
【Python基础】Python基础教程
Python环境搭建
变量的命名规范
- 变量名虽然支持中文,但不推荐使用
- 可以使用数字,但不能以数字开头
- 不可使用特殊字符,下划线除外
- 区分大小写,在python中A和a不是同一个变量
- 不能和关键字同名
- 尽量遵循PEP8规则
PEP8规则:
-
常量:大写加下划线
A_ -
弱私有变量(protected):单下划线开头加小写
_a -
强私有变量(private): 双下划线开头加小写
__a -
内置变量:小写、两个前导和后置下划线
__a__ -
函数和方法:小写和下划线
def a_() -
私有方法:小写和一个前导下划线
def _a() -
特殊方法:小写、两个前导和后置下划线
def __a__() -
类:驼峰格式命名
class FunDemo()
变量或方法单下划线开头表示弱私有(受保护变量/方法)---保护类型只能允许其本身与子类进行访问,不能用于 from module import *
变量或方法双下划线开头表示强私有---只能是允许这个类本身进行访问
注释
- 单行注释
# - 多行注释
''' '''或""" """
Python的五个标准数据类型
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
Python数据类型转换
| 函数 | 描述 | |
| int(x [,base]) | 将x转换为一个整数 | |
| long(x [,base] ) | 将x转换为一个长整数 | |
| float(x) | 将x转换到一个浮点数 | |
| complex(real [,imag]) | 创建一个复数 | |
| str(x) | 将对象 x 转换为字符串 | |
| repr(x) | 将对象 x 转换为表达式字符串 | |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 | |
| tuple(s) | 将序列 s 转换为一个元组 | |
| list(s) | 将序列 s 转换为一个列表 | |
| set(s) | 转换为可变集合 | |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 | |
| frozenset(s) | 转换为不可变集合 | |
| chr(x) | 将一个整数转换为一个字符 | |
| unichr(x) | 将一个整数转换为Unicode字符 | |
| ord(x) | 将一个字符转换为它的整数值 | |
| hex(x) | 将一个整数转换为一个十六进制字符串 | |
| oct(x) | 将一个整数转换为一个八进制字符串 |
Python 的字符串内建函数
| 方法 | 描述 |
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
| string.encode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是返回最后一个匹配到的子字符串的索引号。 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str="", num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
| string.splitlines([keepends]) | 按照行('\r', '\r\n', '\n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del="") | 根据 str 给出的表(包含 256 个字符)转换 string 的字符 要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
条件语句
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……
循环语句
While 循环语句
循环控制语句
- continue 用于跳过该次循环
- break 则是用于退出循环
- pass 是占位符(为了保持程序结构的完整性)
while 判断条件:
执行语句
pass # 占位符,无其他作用
continue # 跳过该次循环,进入到下次循环
else:
执行语句
break # 则是用于退出循环
for 循环语句
for循环可以遍历任何序列的项目,如列表、字典、集合、字符串等。
for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据num迭代
if num%i == 0: # 条件判断
j=num/i
print ('%d 等于 %d * %d' % (num,i,j))
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
循环嵌套
循环体内嵌入其他的循环体,如:在while循环中可以嵌入for循环、while循环, 也可以在for循环中嵌入while循环。
Python日期和时间
python时间日期格式化符号
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00-59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %- % - %号本身
import time
# 格式化成2016-03-20 11:45:39形式
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 格式化成Sat Mar 28 22:24:24 2016形式
print time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y"))
匿名函数
使用lambda来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
lambda [arg1 [,arg2,.....argn]]:表达式
# lambda使用
sum = lambda x, y: x + y
print(sum(1, 2))
# lambda与if
b = lambda x: "Even" if x % 2 == 0 else "Odd"
print(b(10))
# lambda与for
l2=[lambda:i for i in range(10)]
# lambda与map
# 使用map进行两个列表相加
l1 = [1, 2, 3, 4]
l2 = [11, 22, 33, 44]
mm = list(map(lambda x, y: x + y, l1, l2)) # map() 会根据提供的函数对指定序列做映射。
print(mm)
# lambda与内置函数
# 现有字典dic = {'a':1,'b':2,'c':23,'d':11,'e':4,'f':21},请按照字段中的value进行排序?
dic = {'a': 1, 'b': 2, 'c': 23, 'd': 11, 'e': 4, 'f': 21}
dic1 = sorted(dic.items(),key=lambda dic:dic[1])
print(dic1)
## 使用filter进行序列筛选
ll = [20, 30, 25, 40, 50]
print(list(filter(lambda x: x > 25, ll)))
## 使用reduce,对所有元素进行累计操作
print(reduce(lambda x, y: x + y, ll))
# lambda与max(找出字典中值最大的key)
price = {
'a':1,
'b':7,
'c':5,
'd':10,
'e':12,
'f':3
}
result = max(price,key=lambda x:price[x])
print(result)
模块、包
导入模块、包
from package.xxx import xxx
from modname import name1[, name2[, ... nameN]]
from modname import *
import modname
搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
包就是文件夹,但该文件夹下必须存在 init.py 文件, 该文件的内容可以为空。init.py 用于标识当前文件夹是一个包。
文件I/O
open 函数
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:
- file_name:
file_name变量是一个包含了你要访问的文件名称的字符串值。 - access_mode:
access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。 - buffering:
如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
模式参数说明
| 模式 | 描述 |
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
文件读/写方法
# 打开/创建文件
with open(file="a.txt", mode="w", encoding="utf-8") as f:
f.write("写入字符串test")
# 打开并读取文件内容
f = open("a.txt", "r+", encoding="utf-8")
s = f.read()
f.close() # 关闭打开的文件
print(s)
Python 异常处理
python标准异常
| 异常名称 | 描述 |
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
异常处理
try:
print("执行代码。。。") # 正常的操作
a = 1
# raise BaseException("基础异常")
# raise Exception("常规错误", a)
raise IOError("IO异常") # 自己触发异常
# raise StopIteration("迭代器异常")
# raise IndexError("索引异常")
except IOError as e:
print("当前异常1:", e) # 发生以上多个异常中的一个,执行这块代码
except (Exception, BaseException) as e:
print("当前异常2:", e)
else:
print("没有出现异常") # 没有异常则执行这块代码
finally:
print("总是执行finally") # 触发还是没触发异常都会执行
OS文件/目录方法
| 方法 | 描述 |
| os.access(path, mode) | 检验权限模式 |
| os.chdir(path) | 改变当前工作目录 |
| os.chflags(path, flags) | 设置路径的标记为数字标记。 |
| os.chmod(path, mode) | 更改权限 |
| os.chown(path, uid, gid) | 更改文件所有者 |
| os.chroot(path) | 改变当前进程的根目录 |
| os.close(fd) | 关闭文件描述符 fd |
| os.closerange(fd_low, fd_high) | 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| os.dup(fd) | 复制文件描述符 fd |
| os.dup2(fd, fd2) | 将一个文件描述符 fd 复制到另一个 fd2 |
| os.fchdir(fd) | 通过文件描述符改变当前工作目录 |
| os.fchmod(fd, mode) | 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| os.fchown(fd, uid, gid) | 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| os.fdatasync(fd) | 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| os.fdopen(fd[, mode[, bufsize]]) | 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| os.fpathconf(fd, name) | 返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| os.fstat(fd) | 返回文件描述符fd的状态,像stat()。 |
| os.fstatvfs(fd) | 返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| os.fsync(fd) | 强制将文件描述符为fd的文件写入硬盘。 |
| os.ftruncate(fd, length) | 裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| os.getcwd() | 返回当前工作目录 |
| os.getcwdu() | 返回一个当前工作目录的Unicode对象 |
| os.isatty(fd) | 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| os.lchflags(path, flags) | 设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| os.lchmod(path, mode) | 修改连接文件权限 |
| os.lchown(path, uid, gid) | 更改文件所有者,类似 chown,但是不追踪链接。 |
| os.link(src, dst) | 创建硬链接,名为参数 dst,指向参数 src |
| os.listdir(path) | 返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| os.lseek(fd, pos, how) | 设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| os.lstat(path) | 像stat(),但是没有软链接 |
| os.major(device) | 从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| os.makedev(major, minor) | 以major和minor设备号组成一个原始设备号 |
| os.makedirs(path[, mode]) | 递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| os.minor(device) | 从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| os.mkdir(path[, mode]) | 以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| os.mkfifo(path[, mode]) | 创建命名管道,mode 为数字,默认为 0666 (八进制) |
| os.mknod(filename[, mode=0600, device]) | 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 |
| os.open(file, flags[, mode]) | 打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| os.openpty() | 打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| os.pathconf(path, name) | 返回相关文件的系统配置信息。 |
| os.pipe() | 创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| os.popen(command[, mode[, bufsize]]) | 从一个 command 打开一个管道 |
| os.read(fd, n) | 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| os.readlink(path) | 返回软链接所指向的文件 |
| os.remove(path) | 删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| os.removedirs(path) | 递归删除目录。 |
| os.rename(src, dst) | 重命名文件或目录,从 src 到 dst |
| os.renames(old, new) | 递归地对目录进行更名,也可以对文件进行更名。 |
| os.rmdir(path) | 删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| os.stat(path) | 获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| os.stat_float_times([newvalue]) | 决定stat_result是否以float对象显示时间戳 |
| os.statvfs(path) | 获取指定路径的文件系统统计信息 |
| os.symlink(src, dst) | 创建一个软链接 |
| os.tcgetpgrp(fd) | 返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
| os.tcsetpgrp(fd, pg) | 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| os.tempnam([dir[, prefix]]) | 返回唯一的路径名用于创建临时文件。 |
| os.tmpfile() | 返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| os.tmpnam() | 为创建一个临时文件返回一个唯一的路径 |
| os.ttyname(fd) | 返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| os.unlink(path) | 删除文件 |
| os.utime(path, times) | 返回指定的path文件的访问和修改的时间。 |
| os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) | 输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| os.write(fd, str) | 写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
| os.path 模块 | 获取文件的属性信息。 |
Python内置函数
| abs() | divmod() | input() | open() | staticmethod() |
| all() | enumerate() | int() | ord() | str() |
| any() | eval() | isinstance() | pow() | sum() |
| basestring() | execfile() | issubclass() | print() | super() |
| bin() | file() | iter() | property() | tuple() |
| bool() | filter() | len() | range() | type() |
| bytearray() | float() | list() | raw_input() | unichr() |
| callable() | format() | locals() | reduce() | unicode() |
| chr() | frozenset() | long() | reload() | vars() |
| classmethod() | getattr() | map() | repr() | xrange() |
| cmp() | globals() | max() | reverse() | zip() |
| compile() | hasattr() | memoryview() | round() | import() |
| complex() | hash() | min() | set() | |
| delattr() | help() | next() | setattr() | |
| dict() | hex() | object() | slice() | |
| dir() | id() | oct() | sorted() | exec 内置表达式 |
Python 面向对象
面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
类的继承
class A:
def a(self):
print("调用A类a方法")
class B:
def a(self):
print("调用B类a方法")
class C(B): # 单继承
def a(self): # 重写B父类的a方法
print("调用C类a方法")
def c(self):
print("调用C类c方法")
class D(A, B): # 支持多继承,若两个类有相同方法,按小括号顺序取
def d(self):
print("调用D类d方法")
class E(C): # 支持多重继承
def e(self):
print("调用E类e方法")
if __name__ =="__main__":
cc = C()
# print(cc.a())
dd = D()
# print(dd.a())
ee = E()
print(cc.a())
print(issubclass(D, A)) # 判断一个类是不是另一个类的子孙类
print(isinstance(ee, B)) # 判断一个实例对象是不是某个类/子孙类的实例
基础重载方法
| 方法 | 描述 | 简单的调用 |
|---|---|---|
| init ( self [,args...] ) | 构造函数 | obj = className(args) |
| del( self ) | 析构方法, 删除一个对象 | del obj |
| repr( self ) | 转化为供解释器读取的形式 | repr(obj) |
| str( self ) | 用于将值转化为适于人阅读的形式 | str(obj) |
| cmp ( self, x ) | 对象比较 | cmp(obj, x) |
实例方法、静态方法、类方法
-
实例方法:
第一个参数必须要默认传实例对象,一般习惯用self。
通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高 -
静态方法:修饰器@staticmethod来标识其为静态方法
静态方法中引用类属性的话,必须通过类对象来引用,不能访问实例属性 -
类方法:修饰器@classmethod来标识其为类方法
第一个参数必须要默认传类,一般习惯用cls(表示类本身)。
类方法是只与类本身有关而与实例无关的方法。
通过cls引用的必定是类对象的属性和方法,不能访问实例属性
能够通过实例对象和类对象去访问类方法
@staticmethod和@classmethod区别
- @staticmethod不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。
- @classmethod也不需要self参数,但第一个参数需要是表示自身类的cls参数。
- @staticmethod中要调用到这个类的一些属性方法,只能直接类名.属性名或类名.方法名。
- @classmethod因为持有cls参数,可以来调用类的属性,类的方法,实例化对象等,避免硬编码。---更加灵活
- @staticmethod和@classmethod都可以直接类名.方法名()来调用
正则表达式
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
re.match(从头匹配)
re.match从字符串的起始位置匹配,匹配成功返回一个匹配的对象,否则返回 None。
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
re.search(整体匹配)
re.search 扫描整个字符串并返回第一个成功的匹配。
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
re.match与re.search的区别
- re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
- re.search匹配整个字符串,直到找到一个匹配。
获取匹配对象数据
- group(num)
group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 - groups()
返回一个包含所有小组字符串的元组。
re.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
match 和 search 是匹配一次 findall 匹配所有。
re.findall(string[, pos[, endpos]])
参数:
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
参数
pattern:匹配的正则表达式
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
re.sub(检索和替换)
re.sub(pattern, repl, string, count=0, flags=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
参数
pattern :匹配的正则表达式
string :要匹配的字符串。
maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
flags :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
replace()方法
把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
str.replace(old, new[, max])
参数
old:将被替换的子字符串。
new:新字符串,用于替换old子字符串。
max:可选字符串, 替换不超过 max 次
replace()与re.sub()区别
- replace没有正则的效果,但是运行效率高
- re.sub支持正则,功能更强大
如何选择使用
- 常规字符串替换使用replace
- 复杂替换使用re.sub
对于re.sub来说用compile后的obj可以有效减少将近一半的时间
数据库
import pymysql
# 打开数据库连接
db = pymysql.connect(host="localhost", user="root", password="root", port=3306, database="test", charset='utf8')
cursor = db.cursor() # 使用cursor()方法获取操作游标
sql = 'insert into user_base values(2,1823324242,"test");'
cursor.execute(sql) # 使用execute方法执行SQL语句
data = cursor.fetchall() # 使用 fetchall() 方法获取所有数据
db.commit() # 插入、删除、更新表时,需要提交到数据库执行
db.close() # 关闭数据库连接
print(data)
数据库查询操作
- fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
- fetchall():接收全部的返回结果行.
- rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数。
Python 网络编程
Python提供了两个级别访问的网络服务
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
Socket
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
socket.socket([family[, type[, proto]]])
参数
family: 套接字家族可以使 AF_UNIX 或者 AF_INET。
type: 套接字类型可以根据是面向连接的还是非连接分为 SOCK_STREAM 或 SOCK_DGRAM。
protocol: 一般不填默认为 0。
服务端实例
import socket # 导入 socket 模块
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 12345 # 设置端口
s.bind((host, port)) # 绑定端口
s.listen(5) # 等待客户端连接(开始TCP监听。backlog 指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为 1,大部分应用程序设为 5 就可以了。)
while True:
c, addr = s.accept() # 建立被动接受TCP客户端连接,(阻塞式)等待连接的到来
print("连接的客户端地址:", addr)
c.send("hello,我是服务器".encode("gbk")) # 发送TCP数据,将string中的数据发送到连接的套接字(传输是以字节流的方式传输,所以需要转换)
print(c.recv(1024).decode("gbk")) # 接收TCP数据,数据以字符串形式返回(传输是以字节流的方式传输,所以需要转换)
c.close() # 关闭连接
客户端实例
import socket # 导入 socket 模块
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 12345 # 设置端口号
s.connect((host, port)) # 主动初始化TCP服务器连接
data = s.recv(1024).decode("gbk") # 接收TCP数据,数据以字符串形式返回(传输是以字节流的方式传输,所以需要转换)
print("服务器响应:" + data)
s.send("hello,我是客户端1".encode("gbk")) # 发送TCP数据,将string中的数据发送到连接的套接字(传输是以字节流的方式传输,所以需要转换)
s.close()
输出结果:


网络编程重要模块
| 协议 | 功能用处 | 端口号 | Python模块 |
|---|---|---|---|
| HTTP | 网页访问 | 80 | httplib, urllib, xmlrpclib |
| NNTP | 阅读和张贴新闻文章,俗称为"帖子" | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 接收邮件 | 110 | poplib |
| IMAP4 | 获取邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 信息查找 | 70 | gopherlib, urllib |
多线程
线程有两种方式:
- 函数
- 用类来包装线程对象
函数式
调用threading模块中的Thread()函数来产生新线程。
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数说明:
group:官方的解释是,为了日后扩展ThreadGroup类实现而保留。(唉,我也不太清楚的)
target:是要于多线程的函数
name:是线程的名字
args :函数的参数,类型是元组()
kwargs:函数的参数,类型是字典{}
Threading.Thread其中常用到的方法
- start():开始线程活动。这里注意,每个对象只能执行一次
- run() :表示线程的方法,在线程被cpu调度后,就会自动执行这个方法。
但是如果你在自定义的类中想方法run和父类不一样,可以重写。 - join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- setName():给线程设置名字
- getName():获取线程名字
- isAlive():返回线程是否存活(True或者False)
- setDaemon():设置守护线程(True或者False),必须在start()之前设置,不然会报错。
- isDaemon() :是否是线程守护,默认是False。
函数实例
import threading
import time
# 为线程定义一个函数
def print_time(threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print("%s: %s" % (threadName, time.ctime(time.time())))
# 创建两个线程
try:
print("创建线程")
obj1 = threading.Thread(target=print_time, args=("Thread-1", 1,))
obj2 = threading.Thread(target=print_time, args=("Thread-2", 2,))
obj1.start() # 启动线程活动
obj2.start()
obj1.join() # 等待至线程中止。这阻塞调用线程直至线程的join()方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
obj2.join()
print("退出主线程")
except:
print("Error: unable to start thread")
while 1:
pass
用类来包装线程对象
使用Threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法
线程同步(锁Lock和Rlock)
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
- threadLock.acquire() # 加锁
- threadLock.release() # 解锁
import threading
import time
threadLock = threading.Lock()
class MyThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, name, delay, counter):
threading.Thread.__init__(self) # 或者super(MyThread, self).__init__(),重构必须要写
self.name = name # 定义线程名字(后续可以使用self.getName()获取
self.delay = delay # 自定义参数(print_time的延迟时间参数)
self.counter = counter # 自定义参数(print_time的计数参数)
def run(self): # 把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
print("开始线程 " + self.name) # 也可以使用self.getName() 获取线程名
print_time(self.name, self.delay, self.counter) # 调用方法
threadLock.acquire() # 加锁
run_sql(self.name, "show tables", self.counter)
print("退出线程 " + self.name)
threadLock.release() # 解锁
def print_time(thread_name, delay, counter):
while counter:
time.sleep(delay)
print("%s: %s" % (thread_name, time.ctime(time.time())))
counter -= 1
def run_sql(thread_name, sql, counter):
for i in range(counter):
print("{}执行sql语句{}:{}".format(thread_name, i, sql)) # 加锁后,必须等该线程执行完并解锁后,下一个进程才能执行
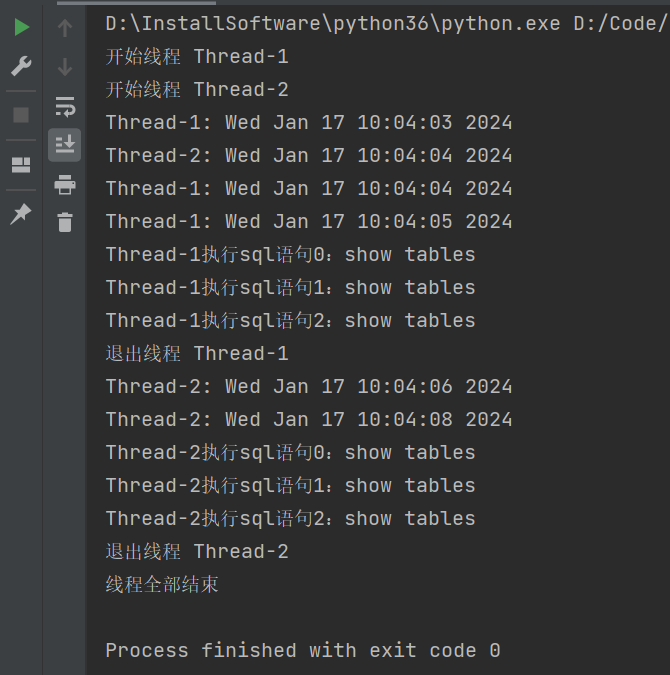
# 创建新线程
thread1 = MyThread("Thread-1", 1, 3)
thread2 = MyThread("Thread-2", 2, 3)
# 开启线程
thread1.start() # 开始执行线程,会自动执行重构的run函数
thread2.start()
# 添加线程到线程列表
threads = [] # 创建线程池
threads.append(thread1)
threads.append(thread2)
for i in threads:
i.join() # 等待所有线程完毕
print("线程全部结束")
执行结果:
线程优先级队列( Queue)
queue模块是Python内置的标准模块,提供了:
- FIFO(先入先出)队列
Queue - LIFO(后入先出)队列
LifoQueue - 优先级队列
PriorityQueue
三者区别仅仅是条目取回的顺序
Queue模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item, block=True, timeout=None) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当 Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
queue.Queue(maxsize=0)
FIFO先进先出队列
maxsize用于设置可以放入队列中的项目数的上限。当达到这个大小的时候,插入操作将阻塞至队列中的项目被消费掉。(maxsize默认为0,队列为无限大。)
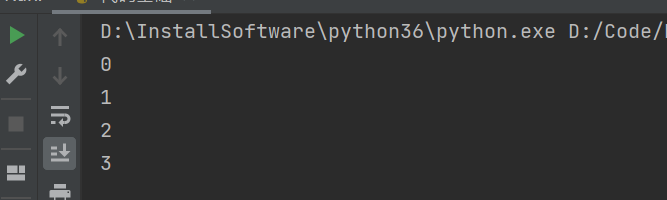
from queue import Queue, LifoQueue, PriorityQueue
queue_obj = Queue() # 创建一个FIFO(先进先出)队列对象
for i in range(4):
queue_obj.put(i)
while not queue_obj.empty():
print(queue_obj.get())
运行结果:
queue.LifoQueue(maxsize=0)
LIFO后进先出队列
maxsize参数设置和功能与Queue一样
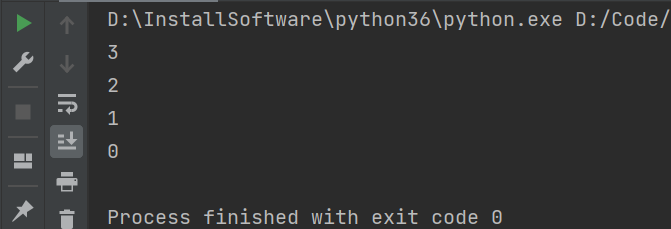
from queue import Queue, LifoQueue, PriorityQueue
queue_obj = LifoQueue() # 创建一个LIFO(后进先出)队列对象
for i in range(4):
queue_obj.put(i)
while not queue_obj.empty():
print(queue_obj.get())
运行结果:
PriorityQueue(maxsize=0)
优先级队列构造器,自定义优先顺序
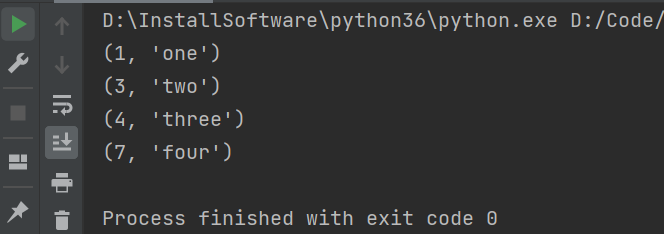
from queue import Queue, LifoQueue, PriorityQueue
queue_obj = PriorityQueue() # 创建一个优先级队列构造器对象
queue_obj.put((3, "two")) # 元祖形式存储(优先级数字,数据),尽量优先级不要设置一样,否则会根据数据进行比较(数字、列表、字符串可以比较,其他会报错,需要自己实现比较,如字典则重写字典构造方法)
queue_obj.put((4, "three"))
queue_obj.put((1, "one"))
queue_obj.put((7, "four"))
while not queue_obj.empty():
print(queue_obj.get())
运行结果:
GUI编程
常用的Python GUI库
- Tkinter:
Tkinter作为Python的标准GUI库,具有简单易用的特点,适合初学者和快速开发小型应用。如果项目规模较小,对外观和功能要求不是很高,而且希望使用标准库,Tkinter可能是一个不错的选择。 - wxPython:
wxPython是一个跨平台的GUI框架,具有Pythonic设计、跨平台性和多种控件的优势。它在学习曲线和功能丰富度之间取得了平衡,适用于中小型项目,尤其是对跨平台支持有要求的应用。 - PyQt5:
PyQt是一个强大而灵活的GUI框架,具有现代外观、丰富的功能和文档完善的优势。它适用于中大型项目,尤其是需要高度定制化、专业外观和先进功能的应用。然而,学习曲线较陡峭,商业应用可能需要考虑相关的许可证费用。
以上GUI库比较与选择
PyQt5功能最强大,属于商业型,Tkinter没有图形界面设计器,需要完全自己写代码,但Tkinter是python自带的图形库,性能不是很差,也容易学习,适用于快速开发小型应用。
wxPython是免费的,源代码是开放的,允许其应用在商业产品上,你可以免费使用它和共享它。有图形界面设计器,是QT的压缩版。
学习建议,先从Tkinter入手,然后再根据情况选择PyQt5或wxPython,推荐wxPython
Tkinter 组件
| 控件 | 描述 |
|---|---|
| Button | 按钮控件;在程序中显示按钮。 |
| Canvas | 画布控件;显示图形元素如线条或文本 |
| Checkbutton | 多选框控件;用于在程序中提供多项选择框 |
| Entry | 输入控件;用于显示简单的文本内容 |
| Frame | 框架控件;在屏幕上显示一个矩形区域,多用来作为容器 |
| Label | 标签控件;可以显示文本和位图 |
| Listbox | 列表框控件;在Listbox窗口小部件是用来显示一个字符串列表给用户 |
| Menubutton | 菜单按钮控件,用于显示菜单项。 |
| Menu | 菜单控件;显示菜单栏,下拉菜单和弹出菜单 |
| Message | 消息控件;用来显示多行文本,与label比较类似 |
| Radiobutton | 单选按钮控件;显示一个单选的按钮状态 |
| Scale | 范围控件;显示一个数值刻度,为输出限定范围的数字区间 |
| Scrollbar | 滚动条控件,当内容超过可视化区域时使用,如列表框。. |
| Text | 文本控件;用于显示多行文本 |
| Toplevel | 容器控件;用来提供一个单独的对话框,和Frame比较类似 |
| Spinbox | 输入控件;与Entry类似,但是可以指定输入范围值 |
| PanedWindow | PanedWindow是一个窗口布局管理的插件,可以包含一个或者多个子控件。 |
| LabelFrame | labelframe 是一个简单的容器控件。常用于复杂的窗口布局。 |
| tkMessageBox | 用于显示你应用程序的消息框。 |
标准属性
标准属性也就是所有控件的共同属性,如大小,字体和颜色等等。
| 属性 | 描述 |
|---|---|
| Dimension | 控件大小 |
| Color | 控件颜色 |
| Font | 控件字体 |
| Anchor | 锚点 |
| Relief | 控件样式 |
| Bitmap | 位图 |
| Cursor | 光标 |
几何管理
Tkinter控件有特定的几何状态管理方法,管理整个控件区域组织,以下是Tkinter公开的几何管理类:包、网格、位置
| 几何方法 | 描述 |
|---|---|
| pack() | 包装 |
| grid() | 网格 |
| place() | 位置 |
具体实例
import tkinter
from tkinter import ttk
def fun1(value):
if select.get() == 'a':
print("触发事件a")
elif select.get() == 'b':
print("触发事件b")
def fun2():
print("调用方法")
tkr = tkinter.Tk() # 创建窗口
tkr.title("Demo") # 窗口名
tkr.geometry('350x250+600+100') # 350 550为窗口大小,+10 +10 定义窗口弹出时的默认展示位置
tkr["bg"] = "#F0F8FF" # 窗口背景色,其他背景色见:blog.csdn.net/chl0000/article/details/7657887
tkr.attributes("-alpha", 0.9) # 虚化,值越小虚化程度越高
tkinter.Label(tkr, text='下拉框', font=('楷书', 10, 'bold')).place(x=1, y=0, anchor='nw') # 标签控件;可以显示文本和位图
select = ttk.Combobox(tkr, text='', width=12, state='readonly') # 创建下拉框对象,选项只读状态
select['values'] = ("a", "b", "c") # 设置下拉列表的值
select.current('1') # 设置下拉列表默认显示的值,值为下标值
select.bind("<<ComboboxSelected>>", fun1) # 触发事件名,被触发函数
select.place(x=5, y=20, anchor='nw') # 下拉框位置设置
start_button = ttk.Button(tkr, # 创建按钮,并调用内部方法,加()为直接调用
text="启动",
# bg="lightblue",
# width=10, height=1,
command=fun2)
start_button.place(x=30, y=100, anchor='nw')
tkr.mainloop() # 父窗口进入事件循环,可以理解为保持窗口运行,否则界面不展示
执行结果:

JSON函数
- json.dumps(序列化)
json.dumps 用于将 Python 对象编码成 JSON 字符串。 - json.loads(反序列化)
将已编码的 JSON 字符串解码为 Python 对象
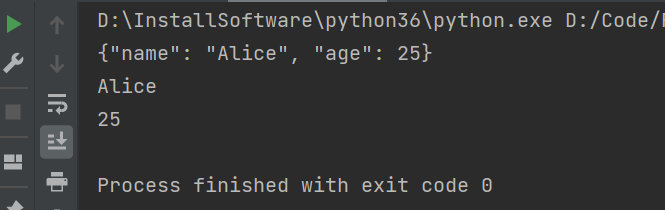
import json
data = {'name': 'Alice', 'age': 25}
json_str = json.dumps(data) # JSON序列化(将数据对象转换为JSON格式字符串)
print(json_str)
data = json.loads(json_str) # JSON反序列化(将JSON格式字符串转换为数据对象)
print(data['name'])
print(data['age'])
执行结果:
Python基础学习教程
Python实例

Python测验
进群交流、获取更多干货, 请关注微信公众号:

> > > 咨询交流、进群,请加微信,备注来意:sanshu1318 (←点击获取二维码)
> > > 学习路线+测试实用干货精选汇总:
https://www.cnblogs.com/upstudy/p/15859768.html
> > > 【自动化测试实战】python+requests+Pytest+Excel+Allure,测试都在学的热门技术:
https://www.cnblogs.com/upstudy/p/15921045.html
> > > 【热门测试技术,建议收藏备用】项目实战、简历、笔试题、面试题、职业规划:
https://www.cnblogs.com/upstudy/p/15901367.html
> > > 声明:如有侵权,请联系删除。
============================= 升职加薪 ==========================
更多干货,正在挤时间不断更新中,敬请关注+期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号