

从Go语言编码角度解释实现简易区块链——打造公链
转载请注明出处:https://www.cnblogs.com/ustca/p/11747826.html
区块链技术
人们可以用许多不同的方式解释区块链技术,其中通过加密货币来看区块链一直是主流。大多数人接触区块链技术都是从比特币谈起,但比特币仅仅是众多加密货币的一种。
到底什么是区块链技术?
从金融学相关角度来看,区块链是一种存储数据的方式,去中心化的数据库,应用到比特币也就是去中心化账本;
从密码学角度来看,区块链是一种传递价值的协议;
从计算机科学的角度来看,区块链只是一种数据结构;
不同于我们平时接触的手机电脑,先有系统,然后才会在系统里开发各种APP应用。09年第一枚比特币诞生,15年也就是6年之后,才有区块链这个概念。许多人了解区块链,都是从金融学或者密码学的角度作为切入,从中本聪的比特币白皮书开始谈起。通过金融角度看待区块链,总有种雾里看花的感觉,从密码学角度看区块链,分析粒度又太细了。就计算机而言,我们所需要的只是看到这项技术的本质。当技术与金融一旦挂钩,往往就会变成玄学,区块链也是这样,当这项技术概念被从比特币中抽离出来的时候,比特币就只不过是这项技术的一个Demo而已。
接下来抛开金融学的概念,密码学的理论,不关心区块链金融,不研究区块链安全,只分析区块链技术,从计算机科学来了解区块链的模型。
本质是一种数据结构
下面将通过Go语言,来编码实现一个简易的区块链模型,模型分为不同阶段,本文先实现区块链简易的数据结构、工作量证明共识、数据库持久化存储以及命令行接口。
即使没学过Go语言,也可以立刻上手。Go语言语法与python类似,却又是编译型而非解释型语言,有着媲美C的高性能,是区块链开发主流语言。
对于程序员而言,需要用逻辑解释的问题,通过代码结合语言特性来描述是最简单易懂的。实际上,当你读完这篇文章,不只是Go语言,你可以用你熟悉的其他语言实现同样的效果,因为这只是个简简单单的数据结构。从学习角度来说,都是C类语法,所以你只需要看懂,不需要会写,就可以转换到你熟悉的语言实现。
接下来的代码,是在多个文件中实现的,这里有必要先简单讨论下Go语言的一些语言特性,这有助于后续的代码逻辑理解。
"一个程序就是一个世界,有许多不同的对象",从C语言不完全面向对象,到Java的面向对象,再到Go语言的不纯粹面向对象,都与现实世界中抽离出的对象这个概念紧密相连。Go语言实际上是没有对象的面向对象编程,因为从语法角度上来说她没有”类“。最吸引人的不是Go拥有的特征,而是那些被故意遗漏的特征。
为什么你要创造一种从理论上来说,并不令人兴奋的语言?
因为它非常有用。 —— Rob Pike
C语言没有完全的面向对象,她在这方面没有完全的语法约束,而后来的Java做了这种约束,到如今的Golang去除了这些约束。从语言本身角度,这并不让人兴奋,但确实非常好用。
“如果你可以重新做一次Java,你会改变什么?”
“我会去掉类class,” 他回答道。
在笑声消失后,他解释道,真正的问题不是类class本身,而是“实现”的继承(类之间extends的关系)。接口的继承(implements的关系)是更可取的方式。
只要有可能,你就应该尽可能避免“实现”的继承。
—— James Gosling(Java之父)
Go可以包含对象的基本功能:标识、属性和特性,所以是基于对象的。如果一种语言是基于对象的,并且具有多态性和继承性,那么它被认为是面向对象的。
那么Go语言是如何实现继承的?
Go通过严格地遵循了符合继承原则的组合方式,明确地避免了继承,她使用嵌入类型来实现组合。
继承把“知识”向下传递,组合把“知识”向上拉升
—— Steve Francia
Go语言又如何实现多态?
Go明确避免了子类型和重载,尚未提供泛型,利用接口提供了多态功能。
总而言之,Go用尽可能少的语法规则,实现了尽可能多的语言特性。这使得go语言面向对象非常简洁,去掉了传统OOP语言的继承,方法重载,构造函数和析构函数等等。
我们之后的编码,分多个文件完成的原因也正是因为这些,我们将感觉像对象的多个文件当作对象,只要它走起路来像鸭子,叫起来像鸭子,那么我们就认为它是一只鸭子。(实际上,一些文件中用到了Go语言提供的面向对象特性,但这里不做详细解释区分)
结构描述
这是我们要编写的main.go文件:
package main
func main() {
bc := NewBlockchain()
defer bc.db.Close()
cli := CLI{bc}
cli.Run()
}
我们需要编写的还有
block.go、 blockchain.go、 cli.go、 proofofwork.go、 utils.go
每部分代码都很简短,分文件是为了通过尽量简单的方式做出我们想看到的对象。
你可以把这些文件看成一个个”类“,也可以把这些文件看成某些业务逻辑关系,因为Go本身没有做出限制你不能这么用,你可以按照你感觉像的逻辑去理解。
那么我们究竟要写的是什么样的结构?
你可以把我们的任务理解成,先构造一种结点,然后再将这种结点链接成链表,只不过链表结点的加入需要满足一种特殊条件——工作量证明共识机制(只不过是暴力搜索凑出一个特定条件的字符串而已,让你不能随随便便往链表添加数据,美其名曰工作量证明,跟计算机算力较劲...所谓的挖矿),最后我们需要把完成的链表保存到数据库,本节所要讨论的简易区块链从编码角度来看只是这么个简单结构而已。从非编码角度去分析区块链,往往就复杂了,可能还没必要,因为那些不是你想理解的。
编码实现
实现顺序为:
- utils.go 提供工具函数
- proofofwork.go 提供工作量证明相关的函数
- block.go 提供关于结点的函数
- blockchain.go 提供关于链表的函数
- cli.go 提供命令行操作控制的函数(为了方便使用命令行执行程序)
- main.go 提供程序入口
你可以理解成是自底向上的顺序,也可以理解成某种业务依赖关系的顺序,可以自由的用你熟悉的方式去理解。
untils.go
因为我们要用这个go语言没提供的类型转换,所以有了untils.go
package main
import (
"bytes"
"encoding/binary"
"log"
)
// IntToHex converts an int64 to a byte array
func IntToHex(num int64) []byte {
buff := new(bytes.Buffer)
err := binary.Write(buff, binary.BigEndian, num)
if err != nil {
log.Panic(err)
}
return buff.Bytes()
}
proofofwork.go
假设现在有了一个区块链,大家都能随便往区块链上写入自己的块,那么这个区块链就没什么价值可言。所以需要设置一个门槛,当你满足一定条件时,才允许你往区块链上添加新的数据,这样付出了成本才有了价值。而区块链的门槛,就是一个被叫做工作量证明共识的东西,这是一个所有矿工(想获得添加区块资格的人)都认同的门槛。
比如我们当前实现的简易区块链,考虑到执行时间问题,我们的门槛就是找到一串长度为64的字符串,而这串字符串的前6位为0.
这个字符串不是随便构造的,不然可以直接指定前6位为0,后面都为随机的字符串,那样就没有价值可言了,所以我们还需要一个构造的规则。
怎么让找到某种字串具有工作难度?容易想到的是寻找哈希值。
好比你现在知道了一个用户密码的哈希值,想去找出用户密码,区块链所谓的工作量证明、挖矿,都只是去找一个大家共识承认的哈希值而已(...与计算机算力斗智斗勇,手动滑稽)。
我们本节用到的字符串获取规则,是采用sha256算法。关于sha256算法的具体原理,或者为什么选择该哈希算法,不是我们当前要考虑的问题,对密码学有兴趣的可以自行拓展了解。要进行哈希运算的字符串,也有一定的共识规则:
字符串 = 前一个区块的哈希值 + 当前块数据 + 时间戳 + targetBits(后面会解释)+ 自由参数。
实际挖矿我们只是想找到有价值的自由参数,其余值都是给定的。
了解完这些概念,接下来就可以直接看代码了:
package main
import (
"bytes"
"crypto/sha256"
"fmt"
"math"
"math/big"
)
var (
maxNonce = math.MaxInt64
)
const targetBits = 24
// ProofOfWork represents a proof-of-work
type ProofOfWork struct {
block *Block
target *big.Int
}
// NewProofOfWork builds and returns a ProofOfWork
func NewProofOfWork(b *Block) *ProofOfWork {
target := big.NewInt(1)
target.Lsh(target, uint(256-targetBits))
pow := &ProofOfWork{b, target}
return pow
}
func (pow *ProofOfWork) prepareData(nonce int) []byte {
data := bytes.Join(
[][]byte{
pow.block.PrevBlockHash,
pow.block.Data,
IntToHex(pow.block.Timestamp),
IntToHex(int64(targetBits)),
IntToHex(int64(nonce)),
},
[]byte{},
)
return data
}
// Run performs a proof-of-work
func (pow *ProofOfWork) Run() (int, []byte) {
var hashInt big.Int
var hash [32]byte
nonce := 0
fmt.Printf("Mining the block containing \"%s\"\n", pow.block.Data)
for nonce < maxNonce {
data := pow.prepareData(nonce)
hash = sha256.Sum256(data)
// fmt.Printf("\n%x", hash)
hashInt.SetBytes(hash[:])
if hashInt.Cmp(pow.target) == -1 {
break
} else {
nonce++
}
}
// fmt.Print("\n\n")
return nonce, hash[:]
}
// Validate validates block's PoW
func (pow *ProofOfWork) Validate() bool {
var hashInt big.Int
data := pow.prepareData(pow.block.Nonce)
hash := sha256.Sum256(data)
hashInt.SetBytes(hash[:])
isValid := hashInt.Cmp(pow.target) == -1
return isValid
}
关于全局变量targetBits,是用做规定当前的“共识”,24位代表哈希值前24位为0,也就是6个十六进制的0,才算有效哈希值(矿)。
我们定义了一个proofofwork的结构体,包含两个指针,一个指向区块,一个指向阈值。
关于阈值,我们可以理解成,既然需要找到一个哈希值前24位为0,那么把它当作二进制数字看的话,一个第23位为1,其余位为0的二进制数就是我们要找的哈希值上限(阈值)。只要我们找到的哈希值小于这个数,那么该哈希值的前24位肯定为0.
除此之外,
- NewProofOfWork函数,可以当成“类”的构造函数,表示我们要初始化一个对象来挖矿了
- prepareData函数用来准备进行哈希运算的字符串
- Run函数使用从0开始的整数作为自由参数,进行挖矿(找到一个比阈值小的哈希值)
- Validate函数用来验证区块哈希值是否满足条件
函数都很好理解,简单到只需要看懂语法,不需要过多解释逻辑,这就是最本质的区块链。
block.go
主要包含以下内容:
- Block结构体,包含时间戳、数据、前块哈希值、当前哈希与自由参数
- NewBlock函数,初始化一个新块
- NewGenesisBlock函数,初始化一个创世块(区块链的第一个块)
- Serialize与DeserializeBlock函数,对Block进行序列化与反序列化,用户实现数据库存储
package main
import (
"bytes"
"encoding/gob"
"log"
"time"
)
// Block keeps block headers
type Block struct {
Timestamp int64
Data []byte
PrevBlockHash []byte
Hash []byte
Nonce int
}
// NewBlock creates and returns Block
func NewBlock(data string, prevBlockHash []byte) *Block {
block := &Block{time.Now().Unix(), []byte(data), prevBlockHash, []byte{}, 0}
pow := NewProofOfWork(block)
nonce, hash := pow.Run()
block.Hash = hash[:]
block.Nonce = nonce
return block
}
// NewGenesisBlock creates and returns genesis Block
func NewGenesisBlock() *Block {
return NewBlock("Genesis Block", []byte{})
}
// Serialize serializes the block
func (b *Block) Serialize() []byte {
var result bytes.Buffer
encoder := gob.NewEncoder(&result)
err := encoder.Encode(b)
if err != nil {
log.Panic(err)
}
return result.Bytes()
}
// DeserializeBlock deserializes a block
func DeserializeBlock(d []byte) *Block {
var block Block
decoder := gob.NewDecoder(bytes.NewReader(d))
err := decoder.Decode(&block)
if err != nil {
log.Panic(err)
}
return &block
}
blockchain.go
这里要引入数据库,用来存储我们当前的区块链,不使用数据库也可以,但那样每次都需要重新运行查看,无法持久化。
本节使用到的boltdb是go实现的一个k-v数据库。
package main
import (
"fmt"
"log"
"bolt-master"
)
const dbFile = "blockchain.db"
const blocksBucket = "blocks"
// Blockchain keeps a sequence of Blocks
type Blockchain struct {
tip []byte
db *bolt.DB
}
// BlockchainIterator is used to iterate over blockchain blocks
type BlockchainIterator struct {
currentHash []byte
db *bolt.DB
}
// AddBlock saves provided data as a block in the blockchain
func (bc *Blockchain) AddBlock(data string) {
var lastHash []byte
err := bc.db.View(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(blocksBucket))
lastHash = b.Get([]byte("l"))
return nil
})
if err != nil {
log.Panic(err)
}
newBlock := NewBlock(data, lastHash)
err = bc.db.Update(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(blocksBucket))
err := b.Put(newBlock.Hash, newBlock.Serialize())
if err != nil {
log.Panic(err)
}
err = b.Put([]byte("l"), newBlock.Hash)
if err != nil {
log.Panic(err)
}
bc.tip = newBlock.Hash
return nil
})
}
// Iterator ...
func (bc *Blockchain) Iterator() *BlockchainIterator {
bci := &BlockchainIterator{bc.tip, bc.db}
return bci
}
// Next returns next block starting from the tip
func (i *BlockchainIterator) Next() *Block {
var block *Block
err := i.db.View(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(blocksBucket))
encodedBlock := b.Get(i.currentHash)
block = DeserializeBlock(encodedBlock)
return nil
})
if err != nil {
log.Panic(err)
}
i.currentHash = block.PrevBlockHash
return block
}
// NewBlockchain creates a new Blockchain with genesis Block
func NewBlockchain() *Blockchain {
var tip []byte
db, err := bolt.Open(dbFile, 0600, nil)
if err != nil {
log.Panic(err)
}
err = db.Update(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(blocksBucket))
if b == nil {
fmt.Println("No existing blockchain found. Creating a new one...")
genesis := NewGenesisBlock()
b, err := tx.CreateBucket([]byte(blocksBucket))
if err != nil {
log.Panic(err)
}
err = b.Put(genesis.Hash, genesis.Serialize())
if err != nil {
log.Panic(err)
}
err = b.Put([]byte("l"), genesis.Hash)
if err != nil {
log.Panic(err)
}
tip = genesis.Hash
} else {
tip = b.Get([]byte("l"))
}
return nil
})
if err != nil {
log.Panic(err)
}
bc := Blockchain{tip, db}
return &bc
}
blockchain文件的实现:
- Blockchain结构体,定义了一个字节数组,一个数据库对象指针,用于连接数据库进行操作
- BlockchainIterator结构体,用于迭代过程
- AddBlock函数,在数据库中链接一个新的区块
- Iterator迭代器,用于迭代遍历区块链
- Next函数,用于遍历中寻找后一个区块
- NewBlockchain函数,初始化一个新的区块链
总之,blockchain只是将区块链存入了数据库,有向数据库初始化一个新区块链与增加区块的功能。
cli.go
cli.go只是方便了在命令行下运行这些代码
package main
import (
"flag"
"fmt"
"log"
"os"
"strconv"
)
// CLI responsible for processing command line arguments
type CLI struct {
bc *Blockchain
}
func (cli *CLI) printUsage() {
fmt.Println("Usage:")
fmt.Println(" addblock -data BLOCK_DATA - add a block to the blockchain")
fmt.Println(" printchain - print all the blocks of the blockchain")
}
func (cli *CLI) validateArgs() {
if len(os.Args) < 2 {
cli.printUsage()
os.Exit(1)
}
}
func (cli *CLI) addBlock(data string) {
cli.bc.AddBlock(data)
fmt.Println("Success!")
}
func (cli *CLI) printChain() {
bci := cli.bc.Iterator()
for {
block := bci.Next()
fmt.Printf("Prev. hash: %x\n", block.PrevBlockHash)
fmt.Printf("Data: %s\n", block.Data)
fmt.Printf("Hash: %x\n", block.Hash)
pow := NewProofOfWork(block)
fmt.Printf("PoW: %s\n", strconv.FormatBool(pow.Validate()))
fmt.Println()
if len(block.PrevBlockHash) == 0 {
break
}
}
}
// Run parses command line arguments and processes commands
func (cli *CLI) Run() {
cli.validateArgs()
addBlockCmd := flag.NewFlagSet("addblock", flag.ExitOnError)
printChainCmd := flag.NewFlagSet("printchain", flag.ExitOnError)
addBlockData := addBlockCmd.String("data", "", "Block data")
switch os.Args[1] {
case "addblock":
err := addBlockCmd.Parse(os.Args[2:])
if err != nil {
log.Panic(err)
}
case "printchain":
err := printChainCmd.Parse(os.Args[2:])
if err != nil {
log.Panic(err)
}
default:
cli.printUsage()
os.Exit(1)
}
if addBlockCmd.Parsed() {
if *addBlockData == "" {
addBlockCmd.Usage()
os.Exit(1)
}
cli.addBlock(*addBlockData)
}
if printChainCmd.Parsed() {
cli.printChain()
}
}
主要包括:
- CLI结构体,含有一个指向区块链的指针
- printUsage,打印命令行使用说明
- validateArgs,验证命令行参数
- addBlock,添加一个区块(这里有点像三层架构的业务逻辑层)
- printChain,打印当前区块链
- Run,CLI函数功能选择
main.go
main函数入口
package main
func main() {
bc := NewBlockchain()
defer bc.db.Close()
cli := CLI{bc}
cli.Run()
}
运行效果
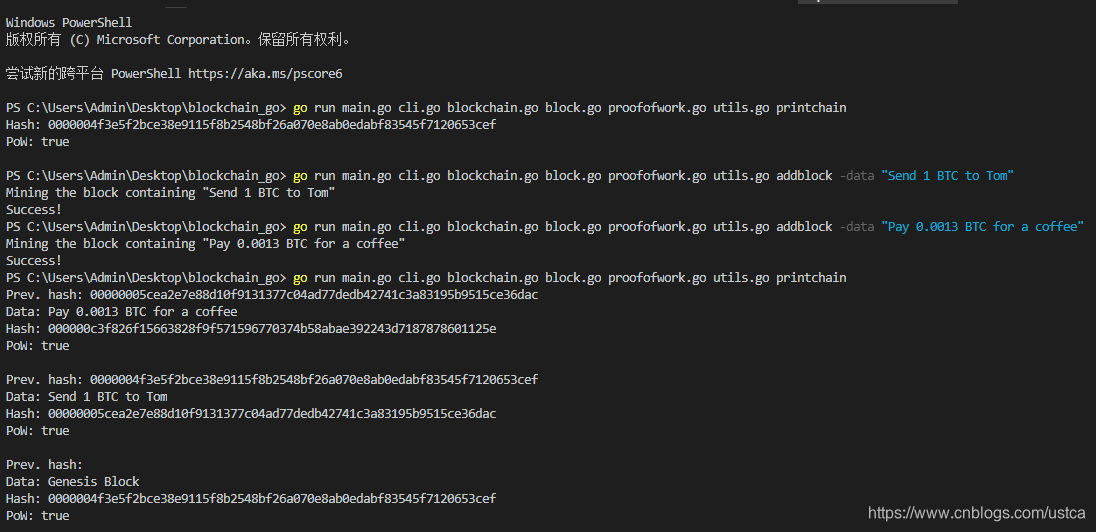
"Pay 0.0013 BTC for a coffee" 挖矿的时间比"Send 1 BTC to Tom"多了一个数量级,程序根据你的输入数据,计算哈希所需要的时间是不确定的,感兴趣的可以记录挖矿时间然后输出。(不要打印挖矿过程,io输出会让处理时间多出好几个量级,会以为是无限循环)
小结
本节实现了区块链的简易数据结构、工作量证明机制、持久化以及命令行接口。实际上核心只有proofofwork.go的工作量证明与block.go的区块链结构,所谓挖矿也只是找一个有价值的哈希值而已。但实际的区块链不仅仅只是这些,之后将会结合比特币实现交易与地址机制。之所以结合比特币实现,是因为比特币是区块链技术的一个成功Demo,并不是炒作比特币概念。再好的概念,与现有法律和监管体系不兼容,也无法成为主流。做个不恰当的类比,有点像C#与JAVA,就语言本身C#比JAVA更先进,但一涉及生态又是另一回事了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号