Hadoop 之 shuffle
Shuffle过程是MapReduce的核心,描述着数据从map task输出到reduce task输入的这段过程。
Hadoop的集群环境,大部分的map task和reduce task是执行在不同的节点上的,那么reduce就要取map的输出结果。那么集群中运行多个Job时,task的正常执行会对集群内部的网络资源消耗严重。虽说这种消耗是正常的,是不可避免的,但是,我们可以采取措施尽可能的减少不必要的网络资源消耗。另一方面,每个节点的内部,相比于内存,磁盘IO对Job完成时间的影响相当的大,。
所以:从以上分析,shuffle过程的基本要求:
1.完整地从map task端拉取数据到reduce task端
2.在拉取数据的过程中,尽可能地减少网络资源的消耗
3.尽可能地减少磁盘IO对task执行效率的影响
那么,Shuffle的设计目的就要满足以下条件:
1.保证拉取数据的完整性
2.尽可能地减少拉取数据的数据量
3.尽可能地使用节点的内存而不是磁盘
一、map阶段
map节点执行map task任务生成map的输出结果
shuffle的工作内容:
从运算效率的出发点,map输出结果优先存储在map节点的内存中。每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区块满时,需要将缓冲区中的数据以一个临时文件的方式存到磁盘,当整个map task结束后再对磁盘中这个map task所产生的所有临时文件做合并,生成最终的输出文件。最后,等待reduce task来拉取数据。当然,如果map task的结果不大,能够完全存储到内存缓冲区,且未达到内存缓冲区的阀值,那么就不会有写临时文件到磁盘的操作,也不会有后面的合并。
图解如下:
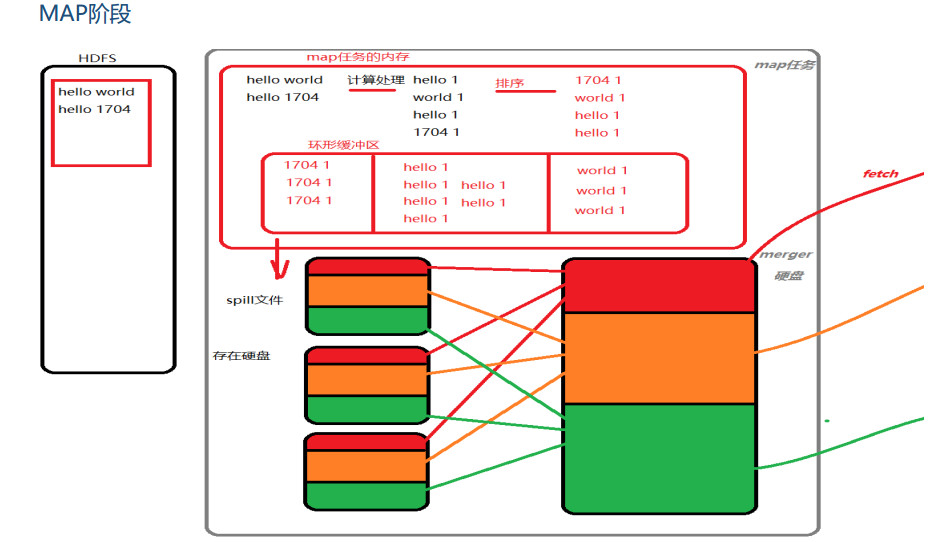
环形缓冲区:是使用指针机制把内存中的地址首尾相接形成一个存储中间数据的缓存区域,默认100MB;80M阈值,20M缓冲区,是为了解决写入环形缓冲区数据的速度大于写出到spill文件的速度是数据的不丢失;
Spill文件:spill文件是环形缓冲区到达阈值后写入到磁盘的单个文件.这些文件在map阶段计算结束时,会合成分好区的一个merge文件供给给reduce任务抓取;spill文件过小的时候,就不会浪费io资源合并merge;默认情况下3个以下spill文件不合并;对于在环形缓冲区中的数据,最终达不到80m但是数据已经计算完毕的情况,map任务将会调用flush将缓冲区中的数据强行写出spill文件。
二、reduce阶段
当mapreduce任务提交后,reduce task就不断通过RPC从JobTracker那里获取map task是否完成的信息,如果获知某台TaskTracker上的map task执行完成,Shuffle的后半段过程就开始启动。其实呢,reduce task在执行之前的工作就是:不断地拉取当前job里每个map task的最终结果,并对不同地方拉取过来的数据不断地做merge,过程如下:
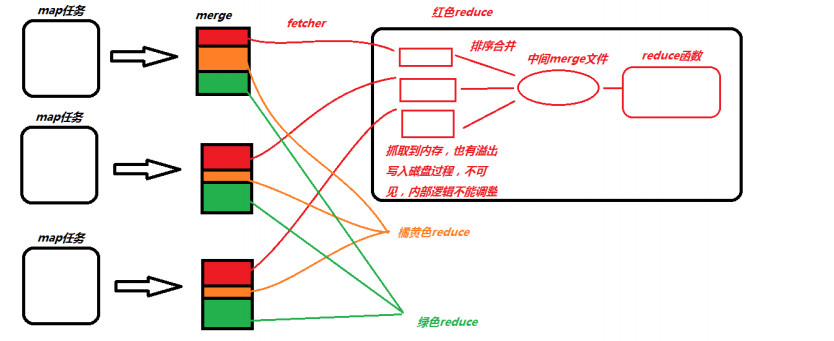
reduce阶段分三个步骤:
抓取,合并,排序
1 reduce 任务会创建并行的抓取线程(fetcher)负责从完成的map任务中获取结果文件,是否完成是通过rpc心跳监听,通过http协议抓取;默认是5个抓取线程,可调,为了是整体并行,在map任务量大,分区多的时候,抓取线程调大;
2 抓取过来的数据会先保存在内存中,如果内存过大也溢出,不可见,不可调,但是单位是每个merge文件,不会切分数据;每个merge文件都会被封装成一个segment的对象,这个对象控制着这个merge文件的读取记录操作,有两种情况出现:
在内存中有merge数据 •
在溢写之后存到磁盘上的数据 •
通过构造函数的区分,来分别创建对应的segment对象
3 这种segment对象会放到一个内存队列中MergerQueue,对内存和磁盘上的数据分别进行合并,内存中的merge对应的segment直接合并,磁盘中的合并与一个叫做合并因子的factor有关(默认是10)
4 排序问题
MergerQueue继承轮换排序的接口,每一个segment 是排好序的,而且按照key的值大小逻辑(和真的大小没关系);每一个segment的第一个key都是逻辑最小,而所有的segment的排序是按照第一个key大小排序的,最小的在前面,这种逻辑总能保证第一个segment的第一个key值是所有key的逻辑最小文件合并之后,最终交给reduce函数计算的,是MergeQueue队列,每次计算的提取数据逻辑都是提取第一个segment的第一个key和value数据,一旦segment被调用了提取key的方法,MergeQueue队列将会整体重新按照最小key对segment排序,最终形成整体有序的计算结果;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号