CDN边缘节点容器调度实践(上)
又拍云容器云是基于 Docker 的分布式计算资源网,节点分散在全国各地及海外,提供电信、联通、移动和多线网络,融合微服务、DevOps 理念,满足精益开发、运维一体化,大幅降低分布式计算资源构建复杂度,大幅降低使用成本。
上文是对容器云的简介,又拍云容器云是一个基于 Docker 的边缘容器网络。
过去,又拍云数据中心用的是基于 Mesos 的容器调度平台。它把数据中心的 CPU、内存、磁盘等抽象成一个资源池,Mesos 官方称之为分布式系统内核。
Mesos架构
下图是 Mesos 容器调度平台的架构图。
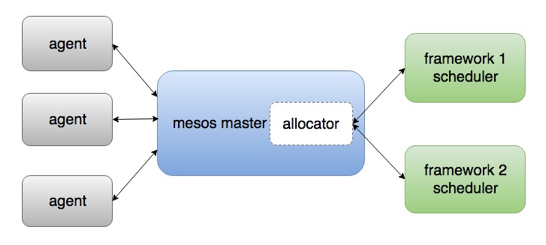
△ Mesos 架构
Mesos 调度平台相当于数据中心的 Master,同时在每个节点上都有一个 Agent。当每个Agent 启动后会向 Mesos 注册,Agent 携带的资源信息,让 Mesos 决定每个框架的资源数量。当框架收到资源后,再根据需求调度资源。
Mesos Master 调度机制后面是 framework,通过 framework 可以满足数据中心的容器调度。
边缘容器调度方案概述
下面我们简要介绍下又拍云的边缘容器调度方案。又拍云边缘节点容器调度方案需要有一个部署在数据中心的 Master,负责集中调度统一管理。而 Agent 则部署在全国各个边缘节点上,每个节点的每台机器上都会有一个 Agent,负责采集数据,管理 Docker。在边缘运行长期服务,支持故障恢复。同一个节点的一批机器会组成一个集群。另外,因为又拍云有不同需求的客户,所以边缘节点需要部署多种功能,功能部署时要完成容器网络的隔离,还会有一些负载均衡和定制化的需求。
版本 1 实现了调度策略最基本的功能
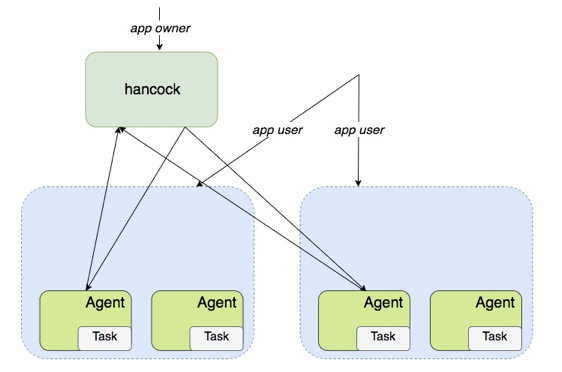
△ 版本1
上图是最基础的版本1 Master—Agent 架构。最上面是 Hancock (又拍云内部项目名称),它本身就是 Master,App 的拥有者可以通过 API 接口接入,部署任务、创建 Docker 项目到边缘节点。
这两个虚线的框分别表示两个不同的节点,每个节点上数量不等的机器会组成一个小集群,每个机器上会部署一个 Agent, Agent 会负责创建各个 Docker 的 Task,容器服务的用户(App user ) 直接会去边缘节点访问容器服务。
Agent 启动后会上报消息到 Master, 而 Master 会根据用户的请求和上报的消息下发指定给 Agent 。由于边缘节点和数据中心的网络可能处于不稳定的状态,在处理数据的时候会出现超时、延迟等问题,同步操作可能会导致用户的请求一直得不到响应,最终导致信息丢失等问题,因此 Master 与 Agent 的数据交互、消息处理都是异步进行的。这种情况下,用户只要把请求提交到 Hancock Master 上,这个任务就会分发到所有的边缘节点。
下面是 Master-Agent 消息介绍:
- 上报消息 Agent -> Master
- 下发指令 Master -> Agent
Resource 消息
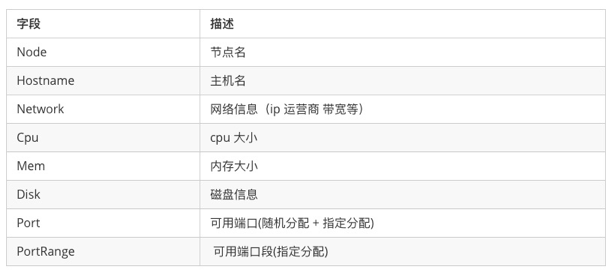
当 Agent 启动时会携带 Resource 消息 ,当携带资源信息发生变更时,会更新一次 Resource 消息 。如图所示,Agent 通过节点名和主机名来唯一表示一台边缘设备,设备的资源信包括,网络信息(包括运营商信息、宽带信息),CPU, 内存, 磁盘,可用端口信息等,其中端口段的分配是因为有个摄像头的用户一个服务需要用到几千个端口,这种情况就不再适合逐个端口进行随机或者指定分配,这样维护成本会变得很高。
Offer 消息

Agent 会定时上报 Offer 消息上报给 Master,会发送机器的 load 和当前网络状况的使用情况、CPU、Memory、Disk等使用情况信息,以此维持 Master 与 Agent 之间的联系。
一般来说,Master 可以计算出 CPU、Memory、Disk 的使用情况。但是 load 和网络状况,Master 是无法知晓的,所以每隔一段时间就要上报,以供 Master 合理的调度 Docker 机器,比如不应该再安排服务部署到 load 较高的机器上。上述就是 offer 的作用。
Update 消息
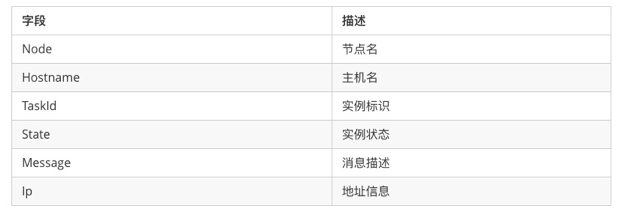
负责提供实例的状态变更,Docker 实例运行成功失败等信息, 由 Agent 实时上报给 Master, 包含任务的状态信息和相关描述。方便 Master 进行故障恢复等操作。
Containers 消息
负责提供机器容器列表, 防止有僵尸任务和任务遗漏, 由 Agent 定时上报给 Master, Master 负责检查。
Master 到 Agent 的指令下发过程中,主要包括两个类下发指令:
- 实例的创建,如增删改查,把客户增删改查请求转变为对容器的操作
- 镜像操作,如镜像拉取,镜像查询。比如 Docker 镜像很大的时候,在边缘节点拉取镜像可能会超时。所以我们设置了一个单独的镜像操作,保证在创建容器前,可以预先异步提交拉取命令。
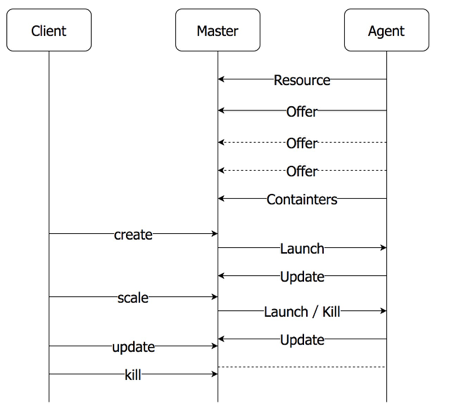 △ 处理流程
△ 处理流程
上图是消息处理流程,当 Agent 启动时上报 Resource、Offer、Container 等定时消息。其中 offer 消息频率最高, 一旦一段时间没有受到 Offer 消息, Master 会尝试迁移这个 Agent 对应机器上的所有容器实例。
上述版本 1 的架构实现了调度策略最基本的功能。当 Master 收到各个集群中 Agent 上报的资源时,通过自定义策略来完成任务调度。一般来说是寻找满足条件的(Node Cpu Mem Disk Port 等)机器。再选择根据带宽、load 等指标,进行权重估算,在估算出权重的前提下进行随机调度。在权重类似的情况下,每次调度尽可能让同一服务的各个实例分布到节点的不同机器,保证在某台机器崩溃的情况下,其他实例正常运行保证高可用。
版本 2 增加 calico,负责网络控制和访问限制
在版本 1 中,Master 和 Agent 已经完成了两者之间的消息交互。App 拥有者可以创建服务,并且在边缘机器上创建 Task。
但我们不希望客户的服务混杂在一起,希望可以隔离不同所有者的容器网络, 可以完成一些访问控制的功能。又拍云使用了 calico 的方案,它是基于 BGP 的路由协议的三层通信模型,不需要额外报文封装。
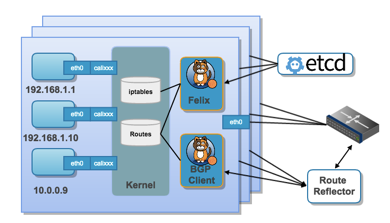
△ 容器网络(图片来自网络)
如图所示,其中 calico BGP client 负责每个节点和集群其他节点建立 BGP Peer 连接,增长趋势是 O(n^2),它并不适合大规模的集群网络, 解决方法是 Route Reflector,选择一部分节点作为 Global BGP Peer,由它们互联来交换路由信息。而又拍云每个边缘集群都是小规模集群网络,O(n^2) 的增长是可以接受的,并不需要 Route Reflector 的机制。
其中 Felix 负责节点网络相关配置。由它负责配置路由表、iptables 表项等。以便完成访问控制和隔离的功能。
另外,集群中还会有一个分布式的 kv 数据库—— etcd,负责保存网络元数据。
calico 的优点: 三层互联,不需要报文封装。访问控制, 满足隔离网络, 隔离容器。
calico 的缺点: 网络规模限制, iptables 和路由表项限制。
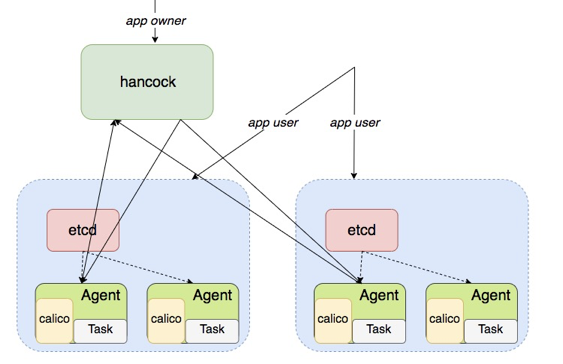
△ 版本2
在我们的场景下,它很好的满足了需求。加上 calico 方案,版本 2 的架构如上图所示。
对内容感兴趣的小伙伴,欢迎关注下我们,《CDN边缘节点容器调度实践(下)》将于明天推送。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号