
20211122唐嘉浩 2021-2022-2《python程序设计》 实验四 Python综合实践
项目实践名称:爬取并下载网易云歌曲
项目要求:
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
(4)如果没有使用华为云服务(ECS或者MindSpore均可),本次实践扣10分。
实验分析及设计过程
1.抓取网页URL和元素地址:
edge浏览器:
Google浏览器:
个人角度讲Google浏览器很明显在元素抓取这方面比edge好得多,至少不会像edge一样元素腰斩。
2.网页外链的获取:
- 现在已经知道下载链接是这样的:
http://music.163.com/song/media/outer/url?id='- 我能够找到的爬虫链接是这样的:
#歌曲清单 music_list = 'https://music.163.com/#/playlist?id=2412826586' #歌手排行榜 artist_list = 'https://music.163.com/#/artist?id=8325' #搜索列表 search_list = 'https://music.163.com/#/search/m/?order=hot&cat=全部&limit=435&offset=435&s=梁静茹'(但有一说一,最开始找链接人都麻了,后来查了资料,参考链接如下:如何获取网易云音乐播放外链 - 知乎 (zhihu.com) - 爬虫代码:
- 1:涉及到的模板:
- requests:专业用于请求处理,requests库学习文档中文版
- lxml:其实可以用python自带的正则表达式库re,但是为了更加简单入门,用 lxml 中的 etree 进行网页数据定位爬取。
- re:python正则表达式处理
- json:python的json处理库
(因为课上没有跟上王老师,又忘记了云班课上有视频回放,导致了我重新一个个看了一遍这几个怎么用: - 对应的学习链接:(10条消息) Python(爬虫篇)---Requests模块_Zachary579的博客-CSDN博客
- (10条消息) Python-- lxml用法_ydw_ydw的博客-CSDN博客_lxml python
- (10条消息) python中re模块的用法_yjj20007665的博客-CSDN博客_python中re
- (10条消息) Json和JS模板的使用_小蚂蚁有力量的博客-CSDN博客_json和js
(离谱的是,最开始没用反应过来etree是lxml的一个模板,然后我看着代码上的bug陷入了沉思。。。。。还好CSDN确实给力)
2:对字符串进行去空格和转协议处理:url = url.replace('/#', '').replace('https', 'http') 3:请求头和页面源码: -
res = requests.get(url=url, headers=headers).text -
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', 'Referer': 'https://music.163.com/', 'Host': 'music.163.com'(我隐约记得王老师上课讲过,但是啥还是得重新学。。。。。) -
整个代码: -
import os
import re
import json
import requests
from lxml import etree
def download_songs(url=None):
if url is None:
url = 'https://music.163.com/#/playlist?id=2384642500'
url = url.replace('/#', '').replace('https', 'http')
out_link = 'http://music.163.com/song/media/outer/url?id='
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://music.163.com/',
'Host': 'music.163.com'
}
res = requests.get(url=url, headers=headers).text
tree = etree.HTML(res)
song_list = tree.xpath('//ul[@class="f-hide"]/li/a')
artist_name_tree = tree.xpath('//h2[@id="artist-name"]/text()')
artist_name = str(artist_name_tree[0]) if artist_name_tree else None
#song_list_tree = tree.xpath('//*[@id="m-playlist"]/div[1]/div/div/div[2]/div[2]/div/div[1]/table/tbody')
song_list_name_tree = tree.xpath('//h2[contains(@class,"f-ff2")]/text()')
song_list_name = str(song_list_name_tree[0]) if song_list_name_tree else None
folder = './' + artist_name if artist_name else './' + song_list_name
if not os.path.exists(folder):
os.mkdir(folder)
for i, s in enumerate(song_list):
href = str(s.xpath('./@href')[0])
song_id = href.split('=')[-1]
src = out_link + song_id
title = str(s.xpath('./text()')[0])
filename = title + '.mp3'
filepath = folder + '/' + filename
print('开始下载第{}首音乐:{}\n'.format(i + 1, filename))
try:
#download_lyric(title, song_id)
data = requests.get(src).content
with open(filepath, 'wb') as f:
f.write(data)
except Exception as e:
print(e)
print('{}首全部歌曲已经下载完毕!'.format(len(song_list)))
def download_lyric(song_name, song_id):
url = 'http://music.163.com/api/song/lyric?id={}&lv=-1&kv=-1&tv=-1'.format(song_id)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://music.163.com/',
'Host': 'music.163.com'
}
res = requests.get(url=url, headers=headers).text
json_obj = json.loads(res)
lyric = json_obj['lrc']['lyric']
reg = re.compile(r'\[.*\]')
lrc_text = re.sub(reg, '', lyric).strip()
print(song_name, lrc_text)
if __name__ == '__main__':
#music_list = 'https://music.163.com/#/playlist?id=2384642500'
music_list = 'https://music.163.com/#/artist?id=8325'
# music_list = 'https://music.163.com/#/search/m/?order=hot&cat=全部&limit=435&offset=435&s=梁静茹'
download_songs(music_list)3:华为云ESC服务器上PUTTY的运行截图: 

本地文件夹的保存截图:
代码实验思路:
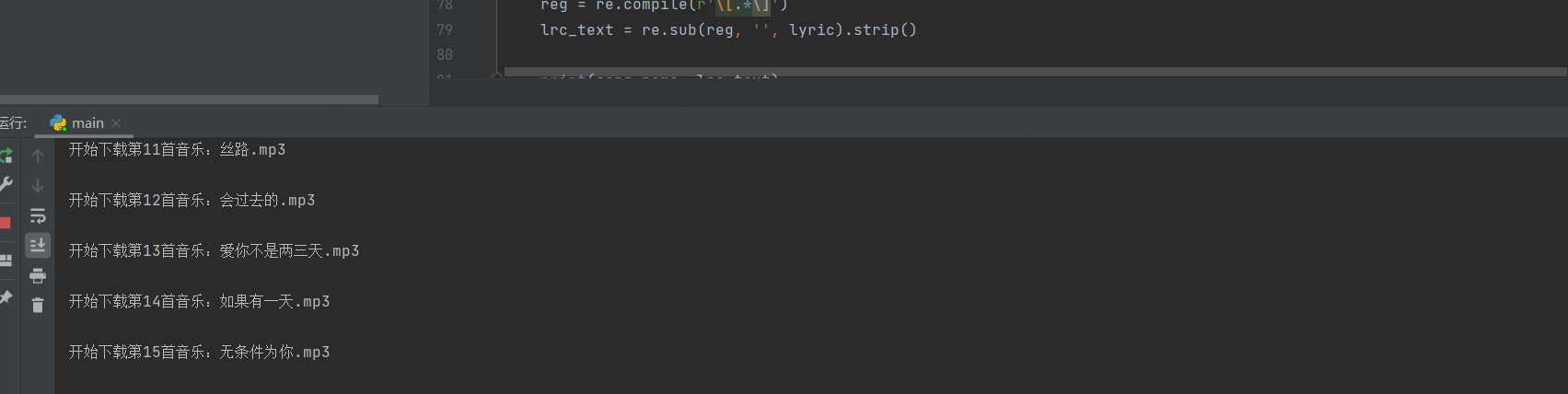
yysy,自己写的时候,大概就是这样的情况:

我明白我驾驭不住:于是我选择跟着教学打代码:
- 13.网易云音乐评论爬虫举例 - Python网络爬虫实战_哔哩哔哩_bilibili
- 20行Python代码简单爬取网易云音乐_哔哩哔哩_bilibili
- 等等;(但是好多都用了selenium,事实上我压根没看懂,所以最后选了一个没有selenium的代码。。。。。。虽然整整100行,但是至少勉强,也许懂了)
·遇到的问题以及解决方法: - 一:无法在putty上运行python文件:
- 解决办法:下载python,通过创建python文件用Python.文件名.py运行;
- 二:上面的也运行不了:
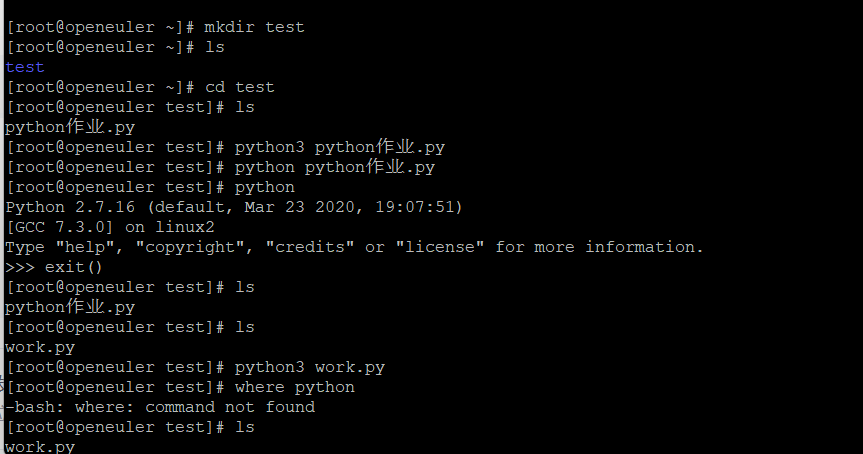
- 解决办法:重新下载所有运用到文件里的库,例如lxml、request、os等
三:文件有中文python3运行不了: - 后来加了utf-8还是没解决,最后没办法了只能把中文给换掉了。
四:lxml在python和python3里都没法下载,用pip也没用: - 参考了(10条消息) Python安装模块(包/库)的方法_Smilecoc的博客-CSDN博客_python 安装模块
- 最后还是靠(10条消息) lxml-4.6.2.tar.gz安装报错处理(Please make sure the libxml2 and libxslt development packages are installed)_了尘自无心的博客-CSDN博客解决的。
本学期所学内容 -
- 变量赋值
- 运算符及其优先级
- 基本数据类型
- 循环语句
- 列表、元组、字典、集合
- 字符串与正则表达式
- 函数
- 面向对象程序设计
- 文件操作及异常处理
- Python操作数据库
- Python爬虫
对于python的理解: - 总的而言python相对于C语言确实具有非常强大的容错率和简便性。好多库以及网上的很多资源都是python用户们可以共享使用的,比如pygame这个神奇的python库。而且python编程使用的语言和逻辑体系相对于C语言来讲通俗易懂很多。
- 其次python的运行并不依赖于二进制,可以直接通过源代码运行程序。并且可以直接移植到很多操作平台里面。
本学期课程的感悟: - 我个人来讲很佩服王老师,老师的对学生的问题回答十分详细耐心,并且有给出了相关的学习视频,课堂氛围也很好。
- 但个人来讲很难受的一点,因为是密码专业导致导论课一些相关的基础完全没有,跟课的时候好多理论基础的都是都是一头雾水,并且打代码跟不上是最难受的,很多课下来自己电脑上的代码都是东拼西凑,有时候低头敲了一个代码,抬头就不知道老师在讲啥了,这不是老师的问题,但我希望老师能不能适当慢一点,敲代码跟不上是真的绝望。
- 但是总的来讲,我很喜欢这门课的老师,也很喜欢python。
- 人生苦短,我用python(手动滑稽)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· [AI/GPT/综述] AI Agent的设计模式综述