第二篇:python基础语法与基本数据类型
上一篇我们已经简单了解了python的介绍。在继续之前,需要刚入门的朋友注意一点,以后所提供的练习案例的代码,除了你已掌握相关知识点,请千万不要用“复制”-“粘贴”把代码从页面粘贴到你自己 的电脑上。写程序也讲究一个感觉,你需要一个字母一个字母地把代码 自己敲进去,在敲代码的过程中,初学者经常会敲错代码,所以,你需 要仔细地检查、对照,才能以最快的速度掌握如何写程序。Python 是一种计算机编程语言。计算机编程语言和我们日常使用的自然 语言有所不同,最大的区别就是,自然语言在不同的语境下有不同的理 解,而计算机要根据编程语言执行任务,就必须保证编程语言写出的程 序决不能有歧义,所以,任何一种编程语言都有自己的一套语法,编译 器或者解释器就是负责把符合语法的程序代码转换成 CPU 能够执行的 机器码,然后执行。Python 也不例外。
注释与缩进
Python 的语法比较简单,采用缩进方式。以#开头的语句或三重引号包含的内容(也称文档字符串)是注释,注释是给人看的,可以是任意内容,解释器会 忽略掉注释。其他每一行都是一个语句,当语句以冒号:结尾时,需要缩进,否则报错。,缩进 的语句视为代码块。Python 函数没有明确的开始(begin)或者结束(end),也没 有用大括号来标记函数从哪里开始从哪里停止。唯一的定界符 就是一个冒号(:)和代码自身的缩进。python是以强制缩进方式格式化代码,使得python代码变得简洁明了。缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几 个空格还是 Tab。按照约定俗成的管理,应该始终坚持使用 4 个空格的 缩进。缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。当你重 构代码时,粘贴过去的代码必须重新检查缩进是否正确。通常在 Python 中, 默认以换行为新的一行,若想在一行输入多句语句,一定要加‘ ;’ ,否则报错。最后,请务必注意,Python 程序是大小写敏感的,如果写错了大小写, 程序会报错(如变量命名为“Number”,调用时不能使用“number”调用。
#python代码语法实例 num = 1; num2 = 6 #用‘;'隔开一行中的多个语句 if num > 0: # 以:结尾的语句下的缩进代码块属于此语句的子代码。 num3 = 3 print(num+num2)
print(num); print(num3)
词法元素
语言中的词法元素是用于构造语句一类的单词和符号。和所有语的高级语言一样,python的一些基本符号是关键字,例如,if、while、def、class等,还包括了其他一些词法元素,例如,标识符(名称)、字面值(数字、字符串、和其他内建的数据类型)、运算符、分隔符(引号、逗号、圆括号、方括号和大括号)。
语法元素
一种语言的语法元素是由词法元素组成的语句(表达式、语句和其他结构)。和其他高级语言不同,python采用空格、换行和缩进来标记多种类型的语句的语法。这意味着,在python中换行和缩进是很重要的。
标识符
标识符是自己定义的 , 如变量名 、函数名,类名等。
标识符命名规则:
1 、只能包含字母、数字和下划线。变量名可以以字母或者下划线开头。但 是不能以数字开头。
2 、不能包含空格,但可以使用下划线来分隔其中的单词。
3 、不能使用 Python 中的关键字作为变量名。
4 、建议使用驼峰命名法,驼峰式命名分为大驼峰( UserName )。和小驼 峰( userName )。
python中的一些关键字:

命名惯例:模块、变量、函数的名称,都是首字母小写的驼峰命名法,类名是首字母大写的驼峰命名法,当变量是常量的时候,其所有字母都是大写的,并且会有一个下划线用来隔开任何嵌入的单词。
变量和赋值语句
变量在程序中就是用一个变量名表示了,变量名必须是大小写英文、数 字和_的组合,且不能用数字开头。python中的变量采用引用语义,每一个变量名其实存储的是实际存放数据的内存的地址。我们可以理解为所有的变量全部都是引用类型,等号=是赋值语句,把对象地址引用给变量,可以把任意数据类型赋值给变量,同 一个变量可以反复赋值,而且可以是不同类型的变量。比如a=A(),首先python创建一个对象A,然后声明一个变量a,再将变量a与对象A联系起来。变量a是没有类型的,它的类型取决于其关联的对象。a=A()时,a是一个A类型的引用,我们可以说a是A类型的,如果再将a赋值3,a=3,此时a就是一个整型的引用。这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语 言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不 匹配,就会报错。例如 Java 是静态语言,赋值语句如下(// 表示注释):int a = 123; // a 是整数类型变量,a = "ABC"; // 错误:不能把字符串赋给整型变量,和静态语言相比,动态语言更灵活。请不要把赋值语句的等号等同于数学的等号。比如下面的代码:
x = 10 x = x + 2 print(x) '''如果从数学上理解 x = x + 2 那无论如何是不成立的,在程序中,赋值 语句先计算右侧的表达式 x + 2,得到结果 12,再赋给变量 x。由于 x 之前的值是 10,重新赋值后,x 的值变成 12。'''
最后,理解变量在计算机内存中的表示也非常重要。当我们写:a = 'ABC' 时,Python 解释器干了两件事情:1. 在内存中创建了一个'ABC'的字符串; 2. 在内存中创建了一个名为 a 的变量,并把它指向'ABC'。也可以把一个变量 a 赋值给另一个变量 b,这个操作实际上是把变量 b 指向变量 a 所指向的数据,例如下面的代码:
a = 'ABC' b = a a = 'XYZ' print(b)
'''最后一行打印出变量 b 的内容到底是'ABC'呢还是'XYZ'?如果从数学意 义上理解,就会错误地得出 b 和 a 相同,也应该是'XYZ',但实际上 b 的 值是'ABC','''
让我们一行一行地执行代码,就可以看到到底发生了什么事,执行 a = 'ABC',解释器创建了字符串'ABC'和变量 a,并把 a 指向'ABC':

执行 b = a,解释器创建了变量 b,并把 b 指向 a 指向的字符串'ABC':

执行 a = 'XYZ',解释器创建了字符串'XYZ',并把 a 的指向改为'XYZ', 但 b 并没有更改:
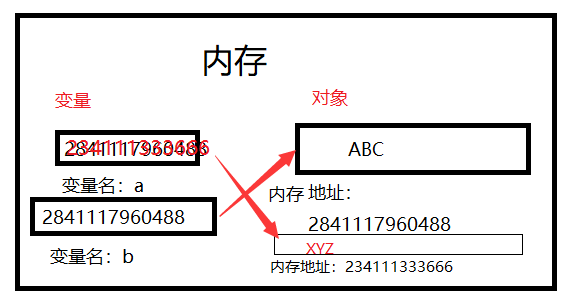
所以,最后打印变量 b 的结果自然是'ABC'了。
常量
所谓常量就是不能变的变量,比如常用的数学常数 π 就是一个常量。在 Python 中,通常用全部大写的变量名表示常量: PI = 3.14159265359 但事实上 PI 仍然是一个变量,Python 根本没有任何机制保证 PI 不会被 改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如 果你一定要改变变量 PI 的值,也没人能拦住你。当一个对象没有被赋值给变量而被调用,也可视为一个常量,如: print(3.14159265359),此时3.14156265359可视为常量。
输入和输出
输出
print()函数用来接受各种数据类型,并以字符串形式将数据类型的可视信息输出到控制台。在python中可用help()函数传入函数名查看函数的相关参数与函数文档。
help(print) ''' 运行结果: Help on built-in function print in module builtins: print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (stream); defaults to the current sys.stdout. sep: string inserted between values, default a space. end: string appended after the last value, default a newline. flush: whether to forcibly flush the stream. '''
print('mm=' 'sdsdsdsd') #两字符串之间,无论隔了多少个空格,都视为没有空格。
输入
input()是python的输入函数,通过它能够完成从键盘获取数据,然后以字符串的方式保存到指定的变量中。即输入的是数字,那么也是以字符串的方式保存。这个函数接受一个可选字符串,并且会不换行的打印出这个字符串,以提示用户进行输入。
example = input('请输入一个数字:') print(type(example)) #type()函数可查看对象所属数据类型
字面值
字面值是在程序里数据类型书写的表现形式,如数字在程序与数学的书写是一样的,字符串的表现形式是以引号把内容括起来。
基本数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当 然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处 理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需 要定义不同的数据类型。,Python 提供了字符串、列表、字典等多种数据类型,还允许创建自定义 数据类型,python中常用的内置数据类型主要有以 下几种:
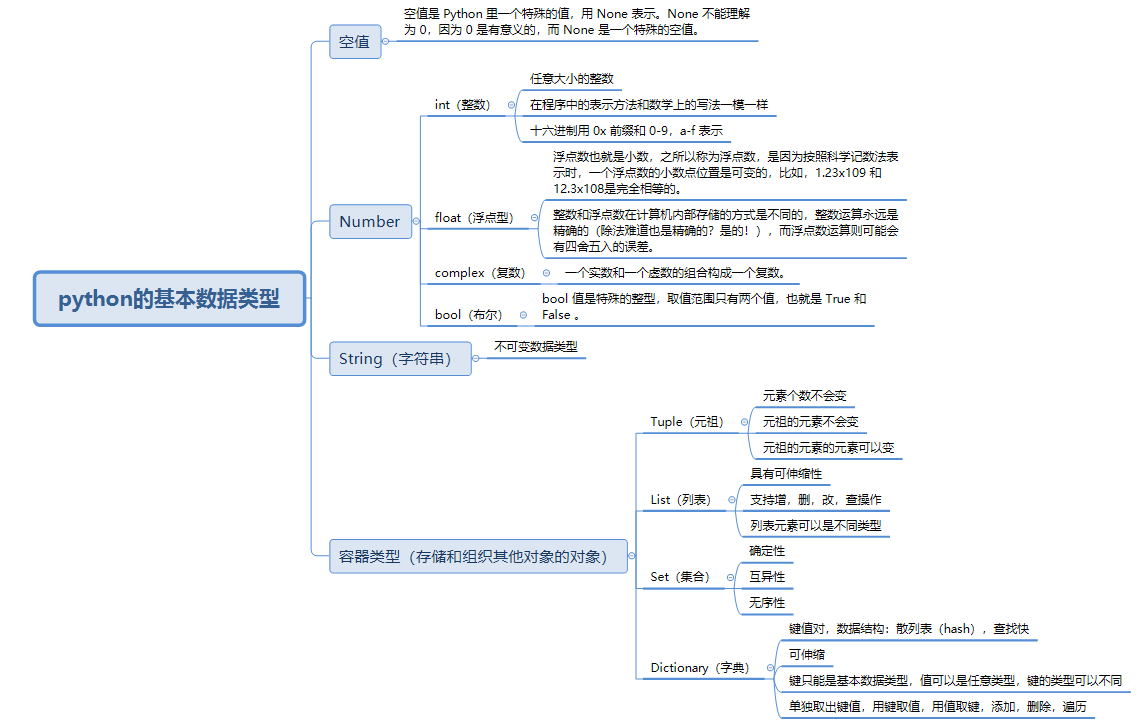
Number
''' int(x, base=10)方法:将浮点数或满足isalnum()方法的字符串转为十进制整形, 可选参数base用来指明x是什么进制数。默认值为10。 ''' num1 = 8.9 num2 = '3t' num3 = '6f' num4 = '8.9' num5 = int(float(num4)) #若将小数字符串转为整型,必须先把它转为浮点型,否则报错。 print('num1整形前:',num1,' num1整形后',int(num1)) print('num1整形前:',num2,' num1整形后',int(num2,base=32)) print('num1整形前:',num3,' num1整形后',int(num3,base=16)) print('num1整形前:',num4,' num1整形后',num5) ''' 运行结果: num1整形前: 8.9 num1整形后 8 num1整形前: 3t num1整形后 125 num1整形前: 6f num1整形后 111 num1整形前: 8.9 num1整形后 8 ''' ''' bit_length():返回十进制整型转二进制至少需要多少位二进制位数。 ''' int1 = 32 binary_number = bin(int1) #将十进制转为二进制,表现形式以0b开头。 octonary_number = oct(int1) #将十进制转为八进制,表现形式以0o开头。 hexadecimal_number = hex(int1) #将十进制转为十六进制,表现形式以0x开头。 print('int1的转二进制数等于:', binary_number) print('int1的二进制位数:', int1.bit_length()) print('int1的转八进制数等于:',octonary_number) print('int1的转十六进制数等于:',hexadecimal_number) ''' 运行结果: int1的转二进制数等于: 0b100000 int1的二进制位数: 6 int1的转八进制数等于: 0o40 int1的转十六进制数等于: 0x20 '''
字符串
字符串就是一系列任意文本。字符串是不可变的,也就说,一旦创建了字符串,不能更改其内部的内容。 Python 中的字符串用单引 号或者双引号括起来,同时可以使用反斜杠( \ )转义特殊字 符。 单引号(’’)和双引号( "” )本身只是一种表示方式,用来声明字符串类型,不 是字符串的一部分,因此,字符串’ hello’ 只有 h,e,l,l,o 这五 个字符。如果’本身也是字符的话,那么就可以用””括起来,比 如” I’m OK” 当中包含了一个 ’ 。如果字符串内部包含 ’ 或 者 ” ,但是又想当成普通字符串处理怎么办?这个时候就要用 转义字符( \ )来标识。\字符用于将非图形化的字符或一些特殊字符(例如,引号‘、换行\n和制表\t,或者\字符本身)进行转义。当字符串只有一个元素时,可称其为字符,如‘2’是字符,字符串是由多个字符组成的。字符串实际上就是字符的数组,每个元素都有对应的编号,称为下标,若字符串从左往右编号,则从0开始步长为1升序编号,若字符串从右往左编号,则从-1开始步长为1降序编号。下标需要与下标运算符( [ ] )一起使用。
#使用''或""来创建字符串,并赋值给变量。 str1 = 'I like python very much' print(str1) print(type(str1)) #查看str1属于哪种数据类型 #字符串索引语法:变量[下标],下标取值不能超出元素对应的最大编号,否则报错。 print(str1[0],str1[5],str1[len(str1)-1]) #len()函数用来查看对象的元素个数,str1最大下标取值为len(str1)-1. #字符串切片语法:变量[开始下标:结束下标:步长],通过下标与步长截取一段子字符串,步长可选,默认是1. print(str1[0:3]) #截取一段从下标0的下标2的子字符串,不包括下标为3的字符。(切片规则:选取的区间属于左闭右开型) print(str1[2:-2]) #负数代表倒数第几个,从第三个开始到倒数第二个,不包含倒数第二个。 print(str1[2:9:2]) #从第三个开始到第九个,每隔2个元素取一个元素。 #字符串拼接:加号(+)是字符串的连接符。 str2 = ', What about you?' print(str1+str2) #星号(*)表示复制当前字符串。 print(str2*5) #复制当前字符串5次。
#字符转义
print('s1=','\'Hello,world\'')
print('s2=\'Hello,\\\'Adam\\\'\'')
print(r's3=\'Hello,"Bart"\'') #以r开头的字符串声明是普通字符串。规避转义符\。
print('s4=\'\'\'Hello,\nLisa!\'\'\'')
字符串格式化操作
在 Python 中,采用的格式化方式和 C 语言是一致的,用%(占位符)实现。这些占位符符为真实值预留位置,并通过参数说明真实数值应该呈现的格式。
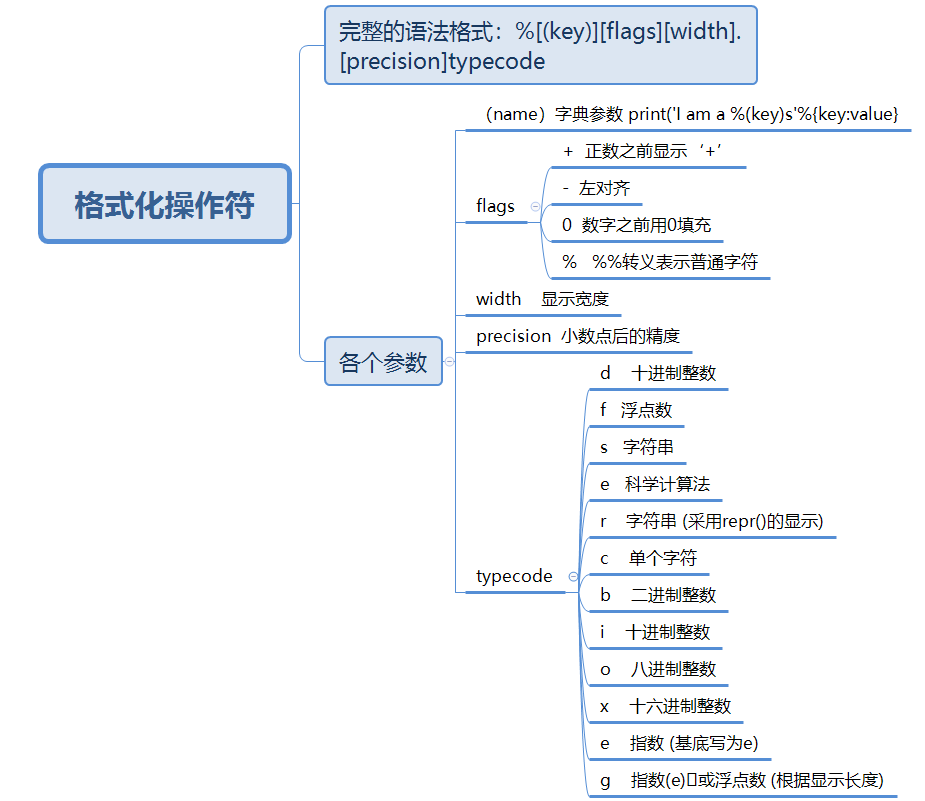
a = "I'm %s. I'm %d year old" % ('Vamei', 18) #%s为第一个格式符,表示一个字符串。%d为第二个格式符,表示一个整数。('Vamei', 99)的两个元素'Vamei'和99为替换%s和%d的真实值。 b = "I'm%+6s. I'm %d year old" % ('Vamei', 18) #%+6s表示占位6个字符,真值右对齐,不够6个字符的真值用空字符填充。 c = 'The price of apples is %.2f dollars a catty'%(2.368) print(a) print(b) print(c)
另外python还有一个更强大的字符串处理函数 str.format(),它通过{}和:来代替%。
#通过位置传值 a = "I'm {}. I'm {} year old".format('Vamei',19) print(a) #通过关键字传值 b = "I'm {name}. I'm {age} year old".format(age=19,name='Vamei') print(b) #通过下标传值 c = "I'm {1}. I'm {0} year old".format(19,'Vamei') print(c) #通过对象属性 class Person: def __init__(self,name,age): self.name,self.age = name,age def __str__(self): return 'This guy is {self.name},is {self.age} old'.format(self=self) print(str(Person('Vamei',18))) #格式限定符语法:{}中带:号,^、<、>分别是居中、左对齐、右对齐,后面带宽度,:号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充 print('{:a>8}'.format('689')) #精度常跟类型f一起使用,b、d、o、x分别是二进制、十进制、八进制、十六进制。 print('{:.2f}'.format(321.33345)) #用,号还能用来做金额的千位分隔符。 print('{:,}'.format(1234567890))
字符串颜色输出
格式:\033[显示方式;前景色;背景色m
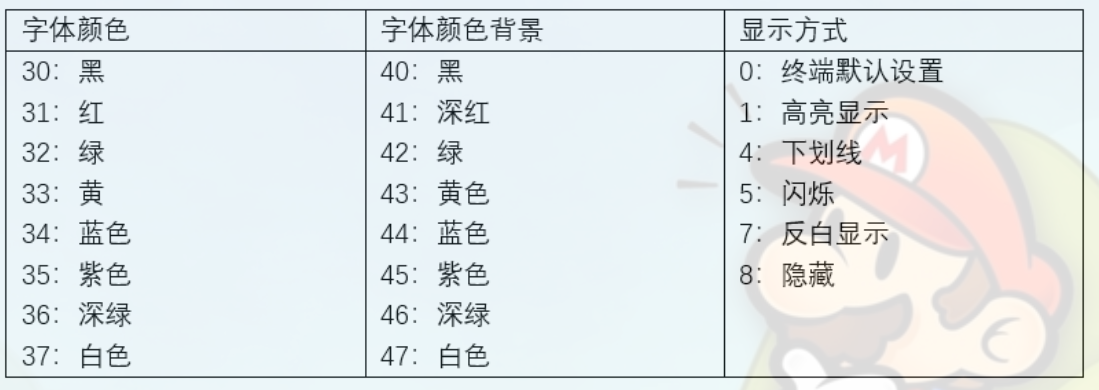
#字体颜色 print("=====字体颜色======") for i in range(31, 38): print("\033[%s;40mHello world!\033[0m" %i) # 背景颜色 print("=====背景颜色======") for i in range(41, 48): print("\033[47;%smHello world!\033[0m" %i) # 显示方式 print("=====显示方式======") for i in range(1, 9): print("\033[%s;31;40mHello world!\033[0m" %i)
字符串和编码
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的 是还有一个编码问题。因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数 字才能处理。实际上,任何东西在计算机中表示,都需要编码。例如,视频要编码然后保存在文件中,播放的时候需要解码才能观看。
字符编码
由于计算机是美国人发明的,因此,最早只有 127 个字母被编码到计算 机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为 ASCII 编码,如果要处理中文显然一个字节是不够的,至少需要两个字节,而且还不 能和 ASCII 编码冲突,所以,中国制定了 GB2312 编码,用来把中文编进去。但是各国有各国的标准,就会不可避免地出 现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。为了解决乱码问题,把所有语言都统一到一套编码里,于是Unicode 应运而生。Unicode 标准也在不断发展,但最常用的是用两个字节表示一个字符(如 果要用到非常偏僻的字符,就需要 4 个字节)。现代操作系统和大多数 编程语言都直接支持 Unicode。现在,捋一捋 ASCII 编码和 Unicode 编码的区别:ASCII 编码是 1 个字 节,而 Unicode 编码通常是 2 个字节。新的问题又出现了:如果统一成 Unicode 编码,乱码问题从此消失了。 但是,如果你写的文本基本上全部是英文的话,用 Unicode 编码比 ASCII 编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把 Unicode 编码转化为“可变长编码” 的 UTF-8 编码。UTF-8 编码把一个 Unicode 字符根据不同的数字大小编 码成 1-6 个字节,常用的英文字母被编码成 1 个字节,汉字通常是 3 个 字节,只有很生僻的字符才会被编码成 4-6 个字节。如果你要传输的文 本包含大量英文字符,用 UTF-8 编码就能节省空间,因Unicode定义了一个“字符”和一个“数字”的对应,但是并没有规定这个“数字”在计算机中怎么保存。(就像在C中,一个整数既可以是int,也可以是short。unicode没有规定用int还是用short来表示一个“字符”,所以Unicode只是编码字符集,而UTF-8是Unicode的实现。它使用unicode定义的“字符”“数字”映射,进而规定了,如何在计算机中保存这个数字。其它的utf16等都是unicode实现。
理论上,从一个字符到具体的编码,会经过以下几个概念。
字符集:就算一堆抽象的字符,如所有中文。字符集的定义是抽象的,与计算机无关。
编码字符集:是一个从整数集子集到字符集抽象元素的映射。即给抽象的字符编上数字。如gb2312中的定义的字符,每个字符都有个整数和它对应。一个整数只对应着一个字符。反过来,则不一定是。这里所说的映射关系,是数学意义上的映射关系。编码字符集也是与计算机无关的。unicode字符集也在这一层。
字符编码方式:这个开始与计算机有关了。编码字符集的编码点在计算机里的具体表现形式。通俗的说,意思就是怎么样才能将字符所对应的整数的放进计算机内存,或文件、或网络中。于是,不同人有不同的实现方式,所谓的万码奔腾,就是指这个。gb2312,utf-8,utf-16,utf-32等都在这一层。
字符编码方案:这个更加与计算机密切相关。具体是与操作系统密切相关。主要是解决大小字节序的问题。对于UTF-16和UTF-32
编码,Unicode都支持big-endian 和 little-endian两种编码方案。
一般来说,我们所说的编码,都在第三层完成。具体到一个软件系统中,则很复杂。
搞清楚了 ASCII、Unicode 和 UTF-8 的关系,我们就可以总结一下现在 计算机系统通用的字符编码工作方式,在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要 传输的时候,就转换为 UTF-8 编码或其他。
用记事本编辑的时候,从文件读取的 UTF-8 字符被转换为 Unicode 字符 到内存里,编辑完成后,保存的时候再把 Unicode 转换为 UTF-8 保存到 文件:
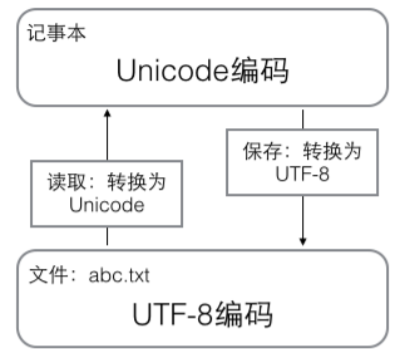
浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF-8 再 传输到浏览器:

搞清楚了令人头疼的字符编码问题后,我们再来研究 Python 的字符串。在最新的 Python 3 版本中,字符串是以 Unicode 编码的,也就是说, Python 的字符串支持多语言的字符。对于单个字符的编码,Python 提供了 ord()函数获取字符的Unicode编码, chr()函数把Unicode编码转换为对应的字符:
print(ord('中')) #返回十进制的Unicode编码 print(chr(20013)) #传入十进制Unicode编码,返回编码对应的字符。 print(chr(0x4e2d)) #传入十六进制的Unicode编码,返回编码对应的字符。
#如果知道字符的整数编码,还可以用十六进制这么写 str
print('\u4e2d\u6587')
# 把字符串转换成Unicode编码 def str2unicode(s:str,file=None): ''' string to unicode ''' unicode = '' for i in s: unicode += '\\u{:0>4}'.format(str(hex(ord(i)))[2:]) if file: with open(file,'w',encoding='utf-8') as f: f.write('[\'{}\']'.format(unicode)) print(unicode) return '字符串的Unicode编码已写入文件:{}'.format(file) return "'{}'".format(unicode) print(str2unicode('中文,i like you','./test.txt'))
def readUnicodeFile(file:str): ''' Read a hexadecimal Unicode encoded file :param file: file path :return: string ''' try: with open(file,'r',encoding='utf-8') as f: unicodeStr = f.read() unicodeList = eval(unicodeStr) #eval():运算字符串表达式或提取字符串所包裹的数据类型。 return unicodeList[0] except BaseException: if '\\' in file: print('找不到文件: {}'.format(file.split('\\')[-1])) else: print('找不到文件: {}'.format(file.split('/')[-1])) print(readUnicodeFile('./tes.txt'))
由于 Python 的字符串类型是 str,在内存中以 Unicode 表示,一个字符 对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把 str 变为以字节为单位的 bytes。Python 对 bytes 类型的数据用带 b 前缀的单引号或双引号表示:x = b'ABC',要注意区分'ABC'和 b'ABC',前者是 str,后者虽然内容显示得和前者一 样,但 bytes 的每个字符都只占用一个字节。 以 Unicode 表示的 str 通过 encode()方法可以编码为指定的 bytes,例如:
print('Abc'.encode('utf-8')) #默认是Unicode的字符串转为utf-8. print('中文'.encode('')) #在 bytes 中,无法显示为 ASCII 字符的字节,用\x**显示。*号是十六进制数 print('Abc'.encode('ascii'))
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是 bytes。要把 bytes 变为 str,就需要用 decode()方法:
print(b'abc'.decode('ascii')) print(b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8'))
len()函数计算的是 str 的字符数,如果换成 bytes,len()函数就计算字 节数。1 个中文字符经过 UTF-8 编码后通常会占用 3 个字节,而 1 个英 文字符只占用 1 个字节。
另外,有一些文件开头写上这两行:

第一行注释是为了告诉 Linux/OS X 系统,这是一个 Python 可执行程序, Windows 系统会忽略这个注释。
第二行注释是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码, 否则,你在源代码中写的中文输出可能会有乱码。申明了 UTF-8 编码并不意味着你的.py 文件就是 UTF-8 编码的,必须并 且要确保文本编辑器正在使用 UTF-8编码。
列表
列表(list)零个或多个python对象的一个序列(有序集合),属于容器类。列表中的对象通常称为项(元素),可以是任何数据类型。列表有一个字面的表示方法,就是使用方括号( [ ] )将用逗号隔开的项括起来。和字符串一样,可以使用标准运算符对列表进行切片和连接(+),然而,返回的结果是一个新列表,而不是最初列表的一部分,最初列表未改变。和字符串不同,列表是可变的,这意味着,可以替换、插入或删除列表中所包含的项(元素),即对原列表对象的元素进行操作。列表类型包含了几个叫做修改器的方法(append、insert、pop等),它们的作用是修改一个列表的结构。
emptyList = [] #创建空列表 listExample = ['北京','上海',1,[2,3]] sub_list = listExample[2] #列表索引,返回索引的元素。 sub_lists = listExample[0::2] #切片,返回新列表,并赋值给新变量。 sub_list2 = listExample[3][1] #对子对象进行索引。 #修改元素 print('listExample修改后:{}'.format(listExample)) listExample[1] = '广州' print('listExample修改后:{}'.format(listExample)) #拼接 newList = ['a','b'] cancatList = listExample + newList print(cancatList)
元祖
元祖是项的一个不可变的序列。元祖字面值是元素写在小括号 ” () “ 里,元素之间用逗号隔开。tuple 的元素不可改变,但是可以包含可变的对象,比如 list。元祖实际上就像列表一样,只不过它没有修改器方法。当函数返回多个值的时候,是以元组的方式返回的。函数还可以接收可变长参数,比如以 “*” 开头的参数名,会将所有的参数收集到一个元组上。
emptyTuple = () oneElement = (1,) #一个元素的元祖,需要在元素后面添加一个逗号 tupleExample = ('北京','上海',2,[1,3,'tuple']) tupleExample[3][1] = 'a' #若子对象是可变类型,则可变。 print(tupleExample)
集合
集合(set)是一个无序不重复元素的序列。基本功能是进行成员关系测试和删除重复元素。可以使用大括号 {} 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 {} ,因为 {} 是用来创建一个空字典的。每个元素必须为不可变类型即(hashable类型,可作为字典的key)。
emptySet = set() #创建空集合 setElement = {'北京','上海',(3,5)} print(setElement)
字典
字典(dictionary)是 Python 中另一个非常有用的内置数据类型,是一种映射类型。字典包含了零个或多个条目(键—值对),每个条目都将一个唯一的键和一个值相关联。键的定义必须是不可变的,即可以是数字、字符串也可以是元组,还有布尔值等。在同一个字典中,键(key) 必须是唯一的。而值的定义可以是任意数据类型。字典的字面值是将键—值条目包含到花括号(大括号)中。CPython使用伪随机探测(pseudo-random probing)的散列表(hash table)作为字典的底层数据结构。其特点是:不管字典中有多少项,in操作符花费的时间都差不多。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素时通过键来存取的,而不是通过偏移存取,不支持切片。列表存储空间小、查询慢。字典查询快、存储空间大,对其有 ‘空间换时间’ 的说法。
emptyDict = {} dictExample = {'name':'job','age':19} #查询 print(dictExample['name']) #修改 dictExample['age'] = 20 print(dictExample) #添加 dictExample['sex'] = '男' print(dictExample)
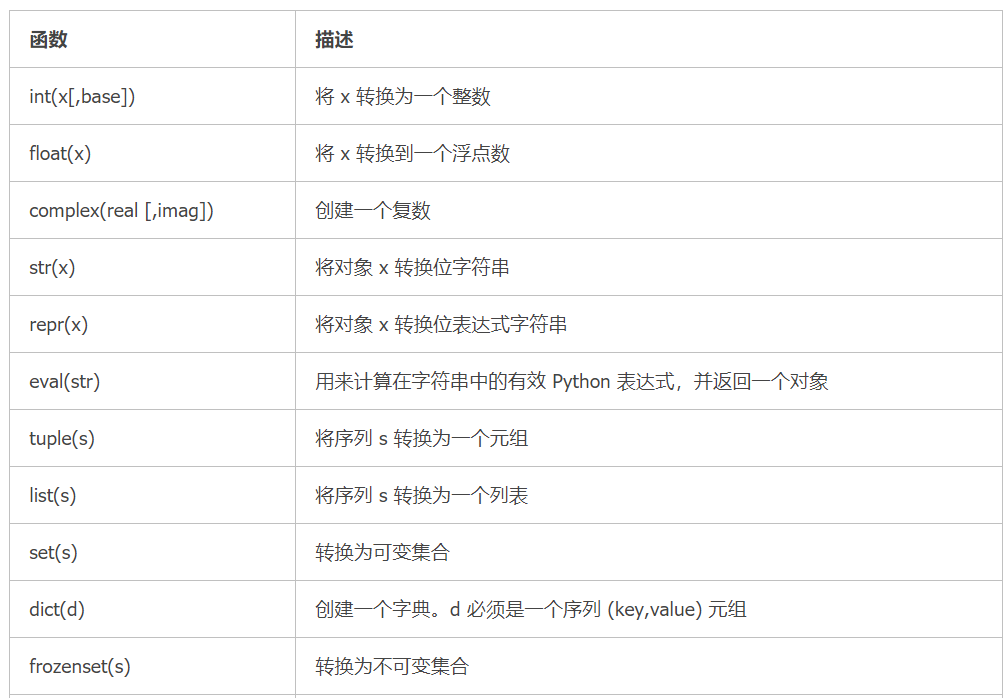
Python 数据类型转换
有时候,我们需要对数据内置的内心进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。以下几个内置的函数可以执行数据类型之间的转换,这些函数返回一个新的对象,表示转换的值。