内容的编码:一般输入utf-8;
跟随重定向:默认选中;
自动重定向:如果选中该项,发出的 http 请求得到响应是 301/302,jmeter 会重定向到新的界面;
使用 keep Alive:jmeter 和目标服务器之间使用 Keep-Alive 方式进行 HTTP 通信(默认选中);
示例:


2、Webservice请求
备注:Jmeter3.2版本之后就没有SOAP/XML-RPC Request插件了,之后的版本不能直接进行webservice接口的测试,可以借助jmeter中的http请求来测试webservice,需要添加配置元件“HTTP信息头管理器”并在HTTP信息头管理器中添加两个参数Content-Type(必填)和SOAPAction(不是必须填的信息)来实现,其他的操作与HTTP协议接口测试流程一样。

3、调试取样器(Debug Sampler)
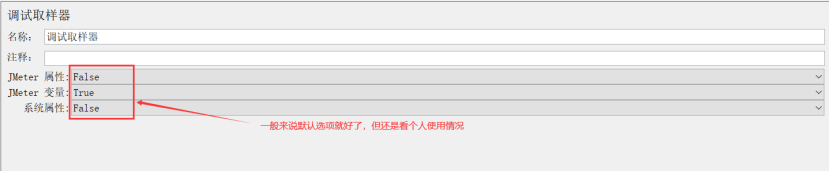
jmeter属性(JMeter properties):读取的是jmeter配置文件中的相关值,一般不开启
jmeter变量(JMeter variables):一般指我们自定义的,需要在接口之间传递的变量,一般开启
系统属性(System properties):一般不开启
作用:在调式脚本的时候用的,添加调试取样器后在察看结果树中能看到我们在脚本中所有参数化变量所取的值,这样有利于我们排错。
应用场景:
(1)想知道参数化的变量取值是否正确;
(2)想知道正则表达式提取器(或json提取器)提取的值是否正确;
(3)想知道调试时服务器返回些什么内容;
(4)想知道JMeter 属性;
示例:

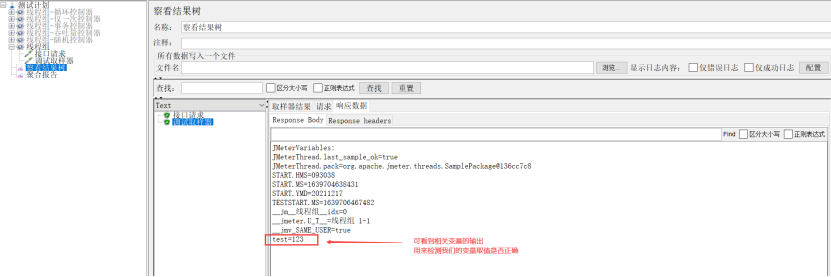
备注:一般将Debug Sampler取样器放在最后。
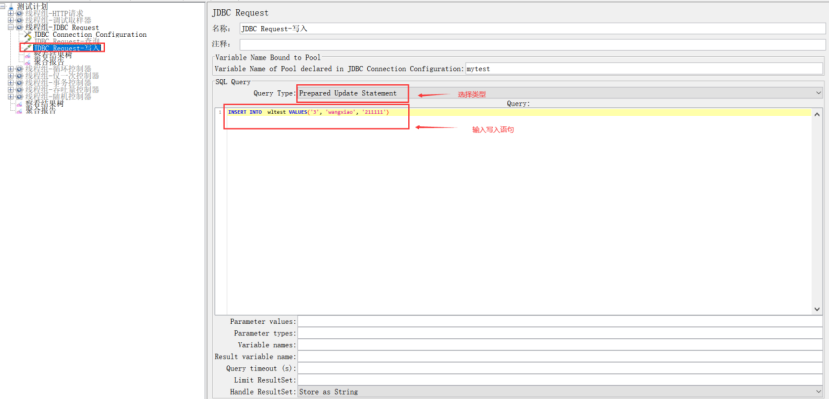
4、JDBC Request
前提环境要求:下载合适的JDBC驱动, JDBC驱动可以在mysql的官网下载
https://mvnrepository.com/artifact/mysql/mysql-connector-java
将下载好的驱动安装到jmeter安装目录的/lib/ext文件下(选择对应的mysql版本驱动下载),然后重启Jmeter。
作用:可以向数据库发送一个jdbc请求(sql语句),并获取返回的数据库数据进行操作,它经常需要和JDBC Connection Configuration配置原件(配置数据库连接的相关属性,如连接名、密码等)一起使用。
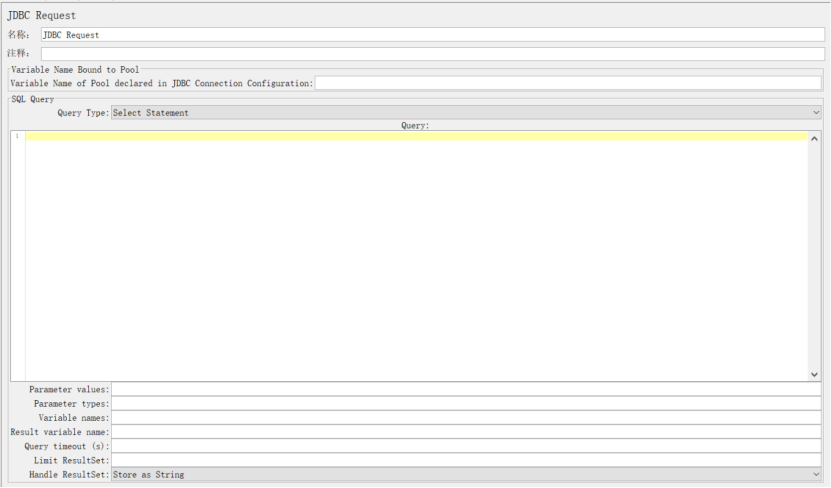
参数说明:
Variable Name:数据库连接池的名字,需要与JDBC Connection Configuration的Variable Name Bound Pool名字保持一致
Query:填写的sql语句未尾不要加“;”
Parameter valus:参数值
Parameter types:参数类型,可参考:Javadoc for java.sql.Types
Variable names:保存sql语句返回结果的变量名
Result variable name:创建一个对象变量,保存所有返回的结果
Query timeout:查询超时时间
Handle result set:定义如何处理由callable statements语句返回的结果

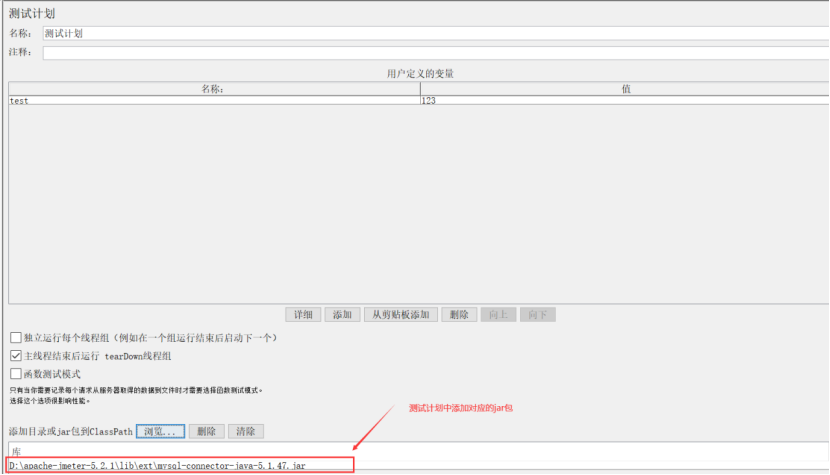
参数说明:
Variable Name for created pool:填写要测试的数据库名字
Database URL :jdbc:mysql://localhost:3306/mytest (localhost可以更改其他IP地址,mytest根据自己的数据库名称修改)
JDBC driver class:根据自己的数据库类型选择
username和password:填写数据库的账号和密码
示例:


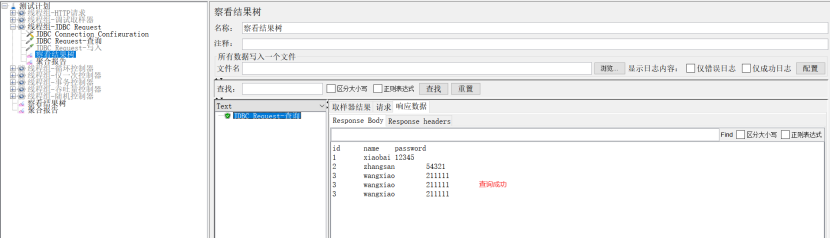

5、Java请求
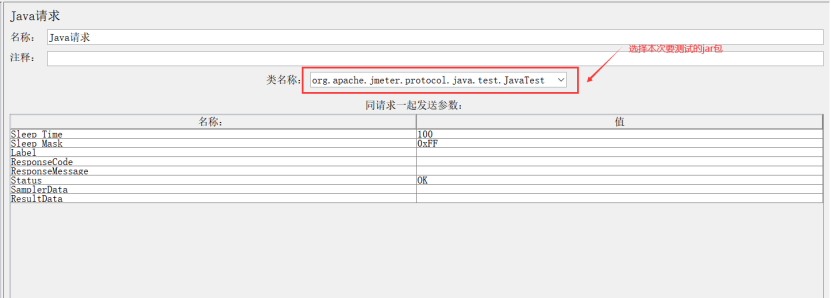
备注:
(1)将测试的jar包放到jmeter安装目录的/lib/ext文件下
(2)类名称:选择jar包(开发提供)
四、逻辑控制器(Logic Controller)
逻辑控制器可以控制取样器(samplers)的执行顺序。由此可知,控制器需要和取样器一起使用,否则控制器就没有什么意义了,放在控制器下面的所有的取样器都会当做一个整体,执行时也会一起被执行。
1、循环控制器(Loop Controller)

永远选项:勾选上这一项表示一直循环下去
循环次数:如果同时设置了线程组的循环次数和循环控制器的循环次数,那循环控制器的子节点运行的次数为两个数值相乘的结果
作用:指定其子节点运行的次数,可以使用具体的数值(如下图,设置为5次),也可以使用变量
示例:



2、仅一次控制器(Once Only Controller)

作用:在测试计划执行期间,该控制器下的子结点对每个线程只执行一次,登录场景经常会使用到这个控制器。
注意:将仅一次控制器作为循环控制器的子节点,仅一次控制器在每次循环的第一次迭代时均会被执行。
示例:


备注:仅一次接口只对线程组属性设置循环次数起作用,对线程数不起作用
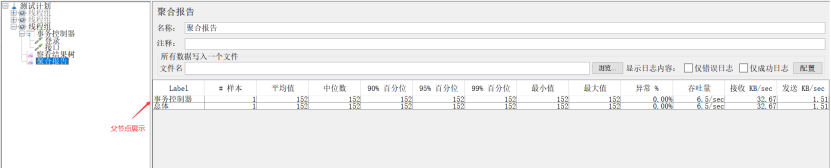
3、事务控制器(Transaction Controller)
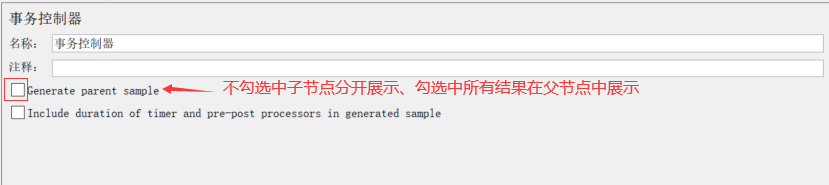
作用:事务控制器会生产一个额外的采样器,用来统计该控制器子结点的所有时间。
应用场景:完成一个完整的页面请求或一组请求
示例:
(1)Generate parent sample:未勾选,子节点分开展示

(2)Generate parent sample:勾选后,所有的结果将在父结点中展示
4、吞吐量控制器(Throughput Controller)
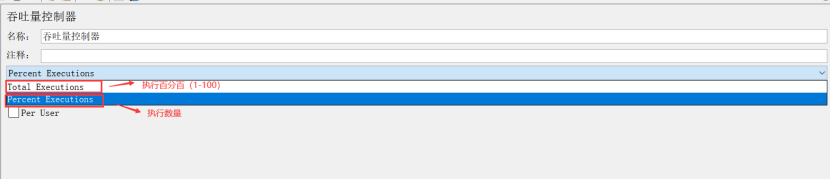
Total Executions:执行百分比(1-100)
percent Executions:执行数量
Per User:线程数,当选Total Executions时,是线程数;当选percent Executions时,是线程数*循环次数
作用:控制其下的子节点的执行次数与负载比例分配
应用场景:10个并发里,有2个是A业务,有8个是B业务,要模拟这种业务场景,则可以通过吞吐量控制器来模拟
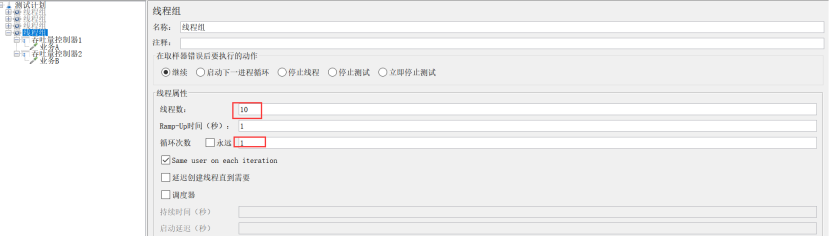
示例1:选择percent Executions(执行数量)
场景:A业务跑8个,B业务跑2个
设置:线程组的线程数设置10,循环次数设置为1;吞吐量控制器1设置为:选percent Executions,吞吐量80%;吞吐量控制器2设置为:选percent Executions,吞吐量20%



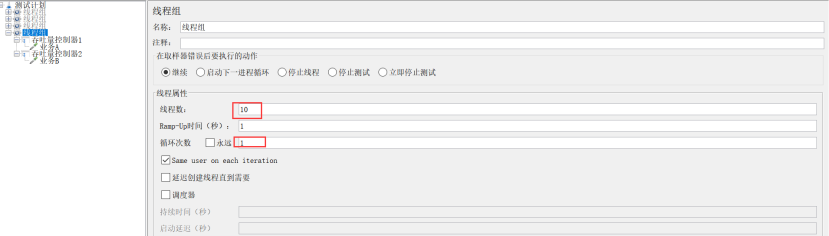
示例2:选择Total Executions(执行百分比)
场景:A业务跑8个,B业务跑2个
设置:线程组的线程数设置10,循环次数设置为1;吞吐量控制器1设置为:选Total Executions,吞吐量8;吞吐量控制器2设置为:选Total Executions,吞吐量2
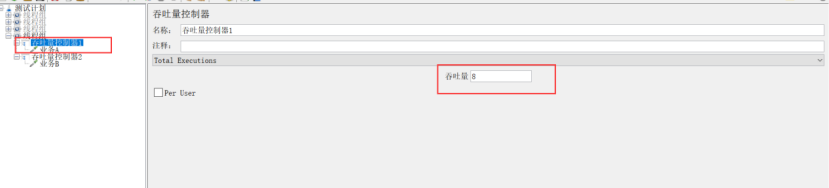

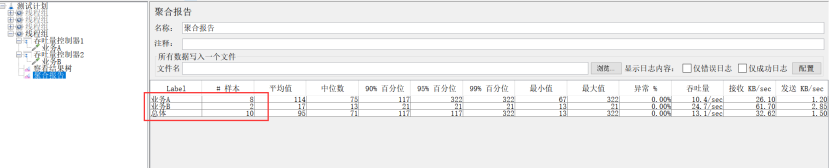
示例3:
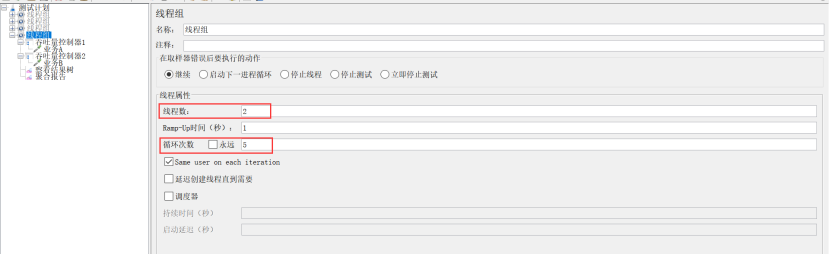
场景:A业务跑6个,B业务跑所有线程(线程数*循环次数)
设置:线程组的线程数设置2,循环次数设置为5;吞吐量控制器1设置为:选Total Executions,吞吐量60%;吞吐量控制器2设置为:选percent Executions,吞吐量不填,勾选Per User



示例4:
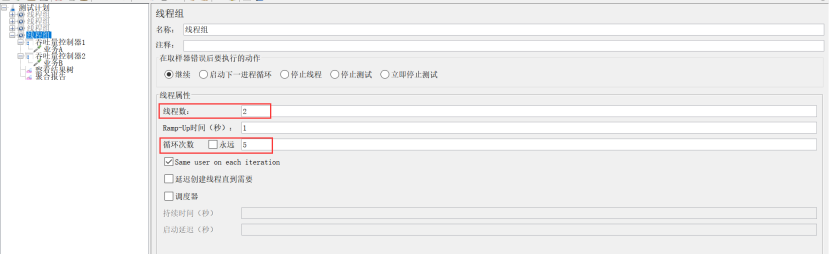
场景:A业务跑6个,B业务跑所有线程数(本次设置的线程数为2)
设置:线程组的线程数设置2,循环次数设置为5;吞吐量控制器1设置为:选percent Executions,吞吐量60%;吞吐量控制器2设置为:选Total Executions,吞吐量不填,勾选Per User



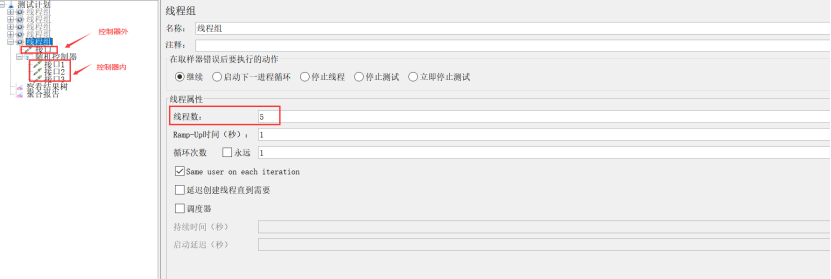
5、随机控制器(Random Controller)

作用:在此控制器下的请求会随机选择
示例:
设置线程数为5,随机控制器外1个请求,随机控制下添加3个请求
五、前置处理器(Pre Processors)
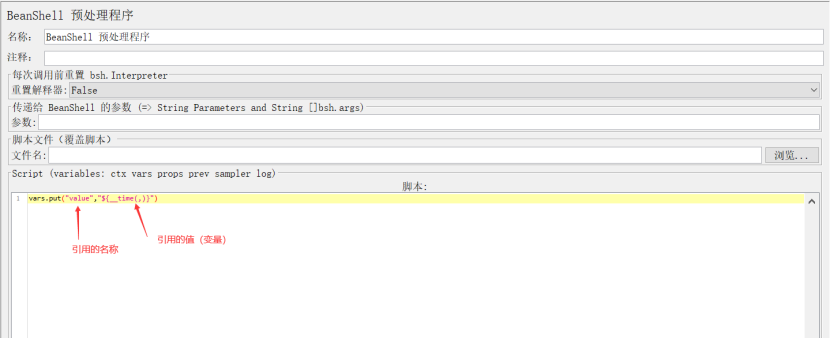
1、BeanShell 预处理程序(BeanShell PreProcessor)
右键http请求–》添加–》前置处理器–》BeanShell 预处理程序

作用:是在请求发送之前对请求参数做一些处理,BeanShell 是小型的嵌入式java的解释器,能够执行java语法,因为BeanShell是利用java写的
示例:
六、后置处理器器(Post Processors)
1、正则表达式提取器(Regular Expression Extractor)
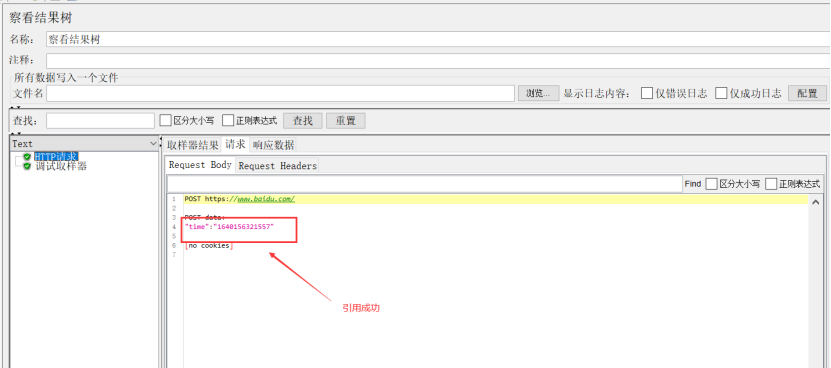
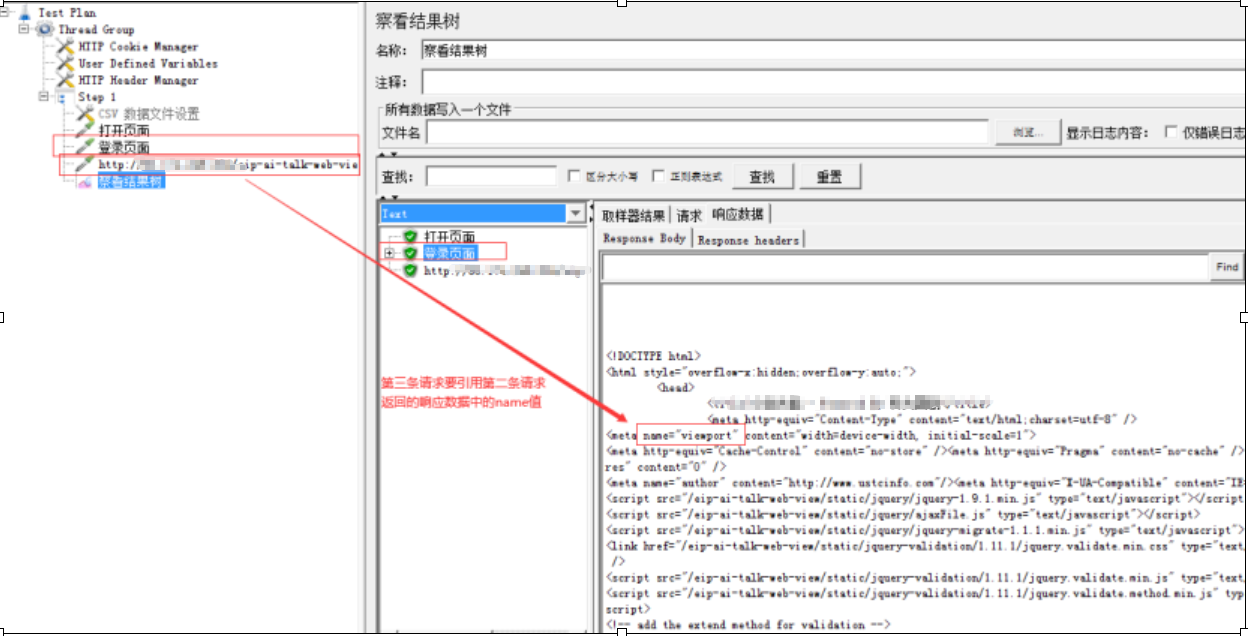
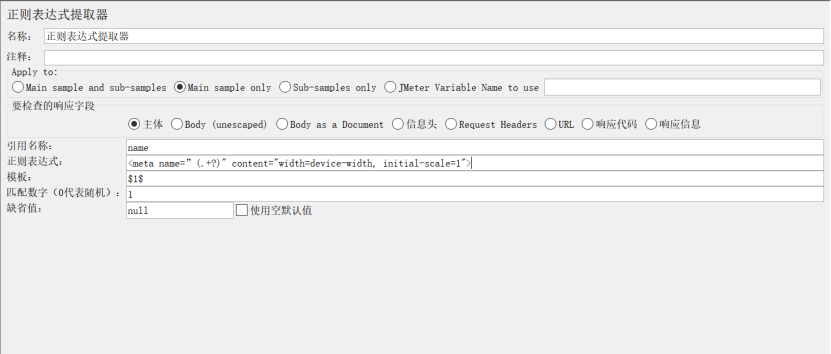
作用:运用Jmeter正则提取器,可以从请求的响应结果中取到需要的内容,从而实现关联
Apply to:要检查的相应字段,一般都默认,主要是针对响应数据中的值去处理,如有其它需要,可以参考jmeter说明
引用名称:自己定义的变量名称,后续请求将要引用到的变量名,如填写的是:actionId,后面的引用方式是${actionId}
正则表达式:提取内容的正则表达式,相当于lr中的关联函
模板:表示使用提取到的第几个值,$1$表示取第1个,以此类推
匹配数字:-1表示全部,0随机,1第一个;
缺省值:如果没有匹配到,给它定义的一个默认值,可以用error、null等表达或者使用空默认值
正则表达式中常用特殊含义字符:
() 括起来的部分就是要提取的
. 匹配任何字符串
* 表示任意个字符
+ 一次或多次
? 不要太贪婪,在找到第一个匹配项后停止
\ 转译字符
[] 表示范围,如:[0-9a-zA-Z\_]可以匹配一个数字、字符或者下划线
示例:

2、BeanShell 后置处理程序(BeanShell PostProcessor)
作用:请求发送完成之后对响应数据进行处理,在beanshell后置处理器中写代码获取接口返回的值,用vars.put输出,在下一个接口用${变量名}直接引用,且提取的响应内容放在bin目录下的log中
备注:边界值提取器、XPath提取器感兴趣的自己去研究下^_^
七、断言(Assertions)
1、响应断言(Response Assertion)

作用:对服务器的响应接口进行断言校验,来判断接口测试得到的接口返回值是否正确。
apply to:通常发出一个请求只触发一个请求,所以勾选“main sampie only”就可以;若发一个请求可以触发多个服务器请求,就有main sample 和sub-sample之分了
测试字段:
(1)响应文本:一般的http响应,都勾选“响应文本”
(2)响应代码:http响应代码,如101,200,302,404,501等。当我们要验证404,501等http响应代码时,需要勾选中因为当http 响应代码为400,500时,jmeter默认这个请求时失败的
(3)响应信息:响应代码对应得响应信息,例如“OK"
(4)URL样本:是对sample的url进行断言,如果请求没有重定向,就请求url,如果有重定向,就请求url和重定向url
模式匹配规则:
(1)包括:响应内容包括需要匹配的内容就算成功,支持正则匹配
(2)匹配:响应内容要完全匹配匹配内容,不区分大小写
(3)相等:完全相等,区分大小写
(3) 字符串:响应内容包括匹配内容即为成功,但是字符串不支持正则字符串
(4) 否:对断言结果进行否定,如果断言结果为true,勾选“否”后,最终断言结果为false;如果断言结果为false,勾选“否”后,则最终断言结果为 true
(5) 或:将多个测试模式以逻辑“或”组合起来
测试模式:输入结果期望值(空格要去掉)
自定义失败:输入失败时返回的消息
八、定时器(Timer)
1、同步定时器(Synchronizing Timer)
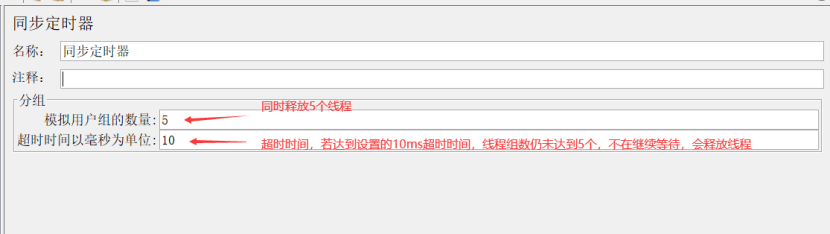
作用:用来设置集合点,阻塞线程,直到指定的线程数量到达后,再一起释放,可以瞬间产生很大的压力
模拟用户组的数量(Number of Simulated Users to Group by):即指定同时释放的线程数数量,若设置为0则等于线程组中的线程数量;
超时时间(Timeout in milliseconds):即超时多少毫秒后同时释放指定的线程数;如果设置为0,该定时器将会等待线程数达到了设置的线程数才释放,若没有达到设置的线程数会一直死等,如果大于0,那么如果超过Timeout inmilliseconds中设置的最大等待时间后还没达到设置的线程数,Timer将不再等待,释放已到达的线程,默认为0
备注:同步定时器(Synchronizing Timer)的超时时间设置要求:超时时间 > 请求集合数量 * 1000 / (线程数 / 线程加载时间)
2、固定定时器(Constant Timer)
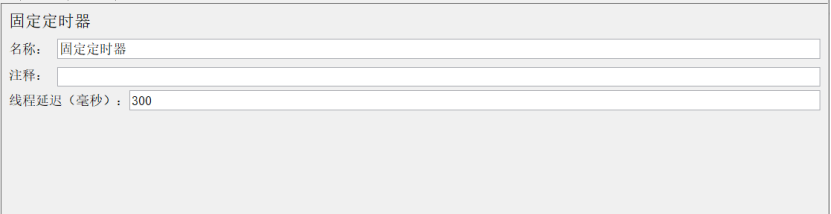
作用:通过线程延迟(Thread Delay)设定每个线程请求之前的等待时间(单位为毫秒)。
注意:固定定时器的延时不会计入当前sampler 的响应时间里,但是会计入事务控制器的时间,对于事务控制器来说,定时器相当于loadrunner中的think time(思考时间:实际操作中,模拟真实用户在操作过程中的等待时间)通常所说的响应时间,大部分情况下是针对某一个具体的sampler(http请求),而不是针对一组sampler组合的事务。
3、常数吞吐量定时器(Constant Throughput Timer)

作用:按指定的吞吐量执行,以每分钟为单位,计算吞吐量依据是最后一次线程的执行时延。
目标吞吐量(Target throughput):每分钟发送的请求数,因此,如果对应测试需求中所要求的20 QPS ,这里的值应该是1200 (20*60)
基于计算吞吐量:
(1)只有此线程(this thread only):设置每个线程的吞吐量,总的吞吐量=线程数*该值
(2)所有活动线程(all active threads):吞吐量被分配到所有线程组的所有活动线程的总吞吐量。每个线程将根据上次运行时间延迟。在这种情况下,每个线程组需要一个具有相同设置的固定吞吐量定时器。(不常用)
(3)当前线程组中的所有活动线程(all active threads in current thread group):吞吐量被分摊到当前线程组所有的活动线程上。每个线程将根据上次运行时间延迟。
(4)所有活动线程(共享):同上,但是每个线程是根据组中的线程的上一次运行时间来延迟。 相当于线程组组内排队。(不常用)
(5)当前线程组中的所有活动线程(共享):同上,但每个线程是根据线程的上次运行时间来延迟。相当于让所有线程组整体排队。(不常用)
4、准确的吞吐量定时器(Precise Throughput Timer)

作用:根据吞吐量在做计时器(到了多少量就发请求),可以做到控制请求的速度和个数
目标吞吐量(Target Throught):根据自己的需求目标设置
吞吐量周期(Throught Period):表示在多长时间内发送Target Throught指定的请求数(以秒为单位)
测试持续时间(Test Druation):指定测试运行时间(以秒为单位)
批处理中的线程之间的延迟(Number of threads in the bath):用来设置集合点,等到指定个数的请求后并发执行
其它参数默认即可。
九、配置元件(Config Element)
1、CSV 数据文件设置(CSV Data Set Config)
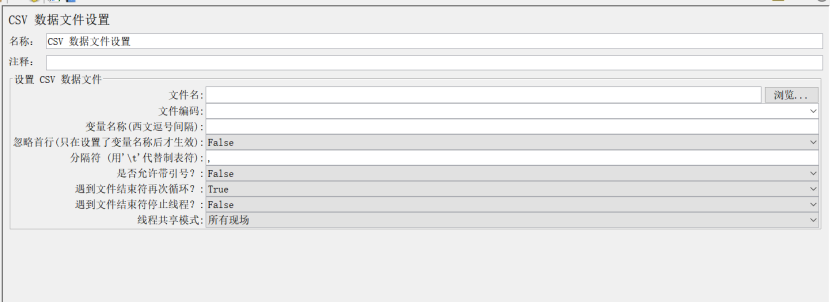
作用:通过从文件中导入大量的测试数据,来模拟大量真实用户发送并发请求,相当于数据参数化可以导入csv、txt格式的文件
文件名:参数化文件放的绝对路径
文件编码:utf-8
变量名称:被引用时的名称,如果csv文件中有多个变量,则用逗号隔开
忽略首行:一般首行都是字段名字,一般都需要忽略选择true除非没有字段名
是否允许带引号:默认(有特殊情况时修改)
遇到文件结束再次循环:默认(有特殊情况时修改)
遇到文件结束停止线程:默认(有特殊情况时修改)
示例:


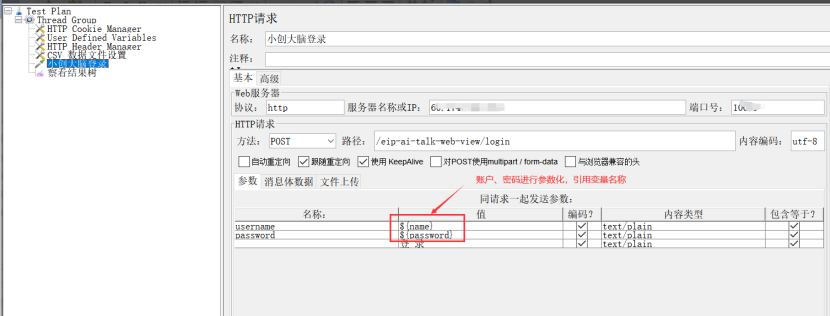


2、HTTP信息头管理器(HTTP Header Manager)
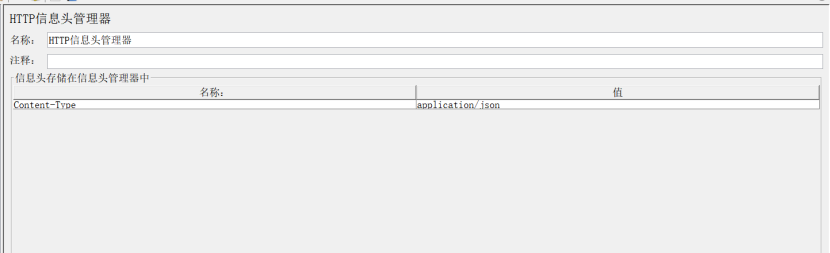
作用:在线程组下面添加HTTP信息头管理器,这时候HTTP信息头管理器是可以作用域整个当前线程组下的所有请求;也可以在某个具体取样器下面添加HTTP信息头管理器,这里只作用于当前取样器。所以在添加HTTP信息头管理器的时候需要结合实际场景来确定添加在树的什么节点
信息头存储在信息头管理中:通过使用浏览器或者抓包工具查看实际请求的Request Headers作为参考
3、HTTP Cookie管理器(HTTP Cookie Manager)
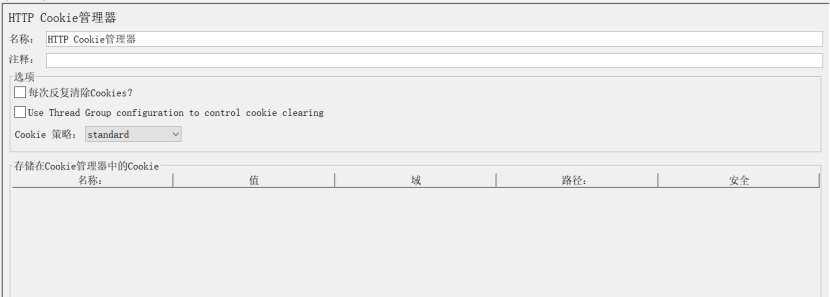
作用:HTTP Cookie管理器会记录服务器返回的cookie信息,并在发送请求时自动添加上合适的cookie,可手动添加一些cookie,在发送请求时也会被自动添加到请求。
4、HTTP请求默认值(HTTP Request Defaults)

作用:多个请求都是发送给同一个服务器,我们就可以添加http请求默认值,这样所有的请求都不需要设置ip、端口、请求方法和路径,只需要设置请求数据即可。
5、JDBC Connection Configuration
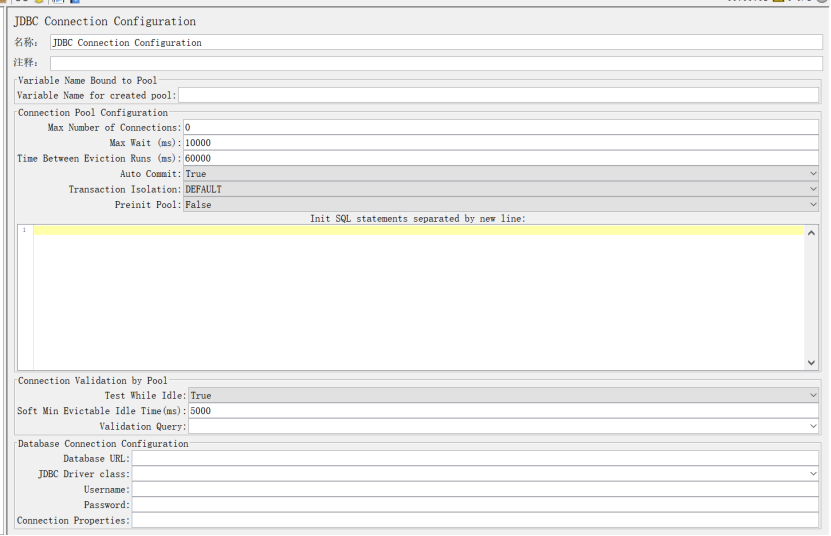
作用:配合JDBC Request一起使用,(参考JDBC Request介绍)。
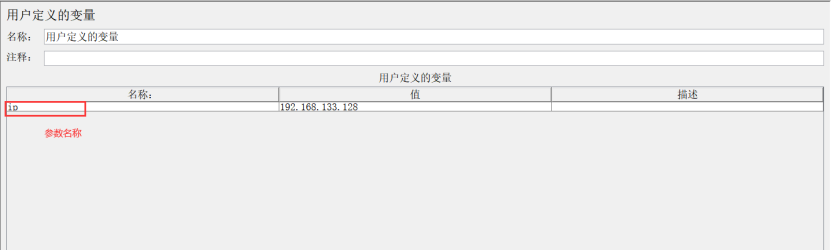
6、用户定义的变量(User Defined Variables)

作用:是Jmeter中常见的参数化方法。
示例:
十、监听器(Listener)
前提环境要求:
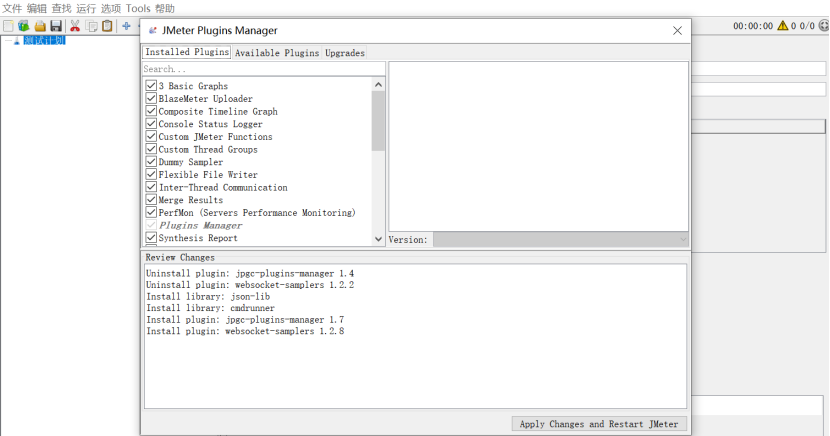
活动线程数曲线图、平均响应时间、每秒事务数等监听器是默认不带,需要下载Plugins Manager插件,官方下载地址:https://jmeter-plugins.org/install/Install/下载插件后把plugins-manager.jar包放到 lib/ext 目录,然后重启jmeter后选项菜单中有Plugins Manager选项,点击Plugins Manager,出现的界面分别显示已安装插件,可用插件(未安装),可更新插件等,根据测试需要安装插件(自己学习安装^_^)
1、察看结果树(View Results Tree)
作用:这是jmeter中最常用的监听器了,通过它就可以看到请求的发送和返回的详细信息

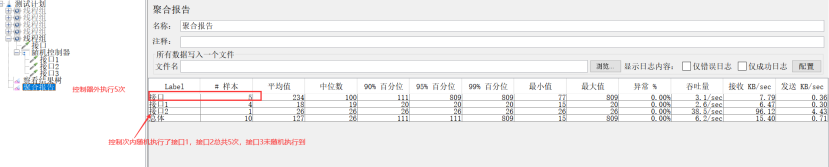
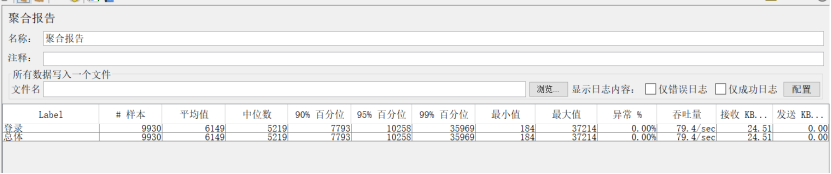
2、聚合报告(Aggregate Report)
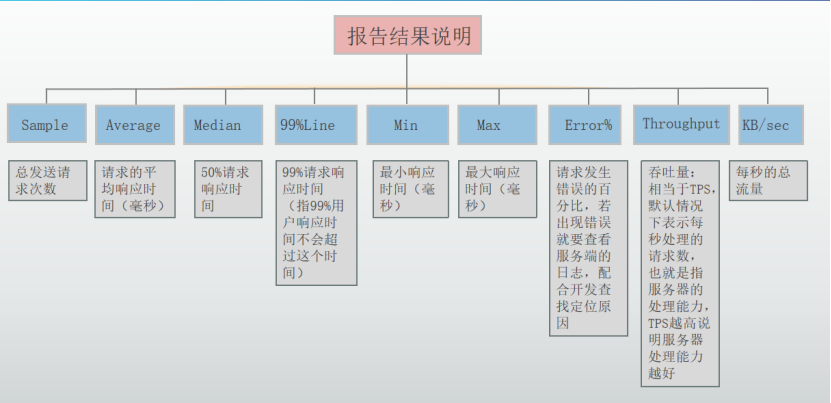
作用:对于每个请求,它统计响应信息并提供请求数,平均值,最大,最小值,错误率,大约吞吐量(以请求数/秒为单位)和以kb/秒为单位的吞吐量。
3、jp@gc - Active Threads Over Time(活动线程数曲线图)
作用:监听在执行测试的过程中每个线程组有多少个活跃的线程数(用户并发数曲线图)。
场景:在1秒内,线程全部启动完毕

4、jp@gc - Response Times Over Time(平均响应时间)
作用:在测试过程中实时监控的平均响应时间,单位是ms(平均响应时间曲线图)。

5、jp@gc - Transactions per Second(每秒事务数)
作用:是在测试脚本执行过程中,监控查看服务器的TPS表现————比如整体趋势、实时平均值走向、稳定性等。
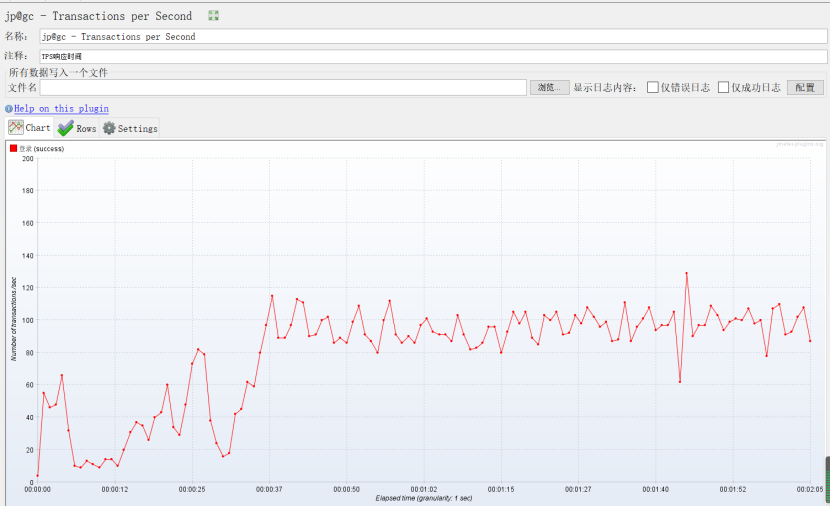
备注:红色是代表全部成功的,有报错的话会绿色显示
6、jp@gc - PerfMon Metrics Collector(服务器监控)
前提环境要求:
(1)客户端插件:在官网https://jmeter-plugins.org/downloads/old/中下载对应的JMeterPlugins-Standard,解压后将JMeterPlugins-Standard.jar放到jmeter的lib\ext目录下,重启jmeter
(2)服务器插件:在官网https://jmeter-plugins.org/wiki/PerfMonAgent/中下载服务端插件server-agent,下载后放置到需要监控的服务器中的任一位置,启动监测程序,Linux系统运行startAgent.sh,windows系统运行startAgent.bat
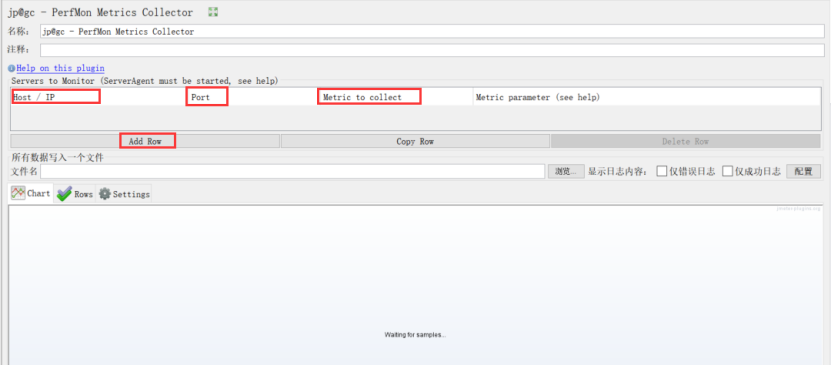
Host/IP:本地写localhost,服务器写服务器IP地址
Port:端口,默认4444
Metric to collect:一般选择CPU,Memory,Disks I/O,NetWork I/O
作用:本地监控服务器性能,一般监测服务器的四个指标:CPU,Memory,Disks I/O,NetWork I/O
示例:
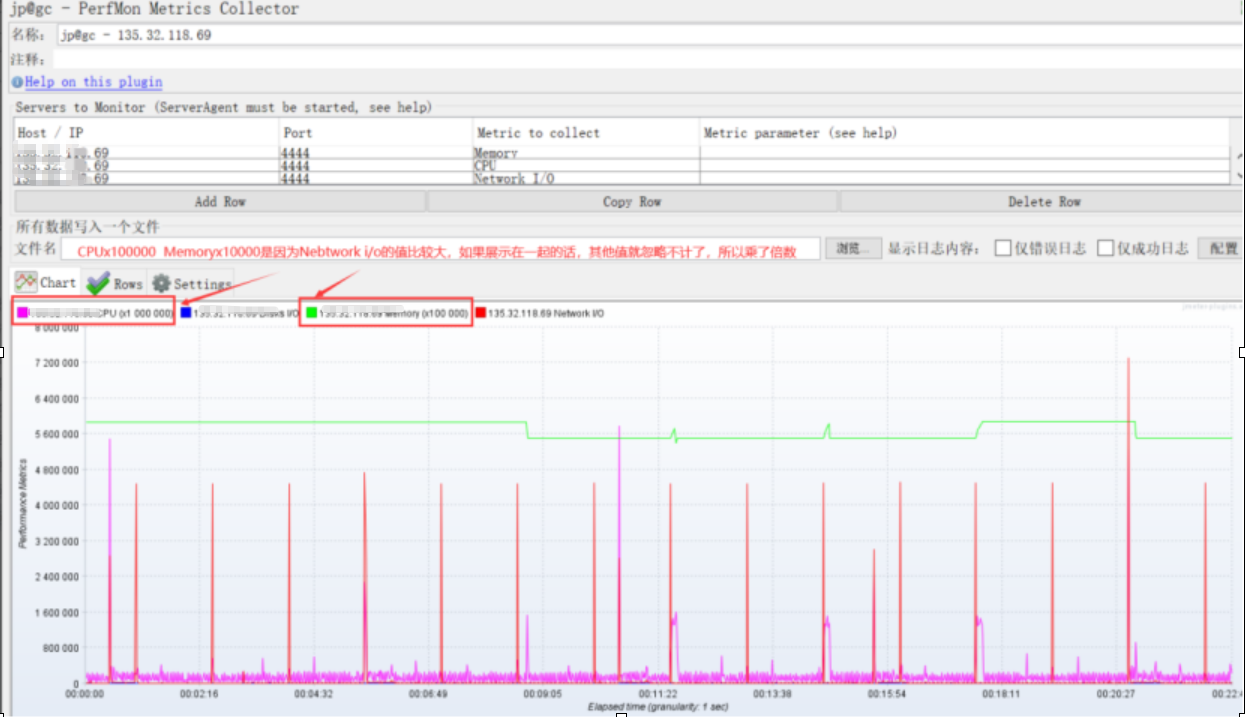
结果数据说明:例如左侧竖坐标值为560000时换算成CPU 则为560000/1000000=5.6%
常见问题汇总:
(1)如果没有启动服务器监测ServerAgent或者服务器防火墙未关闭会报以下错误:ERROR: java.net.ConnectException: Connection refused: connect
(2)如果在使用过程中出现了这个错误java.lang.NoSuchMethodError: org.apache.jmeter.samplers.SampleSaveConfiguration.setFormatter(Ljava/text/DateFormat;),此问题是因为所用JMeter版本过高不支持jp@gc - PerfMon Metrics Collector插件导致
(3)如果默认端口4444被占用,切换到空闲端口,命令:java -jar ./CMDRunner.jar --tool PerfMonAgent --tcp-port xxxx --udp-port xxxx
