布隆过滤器(Bloom Filter)的简介, 优缺点以及使用场景
一 :什么是布隆过滤器?
(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。
二:使用布隆过滤器的 优势 和 缺点?
优点:
它的优点是空间效率和查询时间都远远超过一般的算法。
这是个非常神奇的数据结构,仅需极少的空间就可以判断一个元素是不是在一个集合之内,判断key是否存在。
缺点:
有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,
但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
三:布隆过滤器适用的场景?
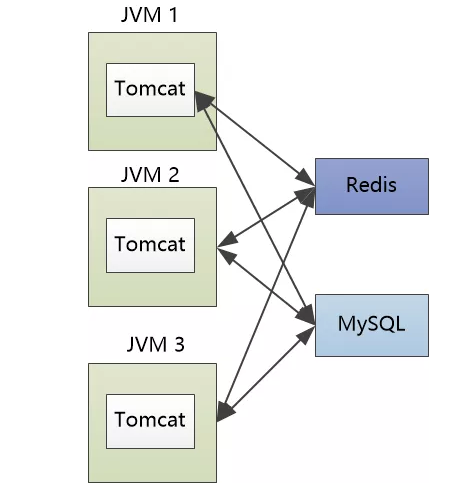
我们可以把所有的用户ID建立一个布隆过滤器,这样当那些黑客的请求过来以后,先用这个过滤器拦截一下,
如果黑客要访问的用户ID不在这个过滤器中,我们就直接把他过滤出去。”
金无足赤,人无完人,Bloom Filter也会有误报,即使某个用户ID不在集合中,他也可能报告说在集合中。
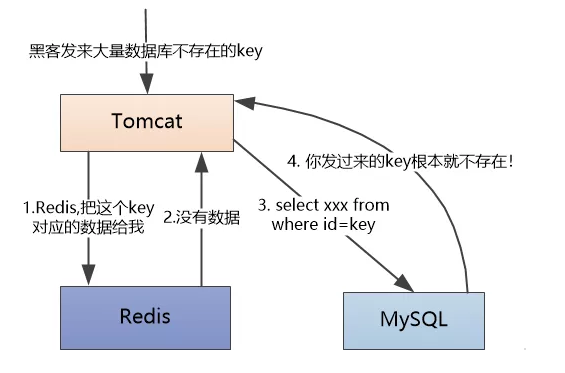
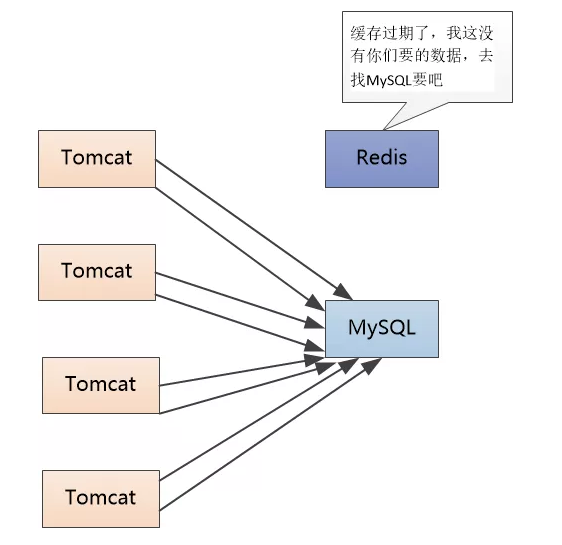
这个时候Tomcat就认为这是一个合法的用户ID,就去Redis中查,不存在,然后到我这里查,还是不存在。”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号