第九篇:python函数
什么是函数
组织好的、可重复使用的、用户实现单一或者关联功能的代码段。函数能够提高应用的模块性和代码的重复利用率。使得python代码的组织结构清晰,可读性强,解决代码冗余,实现某功能的代码可统一管理且易于维护。Python提供了很多内置的函数,比如len()、print()等等,另外也可以根据自己的业务需求进行用户自定义函数的创建。
定义函数
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。
函数的第一行语句可以选择性地使用文档字符串---用于存放函数说明。
函数内容以冒号起始,并且缩进。
语法:def 函数名(用逗号隔开的形参):
'''函数说明'''
要封装的代码块
a = 1 print(a.__class__) print(issubclass(a.__class__, object)) # all objects in Python inherit from a common baseclass def foo(): pass print(foo.__class__) print(issubclass(foo.__class__, object)) ''' 输出结果: <class 'int'> True <class 'function'> True '''
可以看到foo和变量a一样,都是顶级父类object的子类。a是一个int变量,foo是一个函数。所以,函数和python的其他东西一样,都属于对象,其父类是object。这意味着,函数可以被引用,可以当作参数传递,可以当作返回值,可以当作容器类型的元素。
调用函数
函数使用的原则:先定义,再调用,调用一个函数需要知道函数的名称和函数的参数。函数名后面接着圆括号(),需要传入的参数写在圆括号()里。函数名其实就是指向一个函数对象的引用,完全可以把函数名赋值给一个变量,相当于给这个函数起了一个别名。
语法:函数名(用逗号隔开的实参)
#定义函数 def xAddY(x,y): print('x + y = {}'.format(x+y)) #调用函数 str1 = 'abc' str2 = 'def' xAddY(str1,str2) a = xAddY a(2,3)
函数在定义时,只检测语法,不执行代码。函数在被调用时,才会执行被它封装的代码块。也就说。语法错误在函数定义阶段就会被检测出来,而代码的逻辑错误在执行时才会知道。
#定义函数 def xAddY(): x = 1 y = '2' print('x + y = {}'.format(x+y)) #整数和字符串相加是代码逻辑的错误。 print('函数xAddY()不被调用,运行代码不会报错,若调用函数xAddY(),函数里的x和y不是同类型数据,执行到x+y时就会报错。') # xAddY()
函数参数
形参与实参
形参变量只有在函数被调用时才分配内存单元,调用结束时,立刻释放所分配的内存单元,因此,形参只在函数内部有效。
实参可以是常量、变量、表达式、函数等、无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传递给形参。
形参即变量名,实参即变量值,函数调用时,将值绑定到变量名上,函数调用结束,解除绑定。

函数参数分类
必备参数(位置参数,关键字参数)
函数定义中允许拥有多个形参。函数在定义时按照从左到右的顺序定义没有默认值的参数,在调用的时,就必须传入多少个实参,这样的形参就是必备参数。
向函数传递参数的方式有很多,通过实参和形参的顺序对应,这样的传参方式叫做位置传参。必选参数就是位置形参,按照位置给形参传值的实参就是位置实参。只有位置一致,才能被正确匹配。位置实参是最简单也最常用的关联方式。
按照key=value的形式定义的实参,叫做关键字实参,这种传参方式就是关键字传参,无需按照位置给形参传值。关键字实参是传递给函数的名称-值对。直接在实参中将名称和值关联起来,因此向函数传递实参时不会混淆。函数调用使用关键字参数来确定传入的值。使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为Python解释器能够用参数名匹配参数值。
注意:在给函数传参时,关键字实参必须在位置实参右边,同一个形参不能重复传值。
#函数定义 def test(left,centre,right): print('{}在左边,{}在中间,{}在右边。'.format(left,centre,right)) #位置传参 test('小猫','小猪','小狗') #关键字传参 test(right='小狗',left='小猫',centre='小猪') #位置传参+关键字传参 test('小猫',right='小狗',centre='小猪') #关键字实参在位置实参右边,位置实参对象的形参,不能再通过关键字传值。 #错误的传参 # test(left='小猫','小猪',right='小狗') # test('小猫',left='xiaomao',centre='小猪',right='小狗')
默认参数
函数定义的时候,设置的参数是形参。那么也可以给每个形参指定一个默认值。当调用函数时,如果没有传入实参,就使用形参的默认值。如果调用的时候传入了实参,那么程序将使用传入的实参。
注意:函数在定义时,默认参数在必备参数的右边。
#函数定义 def example(left,right,centre='小鸡'): #必备参数在默认参数左边。 print('{}在左边,{}在中间,{}在右边。'.format(left,centre,right)) example('小猫','小狗') #未给默认参数传值 example('小猫','小狗','小猪') #通过位置实参传值给默认参数
不定长参数(参数组)
你可能需要一个函数能处理比当初声明时更多的参数,即传入实参不固定。这些参数叫做不定长参数。定义函数时加了星号(*)的变量名会存放所有未命名的变量参数(通常使用*agrs)。加了(**)会存放所有命名的变量参数(通常使用**kwargs)。在元祖或列表前加*作为参数传值,叫做未命名的可变长参数,未命名的可变长参数通过位置传参给必备参数和默认参数传参,多余的参数存放在函数里加了*的形参。字典前加**作为参数传值,叫做命名的可变长参数,命名的可变长参数通过关键字传参,字典的键对应形参名,然后给形参参值,多余的参数存放在函数里加了**的形参里。
关于不定长参数:*args在左边,**kwargs在右边。
#函数定义
def foo(x,*var): #不定长参必须在必备参数的右边
print('必备参数x:{}'.format(x))
print('其他传入的参数:{}'.format(var),end='\n'*2)
def bar(y,z=None,*var,**kwvar): #命名的不定长参必须在默认参数的右边
print('必备参数y:{}'.format(y))
print('默认参数z:{}'.format(z))
print('其他传入的未命名参数:{}'.format(var))
print('其他传入的命名实参:{}'.format(kwvar),end='\n'*2)
#不定长参的传值方式一
foo(3,4,5,6,'sf')
bar(3,a=2,b=3)
#不定长参的传值方式二:给未命名不定长参传入一个前面加*的列表,给命名不定长参传入一个前面加**字典
foo(3,*[4,5,6,'sf'])
bar(*(3,4,5,6),**{'a':2,'b':3})
无论是定义函数,还是调用函数,做好的参数顺序写法是(位置参数,*args,默认参数 | 关键字实参,**kwargs)。
函数参数--可变对象与不可变对象(传递的时候)
不可变类型数据与可变类型数据传递参数的区别可参考:引用传递与值传递
不可变类型:如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
可变类型:如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响。
#函数定义 def test(var): if isinstance(var,str): var += 'str' elif isinstance(var,list): var += [5,68,9] str1 = 'abc' #不可变类型的代表 list1 = [1,2,3] #可变类型的代表 test(str1) test(list1) print(str1) print(list1)
函数返回值
函数并非总是将结果直接输出,相反,函数的调用者需要函数提供一些通过函数处理过后的一个或者一组数据,只有调用者拥有了这个数据,才能够做一些其他的操作。那么这个时候,就需要函数返回给调用者数据,这个就被称之为返回值,想要在函数中把结果返回给调用者,需要在函数中使用return。
return语句:用于退出函数(中断函数执行),选择性的向调用者返回一个表达式。直接return的语句返回None。return还可以返回多个值,值与值之间用逗号隔开。return返回的对象是临时对象,若没有变量或对象引用它,将被垃圾回收机制销毁。我们可以将函数的返回值保存在变量中。
Return和print区别:print是将结果输出到控制台,return语句结束函数的调用,并将结果返回给调用者,且返回的结果不能输出到控制台(也就是不能直接打印出来)需要通过print才能打印出来。
def example(x,y): add = x+y sub = x-y return add,sub #返回两个数值 num,num2 = example(6,3) #用变量接受返回值。 #打印返回值 print(num,num2) print(example(9,2)) print(type(example(9,2))) def test(min,max): list1 = [] while True: if min % 2 == 0: list1.append(min) elif min >= max: return list1 #中断函数执行 min += 1 print(test(10,50)) #返回两个之间的偶数
注意:
1.函数里如果没有return,会默认 return None。
2.函数如果return多个对象,那么python会帮我们把多个对象封装成一个元祖返回。
函数类型
通过以上学习,我们对函数的主要分为四种类型:
无参数,无返回值的函数
无参数,有返回值的函数
有参数,无返回值的函数
有参数,有返回值的函数
嵌套函数与闭包
python是允许创建嵌套函数的,也就是说我们可以在函数内部定义一个函数,也就是内嵌函数。这些函数都遵循各自的作用域和生命周期规则。在最外层函数叫主函数,属于全局作用域,定义了就可以被调用,内嵌函数只能在定义它的函数中直接调用,不能在全局作用域或者其他函数中调用。
x = 1111111111111111 def f1(): #x=1 print('------>f1 ',x) def f2(): #x = 2 print('---->f2 ',x) def f3(): x=3 print('-->f3 ',x) f3() f2() f1()
def f1(): print('------>f1 ',x) def f2(): print('---->f2 ',x) def f3(): print('-->f3 ',x) return f3 return f2 print(f1()) f1()() fun = f1() fun()()
python中的闭包
闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境),有了嵌套函数这种结构,便会产生闭包问题,闭包函数是嵌套函数的特殊实现。在函数式语言中,函数可以作为另一个函数的参数或返回值,当内嵌函数体内引用到体外的变量(除了全局变量),将会把定义时涉及到的引用环境和函数体打包成一个整体(闭包)返回。一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
闭包函数的必要条件:
外函数返回了内函数的引用
内函数引用外函数的局部变量或参数。


# NO.1 def line_conf(a, b): def line(x): print(x) return a * x + b return line # NO.2 def line_con(): a = 1 b = 2 def line(x): print(a * x + b) return line # NO.3 def _line_(a, b): def line_c(c): def line(x): return a * (x ** 2) + b * x + c return line return line_c print(line_conf(3,5)(9)) line_con()(6)
闭包函数对象一定有__closure__属性,__closure__属性返回的是一个元组对象,包含了闭包引用的外部变量。如果不是闭包函数对象__closure__属性永远为None或不存在__closure__属性。
def out(): a = 1 b = 2 def inner(x): print(x) #<<<------若主函数内的闭包不引用外部变量,就不存在闭包,主函数的_closure__属性永远为None return inner print(out().__closure__) # None for i in out().__closure__: #抛出异常 print(i.cell_contents) def line_conf(): a = 1 b = 2 def line(x): print(a * x + b) return a + b # <<<------若主函数没有return子函数,就不存在闭包,主函数不存在_closure__属性 print(line_conf().__closure__) # 抛出异常 #闭包函数 def outer(): a = 1 b = 2 def inner(x): print(x,a,b) #<<<------主函数内的闭包引用外部变量 return inner print(outer().__closure__) # None for i in outer().__closure__: print(i.cell_contents)
还有一点需要注意:使用闭包的过程中,一旦外函数被调用一次返回了内函数的引用,虽然每次调用内函数,是开启一个函数执行过后消亡,但是闭包变量实际上只有一份,每次开启内函数都在使用同一份闭包变量。
def outer(x): def inner(y): nonlocal x x+=y return x return inner a = outer(10) print(a(1)) #11 print(a(3)) #14
闭包可以保存运行环境
_list = [] for i in range(3): def func(a): return i+a _list.append(func) for f in _list: print(f(1)) ''' 在Python中,循环体内定义的函数是无法保存循环执行过程中的不停变化的外部变量的,即普通函数无法保存运行环境! 想要让上面的代码输出1, 2, 3并不难,“术业有专攻”,这种事情该让闭包来: ''' _list = [] for i in range(3): def func(i): def f_closure(a): # <<<--- return i + a return f_closure _list.append(func(i)) # <<<--- for f in _list: print(f(1))
'''不能保存运行环境''' flist = [] for i in range(3): def foo(x): print(x + i) flist.append(foo) for f in flist: f(1) '''修改之后''' flist = [] for i in range(3): def foo(x,y=i): print(x + y) flist.append(foo) for f in flist: f(1)
闭包函数的应用:
装饰器、面向对象、单例模式
''' 我以一个类似棋盘游戏的例子来说明。假设棋盘大小为50*50,左上角为坐标系原点(0,0),我需要一个函数,接收2个参数, 分别为方向(direction),步长(step),该函数控制棋子的运动。棋子运动的新的坐标除了依赖于方向和步长以外, 当然还要根据原来所处的坐标点,用闭包就可以保持住这个棋子原来所处的坐标。''' # origin = [0, 0] # 坐标系统原点 # legal_x = [0, 50] # x轴方向的合法坐标 # legal_y = [0, 50] # y轴方向的合法坐标 # def create(pos=origin): # def player(direction, step): # # 这里应该首先判断参数direction,step的合法性,比如direction不能斜着走,step不能为负等 # # 然后还要对新生成的x,y坐标的合法性进行判断处理,这里主要是想介绍闭包,就不详细写了。 # new_x = pos[0] + direction[0] * step # new_y = pos[1] + direction[1] * step # pos[0] = new_x # pos[1] = new_y # # 注意!此处不能写成 pos = [new_x, new_y],没有关键字的声明,不能局部作用域对外部作用域的变量进行重新赋值。 # return pos # return player # # player = create() # 创建棋子player,起点为原点 # print(player([1, 0], 10)) # 向x轴正方向移动10步 # print(player([0, 1], 20)) # 向y轴正方向移动20步 # print(player([-1, 0], 10)) # 向x轴负方向移动10步 '''取得文件"result.txt"中含有"pass"关键字的行''' # def make_filter(keep): # def the_filter(file_name): # file = open(file_name) # lines = file.readlines() # file.close() # filter_doc = [i for i in lines if keep in i] # return filter_doc # return the_filter # filter = make_filter("pass") # filter_result = filter("result.txt") '''面向对象''' # def who(name): # def do(what): # print(name, 'say:', what) # return do # lucy = who('lucy') # john = who('john') # lucy('i want drink!') # lucy('i want eat !') # lucy('i want play !') # john('i want play basketball') # john('i want to sleep with U,do U?') # lucy("you just like a fool, but i got you!") '''闭包实现快速给不同项目记录日志,只需在你想要logging的位置添加一行代码即可。''' # import logging # def log_header(logger_name): # logging.basicConfig(level=logging.DEBUG, format='%(asctime)s [%(name)s] %(levelname)s %(message)s', # datefmt='%Y-%m-%d %H:%M:%S') # logger = logging.getLogger(logger_name) # def _logging(something, level): # if level == 'debug': # logger.debug(something) # elif level == 'warning': # logger.warning(something) # elif level == 'error': # logger.error(something) # else: # raise Exception("I dont know what you want to do?") # return _logging # project_1_logging = log_header('project_1') # project_2_logging = log_header('project_2') # def project_1(): # # do something # project_1_logging('this is a debug info', 'debug') # # do something # project_1_logging('this is a warning info', 'warning') # # do something # project_1_logging('this is a error info', 'error') # def project_2(): # # do something # project_2_logging('this is a debug info', 'debug') # # do something # project_2_logging('this is a warning info', 'warning') # # do something # project_2_logging('this is a critical info', 'error') # project_1() # project_2() '''单例模式:所谓单例,是指一个类的实例从始至终只能被创建一次。python中的使用@语法实现的单例模式就是利用闭包实现的, 只不过用了@作为语法糖(装饰器),使写法更简洁,闭包函数将函数的唯一实例保存在它内部的__closure__属性中,在再次创建函数实例时, 闭包检查该函数实例已存在自己的属性中,不会再让他创建新的实例,而是将现有的实例返给它。''' # def Singleton(cls): # _instance = {} # def _singleton(*args, **kargs): # if cls not in _instance: # _instance[cls] = cls(*args, **kargs) # return _instance[cls] # return _singleton # # @Singleton # class A(object): # a = 1 # def __init__(self, x=0): # self.x = x # a1 = A(2) # a2 = A(3)
全局变量与局部变量
名称空间:Python所有有关命名的操作都是在操作名称空间,例如变量名,函数名。即存放名字的地方,三种名称空间(如x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系(引用)的地方)。
1、内置名称空间:Python解释器提供好的功能,解释器启动跟着一起启动,是全局作用域(即内置在解释器中的名称)。
2、全局名称空间:Python中顶行写的,不在函数内部定义的,都是全局名称空间,在运行的时候会产生名称空间,是全局作用域(一般写的顶头名称) 。
3、局部名称空间:在一个小范围定义,只能当前范围及其子空间内运行,例如在函数内部定义的,是局部作用域。
python执行语句找一个名称的查找顺序:先在局部名称空间找,再到全局名称空间找,再到内置名称空间( locals -> enclosing function(闭包) -> globals -> __builtins__)。
需要注意的是:在全局无法查看局部的,在局部可以查看全局的。
import builtins a = (8,9) def f1(): b = 9 print(locals()) #查看局部名称空间的内容。 def f2(): print(b) return f2 print(dir(builtins)) #查看内建名称空间的内容。 print(globals()) #查看全局名称空间的内容。 print(f1().__closure__) #查看闭包保存引用外层函数的局部变量或参数。
变量的作用域
1、作用域即范围:
- 全局范围(内置名称空间与全局名称空间属于该范围):全局存活,全局有效。
- 局部范围(局部名称空间属于该范围):临时存活,局部有效(函数有自己的作用域,在函数外不能访问函数里的定义的变量)。
2、作用域关系是在函数定义阶段就已经固定的,与函数的调用位置无关。
全局变量是声明在函数外部的变量,定义在函数外的拥有全局作用域。一般命名规则,全局变量名为大写,局部变量名为小写。
局部变量,就是在函数内部定义的变量。
不同的函数,可以定义相同的名字的局部变量,但是各用个的不会产生影响。
Python中函数的作用域由def关键字界定,函数内的代码访问变量的方式是从其所在层级由内向外的。
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。局部变量是定义在函数内部的变量,拥有一个局部作用域,只能在该局部作用域里访问它。全局变量是定义在函数外的变量,拥有全局作用域,在整个程序里都可以访问它。
我们了解变量的作用域后,知道在函数里有自己的作用域,还可以访问全局变量,函数体里如果访问全局变量后,再定义与全局变量同名的局部变量就会出现报错,如下例:
var = 10 def fun(): print(var) var = 5 def fun(): var += 5 def fun(): var = var + 1 print(var) #会报错:UnboundLocalError: local variable 'var' referenced before assignment
报错分析:
函数是python第一类对象,定义好后就形成了自己的作用域,有自己的局部名称空间,并作为对象的形式存在内存,而按照python里查找名称的顺序,先从局部名称空间查找,再到全局名称空间查找,在上面的例子里函数定义了变量var,所以变量var在局部名称空间是能找到的,函数体要访问的变量var都是局部变量的var,当函数被调用,执行到要访问var时,在局部名称空间能找到变量var,但执行到此步之前,函数体里没有执行过定义var变量的语句。所以抛出了语句顺序的逻辑错误(UnboundLocalError: local variable 'var' referenced before assignment)。而不是找不到变量名的错误(NameError: name 'var' is not defined)。
global关键字与nonlocal关键字
要想在函数内部给全局变量重新赋值或修改不可变类型,需要使用grobal关键字声明。global关键字修饰变量后标识该变量是全局变量,对该变量进行修改就是修改全局变量。
如果函数的内容无global关键字,能读取全局变量,在函数里给全局变量赋值则是定义与其同名的局部变量,无法对全局变量重新赋值,但是对可变类型,可以对内部元素进行操作。若函数定义了与全局变量同名的局部变量,则优先读取局部变量。
如果函数中有global关键字,声明引用全局变量,变量本质上是全局的哪个变量,可读取可赋值。
在函数嵌套中,内嵌函数想要给外层函数定义的变量重新赋值或修改不可变类型,需要使用nonlocal关键字,nonlocal关键字修饰变量后标识该变量是外层函数中的局部变量,如果嵌套该函数的外层函数中都不存在该局部变量,nonlocal位置会发生错误(主函数使用nonlocal修饰变量必定会报错)。
NAME = '小明' def fun(): name = '小薇' def test(): global NAME nonlocal name print('内嵌函数访问到的name是:{}'.format(name)) name = '小欣' NAME = '小威' print('调用函数test前的局部变量name的值:{}'.format(name)) test() print('调用函数test后的局部变量name的值:{}'.format(name)) print('调用函数fun前的全局变量NAME的值:{}'.format(NAME)) fun() print('调用函数fun后的全局变量NAME的值:{}'.format(NAME))
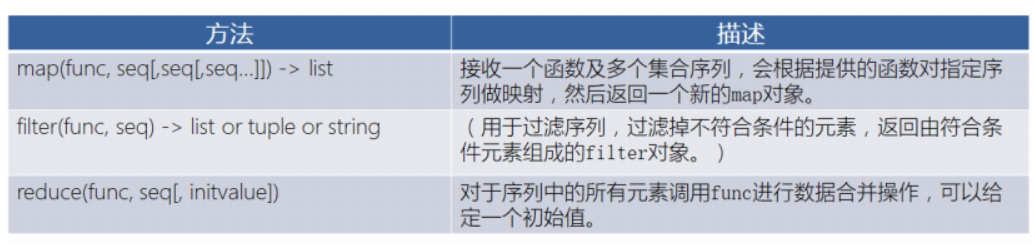
常用高阶函数
满足两个特性任意一个即为高阶函数:
1.函数接受的参数是个函数名。
2.返回值是个函数名。
list1 = [2,3,5,6,8]
list2 = [1,2,3,8,9]
list3 = [3,2,1,8,9]
def myMap(func,*iterable):
for e in range(len(iterable[0])):
element = []
for i in range(len(iterable)):
element.append(iterable[i][e])
res = func(*element)
yield res
for i in myMap(lambda x,y,z:x+y+z,list1,list2,list3):
print(i)
print(list(myMap(lambda x,y,z:x+y+z,list1,list2,list3)))
def myMap(func,*iterable):
result = []
for e in range(len(iterable[0])):
element = []
for i in range(len(iterable)):
element.append(iterable[i][e])
res = func(*element)
result.append(res)
return result
python内置高阶函数:
def myFilter(func,iterable):
for e in iterable:
if func(e):
yield e
def myReduce(func,iterable,init=None):
if init==None:
result = iterable[0]
for i in range(1, len(iterable)):
result = func(result, iterable[i])
return result
else:
result = init
for i in range(len(iterable)):
result = func(result, iterable[i])
return result
from functools import reduce
list1 = ['sub','start','print','min','str']
list2 = (2,3,6,8,2)
print(map(lambda x:x*2,list1))
print(list(map(lambda x:x*2,list1)))
print(filter(lambda x:x.startswith('s'),list1))
print(list(filter(lambda x:x.startswith('s'),list1)))
print(reduce(lambda x,y:x+y,list2))
装饰器
装饰器:装饰器就是闭包函数的一种应用场景,本质就是函数,功能是为其他函数添加附加功能。
装饰器原则:1.不修改被修饰函数的源代码。2.不修改被修饰函数的调用方式。
实现装饰器的知识储备:装饰器 = 高阶函数 + 闭包
语法糖(@):@decorator 相当于 modified_function = decorator(modified_function)
实现装饰器返回被装饰函数的返回值。
import time #添加打印函数运行时间的功能 def decorator(func): def inner(): start_time = time.time() func() # result = func() stop_time = time.time() print('函数对象{}的运行时间是:{}'.format(func.__name__,stop_time-start_time)) # return result return inner @decorator #相当于 modified_function = decorator(modified_function) def modified_function(): time.sleep(1) print('在modified_function函数里的输出语句') return '函数modified_function的返回值' test = modified_function() # 相当于 test = inner() print(test)
装饰器实现验证功能:
def verification(fun): names = {'张三':'123','李四':'456'} def inner(*args,**kwargs): name = input('用户名:') pswd = input('密码:') if names[name] == pswd: result = fun(*args,**kwargs) return result else: print('用户名或密码错误') return inner @verification def index(): print('欢迎来到个人主页') index()
user_list = [{'name':'小维','passwd':'123'},{'name':'小薇','passwd':'456'},{'name':'小欣','passwd':'789'}]
login_status = {'name':None,'lonin':False}
def verification(fun):
names = {'张三':'123','李四':'456'}
def inner(*args,**kwargs):
if login_status['name'] and login_status['lonin']:
result = fun(*args,**kwargs)
return result
user_name = input('用户名:')
pswd = input('密码:')
for user_dict in user_list:
if user_name == user_dict['name'] and pswd == user_dict['passwd']:
login_status['name'] = user_name
login_status['lonin'] = True
res = fun(*args,**kwargs)
return res
else:
print('用户名或密码错误')
return inner
@verification
def index():
print('欢迎来到个人主页')
@verification
def change_password():
print('修改密码')
pass
@verification
def change_name():
print('修改用户名')
pass
index()
change_name()
change_password()
装饰器加参数:
import time #添加打印函数运行时间的功能 def function_doc(docstring): def decorator(func): def inner(): start_time = time.time() func() # result = func() stop_time = time.time() print('{}:'.format(docstring)) print('函数对象{}的运行时间是:{}'.format(func.__name__,stop_time-start_time)) # return result return inner return decorator @function_doc('添加了打印函数运行时间的功能') #相当于 modified_function = function_doc(docstring)(modified_function) def modified_function(): time.sleep(1) print('在modified_function函数里的输出语句') return '函数modified_function的返回值' modified_function()
functools.wraps
装饰器一般返回一个包装器(wrapper),查看被装饰函数对象的属性的时候,返回的不是被装饰函数的属性,而是包装器的属性,如果需要要保持原属性,functools.wraps就是装饰包装器的装饰器。
from functools import wraps def decorator(func): @wraps(func) #加在最内层函数正上方 def wrapper(*args,**kwargs): '''包装器''' return func(*args,**kwargs) return wrapper @decorator def index(): '''哈哈哈哈''' print('from index') print(index.__doc__) print(index.__name__) print(help(index))
叠加多个装饰器
1. 加载顺序(outter函数的调用顺序):自下而上
2. 执行顺序(wrapper函数的执行顺序):自上而下
def outter1(func1): #func1=wrapper2的内存地址 print('加载了outter1') def wrapper1(*args,**kwargs): print('执行了wrapper1') res1=func1(*args,**kwargs) return res1 return wrapper1 def outter2(func2): #func2=wrapper3的内存地址 print('加载了outter2') def wrapper2(*args,**kwargs): print('执行了wrapper2') res2=func2(*args,**kwargs) return res2 return wrapper2 def outter3(func3): # func3=最原始的那个index的内存地址 print('加载了outter3') def wrapper3(*args,**kwargs): print('执行了wrapper3') res3=func3(*args,**kwargs) return res3 return wrapper3 @outter1 # outter1(wrapper2的内存地址)======>index=wrapper1的内存地址 outter2 = outter1(outter2) | wrapper1 @outter2 # outter2(wrapper3的内存地址)======>wrapper2的内存地址 outter3 = outter2(outter3) | wrapper2 @outter3 # outter3(最原始的那个index的内存地址)===>wrapper3的内存地址 index = outter3(index) | wrapper3 def index(): # 相当于执行了语句 index = outter1(outter2(outter3(index))) return 'from index' print('======================================================') print(index())
由 outter1(outter2(outter3(index)))的传参过程
可推index的执行过程:
outter1(outter2(outter3(index))) ======> 参数func3 = index ,outter3()返回 wrapper3
outter1(outter2(wrapper3)) ======> 参数func2 = wrapper3 ,outter2()返回 wrapper2
outter1(wrapper2) ======> 参数func1 = wrapper2 ,outter1()返回 wrapper1
index = wrapper1
上面的过程只要运行模块,无论是否调用index函数,都会被执行,然后形成闭包。
下面接着讲解index被调用的过程。
index() ======> wrapper1()
wrapper1() ======> res1 = func1() ,res1 在等待func1的返回结果
func1() ======> wrapper2()
wrapper2() ======> res2 = func2() ,res2 在等待func2的返回结果
func2() ======> wrapper3()
wrapper3() ======> res3 = index() ,res3 在等待func1的返回结果
return 'from index' ======> res3 = index() = 'from index'
return res3 ======> res2 = func2() = wrapper3() = 'from index'
return res2 ======> res1 = func1() = wrapper2() = 'from index'
return res1 ======> index() = wrapper1() = 'from index'
递归函数
递归函数:递归是函数嵌套调用的一种特殊形式,递归就是子程序(或函数)直接调用自己或通过一系列调用语句间接调用自己,这样的函数就叫递归函数,是一种描述问题和解决问题的基本方法。(一句话,自己调用自己)
def calc(n): if int(n / 2) == 0: return n n = int(n / 2) re = calc(n) return re print(calc(10))

递归优化:尾调用。
尾调用的概念非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
我们知道,函数调用会在内存形成一个"调用记录",又称"调用帧"(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个"调用栈"(call stack)。

尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。
以下两种情况,都不属于尾调用。
#情况一 def calc(n): if int(n / 2) == 0: return n n = int(n / 2) re = calc(n) return re #情况二 def calc(n): if int(n / 2) == 0: return n n = int(n / 2) # return 2+calc(n) return calc(n)+calc(n-1)
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用记录,很容易发生"栈溢出"错误(stack overflow)。但对于尾递归来说,由于只存在一个调用记录,所以永远不会发生"栈溢出"错误。
上面代码改写成尾递归,只保留一个调用记录:
def calc(n): if int(n / 2) == 0: return n n = int(n / 2) return calc(n) print(calc(10))

深入理解python尾递归
虽然尾递归优化很好, 但python 不支持尾递归,递归深度超过1000时会报错,下面以一个阶乘的例子演示。
#常规递归阶乘 def normal_recursion(n): "calculate a factorial" if n == 1: return 1 return n*normal_recursion(n-1) '''执行normal_recursion(5): normal_recursion(5) 5 * normal_recursion(4) 5 * 4 * normal_recursion(3) 5 * 4 * 3 * normal_recursion(2) 5 * 4 * 3 * 2 * normal_recursion(1) 5 * 4 * 3 * 2 5 * 4 * 6 5 * 24 120 可以看到, 一般递归, 每一级递归都需要调用函数, 会创建新的栈,随着递归深度的增加, 创建的栈越来越多, 造成爆栈 ''' #尾递归阶乘 def tail_recursion(n, acc=1): "calculate a factorial" if n == 0: return acc return tail_recursion(n-1, n*acc) '''执行tail_recursion(5): tail_recursion(5) tail_recursion(4,5) tail_recursion(3,20) tail_recursion(2,60) tail_recursion(1,120) tail_recursion(0,120) 120 ''' print(normal_recursion(1000)) #有递归深度的限制,会报错。 print(tail_recursion(1000)) #有递归深度的限制,会报错。
在其他语言中有支持尾递归的,于是一个牛人想出的解决办法:实现一个 tail_call_optimized 装饰器。
import sys class TailRecurseException(BaseException): def __init__(self, args, kwargs): self.args = args self.kwargs = kwargs def tail_call_optimized(g): """ This function decorates a function with tail call optimization. It does this by throwing an exception if it is it's own grandparent, and catching such exceptions to fake the tail call optimization. This function fails if the decorated function recurses in a non-tail context. """ def func(*args, **kwargs): f = sys._getframe() if f.f_back and f.f_back.f_back and f.f_back.f_back.f_code == f.f_code: # 抛出异常 raise TailRecurseException(args, kwargs) else: while 1: try: return g(*args, **kwargs) except TailRecurseException as e: args = e.args kwargs = e.kwargs func.__doc__ = g.__doc__ return func @tail_call_optimized def factorial(n, acc=1): "calculate a factorial" if n == 0: return acc return factorial(n-1, n*acc) print(factorial(10000))
或是用sys模块的一个内置方法设置递归深度。
import sys sys.setrecursionlimit(1000000)
总结递归的使用:
1. 必须有一个明确的结束条件(使用return中断执行)。
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少。
3. 递归效率不高,需要在进入下一次递归时保留当前的状态,递归层次过多会导致栈溢出,在其他语言中可以有解决方法:尾递归优化,即在函数的最后一步(而非最后一行)调用自己,尾递归优化:但是python又没有尾递归,且对递归层级做了限制(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)。
匿名函数
匿名函数:定义函数的过程中,没有给定名称的函数就叫做匿名函数;Python中使用lambda表达式来创建匿名函数。
lambda 来创建匿名函数规则。
●lambda只是一个表达式,函数体比def简单很多。
●lambda的主体是一个表达式,而不是一个代码块,所以不能写太多的逻辑进去。
●lambda函数拥有自己的命名空间。
●lambda定义的函数的返回值就是表达式的返回值,不需要return语句块。
●lambda表达式的主要应用场景就是赋值给变量、作为参数传入其它函数。
lambda匿名函数的表达式规则是:lambda 参数列表: 表达式。
有名字的函数与匿名函数的对比:
有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能 。
匿名函数:一次性使用,随时随时定义
fun1 = lambda x,y:x+y #给匿名函数命名 print(fun1) '''类似于''' def fun(x,y): return x+y print(fun) print(fun1(5)) print(fun(5))
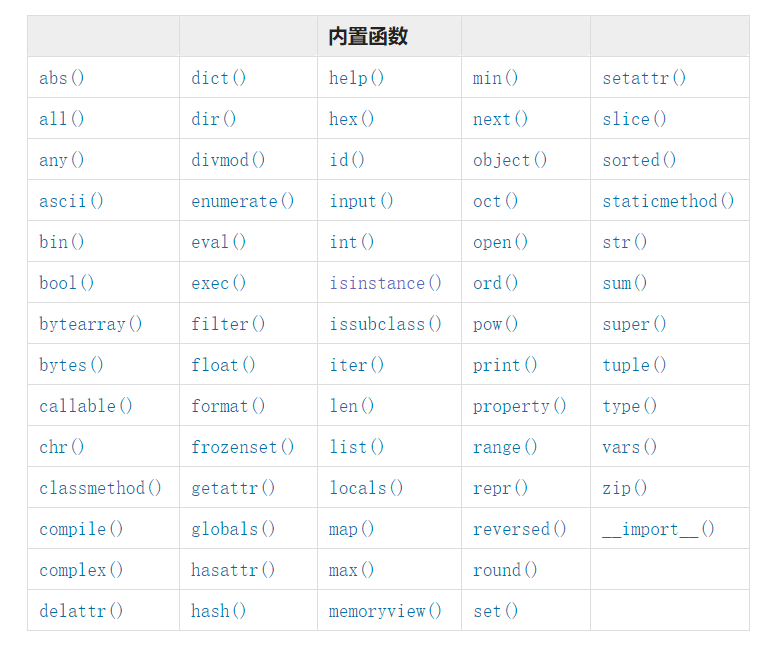
内置函数
python提供了一些内置函数,可方便开发人员使用,内置函数主要来自“__builtins__”模块,__builtins__ 模块是python的内置模块,启动python便会自动导入,所以可以使用print(dir(__builtins__))查看‘“__builtins__”模块所有内置函数。
zip():
str1 = 'abcde' list1 = [1,2,3,4,5] for i in zip(str1,list1): print(i) element1,element2 = zip(*zip(str1,list1)) #zip() 与 * 运算符相结合可以用来拆解一个列表 print(element1)
max():
1.max函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较。注意,不同类型之间不能进行比较。
2.每个元素间进行比较,是从每个元素的第一个位置依次比较,如果第一位置分出大小,后面的都不需要比较了,直接得出这两个元素的大小。
str1 = 'abcde' list1 = [1,2,3,4,5] list2 = [[6,7],[89,0]] fruit = {'Apples':60, 'bananas':20, 'oranges':30} people = [{'name':'小薇','age':18},{'name':'小北','age':20},{'name':'小月','age':19}] print(max(list1)) print(max(list2)) print(max(str1)) print(max(fruit)) print(max(zip(fruit.values(),fruit.keys()))) #结合zip # print(max(people)) #会报错,不支持字典与字典的比较 #解决字典之间的比较 print(max(people,key=lambda dic:dic['age']))
sorted():
fruit = {'Apples':60, 'bananas':20, 'oranges':30}
people = [{'name':'小薇','age':18},{'name':'小北','age':20},{'name':'小月','age':19}]
print(sorted(fruit))
print(sorted(fruit.values()))
print(sorted(fruit,key=lambda key:fruit[key]))
print(sorted(zip(fruit.values(),fruit.keys())))
print(sorted(people,key=lambda dic:dic['age']))

