
PG的递归
WITH RECURSIVE "CTE" AS( SELECT m."Exp_No",m."Exp_Code",m."Exp_Name",m."Exp_PCode" --,m."Exp_PCode" AS "Root" FROM "ExpenseManagement"."ExpList" m WHERE m."Exp_Code" = '1020101' --m."Exp_PCode" is NULL or m."Exp_PCode"='' -- m."Exp_IfUse" IS TRUE UNION ALL SELECT k."Exp_No",k."Exp_Code",k."Exp_Name",k."Exp_PCode"--,(k."Exp_PCode"||s."Exp_PCode") AS "Root" FROM "ExpenseManagement"."ExpList" k INNER JOIN "CTE" s ON s."Exp_PCode" = k."Exp_Code" -- WHERE s."Exp_PCode" = k."Exp_Code" --AND k."Exp_Code" = '1020101' ) SELECT * FROM "CTE"
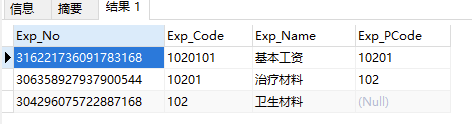
上面语句得到1020101编码从下到顶的递归结果:
希望得到1020101的顶级父编码 WITH RECURSIVE "CTE" AS( SELECT m."Exp_No",m."Exp_Code",m."Exp_Name",m."Exp_PCode" --,m."Exp_PCode" AS "Root" FROM "ExpenseManagement"."ExpList" m WHERE m."Exp_Code" = '1020101' --m."Exp_PCode" is NULL or m."Exp_PCode"='' -- m."Exp_IfUse" IS TRUE UNION ALL SELECT k."Exp_No",k."Exp_Code",k."Exp_Name",k."Exp_PCode"--,(k."Exp_PCode"||s."Exp_PCode") AS "Root" FROM "ExpenseManagement"."ExpList" k INNER JOIN "CTE" s ON s."Exp_PCode" = k."Exp_Code" -- WHERE s."Exp_PCode" = k."Exp_Code" --AND k."Exp_Code" = '1020101' ) SELECT * FROM "CTE" WHERE "Exp_PCode" is NULL

SELECT e1."CT_ID" AS "ID", e1."CT_Date" AS "日期", e1."CT_No" AS "单据号", e1."CT_Memo" AS "备注", e1."CT_ZDR" AS "制单人", e1."CT_CheckAccount" AS "记账", e2."CTD_Key" AS "费用明细ID", e2."CTD_CostCode" AS "费用代码", e2."CTD_CostName" AS "费用名称", e2."CTD_Summary" AS "摘要", e3."Exp_DRGAttr" AS "是否费用成本", e3."Exp_ApportionSign" AS "分摊标志", e2."CTD_DeptCode" AS "科室代码", e2."CTD_DeptName" AS "科室名称", e2."CTD_QTY" AS "数量", e2."CTD_Price" AS "单价", e2."CTD_AMT" AS "金额", ( WITH RECURSIVE "CTE" AS( SELECT m."Exp_No",m."Exp_Code",m."Exp_Name",m."Exp_PCode" --,m."Exp_PCode" AS "Root" FROM "ExpenseManagement"."ExpList" m WHERE m."Exp_Code" = e2."CTD_CostCode" -- '1020101' --m."Exp_PCode" is NULL or m."Exp_PCode"='' -- m."Exp_IfUse" IS TRUE UNION ALL SELECT k."Exp_No",k."Exp_Code",k."Exp_Name",k."Exp_PCode"--,(k."Exp_PCode"||s."Exp_PCode") AS "Root" FROM "ExpenseManagement"."ExpList" k INNER JOIN "CTE" s ON s."Exp_PCode" = k."Exp_Code" -- WHERE s."Exp_PCode" = k."Exp_Code" --AND k."Exp_Code" = '1020101' ) SELECT "Exp_Code" FROM "CTE" WHERE "Exp_PCode" is NULL ) AS "RootCode", ( WITH RECURSIVE "CTE" AS( SELECT m."Exp_No",m."Exp_Code",m."Exp_Name",m."Exp_PCode" --,m."Exp_PCode" AS "Root" FROM "ExpenseManagement"."ExpList" m WHERE m."Exp_Code" = e2."CTD_CostCode" -- '1020101' --m."Exp_PCode" is NULL or m."Exp_PCode"='' -- m."Exp_IfUse" IS TRUE UNION ALL SELECT k."Exp_No",k."Exp_Code",k."Exp_Name",k."Exp_PCode"--,(k."Exp_PCode"||s."Exp_PCode") AS "Root" FROM "ExpenseManagement"."ExpList" k INNER JOIN "CTE" s ON s."Exp_PCode" = k."Exp_Code" -- WHERE s."Exp_PCode" = k."Exp_Code" --AND k."Exp_Code" = '1020101' ) SELECT "Exp_Name" FROM "CTE" WHERE "Exp_PCode" is NULL ) AS "RootName" FROM "ExpenseManagement"."Expense1" e1, "ExpenseManagement"."Expense2" e2 LEFT JOIN "ExpenseManagement"."ExpList" e3 ON e2."CTD_CostCode" = e3."Exp_Code" AND e3."Exp_IfUse" IS TRUE --启用的费用代码 WHERE e1."CT_ID" = e2."CT_ID" AND e3."Exp_DRGAttr" IS TRUE AND NOT NOT e1."CT_CheckAccount" is NULL OR e1."CT_CheckAccount" <> '' --已经记账标志的记录
结果:

详细介绍感谢请看https://www.cnblogs.com/oxspirt/p/13962347.html。比较详细,也很精彩。总感觉SQL Server的SQL语句很强大方便,不知道现在认为更强大的是PG!?
做个复习。
WITH提供了一种方式来书写在一个大型查询中使用的辅助语句。这些语句通常被称为公共表表达式或CTE,它们可以被看成是定义只在一个查询中存在的临时表。
在WITH子句中的每一个辅助语句可以是一个SELECT、INSERT、UPDATE或DELETE,并且WITH子句本身也可以被附加到一个主语句,主语句也可以是SELECT、INSERT、UPDATE或DELETE。
CTE or WITH
WITH语句通常被称为通用表表达式(Common Table Expressions)或者CTEs。
WITH语句作为一个辅助语句依附于主语句,WITH语句和主语句都可以是SELECT,INSERT,UPDATE,DELETE中的任何一种语句。
WITH result AS ( SELECT d.user_id FROM documents d GROUP BY d.user_id ),info as( SELECT t.*,json_build_object('id', ur.id, 'name', ur.name) AS user_info FROM result t LEFT JOIN users ur on ur.id = t.user_id WHERE ur.id IS NOT NULL )select * from info
定义了两个WITH辅助语句,result和info。result查询出符合要求的user信息,然后info对这个信息进行组装,组装出我们需要的数据信息。
当然不用这个也是可以的,不过CTE主要的还是做数据的过滤。什么意思呢,我们可以定义多层级的CTE,然后一层层的查询过滤组装。最终筛选出我们需要的数据,当然你可能会问为什么不一次性拿出所有的数据呢,当然如果数据很大,我们通过多层次的数据过滤组装,在效率上也更好。
WITH moved_rows AS ( DELETE FROM products WHERE "date" >= '2010-10-01' AND "date" < '2010-11-01' RETURNING * ) INSERT INTO products_log SELECT * FROM moved_rows;
本例通过WITH中的DELETE语句从products表中删除了一个月的数据,并通过RETURNING子句将删除的数据集赋给moved_rows这一CTE,
最后在主语句中通过INSERT将删除的商品插入products_log中。
WITH t AS ( UPDATE products SET price = price * 1.05 RETURNING * ) SELECT * FROM products;
外层SELECT可以返回在UPDATE动作之前的原始价格
WITH t AS ( UPDATE products SET price = price * 1.05 RETURNING * ) SELECT * FROM t;
外部SELECT将返回更新过的数据
WITH使用注意事项
1、WITH中的数据修改语句会被执行一次,并且肯定会完全执行,无论主语句是否读取或者是否读取所有其输出。而WITH中的SELECT语句则只输出主语句中所需要记录数。
2、WITH中使用多个子句时,这些子句和主语句会并行执行,所以当存在多个修改子语句修改相同的记录时,它们的结果不可预测。
3、所有的子句所能“看”到的数据集是一样的,所以它们看不到其它语句对目标数据集的影响。这也缓解了多子句执行顺序的不可预测性造成的影响。
4、如果在一条SQL语句中,更新同一记录多次,只有其中一条会生效,并且很难预测哪一个会生效。
5、如果在一条SQL语句中,同时更新和删除某条记录,则只有更新会生效。
6、目前,任何一个被数据修改CTE的表,不允许使用条件规则,和ALSO规则以及INSTEAD规则。
RECURSIVE
可选的RECURSIVE修饰符将WITH从单纯的句法便利变成了一种在标准SQL中不能完成的特性。通过使用RECURSIVE,一个WITH查询可以引用它自己的输出。
比如下面的这个表:
create table document_directories ( id bigserial not null constraint document_directories_pk primary key, name text not null, created_at timestamp with time zone default CURRENT_TIMESTAMP not null, updated_at timestamp with time zone default CURRENT_TIMESTAMP not null, parent_id bigint default 0 not null ); comment on table document_directories is '文档目录'; comment on column document_directories.name is '名称'; comment on column document_directories.parent_id is '父级id'; INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (1, '中国', '2020-03-28 15:55:27.137439', '2020-03-28 15:55:27.137439', 0); INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (2, '上海', '2020-03-28 15:55:40.894773', '2020-03-28 15:55:40.894773', 1); INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (3, '北京', '2020-03-28 15:55:53.631493', '2020-03-28 15:55:53.631493', 1); INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (4, '南京', '2020-03-28 15:56:05.496985', '2020-03-28 15:56:05.496985', 1); INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (5, '浦东新区', '2020-03-28 15:56:24.824672', '2020-03-28 15:56:24.824672', 2); INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (6, '徐汇区', '2020-03-28 15:56:39.664924', '2020-03-28 15:56:39.664924', 2); INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (7, '漕宝路', '2020-03-28 15:57:14.320631', '2020-03-28 15:57:14.320631', 6);
这是一个无限级分类的列表,我们制造几条数据,来分析下RECURSIVE的使用。
WITH RECURSIVE res AS ( SELECT id, name, parent_id FROM document_directories WHERE id = 5 UNION SELECT dd.id, dd.name || ' > ' || d.name, dd.parent_id FROM res d INNER JOIN document_directories dd ON dd.id = d.parent_id ) select * from res 当然这个sql也可以这样写 WITH RECURSIVE res(id, name, parent_id) AS ( SELECT id, name, parent_id FROM document_directories WHERE id = 5 UNION SELECT dd.id, dd.name || ' > ' || d.name, dd.parent_id FROM res d INNER JOIN document_directories dd ON dd.id = d.parent_id ) select * from res

递归查询的过程
这是pgsql操作文档中的描述:
1、计算非递归项。对UNION(但不对UNION ALL),抛弃重复行。把所有剩余的行包括在递归查询的结果中,并且也把它们放在一个临时的工作表中。
2、只要工作表不为空,重复下列步骤:
a计算递归项,用当前工作表的内容替换递归自引用。对UNION(不是UNION ALL),抛弃重复行以及那些与之前结果行重复的行。将剩下的所有行包括在递归查询的结果中,并且也把它们放在一个临时的中间表中。
b用中间表的内容替换工作表的内容,然后清空中间表。
拆解下执行的过程
其实执行就分成了两部分:
1、non-recursive term(非递归部分),即上例中的union前面部分
2、recursive term(递归部分),即上例中union后面部分
拆解下我们上面的sql
1、执行非递归部分 SELECT id, name, parent_id FROM document_directories WHERE id = 5 结果集和working table为 5 浦东新区 2 2、执行递归部分,如果是UNION,要用当前查询的结果和上一个working table的结果进行去重,然后放到到临时表中。然后把working table的数据替换成临时表里面的数据。 SELECT dd.id, dd.name || ' > ' || d.name, dd.parent_id FROM res d INNER JOIN document_directories dd ON dd.id = d.parent_id 结果集和working table为 2 上海 > 浦东新区 1 3、同2,直到数据表中没有数据。 SELECT dd.id, dd.name || ' > ' || d.name, dd.parent_id FROM res d INNER JOIN document_directories dd ON dd.id = d.parent_id 结果集和working table为 1 中国 > 上海 > 浦东新区 0 4、结束递归,将前几个步骤的结果集合并,即得到最终的WITH RECURSIVE的结果集 严格来讲,这个过程实现上是一个迭代的过程而非递归,不过RECURSIVE这个关键词是SQL标准委员会定立的,所以PostgreSQL也延用了RECURSIVE这一关键词。
WITH RECURSIVE 使用限制 1、 如果在recursive term中使用LEFT JOIN,自引用必须在“左”边 2、 如果在recursive term中使用RIGHT JOIN,自引用必须在“右”边 3、 recursive term中不允许使用FULL JOIN 4、 recursive term中不允许使用GROUP BY和HAVING 5、 不允许在recursive term的WHERE语句的子查询中使用CTE的名字 6、 不支持在recursive term中对CTE作aggregation 7、 recursive term中不允许使用ORDER BY 8、 LIMIT / OFFSET不允许在recursive term中使用 9、 FOR UPDATE不可在recursive term中使用 10、 recursive term中SELECT后面不允许出现引用CTE名字的子查询 11、 同时使用多个CTE表达式时,不允许多表达式之间互相访问(支持单向访问) 12、 在recursive term中不允许使用FOR UPDATE
CTE 优缺点 1、 可以使用递归 WITH RECURSIVE,从而实现其它方式无法实现或者不容易实现的查询 2、 当不需要将查询结果被其它独立查询共享时,它比视图更灵活也更轻量 3、 CTE只会被计算一次,且可在主查询中多次使用 4、 CTE可极大提高代码可读性及可维护性 5、 CTE不支持将主查询中where后的限制条件push down到CTE中,而普通的子查询支持
UNION与UNION ALL的区别 UNION用的比较多union all是直接连接,取到得是所有值,记录可能有重复 union 是取唯一值,记录没有重复 1、UNION 的语法如下: [SQL 语句 1] UNION [SQL 语句 2] 2、UNION ALL 的语法如下: [SQL 语句 1] UNION ALL [SQL 语句 2] UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。 1、对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。 2、对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。 从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
-
UNION去重且排序
-
UNION ALL不去重不排序(效率高)
总结
recursive是pgsql中提供的一种递归的机制,比如当我们查询一个完整的树形结构使用这个就很完美,但是我们应该避免发生递归的死循环,也就是数据的环状。当然他只是cte中的一个查询的属性,对于cte的使用,我们也不能忽略它需要注意的地方,使用多个子句时,这些子句和主语句会并行执行。我们是不能判断那个将会被执行的,在一条SQL语句中,更新同一记录多次,只有其中一条会生效,并且很难预测哪一个会生效。当然功能还是很强大的,WITH语句和主语句都可以是SELECT,INSERT,UPDATE,DELETE中的任何一种语句,我们可以组装出我们需要的任何操作的场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号