
【测试基础】jmeter工具介绍及使用
一、Jmeter介绍
jmeter是Apache组织基于java开发的一款性能测试软件。是一款开源、小巧、支持多协议(HTTP/HTTPS、JDBC、JAVA...等等)、众多插件为一体的强大工具。
它不仅做性能测试,还可以做接口的自动化测试。
优点
1.开源免费
2.体积小
3.有丰富的第三方插件
缺点
1.不支持ip欺骗
2.报表的精度比LR要差
二、Jmeter文件目录介绍
1.1 bin目录
存放可执行文件和配置文件
jmeter.bat:windows的启动文件
jmeter.log:日志文件
jmeter.sh:linux的启动文件
jmeter-properties:系统配置文件
jmeter-server.bat:windows分布式测试要用到的服务器配置
jmeter-server:linux分布式测试要用到的服务器配置
1.2 docs目录
docs:是Jmeter的api文档,可打开api/index.html页面来查看
1.3 printable_docs目录
printable_docs的usermanual子目录下的内容是Jmeter的用户手册文档。
usermanual下component_reference.html是最常用到的核心元件帮助文档。
提示:printable_docs的demos子目录下有些常用Jmeter脚本案例,可以参考。
1.4 lib目录
该目录用来存放Jmeter依赖的jar包和用户扩展所依赖的jar包。
三、Jmeter的基础配置
汉化设置
-
临时修改:
options--->language--->choose language--->Chinese
-
永久修改:
-
打开jmeter.properties
-
修改language=zh_CN
-
重启jmeter
-
主题修改
选项--->主题--->选择对应的主题,重启jmeter
四、Jmeter的基本操作
- 启动jmeter
- 添加线程组
- 添加http请求的取样器,并配置
- 添加查询结果树的监听器
- 点击"启动"运行jmeter,并查看结果
基本元件
线程组:模拟用户的。
配置元件:进行测试环境和测试数据初始化--->比如自动化脚本中setup
前置处理器:对要发送请求进行预处理--->比如自动化脚本中参数化
取样器:往服务器发送请求--->比如自动化脚本中发请求的代码
后置处理器:对收到服务器的响应进行数据提取--->比如自动化脚本中获取响应中特定字段语句
断言:将收到响应结果又预期结果做对比--->比如自动化脚本中断言
监听器:查看测试脚本运行后结果和日志--->比如自动化脚本中测试报告
定时器:等待一段时间--->比如自动化脚本中sleep
测试片段:封装基本功能,不单独执行,需要通过脚本的调用才能执行--->比如自动化脚本中封装函数
作用域
核心:根据测试计划中的树形结构的父子节点来确定的
原则:
- 取样器是没有作用域的。
- 逻辑控制器:只对其子节点下的所有元件有效。
- 其他的元件。
- 如果其父节点是取样器,则只对父节点取样器有效。
- 如果其父节点不是取样器,对父节点下所有子节点及节点中子节点有效。
元件的执行顺序
顺序:配置元件--->前置处理器--->定时器--->取样器--->后置处理器--->断言--->监听器
注意:
- 配置元件、前置处理器、后置处理器都需要依赖取样器才能运行
- 在同一个作用域下,相同类型元件执行顺序是从上到下来按顺序执行
Jemter重要的三个组件
线程组
作用:通过配置线程组中的线程数来模拟用户。线程数就是用户数,线程组是用户组
特点:
- 模拟多用户
- 取样器和逻辑控制器必须在线程组下使用
- 一个测试计划下可以添加多个线程组,可以并行或串行执行
- 并行:默认情况下线程组为并行执行
- 串行:在测试计划下勾上"独立运行每个线程组"
线程组的分类:
- setup线程组:拥有测试前预处理操作,在所有线程组中最先执行
- 普通线程组:来执行业务测试脚本
- teardown线程组:用来测试后的后置处理(数据、恢复环境)的操作,在所有的线程组中最后执行
线程组的属性
线程数:模拟虚拟用户数
Ramp-up时间:虚拟用户启动所需要的时间
循环次数:
- 配置指定次数:控制脚本运行执行的次数
- 配置循环永远
- 需要调度器配置使用
- 运行时间:脚本执行的时间
- 延迟启动时间:脚本等待特定的时间才能开始运行
http请求
http协议:可以填写为HTTP或者HTTPS,默认不填写为HTTP协议
http主机名/ip:如:http://baidu.com 80
端口:可以填写为任意值。默认不填写时为80端口
请求发方法:HTTP协议所有支持的所有方法
路径:目录+参数
编码格式:默认IOS国际标准,推荐使用utf-8
查看结果树
取样器结果:统计请求相关的信息
请求:HTTP请求的请求头和请求体的详情信息
响应:HTTP响应的响应头和响应体的详情信息
jmeter响应中出现乱码时:
- 修改jmeter.properties文件中,sampleresult.default.encoding=utf-8
- 重启jmeter
五、Jmeter参数化常用方式
用户定义的变量
- 方式1:
添加:线程组--->配置元件--->用户自定义变量
配置:参数名+参数值
使用:在HTTP请求的取样器中引用定义变量。$(参数名)
- 方式2:
配置:在测试计划中去配置用户定义变量
使用:在HTTP请求的取样器中引用定义变量。$(参数名)
应用场景:当大量脚本中的参数值需要修改时候,直接修改用户定义变量中值会更方便
用户参数
添加:线程组--->前置处理器--->用户参数
配置:
- 参数:添加变量
- 参数值:添加用户--->针对每个用户配置不同的参数值
使用:在HTTP请求的取样器中引用定义的变量。$(参数名)
应用场景:可以针对不同的用户获取到不同的参数值
CSV Data Set Config
添加:线程组--->配置元件--->CSV数据文件设置
编写CSV数据文件(txt、csv、json、xml作为后缀):
- 多个参数写为多列,其中用逗号分隔
- 多组参数值,则使用多行来设置
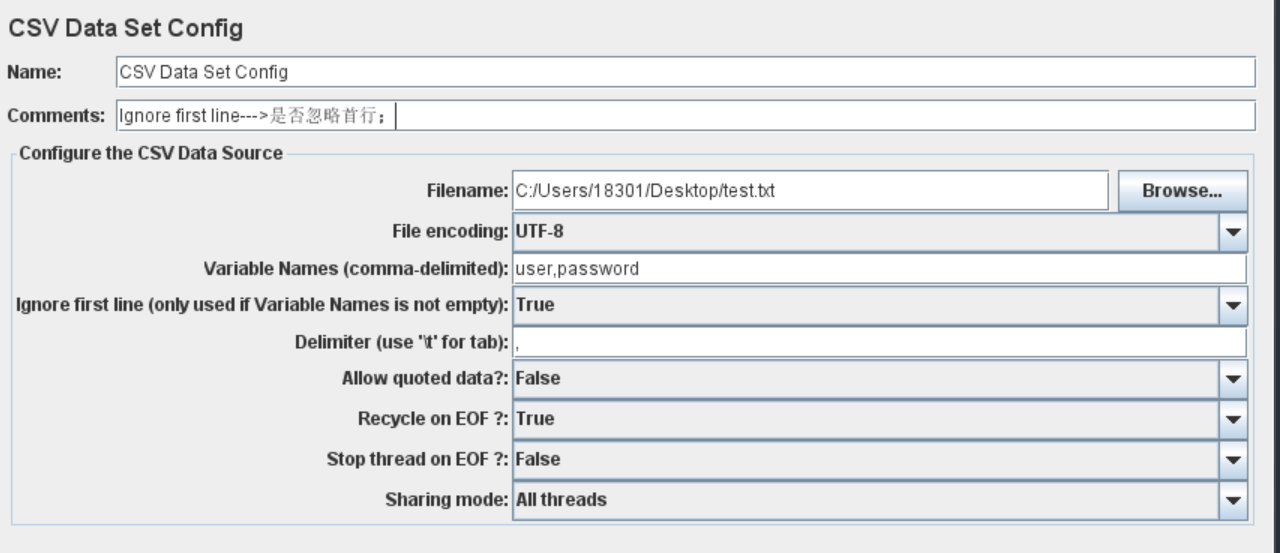
配置:
- 路径
- 文件编码:UTF-8
- 变量名称:从CSV数据文件中读取的数据需要保存变量名。有多个变量时用逗号分隔
- 是否忽略首行:是否从CSV文件第一行中开始读取
- 分隔符:要求与CSV数据文件中多列的分隔符一致
- 遇到文件结束符是否再次循环:默认TRUE
- 遇到文件结束符是否停止线程:当前一个参数为FALSE,该参数有效,一般设置为TRUE
函数
counter:
- TRUE:每个用户使用独立计数器
- FALSE:所有的用户使用全局计数器
引用:在取样器中使用$(__counter(FALSE,))来引用对应值
建议大家使用函数方式
六、Jmeter断言
作用:让脚本自动化执行过程中,能够自动判定执行结果是否符合要求时候,需要添加断言
响应断言
添加:线程组--->HTTP请求--->断言--->响应断言
配置:
- 测试字段:需要检查的字段
- 模式匹配规则:需要使用什么规则来进行检查
- 测试模式:需要校验的值
Json断言
适用于返回的HTTP响应为JSON格式
添加:线程组--->HTTP请求--->断言--->JSON断言
配置:
- JSON PATH:$.weatherinfo.city
- 勾选"Addltonal assert value"
- 在expected value里填写期望值
断言持续时间:
适用于性能测试时,检查HTTP请求的响应时间是否超过预期值
添加:线程组--->HTTP请求--->断言--->断言持续时间
配置:预期时间
七、Jmeter关联(提取器、数据库、逻辑控制器等)
当多个请求之间有依赖关系,后一个请求的参数需要使用前一个请求的响应数据时,需要用到关联。
分类:
- 正则表达式提取器
- xpath提取器
- Json提取器
提取器
正则提取器
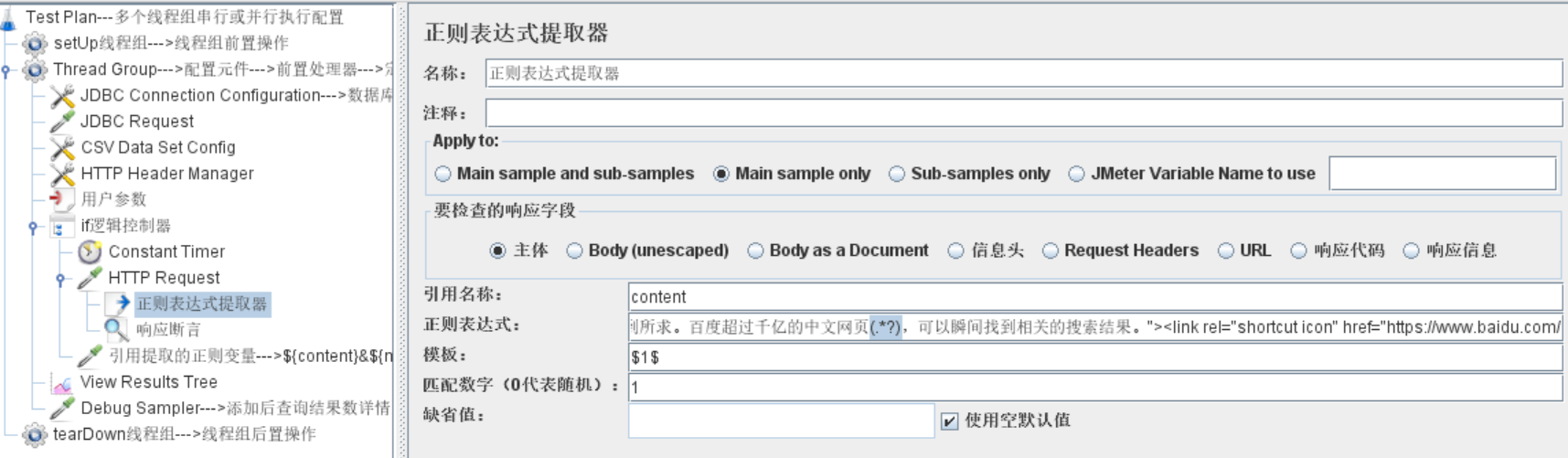
添加:线程组--->HTTP请求--->后置处理器--->正则表达式提取器
配置:
- 要检查的响应字段:默认主体
- 引用名称:匹配后的数据要存储的变量名
- 正则表达式:
<p>(.*?)</p>,"()"里是要保存的数据 - 模板:$1$
- 数据1代表上面正则表达式中第几个()
- 匹配数字:0代表随机值、1代表第一个结果,-1代表所有结果
- 缺省值:当没有匹配上时将该值保存到变量里
xpath提取器
添加:线程组--->HTTP请求--->后置处理器--->xpath提取器
配置:
- 引用名称:匹配后的数据要存储的变量名
- xpath path:xpath匹配规则
- 匹配数字:0代表随机值、1代表第一个结果,-1代表所有结果
- 缺省值:当没有匹配上时将该值保存到变量里
json提取器
添加:线程组--->HTTP请求--->后置处理器--->json提取器
配置:
- 引用名称:匹配后的数据要存储的变量名
- json path:json路径。$.weatherinfo.city
引用:直接引用变量名即可
八、Jmeter数据库连接与操作
连接准备:
- 打开数据库,确定数据库的表及对应的字段
- 加载mysql的jdbc驱动
- 方法一:将jdbc驱动通过测试计划,浏览的方式添加
- 方式二:将jdbc驱动jar包放入到lib\ext目录下,并重启jmeter
- 配置jdbc connection configuration
- created pool name:给连接池命名,用于后续引用
- 数据库URL:jdbc:mysql://127.0.0.1:3306/test
- 用户名
- 密码
直连数据库使用:
- 添加JDBC Request:取样器下添加
- 配置:
- 配置连接池名称
- 配置SQL语句
- 配置保存的变量名
- 如果SQL语句返回了多个参数,输入相同个数的变量名来保存
- HTTP断言中,就可以引用变量来进行判断
九、Jmeter的逻辑控制器
控制元件的执行顺序
if控制器
添加:线程组--->逻辑控制器--->if控制器
配置:
- 使用JS方式:(Interpret Condition as Variable Expression?:不勾选则可以直接写表达式,勾选了就必须要使用函数)
"${name}"=="baidu" - 使用jmeter函数的方式:
__jexl3()或__groovy()函数(系统默认勾选,函数方式性能高)
_jexl3()使用(轻量级,适用于简单的表达式计算和条件判断,如响应断言、循环控制、请求过滤等)
${__jexl3(${code}==200)}
${__jexl3("${name}"=="baidu",)}
__groovy()函数使用(功能强大,适用于复杂的脚本逻辑处理,如动态代码执行、复杂的条件判断、变量处理等)
${__groovy(vars.get("myInt") != "Invalid")}
循环控制器
指定HTTP请求执行特定的次数
添加:线程组--->逻辑控制器--->循环控制器
配置:次数
循环控制器中的循环次数配置m与线程组中的循环次数n配置对比:
- 关系:如果同时配置,循环控制器下HTTP请求实际执行的次数应该是n*m
- 区别:这两个循环次数作用域不同
ForEach控制器
与用户定义的变量或正则表达式提取器配合使用,循环读取返回的变量值,执行一次或多次。
-
与用户定义的变量配合
添加:线程组--->逻辑控制器--->ForEach控制器
配置:
-
用户定义的变量
- 变量名:固定前缀+连续数字
-
ForEach控制器
- 变量前缀:用户定义的变量中配置的固定前缀
- 起始数字:连续数字的最小值-1
- 结束数字:连续数字的最大值
- 输出变量名称:依次读取变量值后存储到参数中,共HTTP请求来引用
-
HTTP请求:
- 引用输出的变量名称
-
-
与正则表达式配合使用
- 先通过正则表达式提取器,提取出请求中所有满足条件数据
- 添加ForEach控制器,并配置提取所有满足条件的数据,并保存为变量
- 在其子节点下,添加HTTP请求并引用变量,可循环读取正则表达式里匹配的所有数据
十、Jmeter定时器
同步定时器
需要进行大量用户的并发测试时,为了让用户能真正同时执行,添加"同步定时器"使其阻塞线程,直到线程达到了预先设置数值,才开始进行取样器操作。
配置:
-
并发数:同事达到多少用户才开始发请求
-
超时时间:
- 必须配置:否则当虚拟用户数无法被并发数整除时,会导致有部分用户挂起无法执行
- 配置不能太短:必须比并发数加载时间要长。否则无法达到并发数的要求,数据就会被释放掉
常数吞吐量定时器
用于性能测试中模拟用户产生业务压力,通过给定QPS来对服务器发送固定频率要求。
添加:线程组--->HTTP取样器--->常数吞吐量定时器
配置:吞吐量的值QPS*60
十一、Jmeter的分布式
原理:
- 分布式测试时分为一台控制机和多台代理机
- 控制机负责发布测试任务给代理机
- 代理机接收任务并向服务器发送请求,并接收服务器返回的响应,然后将测试结果返回给控制机
- 由控制机对测试结果数据进行汇总统计
分布式相关注意事项:
- 所有的测试机防火墙都已经关闭
- 所有的测试机及服务器在同一个网络内
- 所有的测试机的jmeter版本和JDK版本完全相同
- 关闭jmeter里的RMI SSL开关
分布式配置
配置
- 代理机
- server_port:不重复。如果使用多个机器做代理机,可不用配置
- 关闭RMI SSL
- 控制机
- remote_server:所有代理机的IP+port,有多个代理机时要使用逗号分隔
- 关闭RMI SSL
运行
- 代理机
- jmeter-server.bat运行
- 控制机:
- jmeter.bat运行
- 控制代理机执行脚本,运行--->远程启动所有
十二、报告结果分析
聚合报告
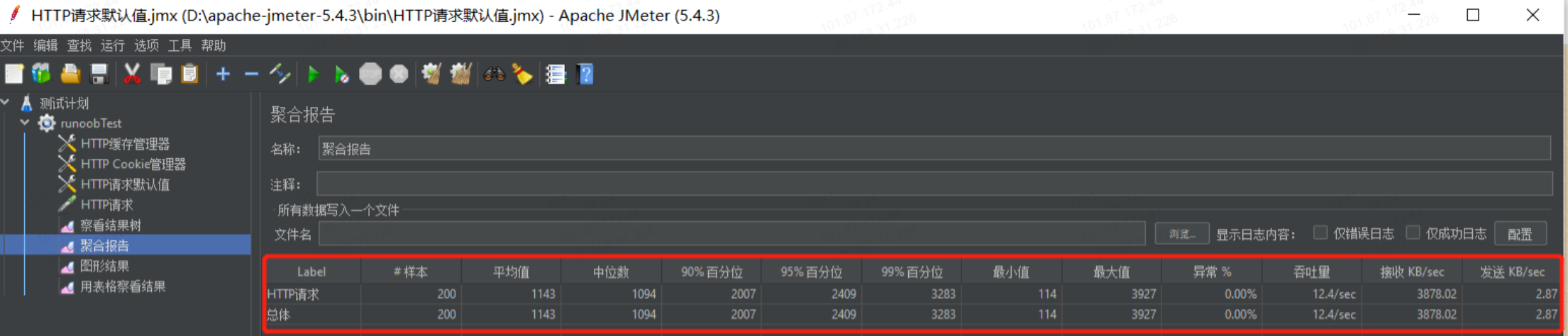
具体参数说明如下:
Label:就是请求名称
#样本:总线程数,值 = 线程数 * 循环次数=20*10=200
平均值:单个请求的平均响应时间,值 = 总运行时间 / 发送到服务器的总请求数
中位数、90%百分位、95%百分位、99%百分位分别代表50%的用户响应时间、90%的用户响应时间、95%的用户响应时间、99%的用户响应时间,也就是有百分之多少的请求小于这个值。其中,90%百分位是性能测试中比较重要的一个衡量指标。
最小值:最小响应时间
最大值:最大响应时间
异常%:错误率,发生错误的请求 / 总请求数,上面示例中错误率为0
吞吐量:表示每秒完成的请求数。
接收KB/sec或发送KB/sec:以每秒接收或发送的千字节为单位测量的吞吐量
图形报告

具体参数说明如下:
样本数目:总的请求数
最新样本:最后一次请求的响应时间
平均:所有请求的平均响应时间
偏离:响应时间变化、离散程度测量值的大小,也就是数据的分布偏差,值越小越好
吞吐量:服务器每分钟处理的请求数,相当于TPS,注意单位是分钟
中值:响应时间的50%百分位的值,也就是有50%的请求响应时间小于该值
表格报告
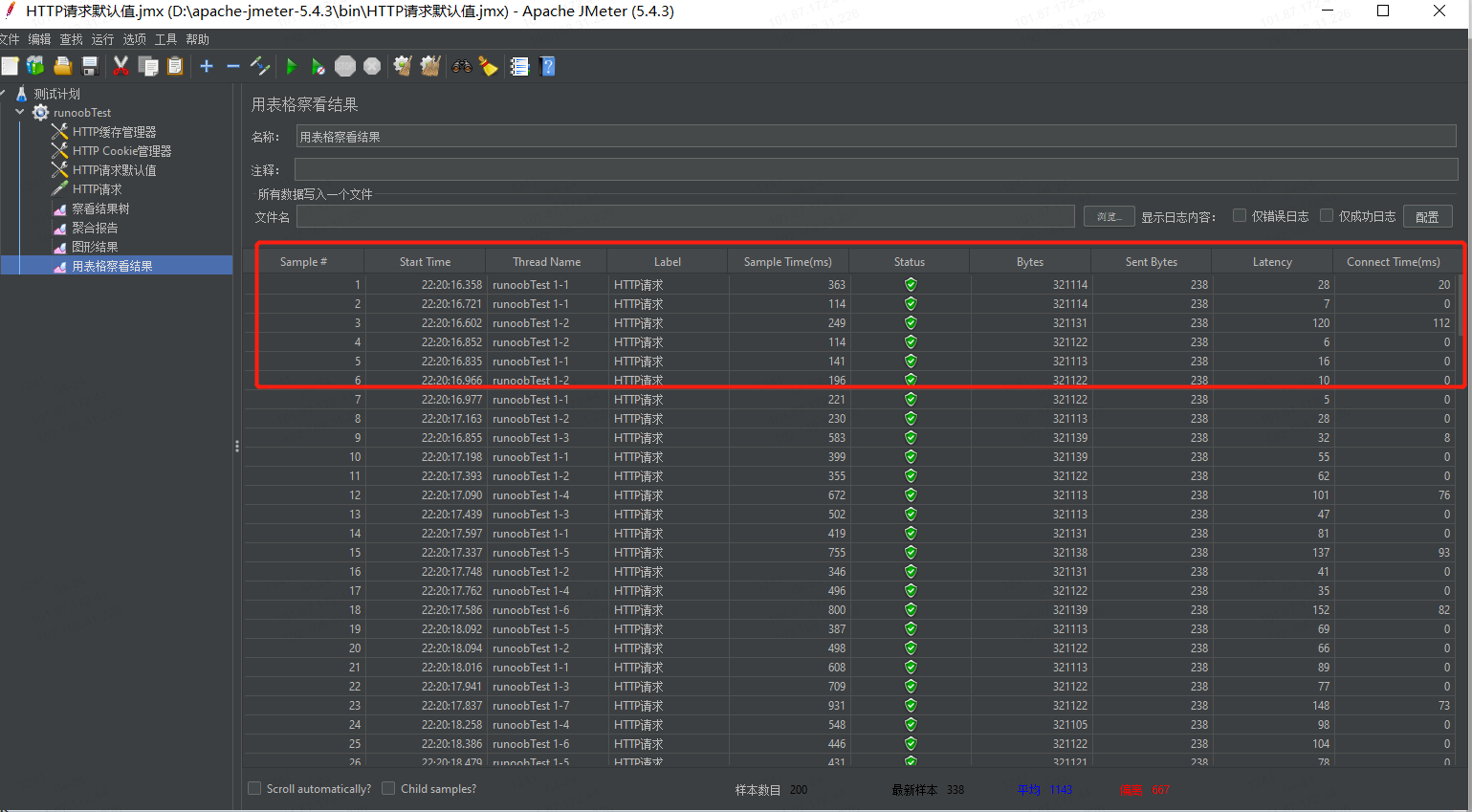
具体参数说明如下:
Sample#:每个请求的序号。
Start Time:每个请求开始时间。(时:分:秒.毫秒)
Thread Name:每个线程的名称(线程序号-第N次循环次数)。
Label:每个请求的自定义名称(无修改时默认显示请求类型,如Http,FTP等请求)。
Sample Time(ms):每个请求的响应时间。(单位:毫秒)
Status:请求状态,如果为勾则表示成功,如果为叉表示失败。
Bytes:响应的字节数,请求的字节数。
Sent Bytes:发送的字节数。
Latency:延迟的时间,等待时长。(单位:毫秒)
Connect Time(ms):连接服务器的时间。(单位:毫秒)
样本数目:所有请求个数,样本数目 = 线程数(请求用户数)* 请求次数 。(单位:个)
平均:所有请求的平均响应时间。(单位:毫秒)
最新样本:最新样本响应时间,表示服务器响应最后一个请求的时间。(单位:毫秒)
偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布。
一般而言,性能测试中我们需要重点关注的数据有: #Samples 请求数,Average 平均响应时间,Min 最小响应时间,Max 最大响应时间,Error% 错误率及Throughput 吞吐量。
Demo--->所在目录D:\Code\Jmeter

Jmeter自动化实战
接口自动化测试框架: jmeter + ant + jenkins:
待更新
Jmeter性能测试实战
【性能测试实战】jmeter+k8s+微服务+skywalking+efk:
待更新
进群交流、获取更多干货, 请关注微信公众号:

> > > 咨询交流、进群,请加微信,备注来意:sanshu1318 (←点击获取二维码)
> > > 学习路线+测试实用干货精选汇总:
https://www.cnblogs.com/upstudy/p/15859768.html
> > > 【自动化测试实战】python+requests+Pytest+Excel+Allure,测试都在学的热门技术:
https://www.cnblogs.com/upstudy/p/15921045.html
> > > 【热门测试技术,建议收藏备用】项目实战、简历、笔试题、面试题、职业规划:
https://www.cnblogs.com/upstudy/p/15901367.html
> > > 声明:如有侵权,请联系删除。
============================= 升职加薪 ==========================
更多干货,正在挤时间不断更新中,敬请关注+期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号