
python练习-爬虫
场景:
1、网址hppt://xxx.yyy.zzz.cn2、打开网页后显示 :

3、填上姓名 身份证和验证码,点击查询后,返回查询结果。

4、页面有cookie。
方案一:
- 程序中嵌入浏览器根据网址打开得到页面,
- 然后程序读取记录自动填写数据,
- 程序截取验证码图片,然后解析,并且填入验证码
- 然后程序点击查询得到查询页面,
- 再从查询结果页面DOM解析得到相关数据
方案二:
采用Python。真是牛逼得一塌糊涂。
import requests
from PIL import Image
import pytesseract
# 获取cookie
session = requests.Session()
response = session.get("http://example.com")
cookie = response.cookies.get_dict()
# 发送HTTP请求,获取响应数据
headers = {
"Cookie": "; ".join([f"{key}={value}" for key, value in cookie.items()]),
}
response = session.get("http://example.com", headers=headers)
content = response.text
# 解析响应数据,获取验证码URL
start_position = content.find('<img src="/verifyCode')
end_position = content.find('"', start_position + 10)
captcha_url = 'http://example.com' + content[start_position + 10:end_position]
# 发送带cookie的HTTP请求,获取验证码的二进制数据
response = session.get(captcha_url, headers=headers)
captcha_data = response.content
# 将二进制图片保存为本地文件
with open('captcha.png', 'wb') as f:
f.write(captcha_data)
 # 识别图片中的文字
image = Image.open('captcha.png')
code = pytesseract.image_to_string(image)
# 打印验证码内容
print("验证码内容:", code)
# 识别图片中的文字
image = Image.open('captcha.png')
code = pytesseract.image_to_string(image)
# 打印验证码内容
print("验证码内容:", code)
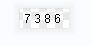
# 7386
至此,关键问题得到解决。
注意得问题:
1、安装requests
2、安装PIL
3、安装pytesseract。其中要另外单独安装与pytesseract配套的Python的OCR识别库。
4.1下载OCR识别库地址 https://digi.bib.uni-mannheim.de/tesseract/
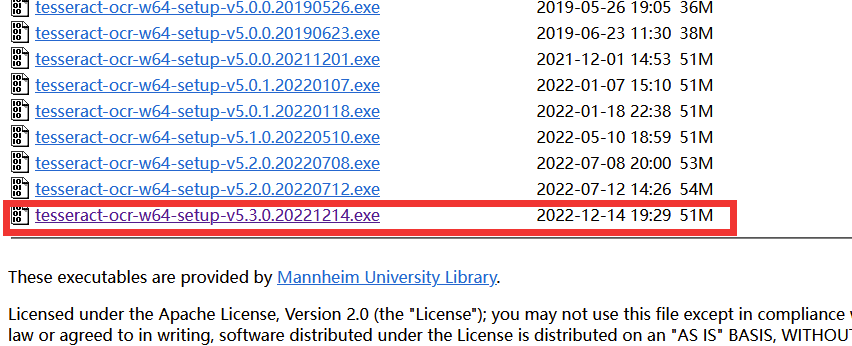
根据你系统进行选择。
4.2下载OCR安装识别库
其中:
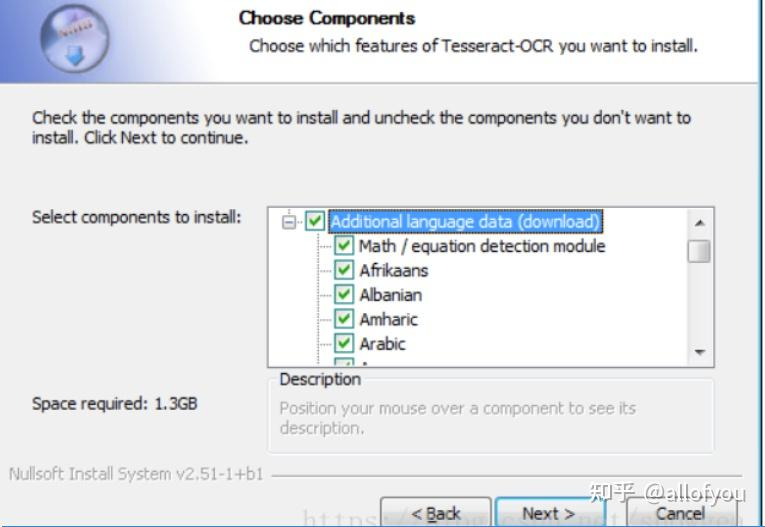
4.3配置OCR路径:
4.3.1看一下你安装得目录。如:D:\Program Files\Tesseract-OCR\tesseract.exe
4.3.2系统环境变量中,把D:\Program Files\Tesseract-OCR\tesseract.exe配置进去。
4.4.找到脚本文件 pytesseract.py。编辑修改:
tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
from os import remove
from os.path import normcase
from os.path import normpath
from os.path import realpath
from pkgutil import find_loader
from tempfile import NamedTemporaryFile
from time import sleep
from packaging.version import InvalidVersion
from packaging.version import parse
from packaging.version import Version
from PIL import Image
tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
numpy_installed = find_loader('numpy') is not None
if numpy_installed:
from numpy import ndarray
pandas_installed = find_loader('pandas') is not None
if pandas_installed:
import pandas as pd
DEFAULT_ENCODING = 'utf-8'
5.可能出现得问题:
常见问题:FileNotFoundError:[WinError 2]系统找不到指定文件。
解决办法:
打开文件pytesseract.py,找到如下代码,将tesseract_cmd的值修改为全路径,再次使用就不会报这个错了。
没了,goodluck!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号