
【Python进阶】并发编程方式
并发编程方式有哪些?
- threading模块---线程
- asyncio模块---协程
- concurrent.futures模块---进程+线程(应用于异步调用)
- multiprocessing模块---进程
进程、线程、协程?
- 进程:运行起来的程序就是进程,是操作系统分配资源的最小单位。
- 线程:线程是进程的组成部分,一个进程可以拥有多个线程,一个线程必须有一个父进程。
- 协程:是线程的更小切分,又称为“微线程”,是一种用户态的轻量级线程。
三者关系:进程里有线程,线程里有协程
进程、线程、协程的区别
- 进程:
针对于python语言执行环境来说,多进程是利用多核CPU来完成任务,进程拥有独立的内存空间,所以进程间数据不共享,进程之间的通讯是由操作系统完成的,在切换时,CPU需要进行上下文切换,导致通讯效率比较低、开销比较大。 - 线程:
多线程是在一个进程内运行,共享进程的内存空间,通讯效率较高、开销较小。但缺点是:因为python底层的GIL锁(global interpeter lock),python的底层的同步锁太多导致多线程被同步很多次,搞成并发效果不佳。 - 协程:
一个可以挂起的函数,协程的调度完全由用户控制,用函数切换,开销极小。
多进程、多线程、协程的使用场景
- 多进程:
CPU密集运算,大部分时间花在计算 - 多线程、协程:
IO密集型(网络IO、磁盘IO、数据库IO),大部分时间花在传输
threading模块
Python中的threading模块提供了多线程编程的基本支持。使用该模块可以创建和管理线程,从而实现并发执行。
示例
import threading
def worker():
print('Worker thread started')
# do some work here
print('Worker thread finished')
if __name__ == '__main__':
print('Main thread started')
# create a new thread
t = threading.Thread(target=worker)
# start the new thread
t.start()
print('Main thread finished')
执行结果:
Main thread started
Worker thread started
Main thread finished
Worker thread finished
asyncio模块
Python中的asyncio模块提供了异步编程的支持。使用该模块可以实现协程,从而在单线程中实现并发执行。
import asyncio
async def worker():
print('Worker task started')
# do some work here
print('Worker task finished')
if __name__ == '__main__':
print('Main task started')
# create a new event loop
loop = asyncio.get_event_loop()
# run the worker coroutine
loop.run_until_complete(worker())
# close the event loop
loop.close()
print('Main task finished')
执行结果:
import asyncio
async def worker(): # 一个异步函数worker,该函数会在一个协程中执行。
print('Worker task started')
# do some work here
print('Worker task finished')
if __name__ == '__main__':
print('Main task started')
# create a new event loop
loop = asyncio.get_event_loop() # 创建了一个新的事件循环loop
# run the worker coroutine
loop.run_until_complete(worker()) # 调用run_until_complete方法来运行worker协程
# close the event loop
loop.close() # 关闭了事件循环
print('Main task finished')
执行结果:
Main task started
Worker task started
Worker task finished
Main task finished
程序先执行了主任务中的代码,然后通过事件循环执行了worker协程。
协程是在单线程中执行的,因此程序的执行速度得到了提高。
concurrent.futures模块
concurrent.futures模块是Python3中的新模块,它提供了线程池和进程池的实现。使用该模块可以更方便地实现并行执行。
import concurrent.futures
def worker():
print('Worker thread started')
# do some work here
print('Worker thread finished')
if __name__ == '__main__':
print('Main thread started')
# 在主线程中创建了一个线程池executor,并设置最大线程数为2。接着,通过调用submit方法将worker函数提交给线程池。
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
# submit worker function to the pool
future = executor.submit(worker)
print('Main thread finished')
执行结果:
Main thread started
Main thread finished
Worker thread started
Worker thread finished
从上面的输出结果可以看出,程序先执行了主线程中的代码,然后通过线程池执行了worker函数。线程池会自动管理线程的创建和销毁,从而使程序更加高效。
multiprocessing模块
Python中的multiprocessing模块提供了多进程编程的支持。使用该模块可以在不同的进程中执行任务,从而实现并发执行。
import multiprocessing
def worker():
print('Worker process started')
# do some work here
print('Worker process finished')
if __name__ == '__main__':
print('Main process started')
# create a new process
p = multiprocessing.Process(target=worker)
# start the new process
p.start()
print('Main process finished')
执行结果:
Main process started
Main process finished
Worker process started
Worker process finished
创建了一个新的进程,并在新进程中执行worker函数。
主进程和新进程是并行执行的,因此程序的执行速度得到了提高
multiprocessing.Process详解
Process([group [, target [, name [, args [, kwargs]]]]])
- group分组,实际上不使用
- target表示调用对象,你可以传入方法的名字
- args表示给调用对象以元组的形式提供参数,比如target是函数a,他有两个参数m,n,那么该参数为args=(m, n)即可
- kwargs表示调用对象的字典
- name是别名,相当于给这个进程取一个名字
方法使用流程
- 实例化进程池 p=Pool()。
- 通过apply_async()函数向进程池中添加进程。
- 通过p.close()函数关闭进程池,关闭之后无法继续添加新的进程。与此同时,CPU开始从进程池中取进程,若CPU有N核,则CPU每次只会取N个进程,待N个进程全部执行完毕,再取出N个。直到将进程池中的进程取完为止。
- 通过p.join()函数等待所有进程被取出并执行完毕。
# 如果有大量进程,则可以用进程池,批量添加
from datetime import datetime
from multiprocessing import Process,Pool
import os,time
def music(func,loop):
for i in range(loop):
print ("I was listening to %s. %s" %(func,time.ctime()))
time.sleep(1)
def movie(func,loop):
for i in range(loop):
print ("I was at the %s! %s" %(func,time.ctime()))
time.sleep(5)
if __name__ =='__main__': #执行主进程
# 主进程
print('这是主进程,进程编号:%d' % os.getpid())
t_start = datetime.now()
pool = Pool()
for i in range(8): # CPU有几核,每次就取出几个进程
pool.apply_async(music, args=('爱情买卖',2))
pool.apply_async(music, args=('阿凡达',3))
pool.close() # 调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了
pool.join() # 对Pool对象调用join()方法会等待所有子进程执行完毕
t_end = datetime.now()
print('主进程用时:%d毫秒' % (t_end - t_start).microseconds)
multiprocessing 支持进程之间的两种通信通道:Queue(队列)、Pipe(管道)
进程间通信---Pipe(管道)
Pipe可以是单项(half-duplex),也可以是双向(duplex)。通过multiprocessing.Pipe(duplex=False)创建单向管道(默认双向)。一个进程从Pipe一端输入对象,然后被Pipe另一端的进程接收,单向管道只允许管道的一端的进程输入,而双向管道从两端输入。
import multiprocessing
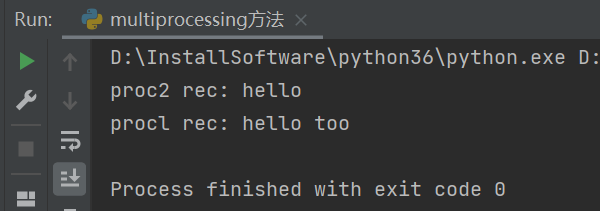
def proc1(pipe):
pipe.send('hello')
print('procl rec:',pipe.recv())
def proc2(pipe):
print('proc2 rec:', pipe.recv())
pipe.send('hello too')
if __name__=='__main__':
multiprocessing.freeze_support()
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=proc1,args=(pipe[0],))
p2 = multiprocessing.Process(target=proc2,args=(pipe[1],))
p1.start()
p2.start()
p1.join()
p2.join()
执行结果
进程间通信---Queue(队列)
Queue类与Pipe相似,都是先进先出的结构,但是 Queue类允许多个进程放入,多个进程从队列取出对象。
Queue类使用Queue(maxsize)创建,maxsize表示队列中可以存放对象的最大数量。
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
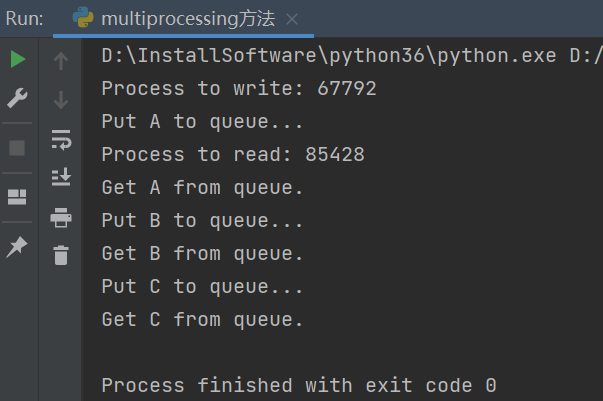
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
执行结果
工具选择
不同的方式适用于不同的场景,可以根据需要选择最合适的方式。
场景应用
- 多线程、协程---IO密集型(网络IO、磁盘IO、数据库IO)
- 网路编程(requests请求、文件读取、修改等操作、数据库操作、实时通信、网络游戏等)
- 爬虫技术
- 多进程---(利用多核CPU进行并行计算,提高程序的执行效率。)
CPU密集型计算
分布式应用
多设备并行处理相同数据(appium多设备并行运行)---利用了多进程的互不干扰特性,就算某个进程僵死,也不会影响其他进程
pytest-xdist
视频的压缩解码任务
多线程编程可以提高程序的效率和执行速度,但需要注意线程安全和*锁**的使用。
进群交流、获取更多干货, 请关注微信公众号:

> > > 咨询交流、进群,请加微信,备注来意:sanshu1318 (←点击获取二维码)
> > > 学习路线+测试实用干货精选汇总:
https://www.cnblogs.com/upstudy/p/15859768.html
> > > 【自动化测试实战】python+requests+Pytest+Excel+Allure,测试都在学的热门技术:
https://www.cnblogs.com/upstudy/p/15921045.html
> > > 【热门测试技术,建议收藏备用】项目实战、简历、笔试题、面试题、职业规划:
https://www.cnblogs.com/upstudy/p/15901367.html
> > > 声明:如有侵权,请联系删除。
============================= 升职加薪 ==========================
更多干货,正在挤时间不断更新中,敬请关注+期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号