redis
1 redis 安装和配置
# redis 是什么
开源:基于c编写的,早起版本2w3千行
基于键值对的存储系统:字典形式
多种数据结构:字符串,hash,列表,集合,有序集合
高性能,功能丰富
#Redis特性(8个)
1 速度快:10w ops(每秒10w读写),数据存在内存中,c语言实现,数据单线程模型
2 持久化:rdb和aof
3 多种数据结构:
4 5大数据结构
BitMaps位图:布隆过滤器 本质是 字符串
HyperLogLog:超小内存唯一值计数,12kb HyperLogLog 本质是 字符串
GEO:地理信息定位 本质是有序集合
5 支持多种编程语言:基于tcp通信协议,各大编程语言都支持
6 功能丰富:发布订阅(消息) 事务(pipeline)
简单:源代码几万行,不依赖外部库
7 主从复制和高可用
主从复制:主服务器和从服务器,主服务器可以同步到从服务器中
高可用和分布式
2 源码安装
# 使用源码包
wget https://download.redis.io/redis-stable.tar.gz
# 解压
tar -xzvf redis-stable.tar.gz
# 改名
mv redis-stable/ redis
cd redis
make && make install
# /usr/local/bin/ 路径下会有可执行文件
# src目录下,就会有几个可执行文件
#redis-server--->redis服务器
#redis-cli---》redis命令行客户端
#redis-sentinel---》sentinel服务器,哨兵
#redis-benchmark---》redis性能测试工具
#redis-check-aof--->aof文件修复工具
#redis-check-dump---》rdb文件检查工具
mv redis.conf redis.conf.bak
vi redis.conf
# 修改配置文件启动
daemonize yes
pidfile /var/run/redis.pid
port 6379
dir ./data
logfile 6379.log
# 创建文件夹
mkdir data
# 启动
./bin/redis-server ./etc/redis.conf # 数据目录data在当前目录下
# 查看redis版本
redis-cli -v
redis-cli 7.2.5
3 redis-stack
# 下载地址:https://redis.io/downloads/ # centos的
wget https://packages.redis.io/redis-stack/redis-stack-server-7.2.0-v11.rhel7.x86_64.tar.gz
# 解压即用
tar -xzvf redis-stack-server-7.2.0-v11.rhel7.x86_64.tar.gz
# 文件夹重命名
mv redis-stack-server-7.2.0-v11 redis-stack-server
cd etc/
vi redis.conf
# 修改配置文件启动
daemonize yes
pidfile /var/run/redis1.pid
port 6380
dir ./data
logfile 6380.log
# 任意路径下敲
redis-server # 启动redis
# 查看redis版本
./bin/redis-cli -v
4 hash类型
###1---hget,hset,hdel
hget key field #获取hash key对应的field的value 时间复杂度为 o(1)
hset key field value #设置hash key对应的field的value值 时间复杂度为 o(1)
hdel key field #删除hash key对应的field的值 时间复杂度为 o(1)
#测试
hset user:1:info age 23
hget user:1:info age
hset user:1:info name lqz
hgetall user:1:info
hdel user:1:info age
###2---hexists,hlen
hexists key field #判断hash key 是否存在field 时间复杂度为 o(1)
hlen key #获取hash key field的数量 时间复杂度为 o(1)
hexists user:1:info name
hlen user:1:info #返回数量
###3---hmget,hmset
hmget key field1 field2 ...fieldN #批量获取hash key 的一批field对应的值 时间复杂度是o(n)
hmset key field1 value1 field2 value2 #批量设置hash key的一批field value 时间复杂度是o(n)
###4--hgetall,hvals,hkeys
hgetall key #返回hash key 对应的所有field和value 时间复杂度是o(n)
hvals key #返回hash key 对应的所有field的value 时间复杂度是o(n)
hkeys key #返回hash key对应的所有field 时间复杂度是o(n)
###小心使用hgetall
##1 计算网站每个用户主页的访问量
hincrby user:1:info pageview count
##2 缓存mysql的信息,直接设置hash格式
##其他操作 hsetnx,hincrby,hincrbyfloat
hsetnx key field value #设置hash key对应field的value(如果field已存在,则失败),时间复杂度o(1)
hincrby key field intCounter #hash key 对英的field的value自增intCounter 时间复杂度o(1)
hincrbyfloat key feld floatCounter #hincrby 浮点数 时间复杂度o(1)
5 列表类型
###插入操作###
#rpush 从右侧插入
rpush key value1 value2 ...valueN #时间复杂度为o(1~n)
#lpush 从左侧插入
#linsert
linsert key before|after value newValue #从元素value的前或后插入newValue 时间复杂度o(n) ,需要遍历列表
linsert listkey before b java
linsert listkey after b php
######删除操作#########
lpop key #从列表左侧弹出一个item 时间复杂度o(1)
rpop key #从列表右侧弹出一个item 时间复杂度o(1)
lrem key count value
#根据count值,从列表中删除所有value相同的项 时间复杂度o(n)
1 count>0 从左到右,删除最多count个value相等的项
2 count<0 从右向左,删除最多 Math.abs(count)个value相等的项
3 count=0 删除所有value相等的项
lrem listkey 0 a #删除列表中所有值a
lrem listkey -1 c #从右侧删除1个c
ltrim key start end #按照索引范围修剪列表 o(n)
ltrim listkey 1 4 #只保留下表1--4的元素
############查询操作############
lrange key start end #包含end获取列表指定索引范围所有item o(n)
lrange listkey 0 2
lrange listkey 1 -1 #获取第一个位置到倒数第一个位置的元素
lindex key index #获取列表指定索引的item o(n)
lindex listkey 0
lindex listkey -1
llen key #获取列表长度
############修改操作############
lset key index newValue #设置列表指定索引值为newValue o(n)
lset listkey 2 ppp #把第二个位置设为ppp
############实战############
实现timeLine功能,时间轴:微博关注的人,按时间轴排列,在列表中放入关注人的微博的即可
############其他操作############
blpop key timeout #lpop的阻塞版,timeout是阻塞超时时间,timeout=0为拥有不阻塞 o(1)
brpop key timeout #rpop的阻塞版,timeout是阻塞超时时间,timeout=0为拥有不阻塞 o(1)
#要实现栈的功能
lpush+lpop
#实现队列功能
lpush+rpop
#固定大小的列表
lpush+ltrim
#消息队列
lpush+brpop
6 集合操作
sadd key element #向集合key添加element(如果element存在,添加失败) o(1)
srem key element #从集合中的element移除掉 o(1)
scard key #计算集合大小
sismember key element #判断element是否在集合中
srandmember key count #从集合中随机取出count个元素,不会破坏集合中的元素
spop key #从集合中随机弹出一个元素
smembers key #获取集合中所有元素 ,无序,小心使用,会阻塞住
##### 集合操作######
sdiff user:1:follow user:2:follow #计算user:1:follow和user:2:follow的差集
sinter user:1:follow user:2:follow #计算user:1:follow和user:2:follow的交集
sunion user:1:follow user:2:follow #计算user:1:follow和user:2:follow的并集
sdiff|sinter|suion + store destkey... #将差集,交集,并集结果保存在destkey集合中
sdiffstore 另一个集合名字 boys girls
sinterstore 另一个集合名字 boys girls
#### 集合可以做什么
1 抽奖系统 :通过spop来弹出用户的id,活动取消,直接删除
2 点赞,点踩,喜欢等,用户如果点了赞,就把用户id放到该条记录的集合中
3 标签:给用户/文章等添加标签,sadd user:1:tags 标签1 标签2 标签3
给标签添加用户,关注该标签的人有哪些
4 共同好友:集合间的操作
#### 总结####
sadd:可以做标签相关
spop/srandmember:可以做随机数相关
sadd/sinter:社交相关
7 有序集合
#有一个分值字段,来保证顺序
#集合有序集合
集合:无重复元素,无序,element
有序集合:无重复元素,有序,element+score
#列表和有序集合
列表:可以重复,有序,element
有序集合:无重复元素,有序,element+score
## API使用
zadd key score element #score可以重复,可以多个同时添加,element不能重复 o(logN)
zrem key element #删除元素,可以多个同时删除 o(1)
zscore key element #获取元素的分数 o(1)
zincrby key increScore element #增加或减少元素的分数 o(1)
zcard key #返回元素总个数 o(1)
zrank key element #返回element元素的排名(从小到大排)
zrange key 0 -1 #返回排名,不带分数 o(log(n)+m) n是元素个数,m是要获取的值
zrange player:rank 0 -1 withscores #返回排名,带分数
zrangebyscore key minScore maxScore #返回指定分数范围内的升序元素 o(log(n)+m) n是元素个数,m是要获取的值
zrangebyscore user:1:ranking 90 210 withscores #获取90分到210分的元素
zcount key minScore maxScore #返回有序集合内在指定分数范围内的个数 o(log(n)+m)
zremrangebyrank key start end #删除指定排名内的升序元素 o(log(n)+m)
zremrangebyrank user:1:rangking 1 2 #删除升序排名中1到2的元素
zremrangebyscore key minScore maxScore #删除指定分数内的升序元素 o(log(n)+m)
zremrangebyscore user:1:ranking 90 210 #删除分数90到210之间的元素
#实战
排行榜:音乐排行榜,销售榜,关注榜,游戏排行榜
# 其他操作
zrevrank #从高到低排序
zrevrange #从高到低排序取一定范围
zrevrangebyscore #返回指定分数范围内的降序元素
zinterstore #对两个有序集合交集
zunionstore #对两个有序集合求并集
8 慢查询
# 我们配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询
# 慢查询是一个先进先出的队列,固定长度,保存在内存中--->通过设置慢查询,以后超过我们设置时间的命令,就会放在这个队列中
# 后期我们通过查询这个队列,过滤出 慢命令--》优化慢命令
# 设置记录所有命令
config set slowlog-log-slower-than 0
# 最多记录100条
config set slowlog-max-len 100
# 持久化到本地配置文件
config rewrite
# 查看慢查询队列
slowlog get [n] #获取慢查询队列
'''
日志由4个属性组成:
1)日志的标识id
2)发生的时间戳
3)命令耗时
4)执行的命令和参数
'''
slowlog len #获取慢查询队列长度
slowlog reset #清空慢查询队列
9 发布订阅
# 发布订阅(观察者模式):发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型
# 原生实现
-发布消息:
publish channel message
-订阅
subscribe channel
-接收消息
-只要发布者一发布,订阅者都会受到
python+redis实现
import redis
# 连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 订阅者
sub = r.pubsub()
sub.subscribe('channel')
for message in sub.listen():
print(message)
import redis
# 连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 发布者
r.publish('channel', 'message')
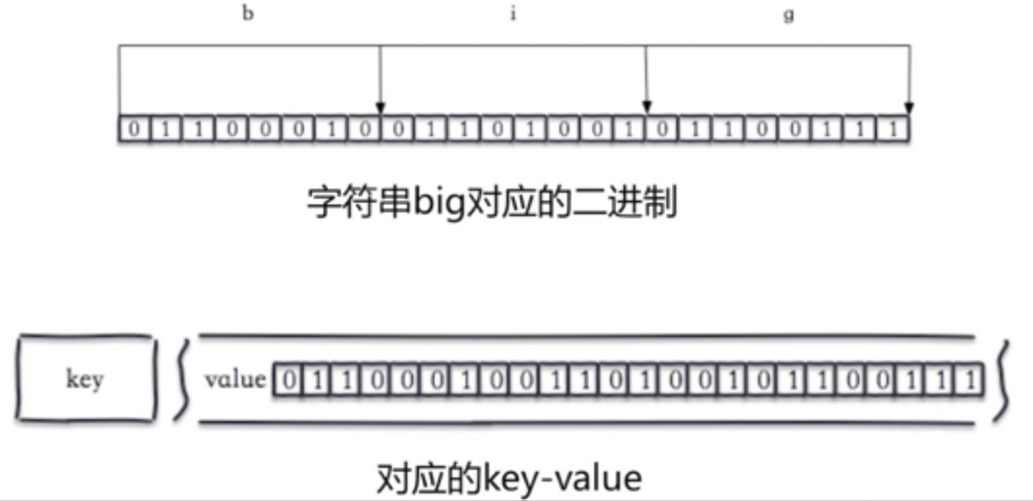
10 bitmap位图
#本质是字符串
#操作比特位
b i g
01100011 01101001 01100111
set hello big #放入key位hello 值为big的字符串
getbit hello 0 #取位图的第0个位置,返回0
getbit hello 1 #取位图的第1个位置,返回1 如上图
# 我们可以直接操纵位
setbit key offset value #给位图指定索引设置值
setbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig
# 获取前3位中1的个数
bitcount name 0 3
11 hyperloglog
# 基于HyperLogLog算法:极小的空间完成独立数量统计,本质还是字符串
# 使用
-放值:pfadd uuids "uuid1" "uuid2" "uuid3" "uuid4"
-统计个数:pfcount uuids
-判断一个值是否在里面:pfadd uuids "uuid1"
# 用处
-统计日活用户
-去重:爬过的网址,就不爬了--》存一下爬过的
-黑白名单
# 注意
-百万级别独立用户统计,百万条数据只占15k
-错误率 0.81%
-无法取出单条数据,只能统计个数
12 geo
# geo 地理位置信息
-GEO(地理信息定位):存储经纬度,计算两地距离,范围等
# js获取经纬度
if (navigator.geolocation) {
navigator.geolocation.getCurrentPosition(function(position) {
var latitude = position.coords.latitude;
var longitude = position.coords.longitude;
console.log("经度:" + longitude);
console.log("纬度:" + latitude);
});
} else {
console.log("浏览器不支持Geolocation API");
}
# 增加地理位置信息
geoadd key longitude latitude member
# 把北京地理信息天津到cities:locations中
geoadd cities:locations 116.28 39.55 beijing
# 获取天津的经纬度 geopos key member #获取地理位置信息
geopos cities:locations tianjin
# 根据经纬度--》文字
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="my_application")
def geolocate_point(latitude, longitude):
location = geolocator.reverse(f"{latitude}, {longitude}")
return location.address
# 统计两个地理位置之间的距离
geodist cities:locations beijing tianjin km
# 统计某个地理位置方圆xx公里,有xx
georadiusbymember cities:locations beijing 150 km
13 持久化
# 什么是持久化
redis的所有数据保存在内存中,对数据的更新将异步的保存到硬盘上
# 持久化的实现方式
快照:某时某刻数据的一个完成备份,
-mysql的Dump:写一个mysql自动定时备份和清理前后端程序
-redis的RDB:某一刻,把内存中得数据,保存到硬盘上这个操作就是rbd的持久化
写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可
-mysql的 Binlog
-Redis的 AOF
rdb
# rdb方案 :三种方式
1 人工同步:客户端 : save # 同步操作,会阻塞其他命令--》单线程架构
2 人工异步:客户端:bgsave # 异步操作,不会阻塞其他命令
3 配置文件
save 900 1 #配置一条
save 300 10 #配置一条
save 60 10000 #配置一条
save 60 5
# 最佳配置
save 900 1
save 300 10
save 60 10000
dbfilename dump-6379.rdb #以端口号作为文件名,可能一台机器上很多reids,不会乱
dir ./bigdiskpath #保存路径放到一个大硬盘位置目录
stop-writes-on-bgsave-error yes #出现错误停止
rdbcompression yes #压缩
rdbchecksum yes #校验
# 确定 RDB问题
耗时,耗性能:
不可控,可能会丢失数据
aof
# 客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复
# AOF的三种策略
日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上
always:redis–》写命令刷新的缓冲区—》每条命令fsync到硬盘—》AOF文件
everysec(默认值):redis——》写命令刷新的缓冲区—》每秒把缓冲区fsync到硬盘–》AOF文件
no:redis——》写命令刷新的缓冲区—》操作系统决定,缓冲区fsync到硬盘–》AOF文件
# 配置文件
appendonly yes #将该选项设置为yes,打开
appendfilename "appendonly-${port}.aof" #文件保存的名字
appendfsync everysec #采用第二种策略
dir /bigdiskpath #存放的路径
no-appendfsync-on-rewrite yes
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite yes
# 放在了文件中
appendonly.aof.1.base.rdb :永久的
appendonly.aof.1.incr.aof :临时的
appendonly.aof.manifest: 哪些文件存了数据


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具