代码
import requests #导入第三方库
from bs4 import BeautifulSoup as bs
import re
import os
import random
import json
import openpyxl
import time
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'cookie':'这里放上自己的cookie'
}
# 用来存放商品信息的列表
auctions = []
# 爬取的最大页面数
maxPage = 10
for i in range(maxPage):
params = {
'q': '鼠标',
's': str(i*44),
}
response = requests.get('https://s.taobao.com/search', params=params, headers=headers)
# 拿到html的文本
content = response.text
# 拿到g_page_config的json字符串
g_page_config = re.findall(r'g_page_config = ({.*})', content)[0]
# 转化成字典dict
g_page_config = json.loads(g_page_config)
# 拿到auctions,商品信息的描述列表
auctions.extend(g_page_config['mods']['itemlist']['data']['auctions'])
print(len(auctions))
time.sleep(4)
workbook = openpyxl.Workbook()
sheet = workbook.active
# 表头
sheet.cell(1,1).value = '商品名称'
sheet.cell(1,2).value = '价格'
sheet.cell(1,3).value = '销量'
sheet.cell(1,4).value = '运费'
sheet.cell(1,5).value = '发货地点'
sheet.cell(1,6).value = '店铺名'
sheet.cell(1,7).value = '图片url'
#写入数据
for i in range(len(auctions)):
print(i)
sheet.cell(i+2, 1).value = auctions[i]['raw_title']
sheet.cell(i+2, 2).value = auctions[i]['view_price']
sheet.cell(i+2, 3).value = auctions[i]['view_sales']
sheet.cell(i+2, 4).value = auctions[i]['view_fee']
sheet.cell(i+2, 5).value = auctions[i]['item_loc']
sheet.cell(i+2, 6).value = auctions[i]['nick']
sheet.cell(i+2, 7).value = auctions[i]['pic_url']
workbook.save('taobao.xlsx')
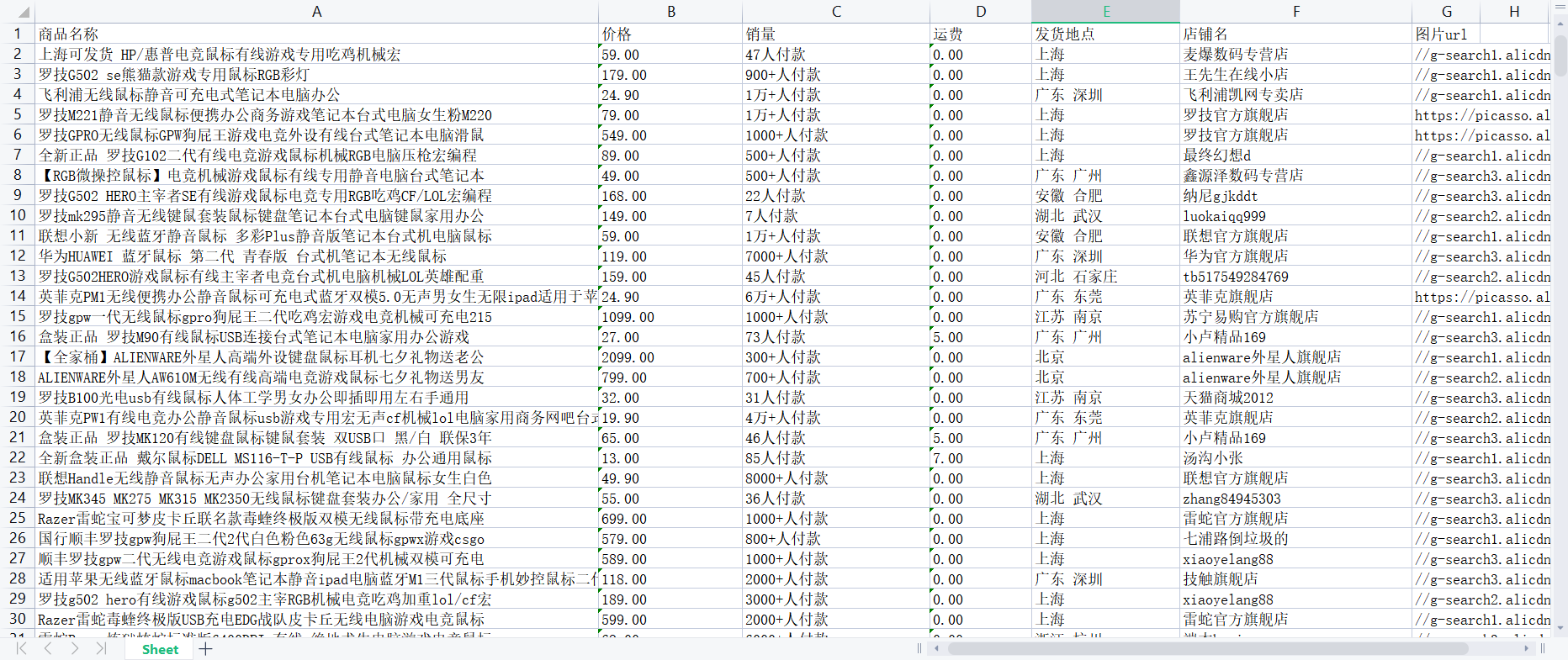
结果
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号