
数据库索引及空间优化
安装pt-query-digest,检查重复索引pt-duplicate-key-checker
安装pt-query-digest--- 源码包安装
[ ! -d /tools ] && mkdir /tools cd /tools wget percona.com/get/percona-toolkit.tar.gz tar zxf percona-toolkit.tar.gz cd percona-toolkit-3.3.1 yum -y install perl-DBD-MySQL yum -y install perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker yum -y install perl-Digest-MD5 perl Makefile.PL PREFIX=/usr/local/percona-toolkit make && make install ln -s /usr/local/percona-toolkit/bin/pt-duplicate-key-checker /usr/local/bin/
使用pt-duplicate_key-checher工具检查重复冗余索引
PTDEBUG=1 pt-duplicate-key-checker -uroot -p 'password' -h xxx.xxx.xxx.xxx -P 3306 -d xuehua_order -t order_discount > dev_xuehua_order_index_check.sql 2>&1 PTDEBUG=1 pt-duplicate-key-checker -uroot -p 'password' -h xxx.xxx.xxx.xxx -P 3306 > csyx_index_check.sql cat dev_xuehua_order_index_check.sql
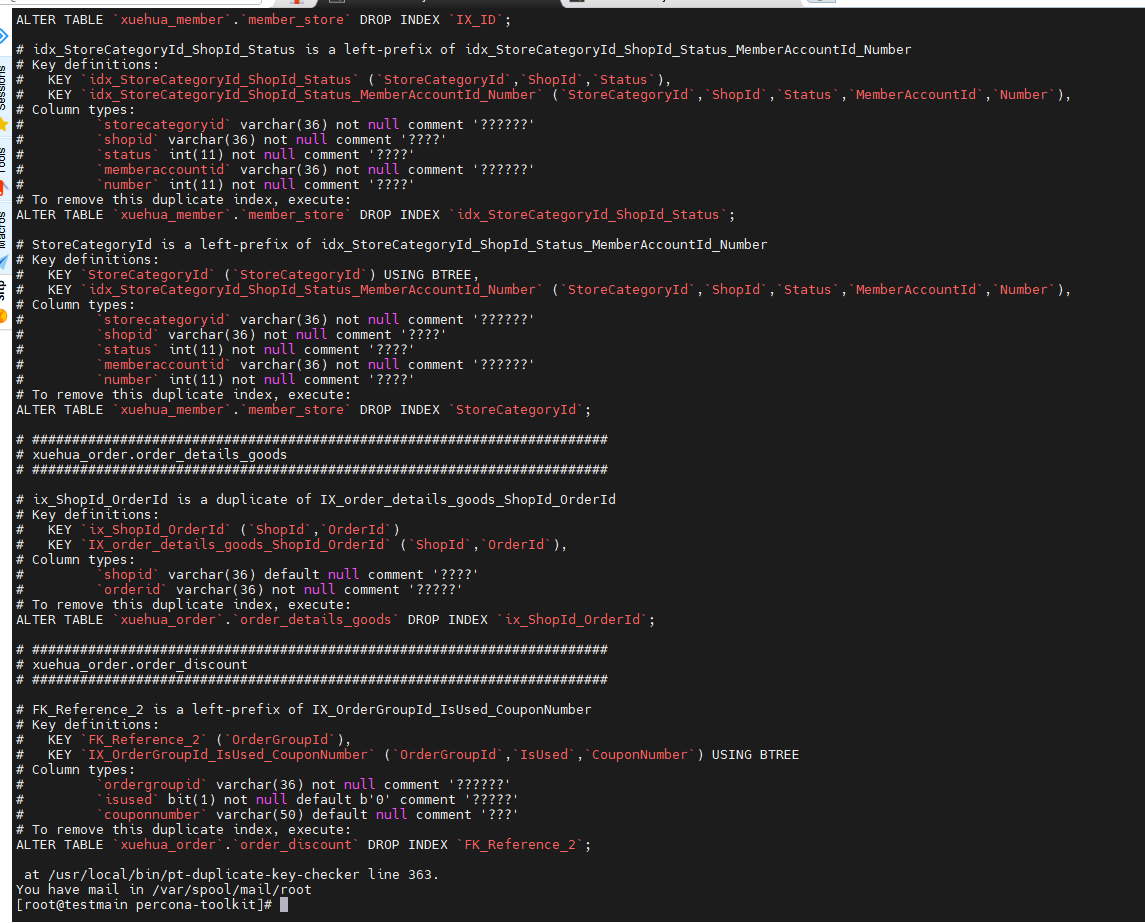
分析慢SQL
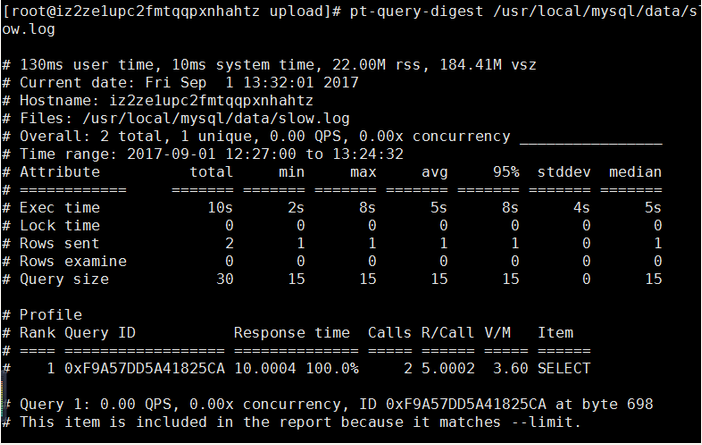
pt-query-digest /usr/local/mysql/data/slow.log
看哪些索引是不使用的,在mysql中通过慢查日志配合pt-index-usage 工具来进行索引使用情况的分析。
pt-index-usage -uroot -p'123456' mysql-slow.log
对于阿里云 mysql-slow.log 直接在rds控制台日志管理》慢日志明细查看即可,高可用版本mysql.slow_log 表会清理的。
最新的慢日志可以查看这个表,执行sql例如查看今天慢sql执行
select `start_time` ,`user_host` ,`query_time` ,`lock_time` ,`rows_sent` ,`rows_examined` ,`db` ,`last_insert_id` ,`insert_id` ,`server_id` ,cast( `sql_text` as char) ,`thread_id` from mysql.slow_log where date_format(start_time,'%Y%m%d')='20220323';
问题: 删除重复索引后,索引空间是变小了,但表空间反而还增大了,碎片率也增大了
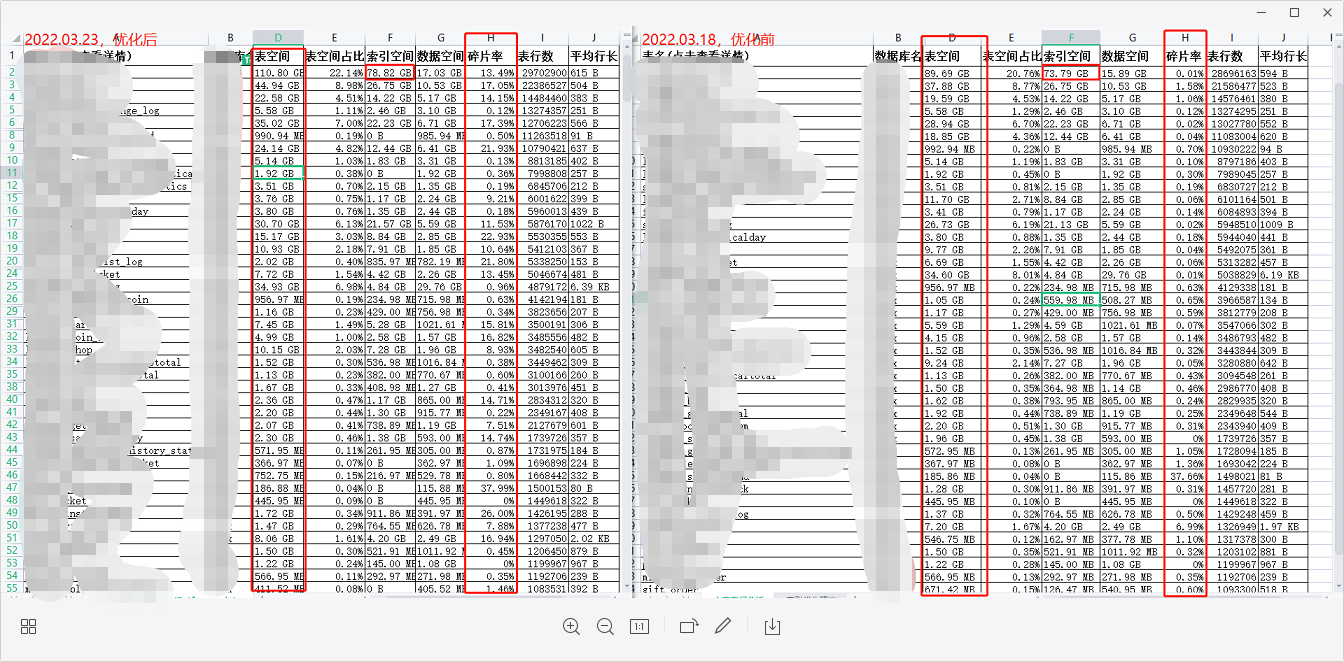
解决反馈的信息碎片率增加了
1、先执行SQL查看数据大小统计。
SELECT file_name,concat(TOTAL_EXTENTS,'MB') as 'FileSize' FROM INFORMATION_SCHEMA.FILES order by TOTAL_EXTENTS DESC limit 20;
2、然后对于大表执行 回收一下表空间(碎片整理)!!!注意会锁表
optimize table <表名>;
OPTIMIZE TABLE语句可以重新组织表、索引的物理存储,减少存储空间,提高访问的I/O效率。类似于碎片整理功能
3、然后执行SQL 重新统计表空间。
analyze table <表名>;
MySQL中analyze table的作用是?生产上操作会有什么风险?
一、analyze table的作用
1、analyze table 会统计索引分布信息。
2、对于 MyISAM 表,相当于执行了一次 myisamchk --analyze
3、支持 InnoDB、NDB、MyISAM 等存储引擎,但不支持视图(view)
4、执行 analyze table 时,会对表加上读锁(read lock)
5、该操作会记录binlog
二、生产上操作的风险
1、analyze table的需要扫描的page代价粗略估算公式:sample_pages * 索引数 * 表分区数。
2、因此,索引数量较多,或者表分区数量较多时,执行analyze table可能会比较费时,要自己评估代价,并默认只在负载低谷时执行。
3、特别提醒,如果某个表上当前有慢SQL,此时该表又执行analyze table,则该表后续的查询均会处于waiting for table flush的状态,严重的话会影响业务,因此执行前必须先检查有无慢查询。
4、在重新执行1的命令看下是否有下降
SELECT file_name,concat(TOTAL_EXTENTS,'MB') as 'FileSize' FROM INFORMATION_SCHEMA.FILES order by TOTAL_EXTENTS DESC limit 20;
原因
个人是这样理解的,当你删除数据时,mysql并不会回收已删除的数据所占据的存储空间,以及索引位。
而是空在那里,而是等待新的数据来弥补这个空缺,这样就有一个缺少,如果一时半会,没有数据来填补这个空缺,那这样就太浪费资源了。
所以对于写比较频繁的表,要定期进行optimize,一个月一次,看实际情况而定了
1、查询所有数据库占用磁盘空间大小的SQL语句
SELECT table_schema as '数据库', sum(truncate(data_length/1024/1024, 2)) as '数据容量(MB)', sum(truncate(index_length/1024/1024, 2)) as '索引容量(MB)', sum(truncate(data_free/1024/1024, 2)) as '碎片空间(MB)', sum(table_rows) as '表总行数' FROM information_schema.tables WHERE table_schema NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys') GROUP BY table_schema ORDER BY sum(data_length) DESC, sum(index_length) DESC;
2、查询所有库中所有表磁盘占用大小的SQL语句
SELECT table_schema as '数据库', table_name as '表名', truncate(data_length/1024/1024, 2) as '数据空间(MB)', truncate(index_length/1024/1024, 2) as '索引空间(MB)', truncate(data_free/1024/1024, 2) as '碎片空间(MB)', table_rows as '表行数' FROM information_schema.tables WHERE table_schema NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys') ORDER BY data_length DESC, index_length DESC;
清除碎片操作会暂时锁表,数据量越大,耗费的时间越长,可以做个脚本,定期检查MySQL中 information_schema.tables字段,查看 data_free 字段,大于0话,就表示有碎片,当大于自己认为的警戒值的话,就清理一次。
SELECT table_schema as 'table_schema', table_name as 'table_name', truncate(data_length/1024/1024, 2) as 'data_length(MB)', truncate(index_length/1024/1024, 2) as 'index_length(MB)', truncate(data_free/1024/1024, 2) as 'data_free(MB)', truncate((data_length+index_length+data_free)/1024/1024, 2) as 'total_size(MB)', table_rows as 'table_rows', truncate(data_free/(data_length+index_length+data_free), 2) as 'frag_percent' FROM information_schema.tables WHERE table_schema NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys') and data_free/(data_length+index_length+data_free) > 0.2 ORDER BY data_length+index_length+data_free DESC;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号