


线性回归
线性回归
一元线性回归
假设对于观测对象x和y我们收集到了一批数据 ,
我们希望找到一个一元线性函数(一个因变量y和一个自变量x)
使得函数(模型)预测出来的值和原来的值的误差平方和
最小,也即是它们的欧式距离最小,这样就会有
我们定义代价函数为(这里添加系数是为了方便求导)
所以问题变成了,寻找出和使得最小,也即有,达到我们预测(拟合)的目的
即
因为代价函数是一个凸函数,当它关于w和b的偏导都为0时,则可以取得和的最优解
令对和求偏导,得
梯度下降法
梯度下降就是通过迭代,不断让函数的参数向着梯度下降的方向走一点点,不断的逼近最优解
设更新步长为,则有更新公式
直接求解
我们也可以直接算出它的闭式解(解析解)。令上面两个偏导数等于0,就得到
多元线性回归
多元线性回归就是具有多个自变量和一个因变量的回归模型,假设自变量x有m个特征,我们对x和y进行了n次观测,则有模型
把和写成向量的形式(这里代表对的第次观测得到的数据)
那我们可以把这个方程写成向量方程的形式
进一步的,对于所有的数据,有数据矩阵
其中,每一行是一次观测,每一列是一个维度(特征)
然后,为了方便,再把常数项纳入中,并且在中多加一列1
则有矩阵方程
则我们的优化目标就是
令
对求偏导得
我们的目标就是让
梯度下降法
像一元线性回归那样,有
正规方程法
令
则当是正定或者满秩的时候,方程有唯一解(因为互不共线的向量只能找到唯一一个线性组合使其等0)
其实还有很多的,但是我很懒,不想写了
其实线性回归不单只可以用来拟合线性模型,还可以用来拟合多项式函数、对数函数、指数函数等等,只要通过一定的变换,把原来的问题转换成线性的问题就可以求解,本质上还是在优化一个凸函数,一个最小二乘的问题,其实也不一定是最小二乘,也可以用其他的,比如说误差绝对值,但这种东西是视情况而论的,就这样吧。
编程实现
理论理清楚了,编程就不会太难
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 14 12:53:36 2021
@author: koneko
"""
'''
多元线性回归
'''
import numpy as np
import matplotlib.pyplot as plt
def lossf(X,w,y):
return np.sum((y-np.dot(X,w))**2)
def init(X,y):
if X.ndim == 1:
X = X.reshape(X.size,1)
if y.ndim == 1:
y = y.reshape(y.size,1)
#在x后面多加一列1
X = np.c_[X,np.ones([X.shape[0],1])]
n,m = X.shape
w = w = np.random.normal(1,0.1,m)
w = w.reshape(w.size,1)
return X,y,w
'''
使用正规方程来求
'''
def LRWithNormalEquation(x,y):
X,y,w = init(x,y)
inv = np.linalg.inv(np.dot(X.T,X))
R = np.dot(X.T,y)
w = np.dot(inv,R)
return w
'''
通过迭代的方法来求
'''
def LRWithGradientDesc(x,y):
#初始化
X,y,w = init(x,y)
delta = 0.001 #收敛系数
alpha = 0.001 #学习速率
max_step = 10000 #最大次数
gradient = 1000
err = 1000
loss = []
i = 1
while err>delta and i < max_step:
i += 1
gradient = 2*np.dot(X.T,(np.dot(X,w)-y))
w = w - alpha*gradient
err = lossf(X,w,y)
loss.append(err)
plt.plot(loss)
return w
def f(X,w):
return np.dot(X,w)
x = np.array([0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,
2.25,2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50])
y = np.array([10, 26, 23, 43, 20, 22, 43, 50, 62, 50, 55, 75,
62, 78, 87, 76, 64, 85, 90, 98])
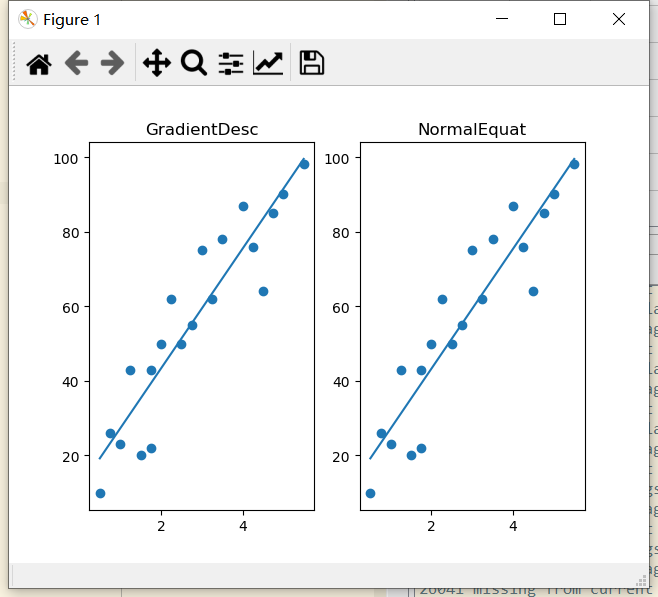
w1 = LRWithGradientDesc(x,y)
w2 = LRWithNormalEquation(x,y)
X,y,w = init(x,y)
y1 = f(X,w1)
y2 = f(X,w2)
plt.subplot(1,2,1)
plt.title('GradientDesc')
plt.scatter(x,y)
plt.plot(x,y1)
plt.subplot(1,2,2)
plt.scatter(x,y)
plt.plot(x,y2)
plt.title('NormalEquat')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!