
Pytorch神经网络拟合sin(x)函数
Pytorch简介
PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多主流框架如TensorFlow都不支持的。 PyTorch提供了两个高级功能:
- 具有强大的GPU加速的张量计算(如Numpy)
- 包含自动求导系统的深度神经网络
用到的包
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
生成训练用的数据
x = torch.linspace(-torch.pi,torch.pi,10000) #(1000, )
x = torch.unsqueeze(input=x, dim=1) # (1000, 1)
y = torch.sin(x) # (1000, 1)
如果可以的话,放到GPU里训练(快很多)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device to train")
x = x.to(device)
y = y.to(device)
定义模型
两层,x --> (1,70) --> sigmoid --> (70,1) --> y_pred
class NeuralNetwork(nn.Module):
def __init__(self):
# 调用
super(NeuralNetwork, self).__init__()
#
self.linear_relu_stack = nn.Sequential(
nn.Linear(1, 70),
nn.Sigmoid(),
nn.Linear(70,1)
)
def forward(self, x):
y_pred = self.linear_relu_stack(x)
return y_pred
定义损失函数和优化器,开始训练
# 把模型放到GPU上训练
model = NeuralNetwork().to(device)
#均方差做损失函数
loss_fn = nn.MSELoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#用下面这个Adam优化器会收敛的快很多
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 迭代3000次
batches = 3000
plt.figure("regression") #新建一张画布,打印数据点和预测值
plt.ion() #开启交互模式
plt.show()
for i in range(batches):
y_pred = model(x)
loss = loss_fn(y_pred, y)
#
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
loss, batch = loss.item(), i
print(f'loss: {loss} {batch}')
plt.cla()
plt.plot(x.cpu().numpy(), y.cpu().numpy())
plt.plot(x.cpu().numpy(), y_pred.detach().cpu().numpy())
plt.pause(0.001)
保存模型和读取模型参数
# 保存
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
# 读取
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))
结果
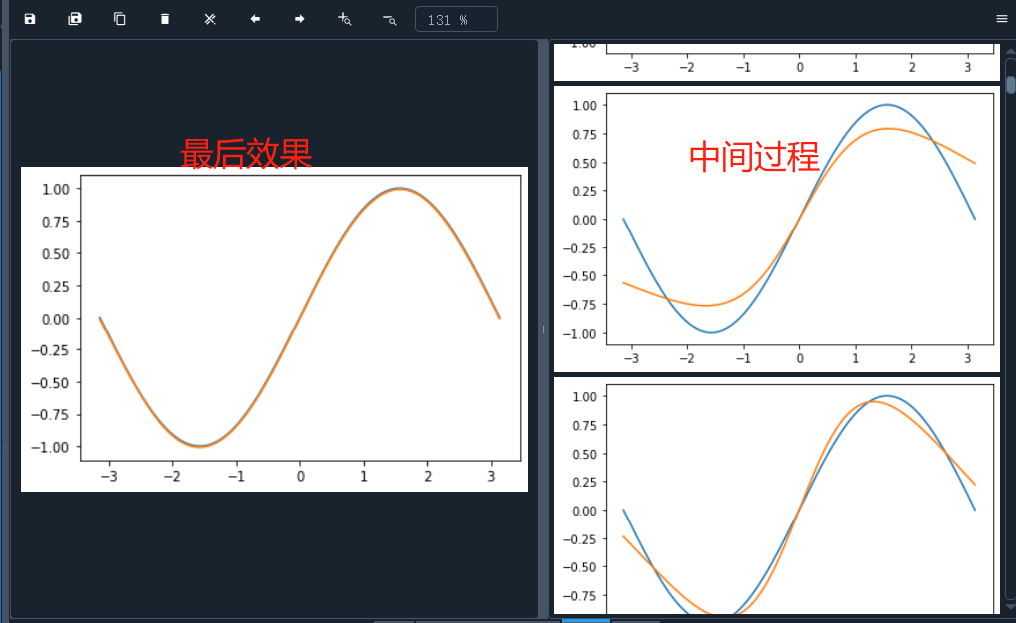
全部代码
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
# 生成训练数据用的数据
x = torch.linspace(-torch.pi,torch.pi,10000) #(1000, )
x = torch.unsqueeze(input=x, dim=1) # (1000, 1)
y = torch.sin(x) # (1000, 1)
plt.plot(x.numpy(),y.numpy())
# 如果可以用cuda就在cuda上运行,这样会快很多
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device to train")
x = x.to(device)
y = y.to(device)
# 定义NN模型,继承自nn.Module
class NeuralNetwork(nn.Module):
def __init__(self):
# 调用
super(NeuralNetwork, self).__init__()
#
self.linear_relu_stack = nn.Sequential(
nn.Linear(1, 70),
nn.Sigmoid(),
nn.Linear(70,1)
)
def forward(self, x):
y_pred = self.linear_relu_stack(x)
return y_pred
# 把模型放到GPU上训练
model = NeuralNetwork().to(device)
#均方差做损失函数
loss_fn = nn.MSELoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#用下面这个Adam优化器会收敛的快很多
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 迭代3000次
batches = 3000
plt.figure("regression") #新建一张画布,打印数据点和预测值
plt.ion() #开启交互模式
plt.show()
for i in range(batches):
y_pred = model(x)
loss = loss_fn(y_pred, y)
#
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
loss, batch = loss.item(), i
print(f'loss: {loss} {batch}')
plt.cla()
plt.plot(x.cpu().numpy(), y.cpu().numpy())
plt.plot(x.cpu().numpy(), y_pred.detach().cpu().numpy())
plt.pause(0.001)
# 保存
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
class NeuralNetwork(nn.Module):
def __init__(self):
# 调用
super(NeuralNetwork, self).__init__()
#
self.linear_relu_stack = nn.Sequential(
nn.Linear(1, 70),
nn.Sigmoid(),
nn.Linear(70,1)
)
def forward(self, x):
y_pred = self.linear_relu_stack(x)
return y_pred
x = torch.linspace(-torch.pi,torch.pi,10000) #(1000, )
x = torch.unsqueeze(input=x, dim=1) # (1000, 1)
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))
y = model(x)
plt.plot(x.numpy(), y.detach().numpy())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号