
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
实验内容:
- 结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
实验环境:
VMWare虚拟机下的Ubuntu18.04.4,实验采用的内核版本为linux-5.4.34。
1 基础概念
CPU工作状态
CPU的工作状态分为系统态(管态)和用户态(目态)。
引入这两个工作状态的原因是为了避免用户程序错误地使用特权指令,保护操作系统不被用户程序破坏。
当CPU处于用户态时,不允许执行特权指令;当CPU处于系统态时,可执行包括特权指令在内的一切机器指令。
中断与系统调用
-
系统调用
程序员或系统管理员通常并非直接和系统调用打交道。在实际应用中,程序员通过调用函数(或称应用程序接口、API),管理员则使用更高层次的系统命令。
操作系统为每个系统调用在标准C函数库中构造一个具有相同名字的封装函数,由它来屏蔽下层的复杂性,负责把操作系统提供的服务接口(即系统调用)封装成应用程序能够直接调用的函数(库函数)
-
中断
所谓中断是指CPU对系统发生的某个事件做出的一种反应,CPU暂停正在执行的程序,保留现场后自动地转去执行相应的处理程序,处理完该事件后再返回断点继续执行被“打断”的程序。
中断概念主要分为三类
- 外部中断,如I/O中断,时钟中断,控制台中断等。
- 异常,如CPU本身故障(电源电压或频率),程序故障(非法操作码、地址越界、浮点溢出等),即CPU的内部事件或程序执行中的事件引起的过程。
- 陷入(陷阱),在程序中使用了请求系统服务的系统调用而引发的过程。
-
中断与系统调用
外部中断与异常通常都称作中断,它们的产生往往是无意、被动的。
陷入是有意和主动的,系统调用本身是一种特殊的中断。
进程上下文与中断上下文
-
进程上下文
用户空间的应用程序,通过系统调用进入内核空间。用户空间的进程需要传递变量、参数的值给内核,在内核态运行时也要保存用户进程的一些寄存器值、变量等。进程上下文,可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量、寄存器值和当时的环境等。
相对于进程而言,就是进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
-
中断上下文
为了在 中断执行时间尽可能短 和 中断处理需完成大量工作 之间找到一个平衡点,Linux将中断处理程序分解为两个半部:顶半部和底半部。顶半部完成尽可能少的比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后就进行“登记中断”的工作。“登记中断”意味着将底半部处理程序挂到该设备的底半部执行队列中去。这样,顶半部执行的速度就会很快,可以服务更多的中断请求。
对于中断而言,内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理,中断上下文就可以理解为硬件传递过来的这些参数和内核需要保存的一些环境,主要是被中断的进程的环境。
2 fork系统调用
Linux中通过fork系统调用来处理进程创建的任务。
对于进程的创建,sys_clone, sys_vfork,以及sys_fork系统调用的内部都使用了do_fork函数。
在sys_clone,sys_vfork和sys_fork处打下断点,运行系统,在sys_clone处停下:
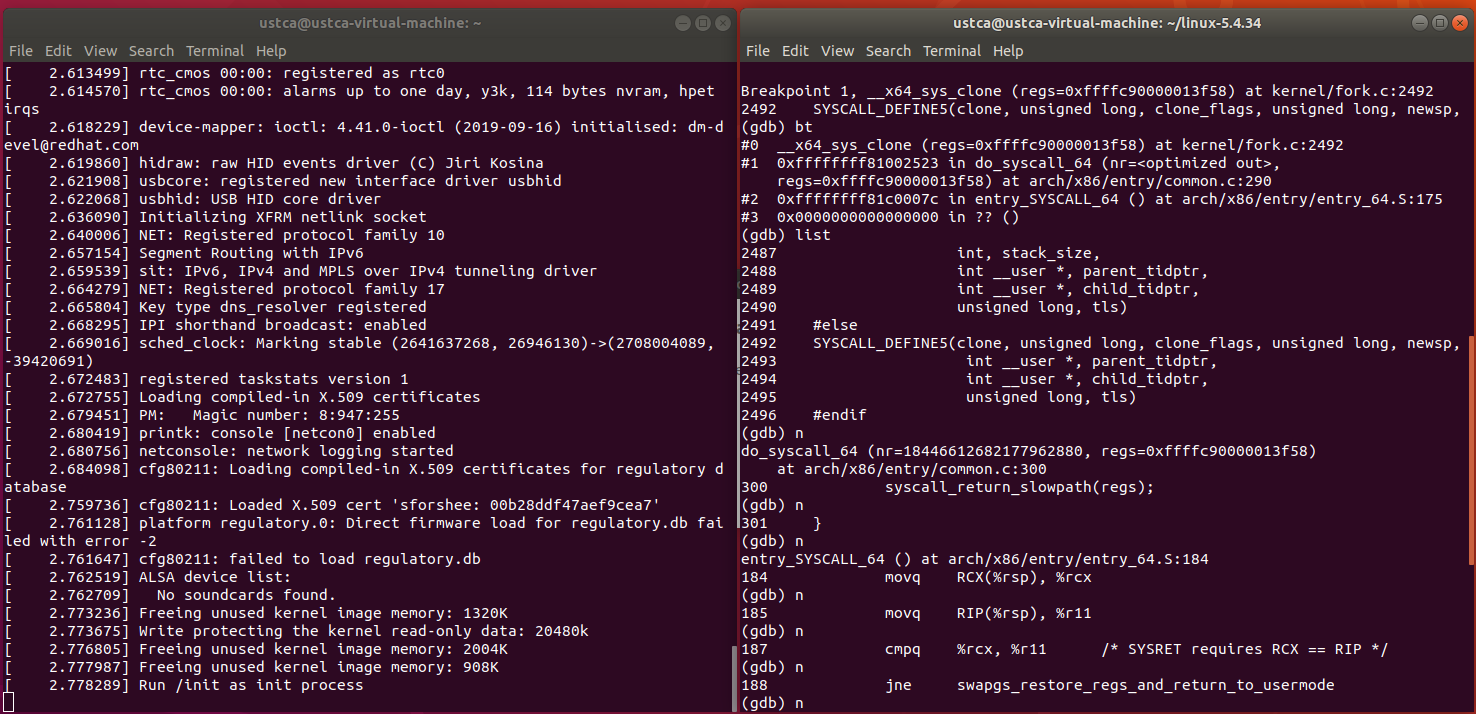
sys_clone源码:
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int, tls_val,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#endif
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
#endif
代码最终调用do_fork函数,转到do_fork执行,其他创建进程函数调用过程与此类似,do_fork函数如下:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
do_fork会进行一些pcb的拷贝工作。
在调用copy_process函数时,会进行一些实际内容的拷贝:复制当前进程产生子进程,并且传入关键参数为子进程设置响应进程上下文。具体过程为:先通过调用 dup_task_struct 复制一份task_struct结构体,作为子进程的进程描述符。再初始化与调度有关的数据结构,调用sched_fork,将子进程的state设置为TASK_RUNNING。之后复制所有的进程信息,包括fs、信号处理函数、信号、内存空间(包括写时复制)等。最终调用copy_thread,设置子进程的堆栈信息, 为子进程分配一个pid。
在调用wake_up_new_task函数时,主要任务是将子进程放入调度队列中,从而使CPU有机会调度并得以运行。
3 execve系统调用
execve系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。
与fork系统调用不同,从一个进程中启动另一个程序时,通常是先 fork 一个子进程,然后在子进程中使用 execve变为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork了自身进程,然后在子进程中使用 execve来运行指定的程序。
execve系统调用的函数原型为:
int execve(const char *filename, char *const argv[], char *const envp[]);
filename 用于指定要运行的程序的文件名,argv 和 envp 分别指定程序的运行参数和环境变量。除此之外,该系列函数还有很多变体(execl、execlp、execle、execv、execvp、execvpe),它们执行大体相同的功能,区别在于需要的参数不同,但都是通过execve系统调用进入内核。
execve系统调用的过程:首先,执行__x64_sys_execve系统调用,进入内核态后调用do_execve加载可执行文件,之后再通过调用search_binary_handler覆盖当前进程的可执行程序。
static int exec_binprm(struct linux_binprm *bprm)
{
pid_t old_pid, old_vpid;
int ret;
/* Need to fetch pid before load_binary changes it */
old_pid = current->pid;
rcu_read_lock();
old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
ret = search_binary_handler(bprm);
if (ret >= 0) {
audit_bprm(bprm);
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
proc_exec_connector(current);
}
return ret;
}
最后将IP设置为新的进程的入口地址,然后返回用户态,继续执行新进程。最终旧进程的上下文被完全替换,但进程pid 不变,调用返回新进程。
4 Linux系统的一般执行过程
当前linux系统中正在运行用户态进程X,需要切换到用户态进程Y的时候,会执行以下过程:
-
用户态进程X正在运行
-
运行的过程当中,发生了中断
-
中断上下文切换,swapgs指令保存现场后,再加载当前进程内核堆栈栈顶地址到RSP寄存器,由进程X的用户态转到进程X的内核态。
-
中断处理过程中或中断返回前调用schedule函数,完成进程调度算法。
-
switch_to调用__switch_to_asm汇编代码,完成关键的进程上下文切换。
-
中断上下文恢复。
-
继续运行用户态进程Y
Linux一般切换流程中有CPU的上下文的切换和内核中的进程上下文的切换。中断和中断返回有中断上下文的切换,CPU和内核代码中断处理程序入口的汇编代码结合起来完成中断上下文的切换。进程调度过程中有进程上下文的切换,而进程上下文的切换完全由内核完成。
几种特殊情况
(1)通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换。
(2)内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略。
(3)创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork。
(4)加载一个新的可执行程序后返回到用户态的情况,如execve。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号