词频分析项目报告
2018-03-30 21:45 ccj1998 阅读(999) 评论(1) 收藏 举报- 要求
- 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
- 使用性能测试工具进行分析,找到性能的瓶颈并改进
- 对代码进行质量分析,消除所有警告
- 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
- 使用Github进行代码管理
- 撰写博客
基本功能
- 统计文件的字符数
- 统计文件的单词总数
- 统计文件的总行数
- 统计文件中各单词的出现次数
- 对给定文件夹及其递归子文件夹下的所有文件进行统计
- 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
功能模块
- 遍历目录
调用函数listDir,参数path为需要读取的路径,变量childpath为文件名
void listDir(char *path){ DIR *pDir=NULL; struct dirent *ent=NULL; int i=0; char childpath[512],ch; pDir=opendir(path); memset(childpath,0,sizeof(childpath)); while((ent=readdir(pDir))!=NULL){ if(ent->d_type & DT_DIR){ if(strcmp(ent->d_name,".")==0||strcmp(ent->d_name,"..")==0)continue; sprintf(childpath,"%s%s/",path,ent->d_name); listDir(childpath); } else{ sprintf(childpath,"%s%s",path,ent->d_name); puts(childpath); if((fin=fopen(childpath,"r"))==NULL){ fprintf(fout,"cannot open this file\n"); exit(0); } while((ch=fgetc(fin))!=EOF){ if(ch>=32&&ch<=126){ //counting the number of character count_character++; } if(ch=='\n'){ count_line++; } wordjudge(ch); } preword=NULL; wordstore[0]=wordstore[1]='\0'; count_line++; fclose(fin); } } }
- 判断单词
调用函数wordjudge,对输入的字符判断其能否构成一个单词。若能,则将形成的字符进行下一步处理
void wordjudge(char ch){ int i; char dest[WORDLEN]={0}; if(ch>='A'&&ch<='Z'||ch>='a'&&ch<='z'||ch>='0'&&ch<='9'){ i=wordstore[0]; if(i<WORDLEN-2){ i=++wordstore[0]; wordstore[i]=ch; wordstore[i+1]='\0'; } else{ // printf("the word is too long!\n"); } } else if(wordstore[0]) { for(i=1;i<=4&&wordstore[i]&&(wordstore[i]>='A'&&wordstore[i]<='Z'||wordstore[i]>='a'&&wordstore[i]<='z');i++); if(i==5){ strncpy(dest,wordstore+1,strlen(wordstore)-1); dest[strlen(dest)]='\0'; wordoperation(dest); count_word++; } wordstore[0]=0; wordstore[1]='\0'; } }
- 单词处理
对要处理的单词进行标准化,对标准化后的单词哈希处理,存入单词结构体哈希表中。同时也顺带将当前单词和前一个单词组成的词组存入词组哈希表中
void wordoperation(char* newword){ int i,t,j,k,h=0,g=0; char c,newwordc[WORDLEN]; strcpy(newwordc,newword); t=(int)strlen(newword); c=*(newwordc+t-1); for(;c>='0'&&c<='9';t--){ newwordc[t]='\0'; c=*(newwordc+t-1); } strlwr(newwordc); /*The following centences are to store word*/ j=strlen(newwordc); for(k=1;k<j&&k<10;k++){ h=(newwordc[k-1]+(h*36))%WORDNUM; } while(Hashw[h].frequency&&strcmp(Hashw[h].after_deal,newwordc)){ h=(h+1)%WORDNUM; } if(Hashw[h].frequency){ Hashw[h].frequency ++; if(strncmp(Hashw[h].content ,newword,51)>0){ strcpy(Hashw[h].content ,newword); } } else{ Hashw[h].frequency =1; strcpy(Hashw[h].content,newword); strcpy(Hashw[h].after_deal ,newwordc); } /*The following centences are to store word group*/ if(preword){ for(i=0;i<4;i++){ g=(g*36+preword->after_deal[i])%GROUPNUM; } for(i=0;i<4;i++){ g=(g*36+newwordc[i])%GROUPNUM; } while(Hashg[g].frequency && (strncmp(Hashg[g].firstword->after_deal,preword->after_deal,51)||strncmp(Hashg[g].secword->after_deal,newwordc,51))){ g=(g+1)%GROUPNUM; } if(Hashg[g].frequency){ Hashg[g].frequency ++; } else{ Hashg[g].frequency =1; Hashg[g].firstword =preword; Hashg[g].secword =&Hashw[h]; } } preword=&Hashw[h]; }
- 寻找前十单词和词组
遍历哈希表,找出前十单词和词组
void toptenw(void){ word tenw[10]={0}; int j,m,n; for(j=0;j<WORDNUM;j++){ if(Hashw[j].frequency ){ for(m=9;m>=0&&(!tenw[m].frequency||Hashw[j].frequency>tenw[m].frequency);m--); if(m+1<=9){ for(n=9;n>m+1;n--){ tenw[n]=tenw[n-1]; } tenw[m+1]=Hashw[j]; } } } for(j=0;j<10;j++){ if(tenw[j].frequency)fprintf(fout,"%s: %d\n",tenw[j].content,tenw[j].frequency); } } void topteng(void){ wordgroup teng[10]={0}; long int j,m,n; for(j=0;j<GROUPNUM;j++){ if(Hashg[j].frequency ){ for(m=9;m>=0&&(!teng[m].frequency||Hashg[j].frequency>teng[m].frequency);m--); if(m+1<=9){ for(n=9;n>m+1;n--){ teng[n]=teng[n-1]; } teng[m+1]=Hashg[j]; } } } for(j=0;j<10;j++){ if(teng[j].frequency)fprintf(fout,"%s %s: %d\n",teng[j].firstword->content,teng[j].secword->content,teng[j].frequency); } }
性能分析

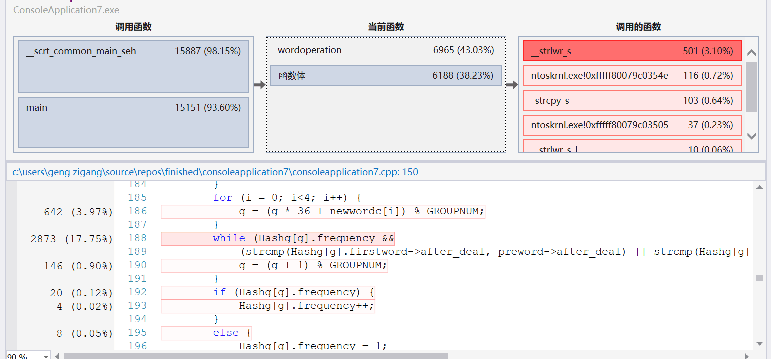

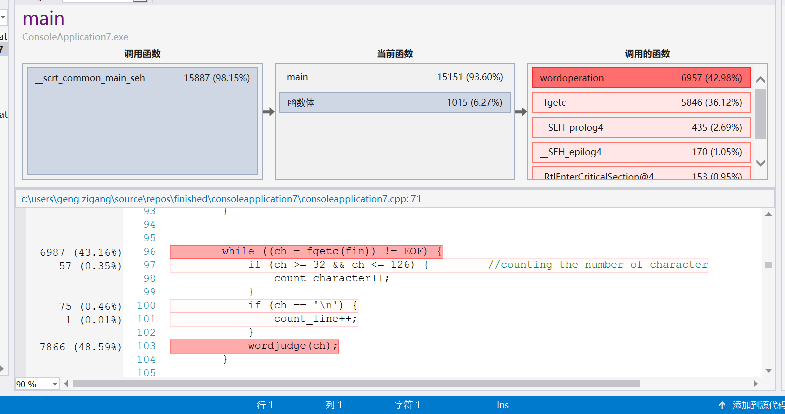
release模式下运行时间大概16s左右,可以看到:
- fgetc耗时量巨大,但是读字符是必不可少的操作所以不好修改。
- 对每一个字符判断处理的函数wordjudge调用次数也很多,但是要处理多少字符就要调用,多少次函数,所以也没有太多优化空间。
- 对词组和词的存入判断占用也较大,但是也是情理之中。
- 遍历词组和词哈希表找前十倒是没有花多少时间。
- 为了提高时间效率,开了较大的空间,属于时间和空间的互换。
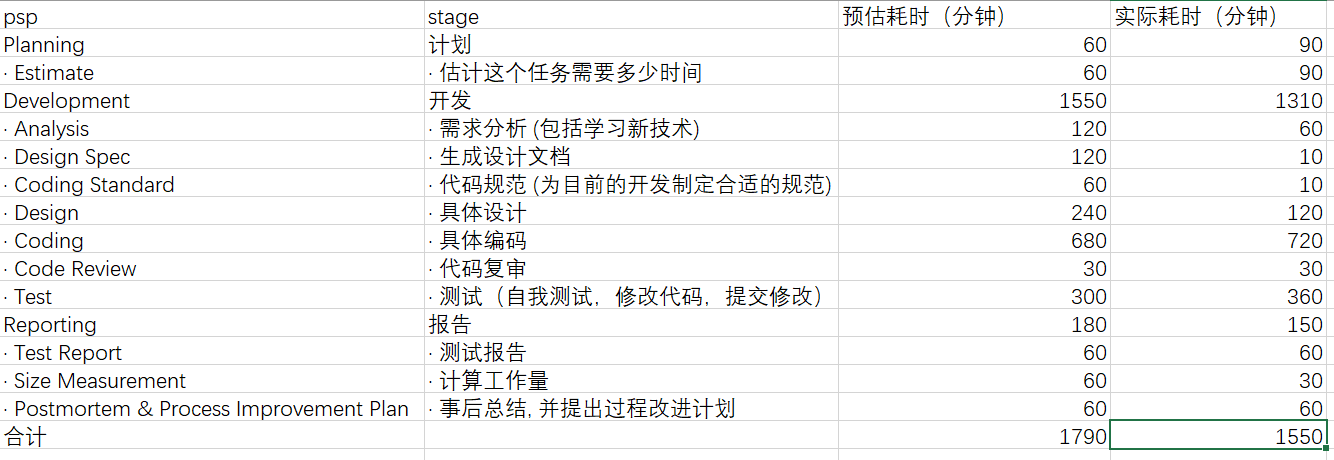
PSP表格
测试结果
VS下(左助教右我的)
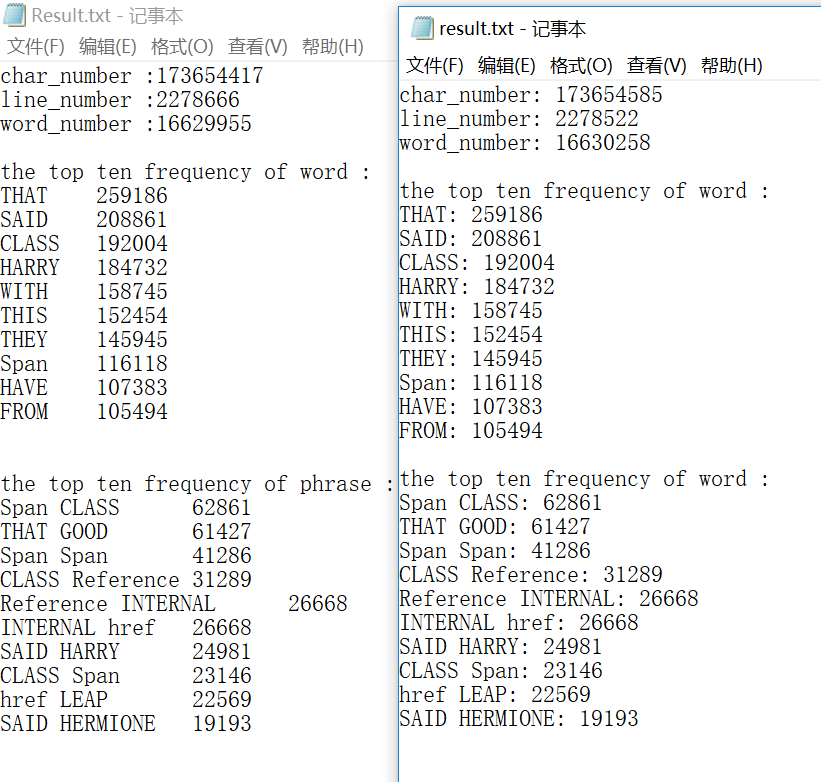
Linux下(左我的右助教)
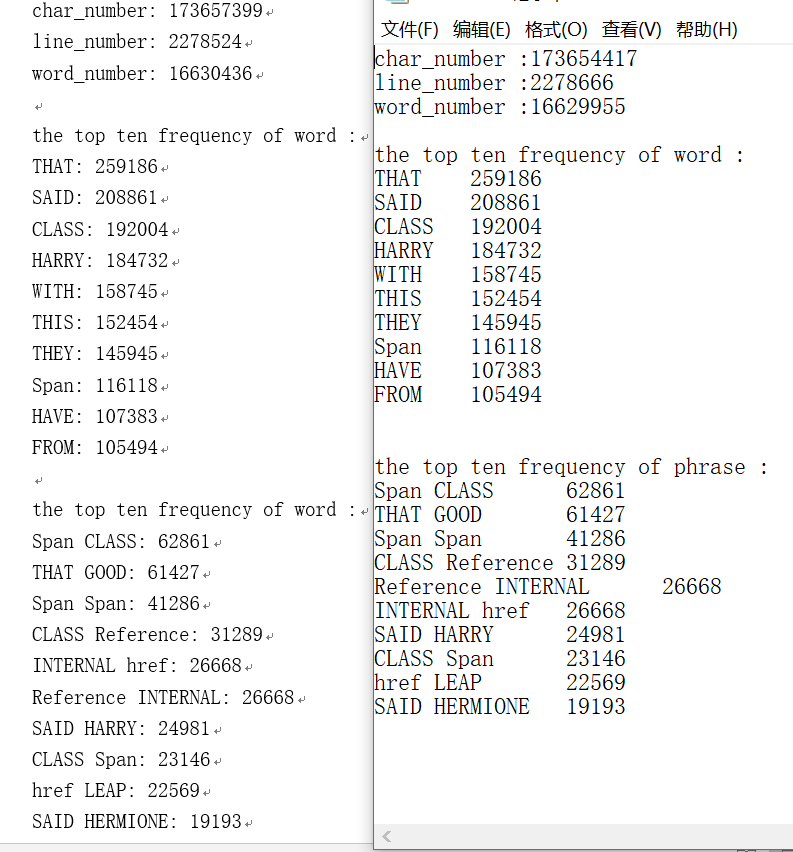
可以看到,在两种测试环境下,前十单词和词组都和助教都是一样的。但是两种环境下的单词字符和行数都有数百的误差,实在不是很清楚原因。
项目经历及总结分析
- 一开始我的畏难情绪十分严重,因为自己实在比较菜,除了c和dev啥也没用过,所以这星期的任务实在太多。所以我选择先写完其它作业再全力肝软工。感觉这个决定很正确。因为我在构思的时候也确实收到了一些写了博客的同学的启发。
- 本次作业,周一周二写完基本函数模块,周三一轮测试,发现不行并进行了大的重构。周四中午完成VS上的调试,周四晚10点完成Linux下的移植。
- 一开始词和词组的哈希表是26*26*26*26的数组,按照前4个字母排序。由于这种方式和题目要求契合的较好,我一度觉得这是很好的解决方案。但是运行到大文件的时候还是出现了读取非常慢的情况。几经考虑后决定加大数组容量,并优化词组的存储方式和哈希函数,使程序明显清晰了不少,速度和稳定性都有提升。
- 这次个人作业让我了解了VS的一些基本操作,以及使用GitHub,遍历文件夹,以及Linux的一些简单命令和操作,还有关于程序移植方面的知识,以及练习了一些调试的技能,可以说是逼着狠狠恶补了一把。
- 这次软工还我明白了时间分配的重要性,从周一一直肝到周五,欠下了一堆的作业,上课的状态也不是很好,之后又要花好多时间来补,而且马上期中考又要加实验课,实在伤不起。以后要么更新技能,提高水平,要么“有舍才有得”/无奈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号