

ELK安装部署-ES
ELK中文社区: https://elasticsearch.cn/
部署准备工作:
准备2台机器,, 样才能完成分布式集群的实验, 当然能有更多机器更好:
• 192.168.10.11 es1.sunli.work Elasticsearch/kibana/head 2U3G
• 192.168.10.12 es2.sunli.work Elasticsearch/logstash 2U3G
角色划分:
• 2台机器全部安装jdk1.8, 因为elasticsearch是java开发的
• 2台全部安装elasticsearch (后续都简称为es)
• master节点上需要安装kibana以及head插件
• data上安装 logstash
ELK版本信息:
• Elasticsearch-6.4.1
• logstash-6.4.1
• kibana-6.4.1
• filebeat-6.4.1
所有机器做好互相解析,时间同步, 关闭防火墙, selinux
Elasticsearch
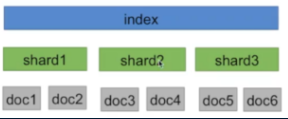
Elasticsearch可扩展性主要是通过索引分片机制来实现的,index即为索引,每个index下面又分为n个shard,真正的数据以doc的形式存储在每个shard中。
Elasticsearch的高可用主要是通过shard冗余备份、跨可用区域部署以及数据快照等方式来实现的,并能够应对集群节点故障和数据损坏。
1.布署java环境(略) - 所有节点
2.安装elasticsearch - 所有节点
创建elk用户
# useradd elk #elasticsearch不能以root用户运行,必须要创建一个普通用户运行
# echo 123|passwd --stdin elk
# tar xf elasticsearch-6.4.1.tar.gz -C /usr/local/
# ln -s /usr/local/elasticsearch-6.4.1 /usr/local/es
# chown -R elk.elk /usr/local/es/*
创建数据目录
# mkdir -p /data/es/{data,logs}
# chown -R elk.elk /data/es/
3.配置es-master
# cd /usr/local/es/
# egrep -v "^#" config/elasticsearch.yml
cluster.name: es-cluster # 集群名称,各节点配成相同的集群名称
node.name: es1 # 节点名称,各节点配置不同。
node.master: true # 指示某个节点是否符合成为主节点的条件
node.data: true # 指示节点是否为数据节点。数据节点包含并管理索引的一部分
path.data: /data/es/data # 数据存储目录
path.logs: /data/es/logs # 日志存储目录
bootstrap.memory_lock: true # 内存锁定,是否禁用交换
network.host: 0.0.0.0 # 绑定节点IP
http.port: 9200 # rest api端口
discovery.zen.ping.unicast.hosts: ["es1", "es2"] # 提供其他 Elasticsearch 服务节点的单点广播发现功能
#bootstrap.system_call_filter 系统调用过滤器。
#discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
#discovery.zen.ping_timeout 节点在发现过程中的等待时间。
#discovery.zen.fd.ping_retries 节点发现重试次数。
#http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。
#http.cors.allow-origin 允许的源地址。

关闭交换分区swap
# swapoff -a
4.配置es-data
在master的基础上作如下修改:
node.name: es2
node.master: false
node.data: true
注意: 这一步在本实验中不做, 因为我们的虚拟机本身内存就很小, 在公司服务器性能比较强悍, 为了提高es性能, 需要设置
设置JVM堆大小
# sed -i 's/-Xms1g/-Xms4g/' /es/config/jvm.options
# sed -i 's/-Xmx1g/-Xmx4g/' /usr/local/es/config/jvm.options
注意:确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。
如果系统内存足够大,将堆内存最大和最小值设置为31G,因为有一个32G性能瓶颈问题。堆内存大小不要超过系统内存的50%
5.启动服务: 先启动master, 再启动data
# su - elk
$ /usr/local/es/bin/elasticsearch -d #-d 以守护进程方式运行就没有输出了

6.验证
查看端口: es服务会监听两个端口,其中9200为传输数据用,9300为集群通信用
# netstat -tlnp |egrep ":9200|:9300"
tcp6 0 0 :::9200 :::* LISTEN 1238/java
tcp6 0 0 :::9300 :::* LISTEN 1238/java
查看服务情况:
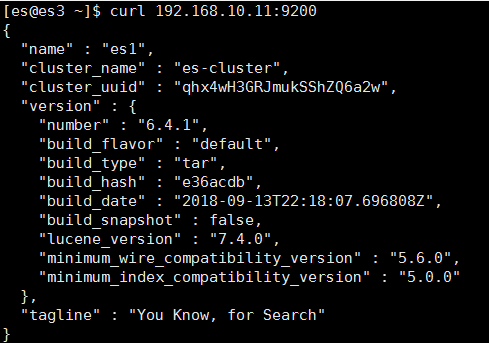
查看集群健康状况:
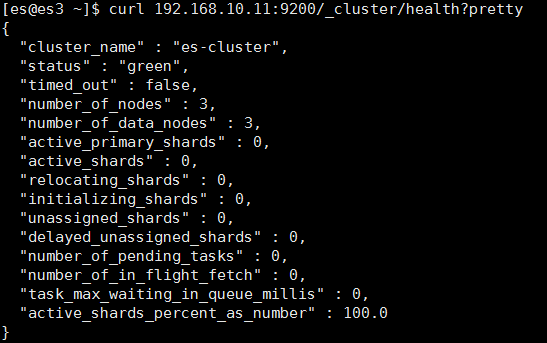
查看集群的详细信息:
# curl 192.168.10.31:9200/_cluster/state?pretty
常见问题:

解决方法: 使用普通用户运行

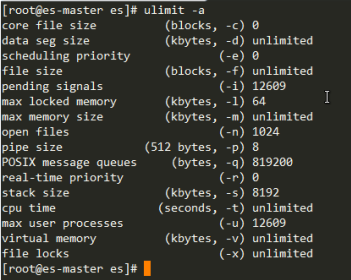
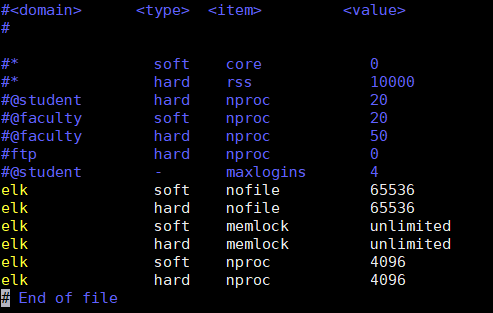
问题[1]: 进程最大可同时打开文件数太小,至少要65536
解决方法:
# echo "elk soft nofile 65536" >> /etc/security/limits.conf
# echo "elk hard nofile 65536" >> /etc/security/limits.conf
# su - elk
$ ulimit -n
65536
问题[2]: 请求锁内存失败,系统默认能让进程锁住的最大内存为64k
解决方法:
# echo "elk soft memlock unlimited" >> /etc/security/limits.conf
# echo "elk hard memlock unlimited" >> /etc/security/limits.conf
问题[3]: elk用户拥有的内存权限太小了,至少需要262114
解决方法:
# echo vm.max_map_count=262144 >> /etc/sysctl.conf
# sysctl -p
vm.max_map_count = 262144
使用curl命令操作elasticsearch:https://zhaoyanblog.com/archives/732.html
安装head插件
ElasticSearch Head是集群管理、数据可视化、增删查改、查询语句可视化工具
1.下载插件
2.安装插件
1).安装node环境
# tar xf node-v10.0.0-linux-x64.tar.gz
# mv node-v10.0.0-linux-x64 /usr/local/node
# vim /etc/profile.d/node.sh
export NODE_HOME=/usr/local/node
export NODE_PATH=$NODE_HOME/lib/node_modules
export PATH=$NODE_HOME/bin:$PATH
# . /etc/profile.d/node.sh
# node -v
v10.0.0
# unzip elasticsearch-head-master.zip
# mv elasticsearch-head-master /usr/local
# cd /usr/local/elasticsearch-head-master
# npm install -g cnpm --registry=https://registry.npm.taobao.org
/usr/local/node-v10.0.0-linux-x64/bin/cnpm -> /usr/local/node-v10.0.0-linux-x64/lib/node_modules/cnpm/bin/cnpm
+ cnpm@6.0.0
dded 679 packages in 133.133s
# cnpm install -g grunt-cli
Downloading grunt-cli to /usr/local/node-v10.0.0-linux-x64/lib/node_modules/grunt-cli_tmp
Copying /usr/local/node-v10.0.0-linux-x64/lib/node_modules/grunt-cli_tmp/_grunt-cli@1.3.2@grunt-cli to /usr/local/node-v10.0.0-linux-x64/lib/node_modules/grunt-cli
Installing grunt-cli's dependencies to /usr/local/node-v10.0.0-linux-x64/lib/node_modules/grunt-cli/node_modules
[1/5] grunt-known-options@~1.1.0 installed at node_modules/_grunt-known-options@1.1.1@grunt-known-options
[2/5] nopt@~4.0.1 installed at node_modules/_nopt@4.0.1@nopt
[3/5] interpret@~1.1.0 installed at node_modules/_interpret@1.1.0@interpret
[4/5] v8flags@~3.1.1 installed at node_modules/_v8flags@3.1.2@v8flags
[5/5] liftoff@~2.5.0 installed at node_modules/_liftoff@2.5.0@liftoff
All packages installed (124 packages installed from npm registry, used 8s(network 8s), speed 104.17kB/s, json 110(132.74kB), tarball 724.09kB)
[grunt-cli@1.3.2] link /usr/local/node-v10.0.0-linux-x64/bin/grunt@ -> /usr/local/node-v10.0.0-linux-x64/lib/node_modules/grunt-cli/bin/grunt
# grunt -version
grunt-cli v1.3.1
# cnpm install

# vim Gruntfile.js
connect: {
server: {
options: {
hostname: '192.168.10.11',
port: 9100,
base: '.',
keepalive: true
}
}
}
3.修改es配置文件并重启es服务(两台机器都需配置)
# vim /usr/local/es/config/elasticsearch.yml
......
http.cors.enabled: true #允许http跨域访问
http.cors.allow-origin: "*" #将这两行添加到配置文件中去
重启ES服务
3.启动服务
# grunt server
浏览器访问9100端口
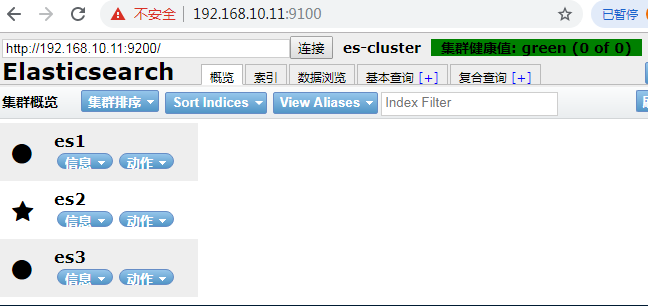
es集群中的角色
Master Node
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。
当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。
稳定的主节点对集群的健康是非常重要的, 为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。
为了防止脑裂,常常设置参数为discovery.zen.minimum_master_nodes=N/2+1,其中N为集群中Master节点的个数。
建议集群中Master节点的个数为奇数个,如3个或者5个。
设置一个节点为Master节点的方式如下:
node.master: true
Data Node
主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。
数据节点对cpu,内存,io要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
建议和Master节点分开,避免因为Data Node节点出问题影响到Master节点。
设置一个节点为Data Node节点的方式如下:
node.data: true
Client Node
当以上两个参数都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。
独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
建议
在一个生产集群中我们可以对这些节点的职责进行划分:
• 集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态;
• 根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务;
• 如果用户请求比较频繁,在集群中建议再设置一批client节点,这些节点只负责处理用户请求,实现请求转发,负载均衡等功能, 以减轻data节点的压力
kibana
kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,, 是一个开源和免费的工具
Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面, 可以帮你汇总、分析和搜索重要数据日志
1.安装
# tar xf kibana-6.4.1-linux-x86_64.tar.gz -C /usr/local
# ln-s /usr/local/kibana-6.4.1-linux-x86_64 /usr/local/kibana
2.配置
# cd /usr/local/kibana/
# egrep -v "^#|^$" config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.10.11:9200"
logging.dest: /usr/local/kibana/logs
3.启动服务
# /usr/local/kibana/bin/kibana &
4.查看:
# netstat -tanp |grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 1460/node
* kibana是使用node.js开发的, 所以进程名称为node
5.浏览器访问
# firefox 192.168.10.31:5601 &

 浙公网安备 33010602011771号
浙公网安备 33010602011771号