Python爬虫
1、任务介绍
https://movie.douban.com/top250
对链接内容包括电影名称、评分、评价数、电影概况、电影链接等需求分析
2、认识爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需要定向抓取相关网页信息,并分析。
可以获取自己想要的数据信息
模拟浏览器打开网页,获取网页中想要的的数据
3、基本流程
1)准备工作
URL分析
页面包括250条电影数据,分10页,每页25条,每页的URL的不同之处:最后的数值=(页数-1)*2
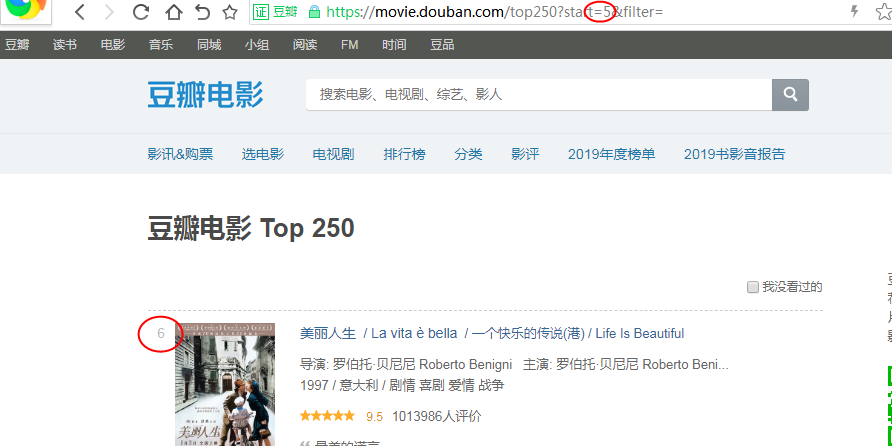
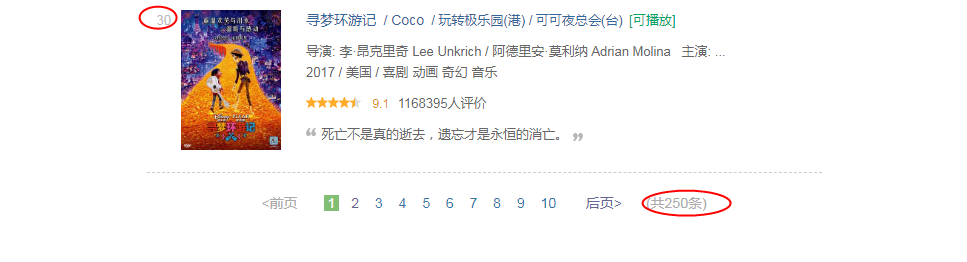
分析页面
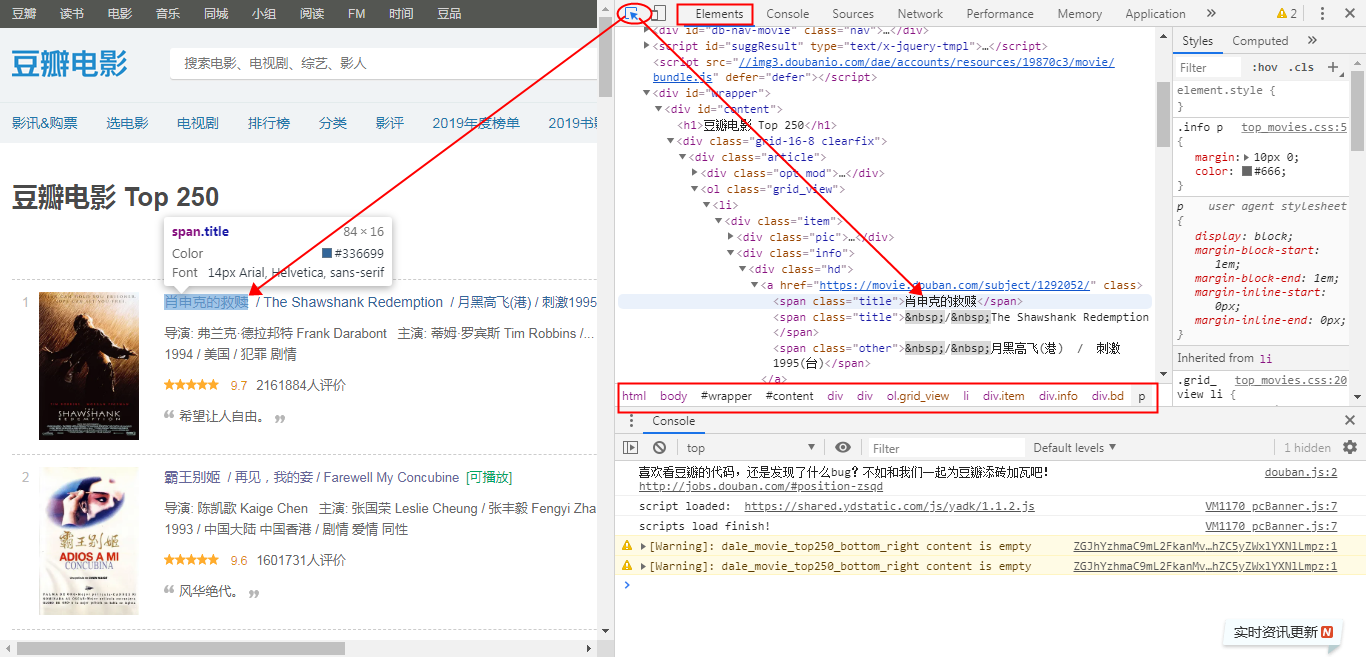
- 借助chrome开发者工具(F12)来分析网页,在Elements下找到需要的数据位置
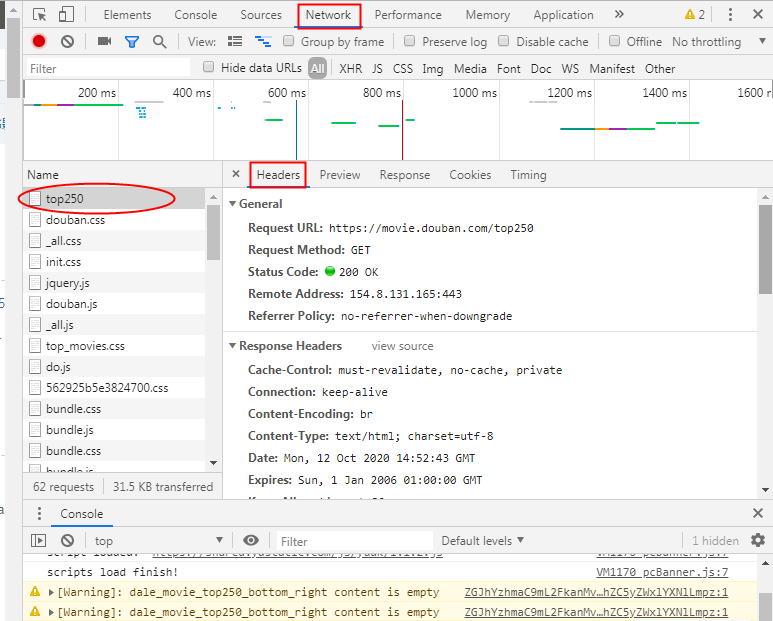
F12-->Network
header是客户端向服务器发消息,服务器从header的信息来鉴定身份
2)获取数据
3)解析内容
4)保存数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号