

Hadoop单机模式
测试用软件
SecureCRT&SecureFX
VMware Workstation 16.1.2 Pro for Windows
CentOS Linux release 7.9.2009 (Core)
1.安装JDK
1.1 下载解压
tar zxf jdk-8u151-linux-x64.tar.gz -C /usr/local/src
mv jdk-8u151-linux-x64 java
1.2 添加环境变量
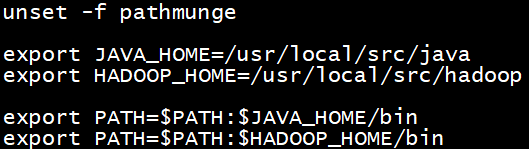
export JAVA_HOME=/usr/local/src/java
export PATH=$PATH:$JAVA_HOME/bin
source /etc/prifile
java -version
2.安装Hadoop
1.1 下载解压
tar zxf hadoop-3.4.0.tar.gz -C /usr/local/src/
mv hadoop-3.4.0 hadoop
1.2 添加环境变量
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/prifile
hadoop version
最终/etc/profile尾部是这个样子的:
3.测试
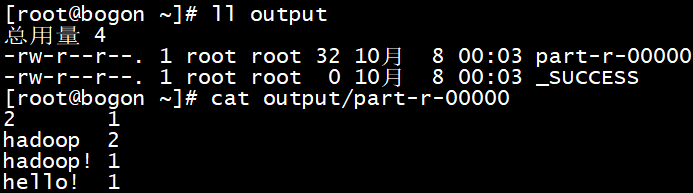
3.1 创建input/data.txt文件输入以下内容
hadoop!
hadoop hello!
hadoop 2
3.2 运行测试用例
hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar wordcount input/data.txt output
结果如图:
jar *.jar wordcount 是jar包的运行格式,指定jar包 包名 主类
可以输入多个文件
输出目录必须不存在
ps:
开启虚拟机前检查主机环境
1.网络适配器中VMware Virtual Ethernet Adapter for VMnet8是否开启
2.虚拟网络编辑器中的VMnet8下子网IP是否与虚拟机DHCP分配到的ip地址在同一网段(前三个字段一致)
3.虚拟机是否开启网络连接
虚拟机查询IP命令:ip a
pps:
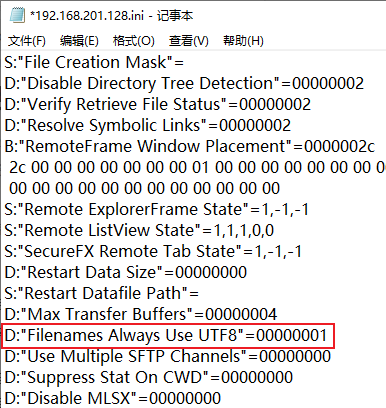
secureFX已经设置UTF-8显示中文时仍然乱码
参考路径:E:\SecureCRT\Data\Settings\Config\Sessions
安装路径下找到你的虚拟机ip.ini作如下修改后重启secureFX
原文链接:
https://blog.csdn.net/baochanghong/article/details/51506271#:~:text=secureFX
p*4s:
SecureCRT设置字符编码及改变字体大小
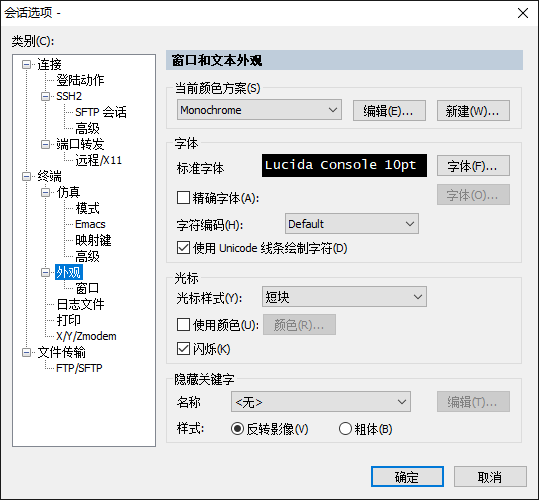
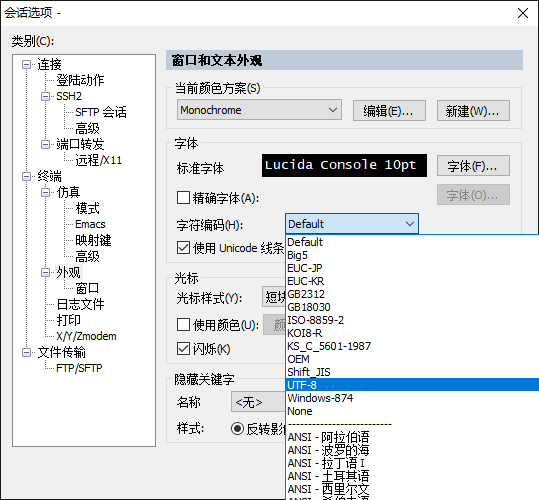
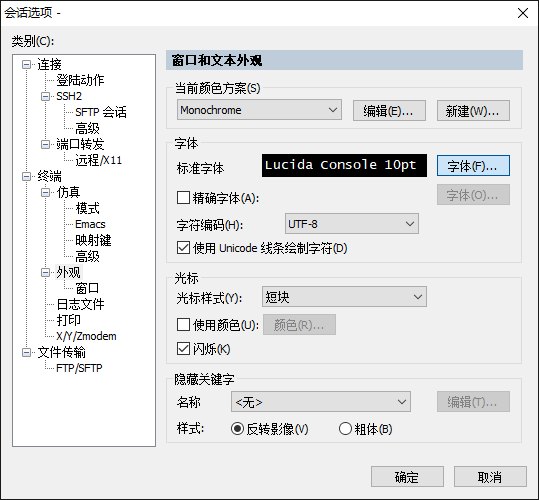
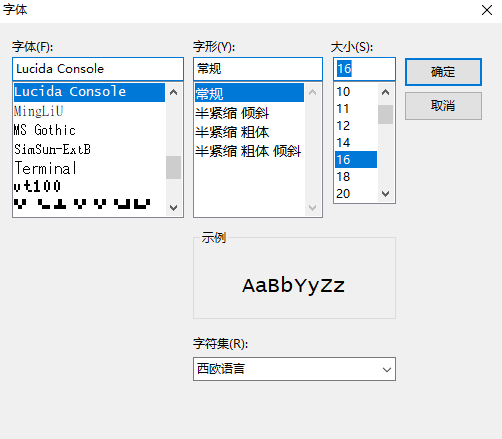
p*5s:
可以分别依次进入/opt/software和/usr/local/src/,然后cd -快速切换工作目录
脚本:
点击查看代码
#清除
cd /usr/local/src
rm -rf /usr/local/src/hadoop*
sed -i '/^export HADOOP_HOME=.*/d' /etc/profile
sed -i '/^export PATH=$PATH:$HADOOP_HOME.*/d' /etc/profile
rm -rf /root/input
if test -d /root/output;then
rm -rf /root/output/
fi
#解压
cd /opt/software
tar -zxf hadoop-2.7.6.tar.gz -C /usr/local/src
cd /usr/local/src
mv /usr/local/src/hadoop-2.7.6 /usr/local/src/hadoop
#添加全局
echo export HADOOP_HOME=/usr/local/src >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin;$HADOOP_HOME/sbin' >> /etc/profile
#配置
#告诉Hadoop java在哪里
cd /usr/local/src/hadoop/etc/hadoop
sed -i '/# The java implementation to use./,/# The jsvc implementation to use. Jsvc is required to run secure datanodes/{/export JAVA_HOME=${JAVA_HOME}/d}' /usr/local/src/hadoop/etc/hadoop/hadoop-env.sh
sed -i '/# The java implementation to use./aexport JAVA_HOME=/usr/local/src/java/' /usr/local/src/hadoop/etc/hadoop/hadoop-env.sh
#测试
cd /root/
mkdir /root/input
cd /root/input
touch /root/input/data.txt
echo Hello World >> /root/input/data.txt
echo Hello Hadoop >> /root/input/data.txt
echo Hello Java >> /root/input/data.txt
cd /root/
hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /root/input/data.txt /root/output/



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)