Polaristech 刘洋:基于 OpenResty/Kong 构建边缘计算平台
2019 年 3 月 23 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·北京站,Polaristech 技术专家刘洋在活动上做了《基于 OpenResty / Kong 构建边缘计算平台》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。活动将陆续在深圳、北京、上海、杭州、成都、武汉等城市巡回举办。

刘洋,Polaristech 技术专家,曾就职于 Redhat、阿里云,10 余年研发经验,近期加入 Polaristech 投入边缘计算领域。作为 RHCA,不仅在 Linux 领域拥有丰富的技术积累,同时在工作中也积累了大量的市场经验。
以下是分享全文:
大家好,我是刘洋,首先介绍一下我们 Polaristech 团队做的几件事情,第一是 Nginx as a Service,因为很多传统的厂商大量使用 Nginx 作为网关,但是流量上来之后管理非常困难;第二是 API 网关,一方面是大家常理解的网关,另外部分是微服务的治理,比如 Service Mesh,我们用提供了一个优雅的方式解决微服务的网关问题;第三个部分就是边缘计算。
边缘计算与边缘节点
什么是边缘节点
边缘计算是一种将主要处理和数据存储放在网络的边缘节点的分布式计算形式。跟云计算侧重的点是不同的,“边缘”是一个相对的概念,比如数据源、数据中心、云等等,从最边上的节点开始,都可以叫做边缘。相对于传统“中心计算“,数据上传到数据中心,通过中心的资源完成存储和计算。
但随着万物互联时代的到来,智慧城市、智能制造、智能交通、智能家居,5G 时代、宽带提速、IPv6 的不断普及,导致数百亿的设备接入网络,在网络边缘产生 ZB 级数据,传统计算难以满足物联网时代大带宽、低时延、大连接的诉求,在这种情况下,今天的技术架构还能不能支撑那时大家的想象当中的计算机的世界?所以,我们想做一些架构上的创新,或者是尝试。
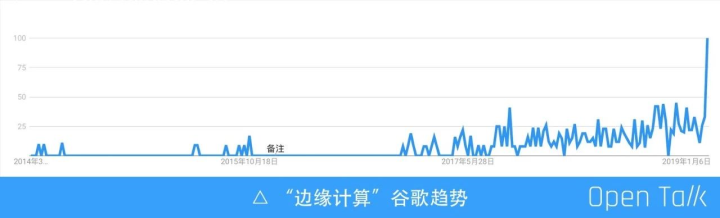
上图可以看到从 2015-2019 年,边缘计算的趋势一直往上走。关于边缘计算,有很多定义的方式,首先定义边缘节点:非数据中心的计算资源, 都是边缘节点。需要注意的是作为边缘计算平台,不仅仅由边缘计算节点组成,也包含数据中心的节点,在实际中,我们遇到了许多的边缘节点场景,比如说楼宇、园区、基站、监控设备、车辆等,把这些的非中心的计算资源、网络资源、存储资源都叫做边缘节点。
边缘节点的环境和特点
我认为环境是边缘计算的最大前提,数据中心通常是可靠计算环境,包括电力、网络、温度、专业运维等。如果把计算放到边缘,比如在一个居民楼中有边缘节点,我们总结了几点:
- 电力不可靠,可能停电或者是插线板坏了。
- 网络不稳定,带宽没有保障,延迟没有保障。
- 物理环境缺乏统一的条件,包括温度、湿度、气压等。
- 算力不统一,今天两核的,明天可能弄一个四核的。
- 连接方式以 TCP/IP 为主,包括基于移动通信的 4G 和 WIFI,或通过 IoT 的协议 LoRa、NB-IoT 等。
总结起来,边缘节点处于不可靠计算环境中,而且没有专业的运维,在中关村还方便找运维,万一如果在攀枝花、牡丹江呢?不好说。
为什么基于 OpenResty / Kong

基于数据中心的“云计算”是以“计算资源”为中心的,而边缘计算本质是以“网络资源”为中心的,是面向网络的计算。那么为什么我们选择 OpenResty 和 Kong 为核心来构建边缘计算平台?
第一,因为 OpenResty 是面向应用的网络架构,现在有一个流行词叫做应用交付网络简称 ADN。OpenResty 具有小巧、灵活、可靠、高效稳定的网络处理能力,因为 OpenResty 下面都是 Nginx 非常高效一个包不到 20 兆,基本上可以稳定运行在一切能够支持 Linux 的平台上。
第二,OpenResty 是可扩展的,数据到达边缘节点后,OpenResty 可以把各种数据和常见的计算框架结合起来。
第三,Kong 可以看成是 OpenResty 领域里的 Struts(类比 Java)或者 Rails(类比 Ruby),提供了很多配置能力和开发框架,对于数据的处理非常方便。
第四,OpenResty / Kong 除了适应边缘节点环境,同样适用各种级别数据中心环境。在数据被最终存储之前,OpenResty / Kong 可以构建整个应用数据的传输链路,并完成各个环节的计算任务。
最后,OpenResty / Kong 很“皮实”,基于 OpenResty / Kong 组成的计算节点,可以做到“RESET即恢复功能” 我们希望做到什么?就是若干年前大家去网吧,网管只会一招"重启"。因为在边缘,没有专业的人员,所以希望当这个东西坏了,重启一下就可以恢复了。基于这几点,我们最后选择了 Kong 加 OpenResty。
除了 OpenResty / Kong 还用了什么
首先是使用 CentOS 作为操作系统。PostgreSQL 是 Kong 原生支持的一个数据库,Kong 原生支持两种数据库,一种是 PostgreSQL,一种是 Cassandra。
还有我们自己加了一个MySQL,因为国内 MySQL 的用户群体非常大。PostgreSQL 是我们最常用和主推的数据库,虽然在国内不是特别火,但是 PostgreSQL 会有非常多的支持,效率也很高。
第三个是 RocksDB,主要部署在边缘节点,用于以 k/v 形式缓存数据,包括上行和下行数据。还有是基于 Nodejs 的调度程序,调度程序是边缘计算的核心能力。
最后是 Kubernetes,用于数据中心里计算资源管理,提供多租户的数据中心计算能力。
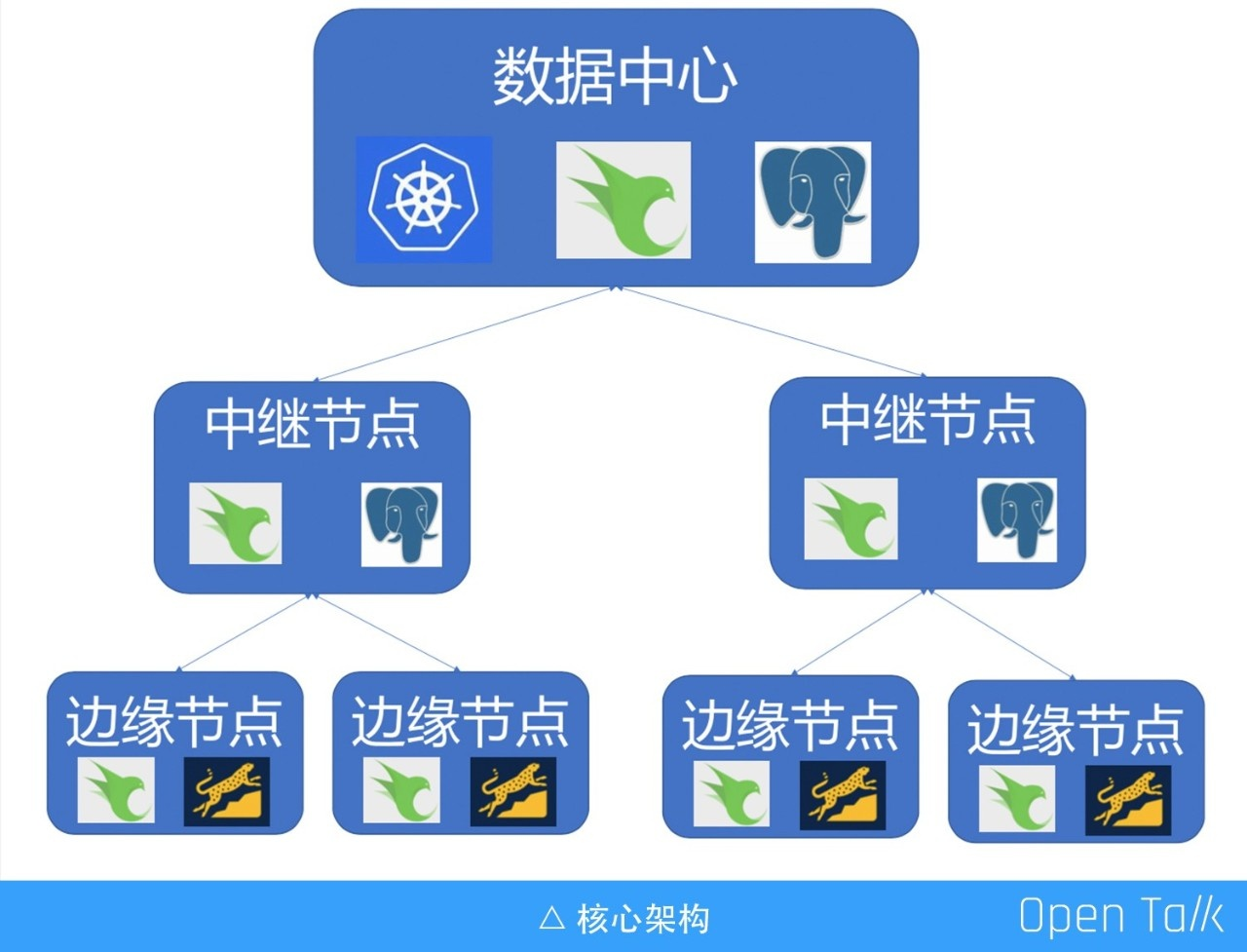
核心架构采用三层或者是 1+N+1,最上层是数据中心,无论是在自己的本地数据中心里面还是在云上都可以。这一层使用 K8S 做数据的核心应用包括 ESS 和 OSS,做多租户的计量计费、数据的调度、节点管理等,然后是标准的 X86 服务器。
中间是中继节点,它的应用是多种多样的,比如一个小地方的数据中心,或者像一些云厂商,会提供边缘节点,在边缘节点和数据中心之间,上行和下行数据通过一层或者多层的中继节点中转和处理,从中继节点到数据中心很像 CDN,虽然不是专线,但是它的网络质量会比纯公网传输好一些。
最下面是边缘节点,做终端的流量下发以及上行流汇聚,在这一层首先是做静态或者是动态内容的缓存,静态缓存很简单,像 CDN 一样有图片、视频等的缓存,动态缓存是上行请求的数据,它可以把 HTTP body 、head 等缓存在边缘节点,这样就不用再走一遍 CDN 或者到数据中心进行请求了,大大加速用户的访问,同时我们也会用 RocksDB 把数据缓存下来。
总体来讲,首先我们做了集成管理系统,做边缘计算应用的交付与下发并把应用部署到边缘节点上,并对远程边缘的设备的进行管理、监控、调度、计量计费等,核心都是在这个中心系统来完成的。设备管理,主要是对设备状态的管理、应用的下发、配置的下发等。我们基于 HTTP 的框架,去实现边缘节点数据的上下行,特别是上行采取了类似 MQTT 的方式,简称叫 HTTPQ,在本地上传数据的时候先把数据存在 Q 里面。因为网络有可能会断掉,所以会通过 Q 的方式,先把数据放在边缘节点,然后通过 Q 的方式传回数据中心。在边缘用 FASTCGI 的方式,提供一个标准的应用方式,主要还是考虑到了边缘的不可靠环境。最后就是调度、监控和流量分发,也是最主要的核心点。
总结

我们的边缘计算平台是云计算加边缘计算,既有中心节点又有边缘节点;不同点就在于云或者是数据中心面对的是数据的计算和存储,边缘计算是面向数据流动;另外,常用的数据中心软件,不适合在边缘的环境里应用,它对环境和运维的要求比较高;在面对不确定、不可靠的计算环境,异步很重要,所以我们用 MQ 的方式去做数据的上行; “Reset-To-Work” 这个核心的设计观念,因为管理配置和下发都是通过中心节点做的,边缘节点出现了任何问题,只需重启就可以直接恢复了,因为在中心有对它的监控和配置的集中管理;边缘计算和云计算一样最重要的就是监控加调度,所以我们以网络监控为主去监控边缘节点的可用性,以及缘节点的适用应用、设备、环境、使用率等;系统中云计算是面向 SLA 的,边缘计算是面向流量的:把流量交付出去,和把流量收集上来,是边缘计算的核心述求。如果云计算是一个航母集群的话,那边缘计算就是一把 AK,适应于各种环境,能够用最小的代价去解决最核心的问题。
观看演讲视频和 PPT 可前往:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号