python基础
1、变量及类型
a_abc = 'xyz'
b = 1
对变量赋值(a_abc = 'xyz'),python解释器会在内存中创建一个 'xyz'的字符串,创建一个名为a_abc的变量,并把a_abc指向'xyz'
变量开头字符必须是英文或下划线
注:对于变量名就是标识符
2、关键字
python中的一些具有特殊功能的标识符,就是关键字,查询方法如下:
方法一:执行help() 会进入帮助系统,再执行keywords 就可以查看到关键字有哪些,直接输入关键字回车可以查看到当前关键字的帮助信息。
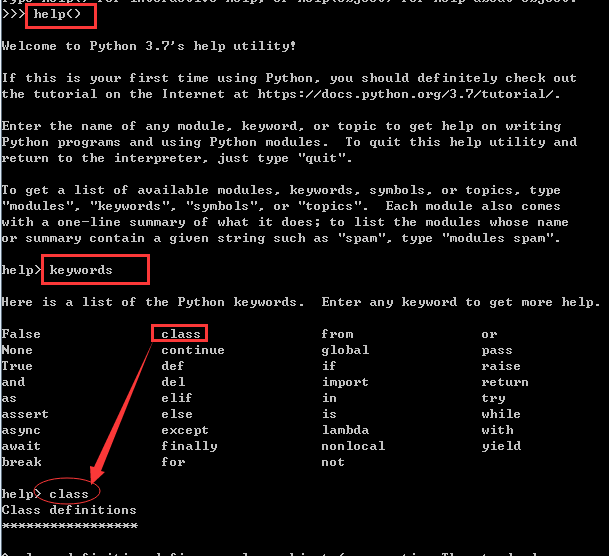
方法二:
>>> import keyword
>>> keyword.kwlist
3、格式化
参考链接:https://www.cnblogs.com/penphy/p/10028546.html
age = 30
print("我的年纪是: %d 岁"%age)
print("我的国籍:%s,我的名字是%s"%("休眠","中国"))
print("www","baidu","com",sep=".")
4、转义字符
print("hello",end="")
print("world",end="\t")
print("python",end="\n")
print("end")
|
转义字符
|
描述
|
|
\(在行尾时)
|
续行符
|
|
\\
|
反斜杠符号
|
|
\'
|
单引号
|
|
\"
|
双引号
|
|
\a
|
响铃
|
|
\b
|
退格(Backspace)
|
|
\e
|
转义
|
|
\000
|
空
|
|
\n
|
换行
|
|
\v
|
纵向制表符
|
|
\t
|
横向制表符
|
|
\r
|
回车
|
|
\f
|
换页
|
|
\oyy
|
八进制数yy代表的字符,例如:\o12代表换行
|
|
\xyy
|
十进制数yy代表的字符,例如:\x0a代表换行
|
|
\other
|
其它的字符以普通格式输出
|
5、输入
user = input("请输入您的用户名:")
print(user)
password = input("请输入登录密码:")
print(password)
6、变量类型
a = 10 print(type(a)) a='abc' print(type(a))
a=input("输入这里是字符") #变量a的类型是字符串,input接受的是一个表达示
print(a)
a=int("123") #强制类型转化
print(type(a))
print(22+a)
c=int(input("输入一个数字"))
print("输入的一个数字:%d"%c)
score = 0 if score >=90 and score <=100: print("本次考试,等级为A") elif score >=80 and score <=90: print("本次考试,等级为B") elif score >=70 and score <=80: print("本次考试,等级为C") elif score >=60 and score <=70: print("本次考试,等级为D") elif score >=0 and score <=60: #else: #else 和 elif 可以一起使用 print("本次考试,等级为E")
import random #引入随机库 print(random.randint(0,2)) #表示[0,2]的随机数,包含0,1,2 x = random.randint(0,2) print(x)
import和from ... import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数格式为:from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc,secondfunc,thirdfunc
将某个模块的全部函数导入,格式为: from somemodule import \*
16、循环语句
1)for...in循环
可以依次把list或tuple中的元素迭代出来
''' for i in range(5): print(i) #返回的是0,1,2,3,4 ''' ''' for i in range(0,11,3): #从0开始,到11结束,步进值为3(每次+3) print(i) #返回的是0,3,6,9 ''' ''' for i in range(-9,-110,-30): print(i) ''' ''' city="hangzhou" for x in city: print(x,end="\t") ''' a = ["aa","bb","cc","dd"] for i in range(len(a)): print(i,a[i])
2)while 和while...else
''' i = 0 while i < 5 : print("当前是第%d次执行打打抱循环"%(i+1)) print("i=%d"%i) # i = i + 1 i += 1 ''' #1-100求和 ''' x = 0 i = 0 while i < 100: i += 1 x += i print(i) print(x) ''' ''' n = 100 sum = 0 counter = 1 while counter <= n : sum = sum + counter counter += 1 print("1到 %d 的和为:%d"%(n,sum)) ''' count = 0 while count < 5 : print(count,"小于5") count += 1 else: print(count,"大于或等于5")
17、break 、continue 和 pass
1) break语句可以跳出for 和while的循环体,结束整个循环
2)continue语句跳过当前循环,直接进进下一轮循环,结束本次循环
''' i = 0 while i < 10 : i = i +1 print("-"*30) if i==6: break #i为6时跳出循环,结束整个while循环 print(i) #i为6时跳出循环了,只会打印到5 ''' i = 0 while i < 10 : i = i +1 print("-"*30) if i==6: continue #会发现数字6被跳过没有打出来,结束本次循环 print(i)
3)pass是空语句,一般用做占位语句,不做任何事情
17、字符串
字符串可以使用 单引号、双引号、三引号括起来定义,使用反斜杠 \ 转义特殊字符
python3源码默认UTF-8编码,所有字符串都是unicode字符串
支持字符串拼接、截取等多种运算
参考如下链接:
https://www.cnblogs.com/twoo/p/11641738.html
https://www.cnblogs.com/twoo/archive/2004/01/13/11642712.html
str = "hangzhou" print(str) print(str[0:7]) #返回hangzho print(str[1:8]) #返回angzhou print(str[0:8:2]) #[起始位置:结束位置:步进值] print(str[:5]) #返回hangz print(str[5:]) #返回hou print(str+",hello") #使用加号连接,返回hangzhou,hello print((str+",") * 4) #返回hangzhou,hangzhou,hangzhou,hangzhou, print("hello\nhangzhou") print(r"hello\nhangzhou") #加r后面\n转义无效,会直接输出原始字符
18、List(列表)
- 列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
- 列表是写在方括号[]之间,用逗号隔开的元素列表。
- 列表索引值以 0 为开始值, -1 为末尾的开始位置。
- 列表可以使用 + 操作符进行拼接,使用 * 表示重复。
列表常用操作参考:https://www.cnblogs.com/twoo/p/11643807.html
''' test_a = [10,"test"] #列表中可以存储混合类型 print(type(test_a[0])) print(type(test_a[1])) ''' namelist = ["小张","小王","小李"] ''' for name in namelist: print(name) ''' # print(len((namelist))) #len() 可以得到列表的长度,这里返回3 ''' length = len(namelist) i = 0 while i < length: print(namelist[i]) i += 1 ''' # 增: [append] ''' print("------增加前,名单列表的数据------") for name in namelist: print(name) nametemp = input("请输入添加学生的姓名:") namelist.append(nametemp) #在末尾追加一个元素 print("------增加后,名单列表的数据------") for name in namelist: print(name) ''' ''' a = [1,2] b = [3,4] a.append(b) #将b列表当作一个元素加入到a列表中,返回[1, 2, [3, 4]] print(a) # 增:[extend] a.extend(b) #b列表中的每个元素逐一追加到a列表中,返回 [1, 2, [3, 4], 3, 4] a.extend("a") print(a) ''' #增:[insert] ''' a = [0,1,2] a.insert(1,3) #第一个变量表示下标,第二个表示元素(对象),指定下标位置插入元素,返回 [0, 3, 1, 2] print(a) ''' # 删 [del] [pop] [remove] ''' moviename = ["我爱米奇","吾米一二三","丛林小精灵之丛林冒险","芭比之海豚魔法","我爱米奇","吾米一二三",] print("------删除前,电影列表的数据------") for name in moviename: print(name) # del moviename[2] #在指定位置删除一个元素 # moviename.pop() #弹出末尾最后一个 moviename.remove("我爱米奇") #直接删除指定内容的元素,只会删除遍历到的第一个 print("------删除后,电影列表的数据------") for name in moviename: print(name) ''' #改: [] ''' print("------修改加前,名单列表的数据------") for name in namelist: print(name) nammlist[1] = "小赵" #修改指定下标的元素内容 print("------修改后,名单列表的数据------") for name in namelist: print(name) ''' # 查:[in] [not in] ''' findName = input("请输入你要查找的学生姓名:") if findName in namelist: print("在学员名单中找到了相同的名字:%s"%findName) else: print("没有找到") ''' list_1 = ["a","b","c","a","b",] ''' print(list_1.index("a",1,4)) #可以查找指定下标范围的元素,并返回对应元素的下标,返回 3 print(list_1.index("a",1,3)) #注意范围区间 左闭右开,[1,3), 如查找不到会报错 ''' ''' print(list_1.count("b")) #统计指定元素出现几次 ''' ''' a = [1,4,2,3] print(a) #返回[1, 4, 2, 3] a.reverse() #将列表所有元素反转 print(a) #返回[3, 2, 4, 1] a.sort() #升序排列 print(a) a.sort(reverse=True) #降序排列 print(a) ''' ''' # schoolName = [[],[],[]] #有3个元素的空列表,每个元素都是一个空列表 schoolName = [["清华大学","北京大学"],["南开大学","天津大学","天津师范大学"],["山东大学","中国海洋大学"]] print(schoolName[1][2]) #返回 天津师范大学 ''' import random offices = [[],[],[]] teacher = ["a","b","c","d","e","f","g","h"] for name in teacher: index = random.randint(0,2) offices[index].append(name) #print(offices) i = 1 for office in offices: print("办公室%d的人数为: %d"%(i,len(office))) i += 1 for name in office: print("%s"%name,end="\t") print("\n") print("-"*20)
19、Tuple(元组)
tuple与list类似,不同之处在于tuple元素不能修改。tuple写在小括号里,元素之间用逗号隔开。
元组的元素不可变,但可以包含可变对象,如list。
定义一个只有一个元素的tuple,必须加逗号
参考链接:https://blog.csdn.net/mgmgzm/article/details/85330414
''' tup1 = () #<class 'tuple'> print(type(tup1)) tup2 = (50) #<class 'int'> print(type(tup2)) tup3 = (50,) #<class 'tuple'> print(type(tup3)) tup4 = (50,60,70) #<class 'tuple'> print(type(tup4)) ''' # 增 (连接) ''' tup1 = (12,34,56) tup2 = ("abc","xyz") tup = tup1 + tup2 print(tup) ''' # 删 ''' tup1 = (12,34,56) print(tup1) del tup1 #删除了整个元组变量 print("删除后:") print(tup1) ''' # 改 不能改 ''' tup1 = (12,34,56) tup1[0] = 100 #报错,不支持修改 TypeError: 'tuple' object does not support item assignment ''' # 查 ''' tup1 = ("ab","cd","ef","23","25","46","66") print(tup1[0]) print(tup1[-1]) #访问最后一个元素 print(tup1[1:5:2]) #[起始位置:结束位置:步进值],左闭右开[1,5) ,进行切片。 '''
20、dict(字典)
字典是无序的对象集合,使用键-值(key-value)存储,具有极快的查找速度。
键(key)必须使用不可变类型。
同一字典中,键(key)必须是唯一的。
参考链接:https://www.cnblogs.com/twoo/p/11644159.html
''' # 字典的定义 info = {"name":"吴彦祖","age":18} # 字典的访问 print(info["name"]) print(info["age"]) ''' # 访问了不存在的键 ''' # print(info["gender"]) #直接访问会报错:KeyError: 'gender' print(info.get("gender")) #使用get方法,没有找到对应的键,默认返回:None print(info.get("gender","m")) #可以设置没有找到对应的键默认返回值,如这里设置默认返回为 m print(info.get("age","20")) ''' info = {"name":"吴彦祖","age":18} # 增 ''' newID = input("请输入新的学号:") info["id"] = newID # print(info["id"]) print(info) ''' # 删 # [del] 删除键或整个字典 ''' print("删除前:%s"%info["name"]) del info["name"] #删除指定键值 print("删除后:%s"%info[name]) #删除了指定键值后,再次访问会报错:NameError: name 'name' is not defined ''' ''' print("删除前%s"%info) del info #删除整个字典 print("删除后:%s"%info) #删除字典后再访问会报错:NameError: name 'info' is not defined ''' # [clear] 清空 ''' print("清空前:%s"%info) info.clear() #清空字典的内容 print("清空后:%s"%info) ''' # 改 ''' info["age"] = 20 #直接修改键age的值 print(info["age"]) ''' # 查 (遍历) ''' print(info.keys()) #得到所有的键(列表) print(info.values()) #得到所有的值(列表) print(info.items()) #得到所有的项(列表)每个键值对是一个元组 ''' #遍历所有的键 ''' for key in info.keys(): print(key) ''' #遍历所有的值 ''' for value in info.values(): print(value) ''' #遍历所有的键值对 ''' for key,value in info.items(): print("key=%s,value=%s"%(key,value)) '''
21、set(集合)
set 和 dict 类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
set是无序的,重复元素在set中自动被过滤。
注意两个set可以做交集intersection,并集union,差集difference
参考链接:https://www.cnblogs.com/twoo/p/11649076.html
22、函数
在开发程序时,需要使用某块代码多次时,为了提高编写的效率以及代码的重用,把具有独立功能的代码组织为一个小模块,这就是函数。
参考链接:https://www.cnblogs.com/twoo/p/11658391.html
https://www.cnblogs.com/twoo/p/11750304.html
https://www.cnblogs.com/twoo/p/11750321.html
''' # 函数的定义 def printinfo(): print("------------------------") print(" 人生苦短,我用Python ") print("------------------------") # 调用函数 printinfo() ''' # 带参数的函数 def add2Num(a,b): c = a + b print(c) add2Num(9,33)
23、全局变量(函数外部定义)和局部变量(函数内部定义)
建议正常情况局部变量不要与全局变量相同,虽然不会受影响,但有时不好区分
a = 50 #全局变量 def test1(): a = 100 #局部变量 print("test1------修改前a=%d" %a) a = 200 print("test1------修改前a=%d" % a) def test2(): a = 300 #不同的函数可以定义相同变量名,彼此无关 print("test2------a=%d"%a) def test3(): print("test3------a=%d"%a) #没有定义局部变量时默认使用全局变量 def test4(): global a #声明全局变量在函数中的标识符 print("test1------修改前a=%d" % a) a = 500 print("test1------修改前a=%d" % a) test1() test2() test3() test4()
24、文件操作
文件,就是把一些数据存放起来,可以让程序下一次执行的时候直接使用,而不必重新制作一份,省时省力。
参考链接:https://zhuanlan.zhihu.com/p/56909212?utm_source=wechat_session
文件打开的几种访问模式
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
''' f = open("test.txt","w") #打开文件,w模式(写模式),文件不存在则新建 f.write("您好! 我的祖国") f.close() #关闭文件 ''' #read()方法,读取指定的字符,开始时定位在文件头部,每执行一次向后移动指定字符数 ''' f = open("test.txt","r") content = f.read(4) print(content) content = f.read(5) print(content) f.close() ''' ''' f = open("test.txt","r") # content = f.readline() #读一行信息 # print(content) content = f.readlines() #一次性读取全部文件内容为列表,每行为一个字符串元素。 #print(content) i = 1 for temp in content: print("%d:%s"%(i,temp)) i += 1 f.close() ''' import os # f = open("test.txt","w") # f.close() # os.rename("test.txt","test1.txt") #文件重命名 # os.remove("test1.txt") #删除文件 os.mkdir("test") #创建目录 # os.getcwd() #获取当前路径 os.chdir("F:\\BaiduNetdiskDownload\shixun\day2") #切换路径 os.getcwd() #获取当前路径 os.listdir("./")#获取当前目录列表 os.rmdir("test") #删除目录
25、错误与异常
#发生异常 ''' print("----test----1-----") f = open("123.txt","r") #用只读模式打开一个不存在的文件,报错 print("----test----2-----") #这行代码不会被执行 ''' # 捕获异常 ''' try: print("----test----1-----") f = open("123.txt", "r") print("----test----2-----") except IOError: #文件没找到,属于IO异常(输入输出异常) pass #捕获异常后,执行的代码 ''' ''' try: print(add) # except IOError: #注意异常类型,捕获时要一致 except NameError: print("有错误了") ''' ''' try: print("----test----1-----") # f = open("123.txt","w") # f.close() f = open("123.txt", "r") f.close() print("----test----2-----") print(add) except (NameError,IOError): #将可能产生的所有异常类型都放到小括号中 print("有错误了") ''' # 获取错误信息 ''' try: print("----test----1-----") # f = open("123.txt","w") # f.close() f = open("123.txt", "r") f.close() print("----test----2-----") print(add) except (NameError,IOError) as error_result: #将错误信息获取后放入变量 print("有错误了") print("ERROR:%s"%error_result) ''' # 捕获所有的异常 ''' try: print("----test----1-----") # f = open("123.txt","w") # f.close() f = open("123.txt", "r") f.close() print("----test----2-----") print(add) except Exception as error_result: #Exception可以承接任何异常 print("有错误了") print("ERROR:%s"%error_result) ''' # try.....finally 和 嵌套 import time try: f = open("123.txt","r") try: while True: content = f.readline() if len(content) == 0: break time.sleep(2) print(content,end="") finally: f.close() print("\n关闭文件") except Exception as result: print("发生异常",result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号