Hadoop 之HDFS
Hadoop是什么?
Hadoop是一个能够对大量数据进行分布式处理的软件框架,实现了Google的MapReduce编程模型和框架,能够把应用程序分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行。在MapReduce中,一个准备提交执行的应用程序称为“作业(job)”,而从一个作业划分出 得、运行于各个计算节点的工作单元称为“任务(task)”。此外,Hadoop提供的分布式文件系统(HDFS)主要负责各个节点的数据存储,并实现了高吞吐率的数据读写。
1、hadoop版本介绍
Hadoop3个版本
1.x版本,包含两个组件:HDFS MAPREDUCE
2.x版本,包含三个组件:HDFS MR YARN
3.0版本和2.0结构一致,做了一个非常重要的优化,
2.x版本namenode高可用只能开启2台,3.0可以5台
hadoop各组件功能:
HDFS:是数据管理存储的组件--解决了zebra当中没有数据存储管理的概念
MR:是计算组件,是hadoop底层封装了分布式计算的所有框架结构--解决了没有计算架构的问题
YARN :资源调度组件--解决zebra中没有细粒度资源分配的问题
2.0引入yarn后,接运行其他的计算架构,spark,storm
yarn同类产品(hadoop生态圈中另一个资源调度技术):Mesos,涉及到操作系统架构
2、hadoop三种分布模式
(1)、单机模式
核心组件HDFS不支持,无法进行存储功能的使用,可以支持MR代码的调优和调整工作;
(2)、单机伪分布
对于开发者使用角度的感受和完全分布式一样的,利用线程代替单机物理节点完成分布
式的使用,HDFS和MR都支持,专门设计出来给教学使用的;
(3)、完全分布式
按照环境搭建的所有节点角色,使用物理节点配置对应的角色,多台物理机组成的分布
式完全集群;
一、HDFS系统架构(The Hadoop Distributed Filesystem)
HDFS是hadoop的分布式文件系统,HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上;(流式数据访问:运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集)
(一)具体架构:
HDFS也是按照Master和Slave的结构,分NameNode、SecondaryNameNode、DataNode这几个角色。
1、nameNode:
是Master节点;
主要职责:(1)管理元数据(文件/目录的元信息和每个文件对应的数据块列表) (2)维护整个文件系统的目录树 (3)响应客户请求
问:命名空间指的什么?(命名空间,hdfs格式化会改变命名空间id,当首次格式化的时候datanode和namenode会产生一个相同的namespaceID,然后读取数据就可以,如果你重新执行格式化的时候,namenode的namespaceID改变了,但是datanode的namespaceID没有改变,两边就不一致了,如果重新启动或进行读写hadoop就会挂掉
)
结构:
NameNode维护着2张表:
1.文件系统的目录结构,以及元数据信息
2.文件与数据块(block)列表的对应关系
元数据存放在fsimage中,在运行的时候加载到内存中的(读写比较快),操作日志写到edits中。(namenode内存中存储的是=fsimage+edits)
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
Namenode容错机制:
第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了
2、Datanode
提供真实文件数据的存储服务,执行数据块的读写操作。
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。
HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block. (一个文件可以产生多个快,多个文件是不可能成为一个块信息的,处于减轻namenode的压力,最好的方式就是一个文件一个块 )
Replication:多复本,默认是三个。(使用副本形式保存数据的安全,hdfs-site.xml的dfs.replication属性)
3、SecondaryNameNode
问:通过什么机制可以做到双机热备?
是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。(Secondary NameNode的处理,是将fsimage和edites文件周期的合并,不会造成nameNode重启时造成长时间不可访问的情况。)
具体机制如下:
(1) Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log),将新的编辑操作记录到新生成的edit log文件;
(2通过http get方式,读取NameNode上的fsimage和edits文件,到Secondary NameNode上;
(3)读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作(类似OracleDG,应用redo log),并生成一个新的fsimage文件,即这个检查点被创建;
(4)通过http post方式,将新的fsimage文件传送到NameNode;
(5) NameNode使用新的fsimage替换原来的fsimage文件,让(1)创建的edits替代原来的edits文件;并且更新fsimage文件的检查点时间。
4、HDFS安全模式
(1)在hadoop集群的时候,集群的运行会进入到安全模式(safeMode)下。在安全模式下运行一段时间后,自动退出
在安全模式下,系统会做什么?
当集群启动的时候,会首先进入到安全模式。系统在安全模式下,会检查数据块的完整性。假设我们设置的副本数(即参数dfs.replication)是5,那么在dataNode上就应该有5个副本存在,假设只存在3个副本,那么比率就是3/5=0.6。在配置文件hdfs-default.xml中定义了一个最小的副本率
此外,安全模式还会在secondarynamenode合并文件传送给nameenode的同时启用
(2)使用命令查看、进入、离开安全模式
命令hadoop fs –safemode get 查看安全模式状态
命令hadoop fs –safemode enter 进入安全模式状态
命令hadoop fs –safemode leave 离开安全模式状态
备注:FSNamesystem的内部类:SafeModeInfo实现的。监控安全模式的是SafeModeMonitor内部类
5、HDFS回收站机制
在HDFS里,删除文件时,不会真正的删除,其实是放入回收站/trash,回收站里的文件可以快速恢复。可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值或是回收站被清空时,文件才会被彻底删除,并且释放占用的数据块。hadoop 的回收站trash功能默认是关闭的,所以需要在core-site.xml中手动开启
我们可以通过递归查看指令,找到我们要恢复的文件放在回收站的哪个目录下,执行:hadoop fs -lsr /user/root/.Trash
找到文件路径后,如果想恢复,执行hdfs 的mv 指令即可,(mv指令可用于文件的移动)
6、HDFS读写模型
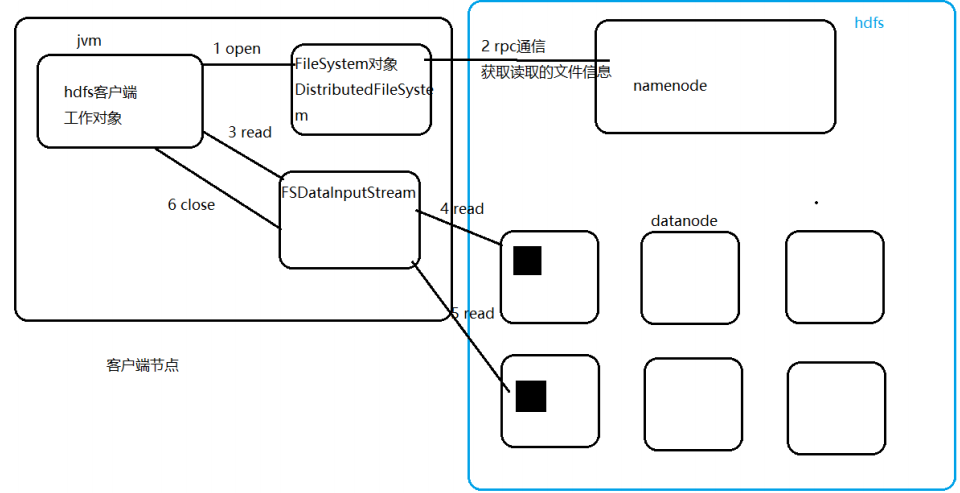
(1)、读流程
1:客户端调用fileSystem对象的open方法,来打开希望读取的文件
2:文件系统,通过RPC通信,与namenode链接,把希望读取的文件发送给namenode,
namenode获取到文件名后,将把元数据对应的所有切块和datanode位置都发送回客户端;
包括文件起始数据块,对每一个数据块都返回存有该数据块副本的datanode位置,这些
datanode会按照与客户端距离排序,而且文件系统在客户端节点返回一个流
3 客户端捡回通过调用流的read方法,开始读取所有数据块,从第一批开始
4 客户端调用的流对象中封装这一个流实例(DFSInputStream,这个流管理namenode和
datanode的所有io操作),这个流对象链接最佳位置的datanode进行读取操作,读取到当
前块末尾时,关闭流,链接下一个块的最佳位置的副本
5 开始读取下一个
6 当所有的文件数据块都读完,客户端调用FSDataInputStream的close方法,结束读取操作;
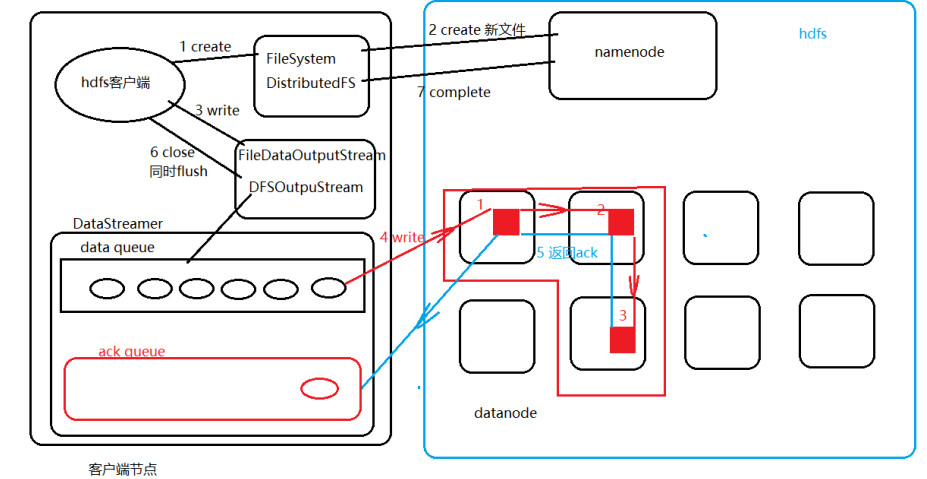
(2)、写流程
1 客户端调用文件系统create方法,创建一个新文件
2 文件系统通过RPC通信,与namenode通信,在hdfs命名空间创建一个空的文件名称,没有
数据块;namenode根据文件名称,客户端操作权限进行校验,一旦校验失败返回IO异常,
校验如果通过在元数据中暂存一条记录
3 create方法调用成功后返回一个流对象(FileDataOutputStream封装的操作namenode和
datanodeIO流的DFSOutputStream),调用该对象的write方法,将数据源源不断的写入到
DataStreamer维护的队列中,data queue,以64KB的package封装数据
4 DataStreamer根据namenode返回的一个datanode列表(默认3个副本,3个
datanode),将package包写入到datanode列表组成的一个“pipeline”的第一个
datanode中,管道利用双攻通信的技术,不会使用流对象直接在写一个副本,而是在管道里
将写完的数据传递下去,datanode1传送数据给datanode2,2传送给3;写入datanode的
package包从data queue中删除,但是备份一份到DataStreamer维护的另一个队列里ack
queue;
5 每当一个包写入成功备份在ack queue里的包将会被删除;有几个副本就接受几次成功的反
馈
6 当客户端调用流对象,将数据写完,就会直接调用close方法,将流中的所有缓存flush
同时DataStreamer里的所有package都直接写入
7 等待所有的写入的包确认信息都完成了,文件系统最终于namenode通信,调用complete
方法,完成元数据的修改

 浙公网安备 33010602011771号
浙公网安备 33010602011771号